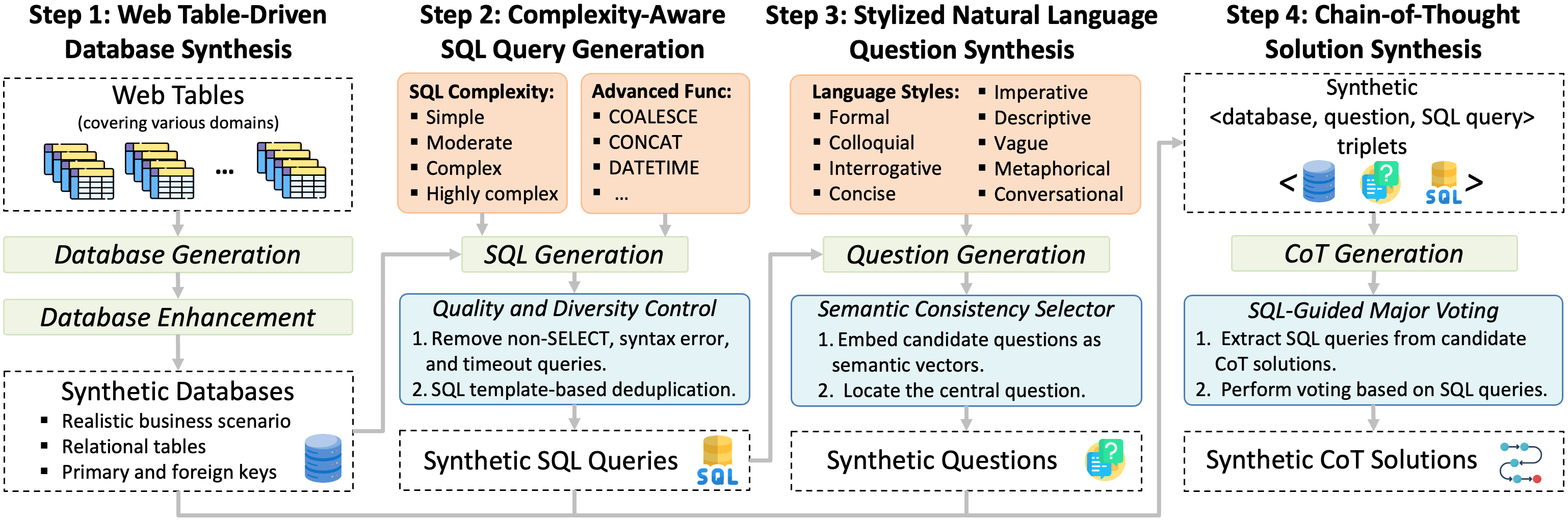
RolmOCR : Modèle d'OCR de documents pour la reconnaissance de caractères manuscrits et obliques

Introduction générale
RolmOCR est un outil de reconnaissance optique de caractères (OCR) open source développé par l'équipe Reducto AI, basé sur le modèle de langage visuel Qwen2.5-VL-7B. Il peut extraire du texte à partir d'images et de fichiers PDF plus rapidement que des outils similaires. olmOCR RolmOCR ne s'appuie pas sur les métadonnées PDF, ce qui simplifie le traitement tout en prenant en charge un large éventail de types de documents, y compris les notes manuscrites et les documents universitaires. Il est publié sous la licence Apache 2.0 et son utilisation, sa modification et son intégration sont gratuites pour les particuliers et les développeurs. L'équipe de Reducto a construit l'outil en mettant à jour le modèle et en optimisant les données d'entraînement, dans le but de rendre la numérisation des documents plus efficace.


Liste des fonctions
- Extraction de texte rapide : Extraction de texte à partir d'images et de PDF avec une vitesse de traitement rapide pour un grand nombre de documents.
- Prise en charge d'un large éventail de documents : reconnaissance de notes manuscrites, de documents imprimés et de formulaires complexes.
- Open source et gratuit : ouvert sous la licence Apache 2.0, le code peut être librement téléchargé et adapté.
- Faible encombrement mémoire : par rapport à olmOCR Plus efficace en termes de ressources et de besoins informatiques en fonctionnement.
- Aucune métadonnée n'est requise : traitez directement le document original sans vous appuyer sur des informations supplémentaires provenant du PDF.
- Reconnaissance améliorée des documents inclinés : 15% dans les données d'apprentissage est tourné pour améliorer l'adaptation aux documents non positivement inclinés.
- Basé sur le dernier modèle : adopte Qwen2.5-VL-7B pour améliorer la précision et l'efficacité de la reconnaissance.
Utiliser l'aide
RolmOCR est un outil open source qui fonctionne principalement par le biais du code et convient aux utilisateurs ayant des compétences de base en programmation. Vous trouverez ci-dessous un guide d'installation et d'utilisation détaillé.
Processus d'installation
- Vérification de l'environnement Python
RolmOCR nécessite Python 3.8 ou plus. Ouvrez la ligne de commande et tapezpython --versionVérifiez la version. Si vous ne l'avez pas installé, allez sur le site web de Python et téléchargez et installez-le. - Installation du framework vLLM
Utilisation du RolmOCR vLLM Exécuter le modèle. Entrez dans la ligne de commande :
pip install vllm
Une fois l'installation terminée, définissez les variables d'environnement :
export VLLM_USE_V1=1
Cela garantit le bon fonctionnement de vLLM.
- Télécharger le modèle RolmOCR
Les fichiers du modèle sont hébergés sur Hugging Face. Allez sur https://huggingface.co/reducto/RolmOCR et cliquez sur "Files and versions" pour les télécharger. Vous pouvez aussi le télécharger à partir de la ligne de commande :
git clone https://huggingface.co/reducto/RolmOCR
- Démarrage des services locaux
Allez dans le dossier du modèle téléchargé et exécutez-le :
vllm serve reducto/RolmOCR
Au démarrage du service, l'adresse par défaut est http://localhost:8000/v1. Laissez la fenêtre de la ligne de commande ouverte.
Utilisation
RolmOCR extrait du texte via des appels API. Voici les étapes exactes.
Préparer le document
Préparez le fichier à reconnaître, par exemple une image (PNG/JPG) ou un PDF. supposez que le chemin d'accès au fichier soit test_doc.png.
Appeler l'API pour extraire du texte
Ecrivez un script en Python pour convertir le fichier en encodage base64 et l'envoyer à RolmOCR. L'exemple de code est le suivant :
from openai import OpenAI
import base64
# 连接本地服务
client = OpenAI(api_key="123", base_url="http://localhost:8000/v1")
model = "reducto/RolmOCR-7b"
# 图片转 base64
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# 调用 RolmOCR 提取文字
def ocr_page_with_rolm(img_base64):
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{img_base64}"}},
{"type": "text", "text": "把这张图片里的文字提取出来,像人读的那样自然返回。"}
]
}
],
temperature=0.2,
max_tokens=4096
)
return response.choices[0].message.content
# 运行示例
test_img_path = "test_doc.png"
img_base64 = encode_image(test_img_path)
result = ocr_page_with_rolm(img_base64)
print(result)
enregistrer sous (un fichier) ocr_test.pyet de l'exécuter :
python ocr_test.py
Le programme renvoie le texte extrait, par exemple :
会议记录
2025年4月7日
- 项目计划讨论
- 准备相关资料
fichier de lot
Pour gérer plusieurs fichiers, réécrivez le code. Placez les chemins d'accès aux fichiers dans une liste et appelez-la dans une boucle :
file_paths = ["doc1.png", "doc2.png", "doc3.png"]
for path in file_paths:
img_base64 = encode_image(path)
result = ocr_page_with_rolm(img_base64)
print(f"{path} 的结果:\n{result}\n")
Fonction en vedette Fonctionnement
- reconnaissance de l'écriture manuscrite
RolmOCR reconnaît l'écriture manuscrite. Par exemple, une note portant la mention "Deepseek Coder" est restituée avec précision sans être confondue avec "OCLM". Après avoir téléchargé l'image, les résultats sont classés par ordre naturel. - Traitement asymétrique des documents
Le 15% est tourné dans les données d'apprentissage, ce qui lui permet de mieux s'adapter aux documents de travers. Par exemple, dans le cas d'une numérisation en biais, le texte est toujours extrait correctement. - Fonctionnement avec peu de mémoire
Pas de dépendance à l'égard des métadonnées, des indices plus courts et moins de mémoire graphique (VRAM) utilisée pour le traitement. Convient aux ordinateurs à faible configuration.
mise en garde
- interruption de serviceNe fermez pas la fenêtre de la ligne de commande après avoir démarré le service, sinon l'API s'arrêtera.
- déficit de mémoireSi votre ordinateur ne dispose pas de suffisamment de mémoire, vous pouvez ajuster le paramètre vLLM, comme par exemple
per_device_train_batch_sizeréduisant ainsi les besoins en ressources. - limitationsLe RolmOCR peut ne pas reconnaître un texte de petite taille avec un faible contraste ou une reconnaissance incomplète de tableaux complexes sans métadonnées. Il est recommandé d'optimiser la qualité de l'image et de réessayer.
- Les boîtes de mise en page ne sont pas prises en chargeContrairement à l'API commerciale de Reducto, RolmOCR n'est pas en mesure de produire des cadres de délimitation pour le texte.
Avec ces étapes, les utilisateurs peuvent facilement installer et utiliser RolmOCR pour extraire rapidement du texte à partir de documents.
scénario d'application
- recherche universitaire
Les étudiants et les chercheurs peuvent utiliser RolmOCR pour numériser des notes manuscrites ou des documents anciens en textes électroniques afin de faciliter l'organisation et la recherche. - Traitement des documents d'entreprise
L'entreprise peut l'utiliser pour extraire le texte des contrats et des enveloppes et le saisir dans le système, ce qui réduit le travail manuel. - Prise en charge multilingue
Traiter des documents mixtes chinois et anglais ou des lettres manuscrites en français, en extrayant rapidement les informations et en les adaptant à la communication transfrontalière.
QA
- Quelle est la différence entre RolmOCR et olmOCR ?
RolmOCR est basé sur le modèle Qwen2.5-VL-7B mis à jour, qui est plus rapide, a une empreinte mémoire plus faible, n'utilise pas de métadonnées et est plus robuste pour les documents asymétriques. - Peut-il être utilisé hors ligne ?
Peut. Il suffit de télécharger le modèle et de démarrer le service local, sans connexion internet. - Prend-il en charge la reconnaissance des formes ?
Pris en charge, mais risque de ne pas prendre en compte certaines parties de tableaux complexes sans métadonnées, comme les sous-titres dans les documents universitaires.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes

Pas de commentaires...