DeepSeek Hands-on : Construction d'un graphe de connaissances en trois étapes - Extraction unique, Fusion multiple, Génération de sujets
Question : Les graphes de connaissances sont importants, le modèle de langage DeepSeek est en vogue, peut-il être utilisé pour construire rapidement des graphes de connaissances ? J'aimerais l'essayer. DeepSeek de l'objet réel pour voir s'il est capable d'extraire des informations, d'intégrer des connaissances et de créer des graphiques à partir de rien.
Méthodes : J'ai réalisé trois expériences pour tester les capacités de construction de graphes de connaissances de DeepSeek :
- Cartographie de la construction d'un seul article : Donnez un article à DeepSeek et voyez s'il peut saisir les informations avec précision et construire un graphique.
- Cartographie de fusion d'articles multiples : Donnez à DeepSeek plusieurs articles pour voir s'il peut ajouter de nouvelles connaissances à un graphique existant.
- Cartographie de la génération de thèmes : Indiquez à DeepSeek le sujet de l'atlas, et non celui de l'article, et voyez s'il est capable de créer un atlas tout seul.
Résultats : Les expériences montrent que DeepSeek construit et fusionne bien les graphes de connaissances, mais il y a encore de la place pour l'amélioration.
Voici la procédure exacte et les résultats de l'expérience, que je vais expliciter en termes plus simples.
I. Extraire les connaissances d'un seul article pour construire une carte
Objet : Test de la capacité de DeepSeek à extraire des connaissances d'un article et à construire un graphe de connaissances.
Processus : J'ai trouvé un article sur les bases de données graphiques NebulaGraph et j'ai demandé à DeepSeek de lire l'article, d'extraire les informations clés, puis de générer le code de la base de données NebulaGraph (nGQL) pour créer un graphe de connaissances.
Instructions : "Pouvez-vous m'aider à générer un graphe de connaissances ? Je vous donnerai l'article, vous en extrairez les informations clés et construirez le graphe de connaissances avec le code nGQL".
Fonctionnement : Copiez et collez le contenu de l'article directement sur DeepSeek.
Code nGQL généré par DeepSeek :
# Schema 定义(TAG 类型)
CREATE TAG IF NOT EXISTS product (
name STRING,
description STRING
);
CREATE TAG IF NOT EXISTS company (
name STRING
);
CREATE TAG IF NOT EXISTS feature (
name STRING
);
CREATE TAG IF NOT EXISTS tool (
name STRING
);
CREATE TAG IF NOT EXISTS scenario (
name STRING
);
CREATE TAG IF NOT EXISTS language (
name STRING
);
CREATE TAG IF NOT EXISTS auth_service (
name STRING
);
CREATE TAG IF NOT EXISTS ecosystem (
name STRING
);
# Schema 定义(EDGE 类型)
CREATE EDGE IF NOT EXISTS has_feature ();
CREATE EDGE IF NOT EXISTS used_by ();
CREATE EDGE IF NOT EXISTS provides_tool ();
CREATE EDGE IF NOT EXISTS supports_language ();
CREATE EDGE IF NOT EXISTS applicable_scenario ();
CREATE EDGE IF NOT EXISTS compatible_with ();
CREATE EDGE IF NOT EXISTS supports_auth ();
CREATE EDGE IF NOT EXISTS integrates_with ();
# 数据插入 - 核心产品
INSERT VERTEX product(name, description) VALUES
"NebulaGraph": ("NebulaGraph", "开源的分布式图数据库,支持千亿点万亿边数据集");
# 数据插入 - 产品特性
INSERT VERTEX feature(name) VALUES
"high_performance": ("高性能"),
"open_source": ("开源"),
"scalability": ("易扩展"),
"flexible_modeling": ("灵活数据建模"),
"read_write_balance": ("读写平衡"),
"compatibility": ("查询语言兼容性");
/* ... 此处省略 n多数据 ... */
Résultats : Le code DeepSeek est bon, la syntaxe est correcte et il est efficace en ce sens qu'il combine plusieurs éléments de données en une seule déclaration. Le code est placé dans NebulaGraph pour être exécuté, le graphique ressemble à ceci :
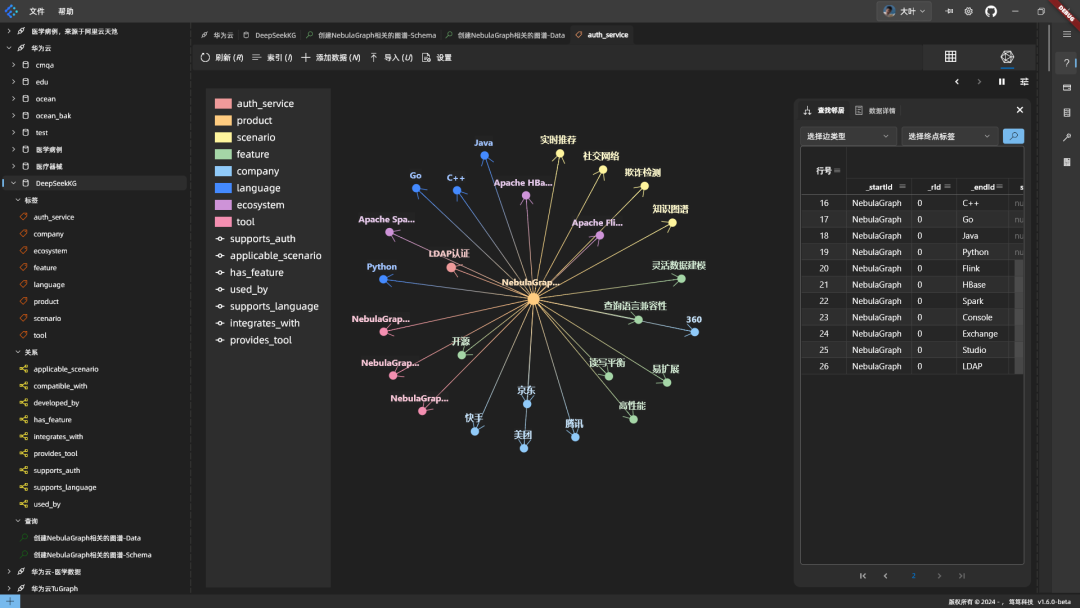
Le graphique est centré sur le NebulaGraph et affiche les informations pertinentes.
II. intégration des connaissances dans plusieurs articles
Objet : Test de la capacité de DeepSeek à fusionner les connaissances de plusieurs articles pour étendre un graphe existant.
Processus : Le graphe est d'abord construit à partir d'un article, puis DeepSeek reçoit d'autres articles sur NebulaGraph (provenant de l'encyclopédie Baidu) afin de fusionner les nouvelles connaissances dans le graphe existant.
Instructions : "Ensuite, un autre article pour vous. Essayez d'harmoniser le mappage avec la structure actuelle de la table. Pour modifier la structure de la table, utilisez la commande ALTER."
Fonctionnement : Les résumés des entrées de NebulaGraph et de l'encyclopédie 360 ont été donnés à DeepSeek, respectivement.
Le code nGQL généré par DeepSeek (lexique NebulaGraph) :
# 结构变更 1:为 product 标签增加版本和时间属性
ALTER TAG product ADD (
license STRING,
current_version STRING,
release_date STRING,
last_updated STRING
);
# 结构变更 2:新增开发关系类型
CREATE EDGE IF NOT EXISTS developed_by();
# 数据更新 - 补充产品属性
INSERT VERTEX product(name, description, license, current_version, release_date, last_updated)
VALUES
"NebulaGraph": ("NebulaGraph", "分布式图数据库", "Apache 2.0", "v3.3.0", "2019-05-15", "2022-11-14");
# 新增开发公司(复用 company 标签)
INSERT VERTEX company(name)
VALUES
"Yueshu": ("杭州悦数科技有限公司");
# 新增特性(复用 feature 标签)
INSERT VERTEX feature(name)
VALUES
"acl_mechanism": ("ACL 机制"),
"linear_scaling": ("线性扩容"),
"data_recovery": ("数据恢复"),
"htap": ("HTAP 混合负载"),
"nGQL_language": ("nGQL 查询语言");
# 关系建立(复用已有关系类型)
INSERT EDGE has_feature()
VALUES
"NebulaGraph"->"acl_mechanism":(),
"NebulaGraph"->"linear_scaling":(),
"NebulaGraph"->"data_recovery":(),
"NebulaGraph"->"htap":(),
"NebulaGraph"->"nGQL_language":();
# 新增开发关系
INSERT EDGE developed_by()
VALUES
"NebulaGraph"->"Yueshu":();
Code nGQL généré par DeepSeek (360 mots) :
# 结构变更 1:为 company 标签增加创始人、成立时间和收入属性
ALTER TAG company ADD (founder STRING, founded_date STRING, revenue DOUBLE);
# 结构变更 2:新增事件类型 TAG
CREATE TAG IF NOT EXISTS event (
type STRING,
date STRING,
amount DOUBLE,
details STRING
);
# 数据更新:补充 360 公司信息
INSERT VERTEX company(name, founder, founded_date, revenue)
VALUES
"360": ("奇虎360", "周鸿祎", "2005-09", 116.15);
# 数据插入:产品生态(复用 product 标签)
INSERT VERTEX product(name)
VALUES
"360_Security_Guard": ("360安全卫士"),
"360_Browser": ("360安全浏览器"),
"360_Cloud": ("360安全云");
# 数据插入:重大事件(使用新增 event 标签)
INSERT VERTEX event(type, date, amount, details)
VALUES
"acquisition_360.com": ("域名收购", "2015-02-04", 1700.0, "1.1亿人民币收购 360.com"),
"privatization": ("私有化", "2015-12", 9300.0, "93 亿美元私有化交易");
# 关系建立:复用 developed_by 边连接产品
Résultats : DeepSeek peut modifier la structure du tableau en fonction du nouvel article (par exemple, en donnant à produit répondre en chantant entreprise (table et champs) et a également ajouté un nouveau type de relation. Il le fait comme il se doit avec l'option ALTER pour modifier la structure du tableau. Le petit problème est que le commentaire utilise la commande --nGQL n'est pas reconnu, modifiez-le manuellement. # En ligne.
Le code est introduit dans la base de données pour exécution, et la cartographie fusionnée fonctionne :
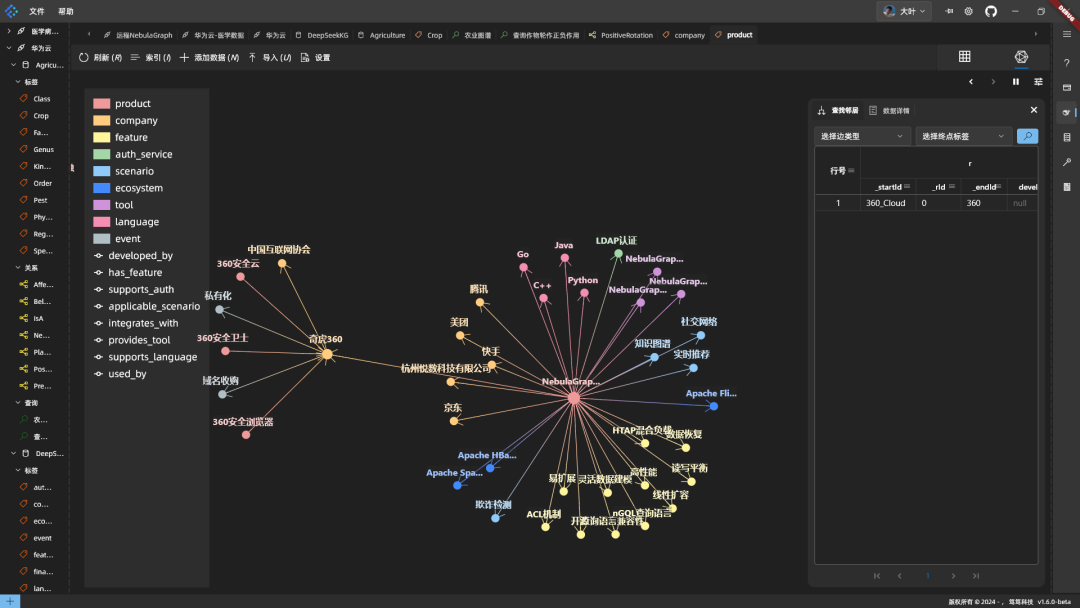
Résumé : DeepSeek est un bon outil pour construire des graphes et fusionner des connaissances. Cependant, le serveur est parfois lent et NebulaGraph modifie le schéma de manière asynchrone, ce qui prend un certain temps avant de prendre effet.
III. génération de thèmes : cartographie agricole à partir de rien
Objet : Tester la capacité de DeepSeek à générer un graphe de connaissances basé sur des sujets sans articles.
Processus : Créez un nouveau dialogue et laissez DeepSeek générer le code de cartographie directement sur le sujet "Agriculture". Aucun article n'est donné, c'est un "free-for-all".
Instructions : "Je veux construire un graphe de connaissances agricoles. Utiliser la base de données NebulaGraph et générer un script nGQL. Les noms des tables sont de grandes bosses, les noms des attributs sont de petites bosses. Les noms des schémas sont entourés de `` pour éviter les conflits. Générer au moins 3000 noeuds."
Code nGQL généré par DeepSeek (partiel) :
# ======================================= #
# 创建图空间
# ======================================= #
CREATE SPACE `Agriculture` (vid_type = FIXED_STRING(32));
USE `Agriculture`;
# ======================================= #
# 定义标签 Schema(大驼峰命名)
# ======================================= #
CREATE TAG IF NOT EXISTS `Crop` (
`cropId` int,
`cropName` string,
`growthPeriod` int,
`suitableTemp` string,
`yieldPerMu` float
);
# ======================================= #
# 此处省略好多脚本
# ======================================= #
Problèmes et améliorations :
- Limite du nombre de nœuds : Avec 3000 noeuds, DeepSeek a refusé et a donné Python pour importer le code CSV. Je ne voulais pas utiliser Python, j'ai donc réduit le nombre de noeuds.
- La question de l'annotation se pose à nouveau : Les commentaires du code sont à nouveau --La question a de nouveau été soulevée.
Instructions d'amélioration : "Utilisez # pour les commentaires, pas de code Python, 3000 nœuds c'est trop. Donnez-moi juste le script ngql pour 50 nœuds".
Dialogue et instructions de suivi : Afin d'affiner la carte, j'ai continué à parler à DeepSeek, lui demandant d'ajouter des données, de renforcer les associations, d'organiser la carte par classification (phylum, ordre, famille, genre et espèce) et de générer des données sur la rotation des cultures.
Par exemple, mes instructions :
- "Données supplémentaires pour des liens plus forts entre les données".
- "Faites un atlas de ces classifications [des phylums, des ordres, des familles, des genres et des espèces].
- "Identifier les contre-indications et intégrer les cultures dans la rotation des cultures existantes.
- "Combinaison de données cartographiées sur les tissus végétaux pour obtenir des scripts nGQL dans le format précédent"
Interlude expérimental : DeepSeek, une fois. INSÉRER utilise la syntaxe Cypher, qui n'est pas supportée par nGQL, et elle a été signalée et modifiée.
Instructions : "Cette instruction d'insertion ne correspond pas à la syntaxe nGQL. Modifiez-la de manière à ce que le DDL soit placé en premier et le DML en second."
Volume de données final : Après quelques tours de table, la quantité de données est affichée :

Effets de cartographie : Développez quelques nœuds au hasard pour voir :
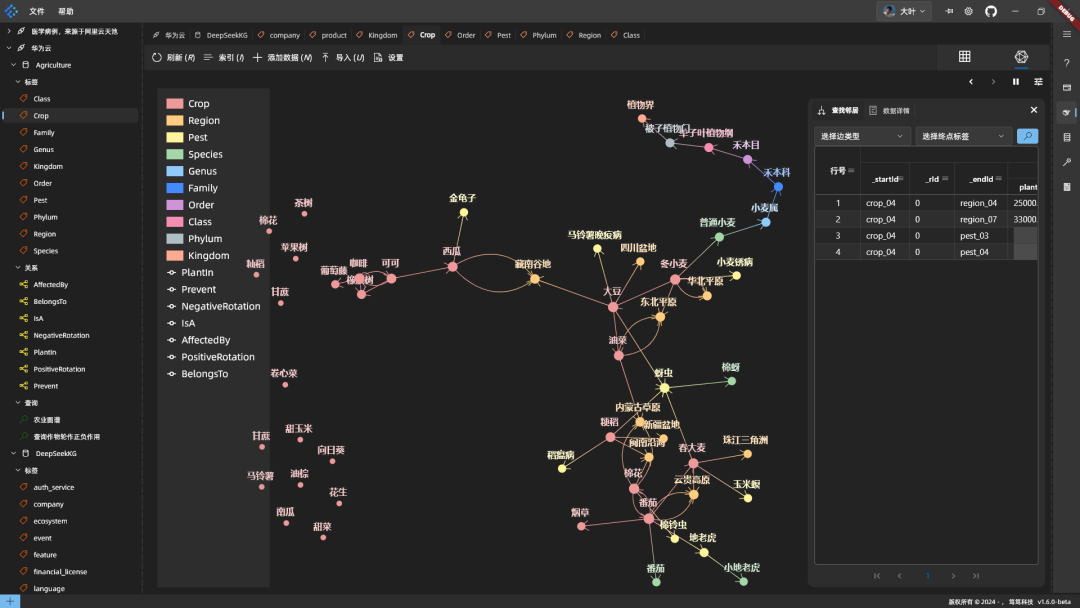
Exemples de combinaisons d'espèces en rotation permettant d'augmenter le rendement : Effets combinatoires de la plantation adventice sur l'amélioration du rendement :
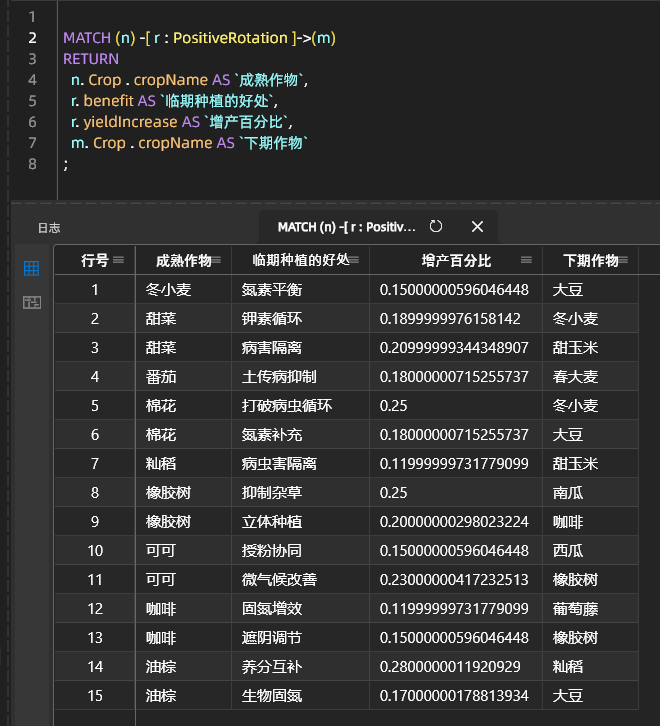
IV. résumé
Conclusion : DeepSeek excelle dans la construction et la fusion de graphes de connaissances, et des expériences démontrent ses capacités :
- L'extraction des informations est rapide et précise : DeepSeek extrait rapidement les informations clés du texte, génère des scripts nGQL conformes et possède une forte compréhension du langage pour reconnaître les entités, les relations et les événements.
- Forte capacité à intégrer les connaissances : DeepSeek fusionne les connaissances de plusieurs articles, développe et met à jour le graphique en fonction des nouveaux articles, et garantit l'exhaustivité et l'exactitude du graphique.
- On peut construire une carte à partir de rien : Aucun article ne peut générer des graphiques par thème. Il y a quelques problèmes de syntaxe dans le processus de génération, mais les ajustements produisent des scripts acceptables.
- Les détails doivent être optimisés : Les scripts générés par DeepSeek présentent parfois des problèmes de syntaxe, tels que des commentaires incorrects. Lors de la génération d'un grand nombre de nœuds, le serveur peut être lent à répondre. Vous devez prêter attention à ces problèmes lorsque vous l'utilisez réellement.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...