
Sesame publie le modèle de parole conversationnelle CSM : rendre l'interaction vocale avec l'IA plus naturelle
Un récent billet de blog de Brendan Iribe, Ankit Kumar et de l'équipe Sesame décrit les dernières recherches de l'entreprise dans le domaine de la génération de discours conversationnel, le modèle de discours conversationnel (Conversational Speech Model - CSM). CSM). Ce modèle est conçu pour remédier au manque d'émotion et de naturel dans les interactions actuelles avec les assistants vocaux, en rapprochant les interactions vocales de l'IA du niveau humain.
Traverser la "vallée de la terreur" dans la quête de la "présence vocale".
L'équipe de Sesame est convaincue que la voix est le moyen de communication le plus intime pour les humains et qu'elle contient une mine d'informations qui vont bien au-delà du sens littéral. Cependant, les assistants vocaux existants manquent souvent d'expression émotionnelle et ont un ton plat, ce qui rend difficile l'établissement d'une connexion profonde avec les utilisateurs. Lorsqu'ils utilisent ces assistants vocaux pendant une longue période, les utilisateurs se sentent non seulement déçus, mais aussi fatigués.
Pour résoudre ce problème, Sesame a développé le concept de "présence vocale", qui signifie que les interactions vocales semblent réelles, comprises et valorisées, et le modèle CSM est une étape clé vers cet objectif. L'équipe de Sesame insiste sur le fait qu'elle ne crée pas seulement un outil, mais un partenaire de dialogue qui établit une relation de confiance avec l'utilisateur.
Atteindre la "présence vocale" n'est pas une tâche facile et nécessite une combinaison des éléments clés suivants :
- L'intelligence émotionnelle : Reconnaître les changements d'humeur de l'utilisateur et y répondre.
- Dynamique du dialogue : Saisir le rythme naturel du dialogue, y compris le débit de parole, les pauses, les interruptions et l'emphase.
- Conscience de la situation : Adapter le ton et l'expression à différents scénarios de dialogue.
- Personnalité cohérente : Maintenir la cohérence et la fiabilité de la personnalité de l'assistant IA.
Modèle CSM : une seule étape, multimodal, plus efficace
Pour atteindre ces objectifs, l'équipe de Sesame a proposé un nouveau modèle de discours conversationnel, CSM, qui utilise un cadre d'apprentissage multimodal de bout en bout pour générer un discours plus naturel et plus cohérent en utilisant des informations provenant de l'historique de la conversation.
Contrairement aux modèles traditionnels de synthèse vocale, le modèle CSM fonctionne directement sur les jetons RVQ (quantification vectorielle résiduelle). Cette conception permet d'éviter le goulot d'étranglement de l'information qui peut être causé par les jetons sémantiques dans les modèles TTS traditionnels, ce qui permet de mieux capturer les nuances de la parole.
CSM La conception architecturale du modèle est également assez impressionnante. Il utilise deux transformateurs autorégressifs :
- Une épine dorsale multimodale : Traitement des informations textuelles et audio entrelacées pour prédire la couche zéro du livre de codes RVQ.
- Décodeur audio : En utilisant un en-tête linéaire différent pour chaque livre de codes, les N-1 couches restantes sont prédites pour reconstruire la parole.
Cette conception permet au décodeur d'être beaucoup plus petit que le tronc, ce qui se traduit par une génération de parole à faible latence tout en conservant le modèle de bout en bout.

Processus d'inférence du modèle CSM
En outre, afin de résoudre le problème du goulot d'étranglement de la mémoire pendant le processus d'apprentissage, l'équipe Sesame a proposé un schéma de répartition des calculs. Ce schéma permet d'entraîner le décodeur audio uniquement sur un sous-ensemble aléatoire d'images audio, ce qui réduit considérablement la consommation de mémoire sans affecter les performances du modèle.

Répartition du processus de formation
Résultats expérimentaux : proches du niveau humain, mais encore insuffisants
L'équipe de Sesame a entraîné le modèle CSM sur un ensemble de données contenant environ 1 million d'heures d'audio en anglais et a utilisé une variété de mesures pour évaluer en profondeur les performances du modèle.
Les résultats de l'évaluation montrent que le modèle CSM est proche du niveau humain dans les mesures traditionnelles du taux d'erreur de mot (WER) et de la similarité de locuteur (SIM).
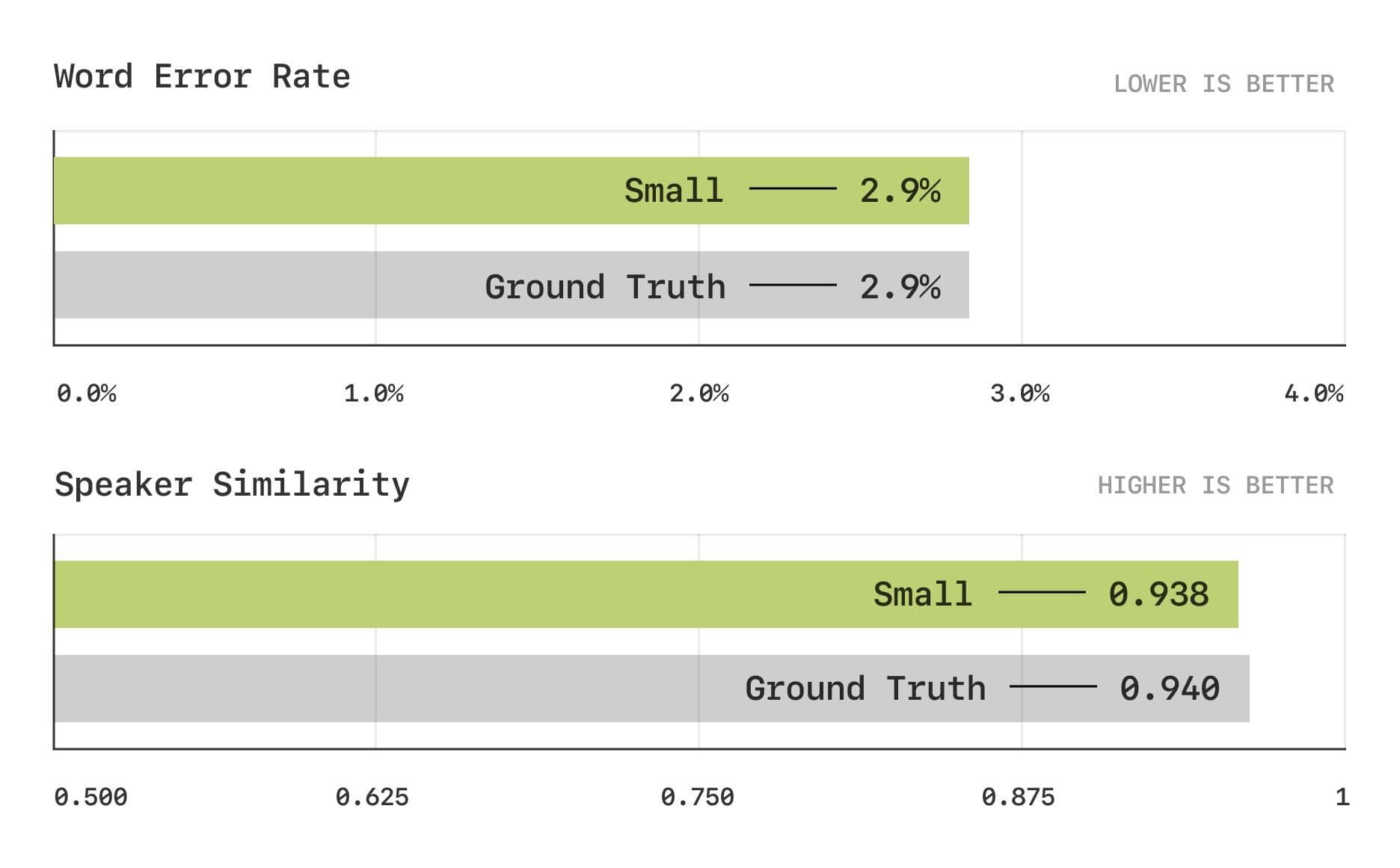
Taux d'erreur sur les mots et tests de similarité entre locuteurs
Afin d'évaluer plus en profondeur les capacités du modèle en matière de prononciation et de compréhension du contexte, l'équipe de Sesame a également introduit un nouvel ensemble de tests de référence basés sur la transcription de la parole, notamment des tests de désambiguïsation des homophones et de cohérence de la prononciation. Les résultats montrent que le modèle CSM est également performant dans ces domaines et que les performances s'améliorent à mesure que la taille du modèle augmente.
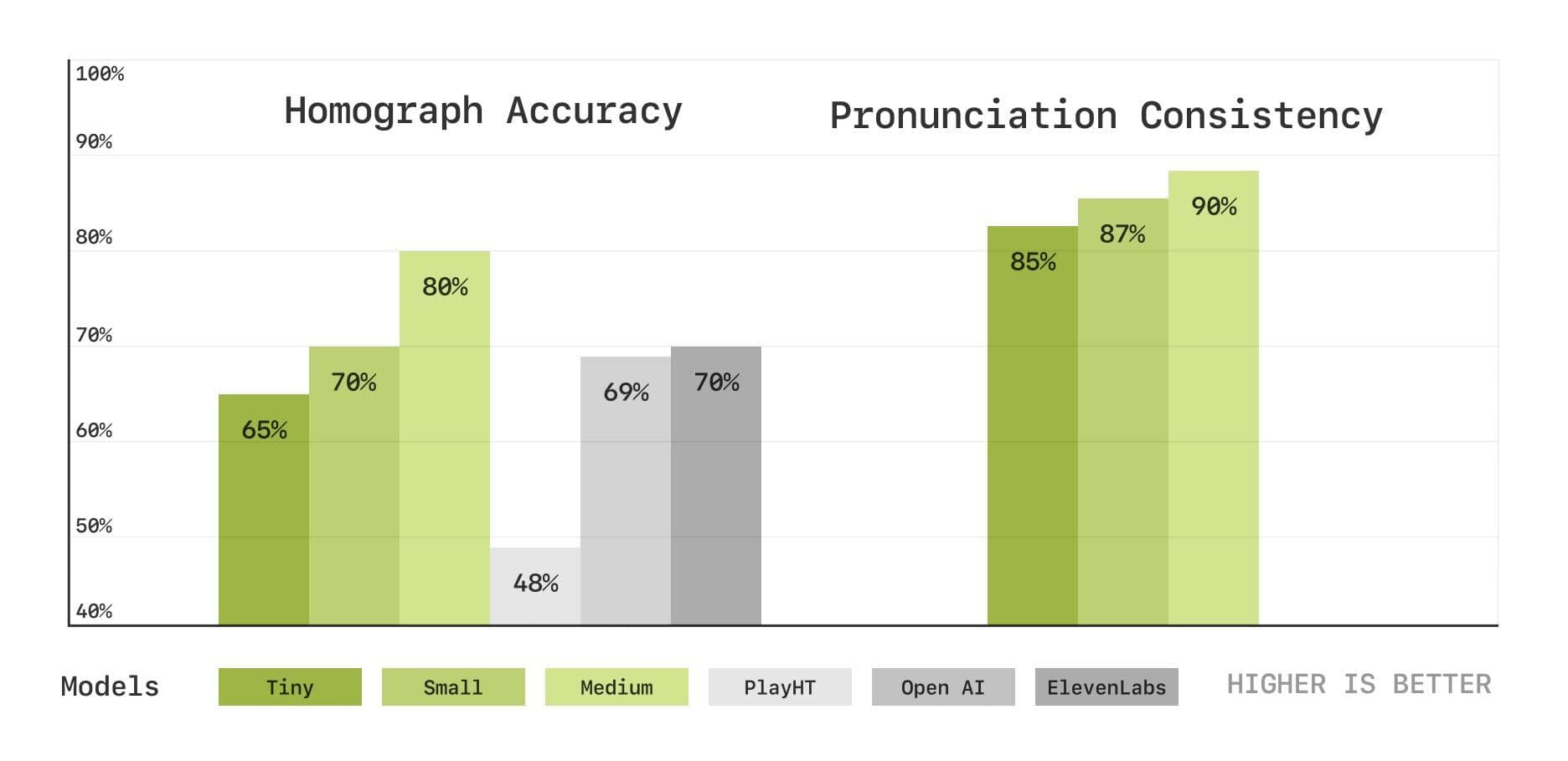
Tests de désambiguïsation des homophones et de cohérence de la prononciation
L'équipe de Sesame a mené deux études sur le score d'opinion moyen comparatif (CMOS) à l'aide de l'ensemble de données Expresso. Les résultats ont montré qu'en l'absence de contexte, les auditeurs avaient des préférences comparables pour la parole générée par le modèle CSM et la parole humaine réelle. Cependant, lorsqu'ils disposent d'informations contextuelles, les auditeurs préfèrent de manière significative le discours humain réel. Cela suggère que le modèle CSM peut encore être amélioré pour capturer les changements rythmiques subtils dans le dialogue.
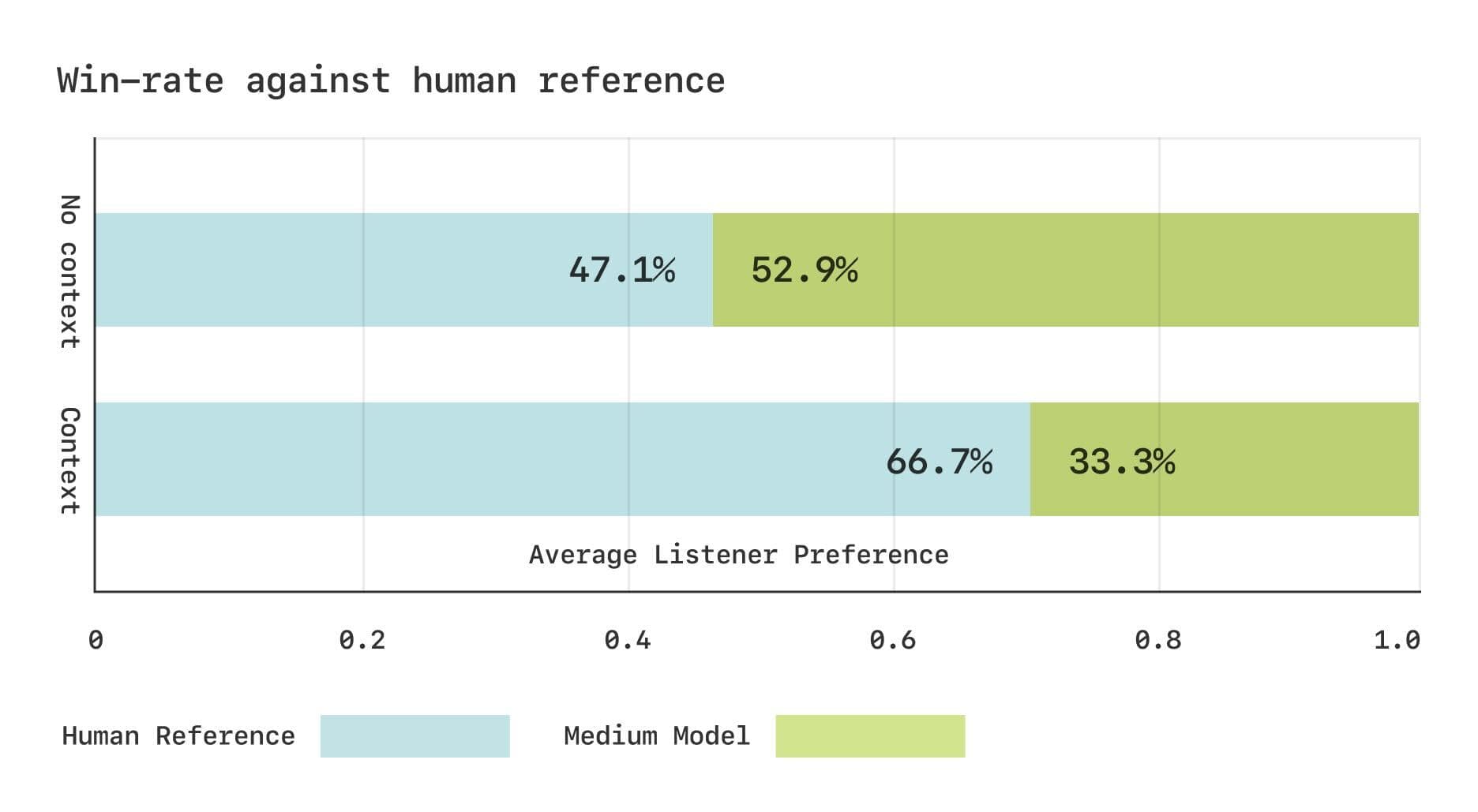
Résultats de l'évaluation subjective pour l'ensemble de données Expresso
Partage des sources ouvertes, perspectives d'avenir
Dans l'esprit de l'open source, l'équipe de Sesame prévoit d'ouvrir les composants clés du modèle CSM pour le développement mutuel de la communauté.
https://github.com/SesameAILabs/csm
Bien que le modèle CSM ait fait des progrès significatifs, il présente encore certaines limites, telles que la prise en charge de l'anglais principalement, avec des capacités multilingues qui doivent être améliorées. L'équipe de Sesame a déclaré qu'à l'avenir, elle continuera à augmenter la taille du modèle, à accroître la capacité de l'ensemble de données, à étendre la prise en charge linguistique et à explorer l'utilisation de modèles linguistiques de pré-entraînement afin d'améliorer encore les performances du modèle CSM. L'équipe Sesame est convaincue que l'avenir du dialogue IA réside dans les modèles full duplex, c'est-à-dire les modèles capables d'apprendre implicitement la dynamique du dialogue à partir des données.
Dans l'ensemble, le modèle CSM publié par Sesame constitue une avancée importante dans le domaine de la génération de la parole conversationnelle, en fournissant de nouvelles idées pour construire des interactions vocales IA plus naturelles et plus émotionnelles. Bien que des améliorations soient encore possibles, l'esprit open source de l'équipe de Sesame et ses projets d'avenir méritent d'être salués.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...