
Enroulé ! Modèles vectoriels de textes longs Stratégies de découpage Compétition
Le modèle vectoriel de texte long est capable d'encoder dix pages de texte en un seul vecteur, ce qui semble puissant, mais est-ce vraiment pratique ?
Beaucoup de gens pensent... Pas nécessairement.
Peut-on l'utiliser directement ? Doit-il être découpé en morceaux ? Quelle est la méthode de découpage la plus efficace ? Dans cet article, nous vous proposons d'explorer différentes stratégies de découpage pour les modèles vectoriels de texte long, d'analyser les avantages et les inconvénients et de vous aider à éviter les pièges.
Le problème de la vectorisation des textes longs
Tout d'abord, voyons quels sont les problèmes posés par la compression d'un article entier en un seul vecteur.
Dans le cadre de la construction d'un système de recherche documentaire, un seul article peut contenir plusieurs sujets. Par exemple, ce blog sur le rapport des participants à la conférence ICML 2024 contient une introduction à la conférence, une présentation du travail de Jina AI (jina-clip-v1) et des résumés d'autres documents de recherche. Si l'article entier est vectorisé en un seul vecteur, ce vecteur mélangera des informations provenant de trois sujets différents :
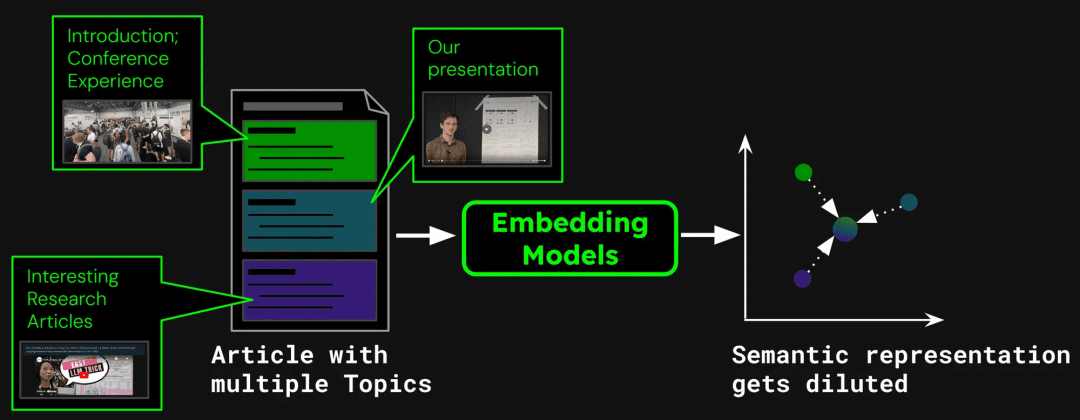
Cela peut entraîner les problèmes suivants :
1. dilution de la représentation
indique que la dilution affaiblit la précision des vecteurs de texte. Bien que l'article de blog contienne plusieurs sujets, leCependant, les demandes de recherche des utilisateurs ont tendance à se concentrer sur un seul de ces éléments. Représenter l'ensemble de l'article par un seul vecteur équivaut à comprimer toutes les informations relatives au sujet en un seul point de l'espace vectoriel. Au fur et à mesure que du texte est ajouté à l'entrée du modèle, ce vecteur représente progressivement le sujet global de l'article, en diluant les détails de passages ou de sujets particuliers. C'est comme si l'on mélangeait plusieurs pigments en une seule couleur, ce qui rend difficile pour l'utilisateur d'identifier une couleur particulière à partir du mélange lorsqu'il essaie de la trouver.
2. capacité limitée
Les dimensions vectorielles générées par le modèle sont fixes, et le texte long contient beaucoup d'informations, ce qui entraînera inévitablement une perte d'informations au cours du processus de transformation. C'est comme si l'on compressait une carte haute définition dans un timbre-poste, et de nombreux détails ne sont pas visibles.
3. la perte d'informations
De nombreux modèles de textes longs ne peuvent traiter que jusqu'à 8192 tokens. Un texte de meilleure qualité devra être tronqué, généralement à la fin, et si l'information clé se trouve à la fin du document, la recherche peut échouer.
4) Exigences en matière de segmentation
Certaines applications n'ont besoin d'effectuer la vectorisation que sur des segments spécifiques du texte, comme les systèmes de questions-réponses, où seuls les paragraphes contenant les réponses doivent être extraits pour la vectorisation. Dans ce cas, le découpage en morceaux du texte reste nécessaire.
3 Stratégies de traitement des textes longs
Avant de commencer l'expérience, pour éviter toute confusion conceptuelle, nous définissons d'abord trois stratégies de blocs :
1. pas de regroupement :Encode l'ensemble du texte directement dans un vecteur unique.
2. le découpage naïf (Naive Chunking) :Le texte est d'abord divisé en plusieurs morceaux de texte et vectorisé séparément. Les méthodes couramment utilisées comprennent le découpage en morceaux de taille fixe, qui divise le texte en morceaux de taille fixe. jeton nombre de morceaux ; découpage en phrases : découpage en phrases ; découpage sémantique : découpage basé sur des informations sémantiques. Dans cette expérience, des morceaux de taille fixe sont utilisés.
3. le découpage tardif :Il s'agit d'une nouvelle méthode qui consiste à lire l'ensemble du texte avant de le découper en morceaux et qui se compose de deux étapes principales :
- Texte complet du codeEncoder d'abord l'ensemble du document pour obtenir une représentation vectorielle de chaque mot, en préservant l'ensemble des informations contextuelles.
- mise en commun des données (chunk pooling)Le partitionnement tardif : Générer des vecteurs pour chaque bloc de texte en regroupant en moyenne les vecteurs de jetons du même bloc de texte en fonction de la limite du bloc. Étant donné que le vecteur de chaque jeton est généré dans le contexte du texte complet, le partitionnement tardif peut préserver les informations contextuelles entre les blocs.
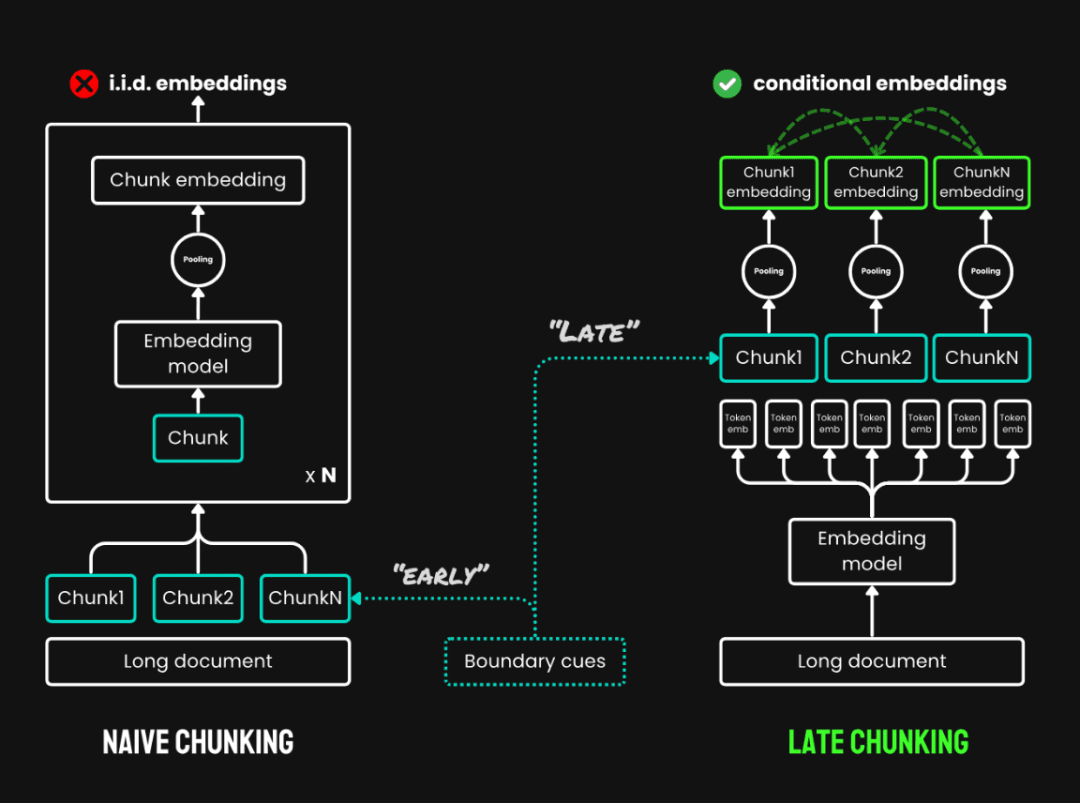
Fractionnement tardif vs. découpage simple
Pour les modèles qui dépassent la longueur maximale d'entrée (par exemple 8192 jetons), nous utilisons le Chunking long et tardifDans le cas de la segmentation tardive, une étape de pré-segmentation est ajoutée au découpage tardif en divisant d'abord le document en plusieurs macroblocs qui se chevauchent, chacun d'entre eux ayant une longueur comprise dans la plage de traitement du modèle. Ensuite, une stratégie standard de découpage tardif (encodage et mise en commun) est appliquée à l'intérieur de chaque macrobloc. Le chevauchement entre les macroblocs est utilisé pour assurer la continuité des informations contextuelles.
Note tardive Code de mise en œuvre spécifique : https://github.com/jina-ai/late-chunking在 Expérience du carnet de notes : https://colab.research.google.com/drive/1iz3ACFs5aLV2O_ uZEjiR1aHGlXqj0HY7?usp=sharing
Quelle est donc la meilleure méthode ?
À des fins de comparaison, nous avons utilisé l'ensemble de données sur 5 ensembles de données, en utilisant la méthode jina-embeddings-v3 Des expériences ont été menées dans lesquelles tous les textes longs ont été tronqués à la longueur d'entrée maximale du modèle (8192 tokens) et segmentés en blocs de texte de 64 tokens chacun.

Les 5 ensembles de données de test correspondent également à 5 tâches de recherche différentes
La figure ci-dessous montre la différence de performance entre les trois méthodes pour différentes tâches. Aucune méthode n'est meilleure dans tous les cas et le choix dépend de la tâche spécifique.
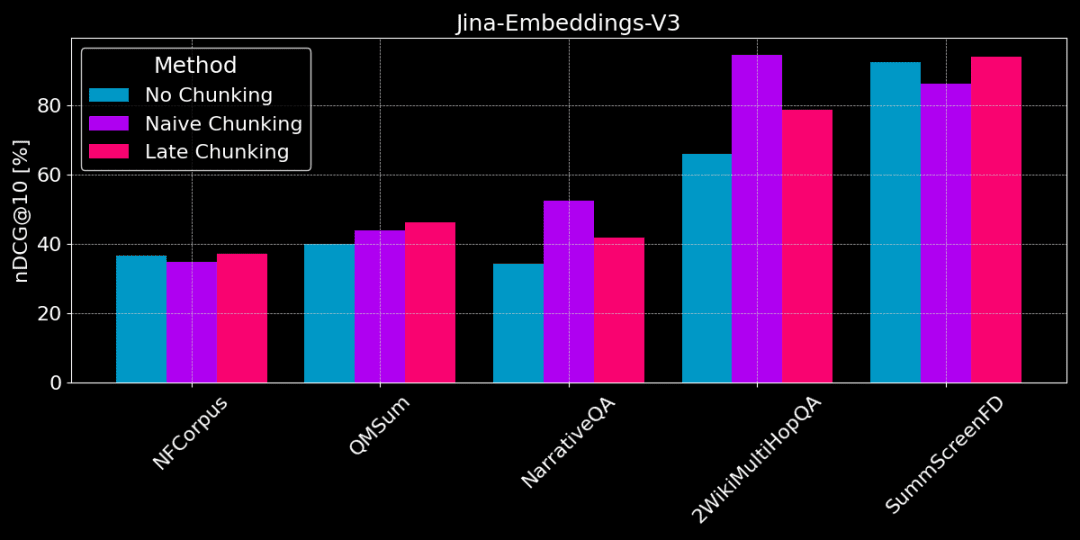
Pas de chunking vs chunking simple vs chunking tardif
👩🏫 Trouvez des faits spécifiques, le découpage simple est une bonne chose.
Si des informations factuelles spécifiques et localisées doivent être extraites du texte (par exemple, "Qui a volé quelque chose ?"), les ensembles de données comme QMSum, NarrativeQA et 2WikiMultiHopQA sont plus performants que la vectorisation du document entier. ), dans des ensembles de données tels que QMSum, NarrativeQA et 2WikiMultiHopQA, le découpage simple est plus performant que la vectorisation de l'ensemble du document. Les réponses étant généralement situées dans une partie spécifique du texte, le découpage simple permet de localiser plus précisément le morceau de texte contenant la réponse sans être distrait par d'autres informations étrangères.
Mais le découpage simple coupe également le contexte et peut perdre des informations globales permettant d'analyser correctement les relations référentielles et les références dans le texte.
👩🏫 L'article est cohérent sur le plan thématique et les notes tardives sont meilleures.
La notation tardive est plus efficace lorsque le sujet est clair et que la structure du texte est cohérente. Comme la division tardive tient compte du contexte, elle permet de mieux comprendre le sens et la pertinence de chaque partie, y compris les relations référentielles au sein des textes longs.
Cependant, si l'article contient beaucoup d'informations non pertinentes, la notation tardive prendra en compte le "bruit" et entraînera une régression des performances et une dégradation de la précision. Par exemple, NarrativeQA et 2WikiMultiHopQA ne sont pas aussi performants que le simple découpage en morceaux, car ces articles contiennent trop d'informations non pertinentes.
La taille du morceau a-t-elle un effet ?
La figure suivante montre les performances des méthodes de découpage simple et de découpage tardif sur différents ensembles de données avec différentes tailles de morceaux :
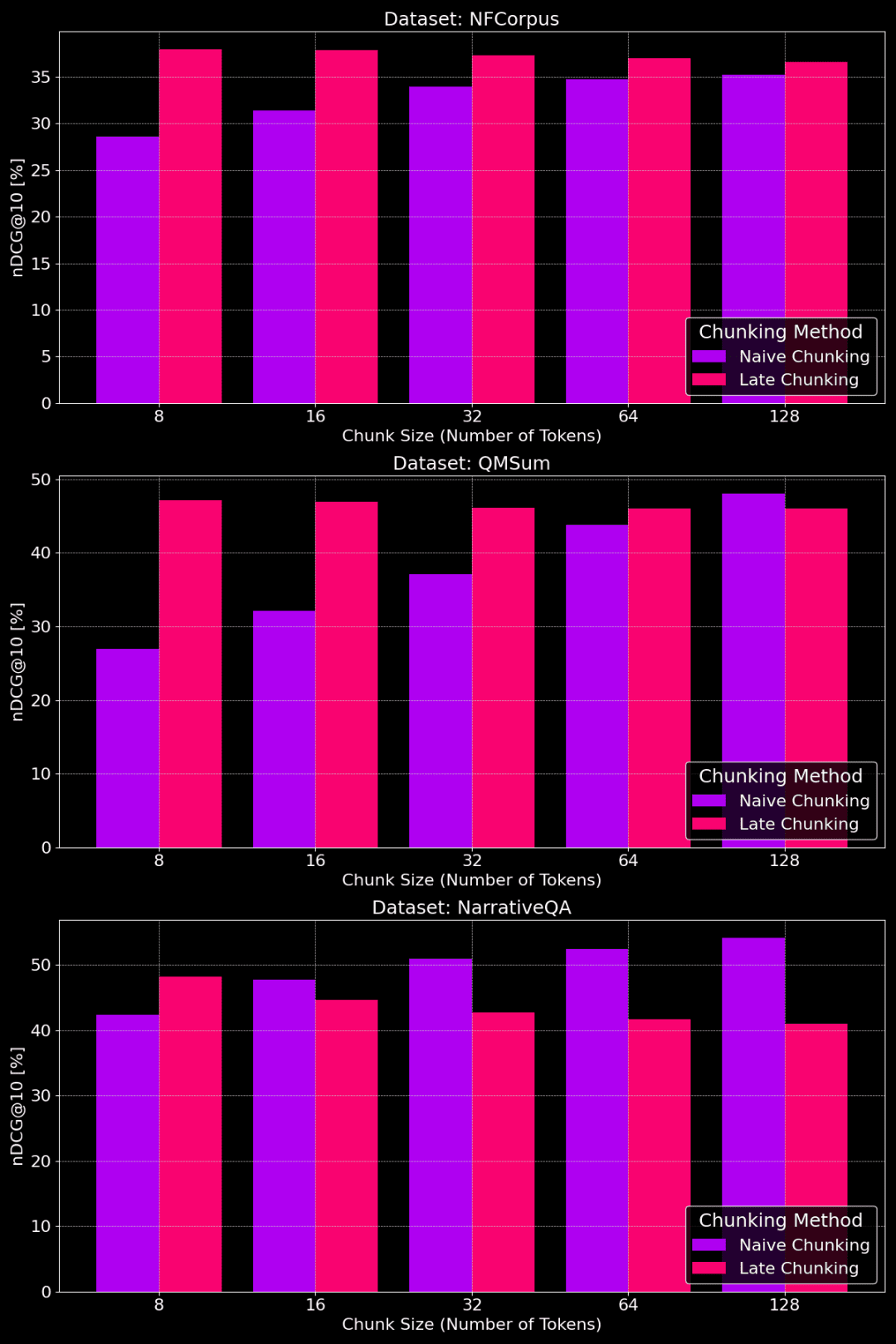
Comparaison des performances du découpage simple et du découpage tardif avec différentes tailles de morceaux
Comme le montre la figure, la taille optimale des morceaux dépend en fait de l'aspect de l'ensemble de données.
Pour la méthode de découpage tardif, les petits morceaux capturent mieux les informations contextuelles et fonctionnent donc mieux. En particulier, si l'ensemble de données contient beaucoup de contenu qui n'est pas lié au sujet (comme dans le cas de l'ensemble de données NarrativeQA), trop de contexte peut introduire du bruit et nuire aux performances.
Dans le cas d'un découpage simple, les gros morceaux sont parfois plus efficaces car les informations qu'ils contiennent sont plus complètes et présentent moins de pertes. Cependant, il arrive que les morceaux soient trop grands et que les informations soient trop encombrées, ce qui réduit la précision de la recherche. La taille optimale des morceaux doit donc être adaptée à l'ensemble de données et à la tâche spécifiques, et il n'existe pas de réponse unique.
Après avoir compris les avantages et les inconvénients des différentes stratégies de découpage, comment choisir la bonne ?
1) Dans quels cas la vectorisation du texte intégral (sans découpage) est-elle appropriée ?
- Le thème est unique et les informations clés sont centrées au début :Par exemple, dans les articles d'actualité structurés, les informations clés se trouvent souvent dans les titres et les premiers paragraphes. Dans ce cas, l'utilisation directe de la vectorisation en texte intégral donne généralement de bons résultats car le modèle capture l'information principale.
- En général, l'introduction d'un maximum de texte dans le modèle n'affecte pas les résultats de la recherche. Toutefois, les modèles de textes longs ont tendance à accorder plus d'attention à la partie initiale (titre, introduction, etc.), et les informations contenues dans les parties centrale et finale peuvent être ignorées. Par conséquent, si l'information clé se trouve au milieu ou à la fin de l'article, cette méthode sera beaucoup moins efficace.
- Les résultats expérimentaux détaillés sont présentés dans le document :https://jina.ai/news/still-need-chunking-when-long-context-models-can-do-it-all
2) Où le Naive Chunking est-il approprié ?
- Variété de sujets, besoin de retrouver des informations spécifiquesSi votre texte contient plus d'un sujet, ou si une requête d'utilisateur cible un fait spécifique dans le texte, le découpage simple est un bon choix. Il permet d'éviter la dilution de l'information et d'améliorer la précision de la recherche d'informations spécifiques.
- Besoin d'afficher des extraits de texte localisésLe moteur de recherche : Comme pour un moteur de recherche, la nécessité d'afficher dans les résultats des extraits de texte liés à la requête impose une stratégie de découpage en morceaux.
- En outre, le découpage en morceaux a une incidence sur l'espace de stockage et le temps de traitement, car il faut vectoriser davantage de blocs de texte.
3) Quelle est la place du "Late Chunking" (découpage tardif) ?
- Cohérence thématique, besoin d'informations contextuellesPour les textes longs avec des sujets cohérents, tels que les essais, les rapports longs, etc., la méthode de partitionnement tardif peut retenir efficacement les informations contextuelles et ainsi mieux comprendre la sémantique globale du texte. Elle est particulièrement adaptée aux tâches qui nécessitent de comprendre la relation entre les différentes parties d'un texte, telles que la compréhension de la lecture et l'appariement sémantique de textes longs.
- Nécessité d'équilibrer les détails locaux avec la sémantique globaleLa méthode du découpage tardif peut équilibrer efficacement les détails locaux et la sémantique globale dans des morceaux de plus petite taille et, dans de nombreux cas, elle peut donner de meilleurs résultats que les deux autres méthodes. Toutefois, il convient de noter que si l'article contient de nombreux contenus non pertinents, le découpage tardif affectera l'effet en raison de la prise en compte de ces informations non pertinentes.
rendre un verdict
Le choix d'une stratégie de vectorisation des textes longs est une question complexe, sans solution unique, qui nécessite la prise en compte des caractéristiques des données et des objectifs de recherche, notamment la longueur du texte, le nombre de sujets et l'emplacement des informations clés.
Dans ce document, nous espérons fournir un cadre d'analyse comparative des différentes stratégies de découpage et fournir des références à travers des résultats expérimentaux. Dans la pratique, vous pouvez comparer d'autres expériences et choisir la stratégie la plus adaptée à votre scénario.
Si vous êtes intéressé par la vectorisation de textes longsjina-embeddings-v3Offrant des capacités avancées de traitement des textes longs, une prise en charge multilingue et une notation tardive, il vaut la peine d'être essayé.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Postes connexes



Pas de commentaires...