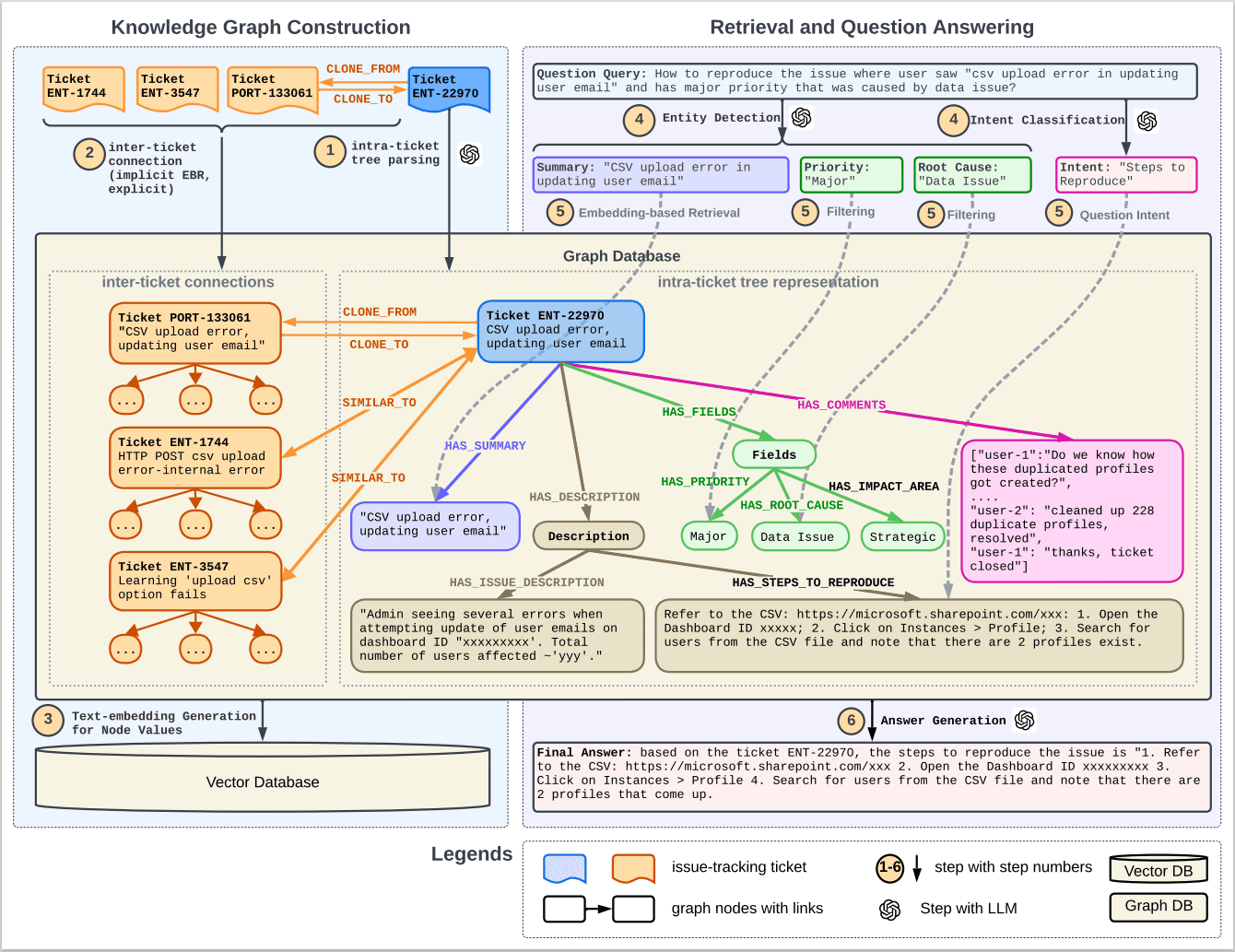
CoD : Chaîne de densité
Texte original :https://arxiv.org/pdf/2309.04269
Lecture rapide :De l'éparse au dense : génération de résumés GPT-4 à l'aide d'indices de densité enchaînés
Recueillis dans :Résumer les connaissances sur les messages-guides couramment utilisés
résumés
Déterminer la "bonne" quantité d'informations à inclure dans un résumé de texte automatisé est une tâche difficile. Un bon résumé doit être détaillé et centré sur l'entité tout en évitant d'être trop long et difficile à comprendre. Pour mieux comprendre ce compromis, nous proposons une méthode de repérage appelée chaîne de densité (CoD), qui permet à GPT-4 de générer des résumés de plus en plus denses. Nous constatons que les résumés générés par la CoD sont plus abstraits, plus convergents et présentent moins de biais d'ouverture que les résumés du GPT-4 générés à l'aide d'indices normaux. À l'aide d'une étude des préférences humaines portant sur 100 articles de CNN/DailyMail, nous constatons que les humains préfèrent les résumés plus denses que les résumés générés par le GPT-4 à l'aide d'invites normales, et que leur densité est presque comparable à celle des résumés rédigés manuellement.
1. introduction
Les techniques de résumé automatique ont beaucoup progressé ces dernières années, en grande partie grâce au changement de paradigme, qui est passé d'un réglage fin supervisé à des messages-guides à zéro échantillon utilisant des modèles de langage à grande échelle (LLM). Par exemple, GPT-4 peut contrôler finement les caractéristiques du résumé (par exemple, la longueur, le sujet et le style) à l'aide d'indices bien conçus sans formation supplémentaire.
Cependant, la densité d'information d'un résumé est un aspect souvent négligé. Théoriquement, en tant que compression d'un autre texte, un résumé devrait contenir une plus grande concentration d'informations que le document source. Cependant, la densité d'un résumé est une question ouverte. Si un résumé ne contient pas suffisamment d'informations, il sera sans conséquence ; s'il contient trop d'informations, il peut devenir difficile à comprendre sans pour autant augmenter la longueur du texte. Pour communiquer davantage d'informations dans le cadre d'un budget symbolique fixe, il faut combiner l'abstraction, la compression et la fusion. Il y a une limite à l'espace que l'on peut accorder aux informations supplémentaires avant qu'elles ne deviennent incompréhensibles ou même incorrectes.
2. les indices de densité enchaînés (CoD)
2.1 Objectifs
Notre objectif était de générer un ensemble de résumés GPT-4 avec différentes densités d'information tout en contrôlant la longueur, qui s'est avérée être un facteur de confusion important lors de l'évaluation des résumés. À cette fin, nous avons conçu un indice unique de densité en chaîne (CoD) par lequel un résumé initial est généré et rendu progressivement plus dense dans les entités. Plus précisément, pour un nombre fixe de tours, un ensemble unique d'entités saillantes est identifié à partir du texte source et fusionné avec le résumé précédent sans en augmenter la longueur. Le premier résumé est pauvre en entités puisqu'il ne se concentre que sur 1 à 3 entités initiales.
2.2 Données
Nous avons sélectionné au hasard 100 articles de l'ensemble de tests de résumés CNN/DailyMail pour générer des résumés CoD.
2.3 Points de référence
À titre de comparaison, nous avons comparé les statistiques des résumés de la CdC avec celles des résumés de référence à puces rédigés manuellement et des résumés GPT-4 générés à l'aide d'invites communes :
- Conseils ordinairesLe texte de l'article est le suivant : "Rédigez un très bref résumé de l'article en 70 mots maximum.
Nous avons fixé la longueur du jeton requis pour qu'elle corresponde à la longueur du condensé de CdC (comme indiqué dans le tableau ci-dessous).
2.4 Exemples de conseils
Vous trouverez ci-dessous un exemple d'invite CoD :
请生成一个非常简短的摘要,不超过70个单词。然后,逐步添加1-3个缺失的重要实体,而不增加长度。
Exemple d'une invite CoD complète (en anglais).
Article: {{ ARTICLE }}
You will generate increasingly concise, entity-dense summaries of the above article.
Repeat the following 2 steps 5 times.
Step 1. Identify 1-3 informative entities (";" delimited) from the article which are missing from the previously generated summary.
Step 2. Write a new, denser summary of identical length which covers every entity and detail from the previous summary plus the missing entities.
A missing entity is:
- relevant to the main story,
- specific yet concise (5 words or fewer),
- novel (not in the previous summary),
- faithful (present in the article),
- anywhere (can be located anywhere in the article).
Guidelines:
- The first summary should be long (4-5 sentences, ~80 words) yet highly non-specific, containing little information beyond the entities marked as missing. Use overly verbose language and fillers (e.g., "this article discusses") to reach ~80 words.
- Make every word count: rewrite the previous summary to improve flow and make space for additional entities.
- Make space with fusion, compression, and removal of uninformative phrases like "the article discusses".
- The summaries should become highly dense and concise yet self-contained, i.e., easily understood without the article.
- Missing entities can appear anywhere in the new summary.
- Never drop entities from the previous summary. If space cannot be made, add fewer new entities.
Remember, use the exact same number of words for each summary.
Answer in JSON. The JSON should be a list (length 5) of dictionaries whose keys are "Missing_Entities" and "Denser_Summary".
Explication des indices.
Ce mot clé CoD détaillé est conçu pour guider le GPT-4 vers la génération progressive de résumés plus denses, l'idée principale étant d'ajouter de nouvelles entités clés au résumé à chaque tour par le biais d'un processus itératif, tout en maintenant la longueur du résumé constante. Décortiquons les différentes parties de ce mot-clé :
Article: {{ ARTICLE }}: Il s'agit d'un espace réservé pour le contenu de l'article que vous souhaitez résumer.{{ ARTICLE }}.You will generate increasingly concise, entity-dense summaries of the above article.: C'est le cœur de la directive, qui indique au modèle que l'objectif est de générer des résumés de plus en plus concis et denses en termes d'entités.Repeat the following 2 steps 5 times.Le nombre d'itérations est de 5, ce qui signifie que le modèle répétera les deux étapes suivantes pendant cinq tours, en augmentant progressivement la densité des résumés.Step 1. Identify 1-3 informative entities (";" delimited) from the article which are missing from the previously generated summary.: Étape 1 : Identifier les entités manquantes. Le modèle doit identifier une à trois entités informatives de l'article original, qui ne doivent pas être apparues dans les résumés générés précédemment. Les entités sont séparées par des points-virgules;Séparation.Step 2. Write a new, denser summary of identical length which covers every entity and detail from the previous summary plus the missing entities.: Étape 2 : Générer un résumé plus dense. Le modèle doit générer un nouveau résumé basé sur le résumé précédent, en incorporant les entités manquantes identifiées à l'étape 1. Il est essentiel que le nouveau résumé ait exactement la même longueur que le précédent, ce qui oblige le modèle à comprimer et à fusionner les informations pour intégrer les nouvelles entités.A missing entity is:: : définit des critères pour les "entités manquantes" afin de s'assurer que les entités sélectionnées sont de grande qualité et pertinentes :- relevant to the main storyLe contenu de l'article : Il est lié à l'histoire principale de l'article.- specific yet concise (5 words or fewer): Spécifiques et concis, pas plus de cinq mots.- novel (not in the previous summary): Non présent dans les résumés précédents.- faithful (present in the article)Le texte de l'article doit être réel.- anywhere (can be located anywhere in the article)Les informations peuvent être situées à n'importe quel endroit de l'article.
Guidelines:Le modèle peut être utilisé pour la génération de résumés, mais il ne peut pas être utilisé pour la génération d'un résumé :- The first summary should be long (4-5 sentences, ~80 words) yet highly non-specific...: Orientations pour le premier résuméLe premier résumé doit être plus long (~80 mots, 4-5 phrases) mais moins informatif, dans le but principal de préparer le terrain pour les itérations suivantes. Le langage redondant et les mots de remplissage peuvent être utilisés.- Make every word count: rewrite the previous summary to improve flow and make space for additional entities.: Rationalisation de la langue: L'accent est mis sur la nécessité de réécrire les résumés précédents afin d'optimiser l'expression linguistique et de faire de la place pour l'inclusion de nouvelles entités.- Make space with fusion, compression, and removal of uninformative phrases like "the article discusses".: technique de mise à l'échelle de l'espace: : Indiquer explicitement l'utilisation de techniques telles que la fusion, la compression et l'élimination des phrases non informatives pour comprimer les résumés.- The summaries should become highly dense and concise yet self-contained, i.e., easily understood without the article.: Résumé des objectifs de qualitéLe résumé final doit être très dense et concis, mais aussi autonome, c'est-à-dire que le contenu du résumé peut être compris sans lire le texte original.- Missing entities can appear anywhere in the new summary.: emplacement physiqueLes entités nouvellement ajoutées peuvent apparaître n'importe où dans le nouveau résumé.- Never drop entities from the previous summary. If space cannot be made, add fewer new entities.: Réservations d'entitésLes entités des résumés précédents ne doivent jamais être supprimées. S'il n'y a pas assez d'espace, de nouvelles entités peuvent être ajoutées avec parcimonie.- Remember, use the exact same number of words for each summary.: uniforme: Insister à nouveau sur la nécessité d'une certaine cohérence dans la longueur des résumés générés à chaque tour.Answer in JSON. The JSON should be a list (length 5) of dictionaries whose keys are "Missing_Entities" and "Denser_Summary".: format de sortieLe JSON doit être une liste de 5 dictionnaires, chacun contenant les clés "Missing_Entities" (entités manquantes ajoutées au cours de ce cycle) et "Denser_Summary" (résumé plus dense généré au cours de ce cycle).

Figure 1: : Conseils sur la densité en chaîne (CoD) et exemple de résultat. À chaque étape, 1 à 3 détails supplémentaires (entités) sont ajoutés au résumé précédent sans en augmenter la longueur. Le contenu existant est réécrit (par exemple, compressé, fusionné) afin de faire de la place aux nouvelles entités. La moitié des annotateurs (2/4) ont préféré l'avant-dernier résumé et les autres ont préféré le dernier.
Exemple d'utilisation réelle des mots-clés de la CdC :
Supposons que nous disposions d'un article de presse sur "la visite du président américain Joe Biden en Pologne" et que nous souhaitions générer une série de résumés de différentes densités à l'aide d'indices CoD.
Étape 1 : Préparer la saisie de l'article
Tout d'abord, nous devons préparer le contenu de l'article de presse, par exemple :
美国总统乔·拜登 неожиданно 抵达波兰进行访问,与波兰总统安杰伊·杜达举行会晤。此次访问正值俄乌冲突一周年之际,预计两国领导人将讨论地区安全、对乌克兰的进一步支持以及加强北约东翼等议题。拜登的访问是对波兰在支持乌克兰难民和向乌克兰提供军事援助方面所做努力的肯定。此外,拜登还计划在华沙就俄乌冲突发表重要讲话,并会见在波兰的美军士兵。
Étape 2 : Élaborer la demande d'API (exemple de l'API OpenAI)
Nous utiliserons l'API OpenAI (ou une autre API prenant en charge le modèle GPT-4) pour envoyer la requête. Le corps de la requête contiendra notre mot-clé CoD et le mot-clé {{ ARTICLE }} Remplacez-la par le contenu de l'article préparé.
{
"model": "gpt-4",
"prompt": "Article: 美国总统乔·拜登 неожиданно 抵达波兰进行访问,与波兰总统安杰伊·杜达举行会晤。此次访问正值俄乌冲突一周年之际,预计两国领导人将讨论地区安全、对乌克兰的进一步支持以及加强北约东翼等议题。拜登的访问是对波兰在支持乌克兰难民和向乌克兰提供军事援助方面所做努力的肯定。此外,拜登还计划在华沙就俄乌冲突发表重要讲话,并会见在波兰的美军士兵。\nYou will generate increasingly concise, entity-dense summaries of the above article.\n\nRepeat the following 2 steps 5 times.\n\nStep 1. Identify 1-3 informative entities (\";\" delimited) from the article which are missing from the previously generated summary.\nStep 2. Write a new, denser summary of identical length which covers every entity and detail from the previous summary plus the missing entities.\n\nA missing entity is:\n- relevant to the main story, \n- specific yet concise (5 words or fewer), \n- novel (not in the previous summary), \n- faithful (present in the article), \n- anywhere (can be located anywhere in the article).\n\nGuidelines:\n\n- The first summary should be long (4-5 sentences, ~80 words) yet highly non-specific, containing little information beyond the entities marked as missing. Use overly verbose language and fillers (e.g., \"this article discusses\") to reach ~80 words.\n- Make every word count: rewrite the previous summary to improve flow and make space for additional entities.\n- Make space with fusion, compression, and removal of uninformative phrases like \"the article discusses\".\n- The summaries should become highly dense and concise yet self-contained, i.e., easily understood without the article. \n- Missing entities can appear anywhere in the new summary.\n- Never drop entities from the previous summary. If space cannot be made, add fewer new entities. \n\nRemember, use the exact same number of words for each summary.\nAnswer in JSON. The JSON should be a list (length 5) of dictionaries whose keys are \"Missing_Entities\" and \"Denser_Summary\".",
"max_tokens": 1000, // 确保模型有足够的token生成完整JSON输出
"temperature": 0.7// 可调整temperature控制生成结果的随机性
}
Étape 3 : Envoi d'une requête API et réception d'une réponse JSON
Envoyez la requête JSON ci-dessus au point de terminaison de l'API OpenAI. L'API renvoie une réponse au format JSON contenant un résumé des cinq densités différentes et des entités manquantes ajoutées à chaque étape.
Étape 4 : Analyse de la réponse JSON et utilisation du condensé
Analyse la réponse JSON renvoyée par l'API. Vous obtiendrez une liste JSON, similaire à :
{
"Missing_Entities": [],
"Denser_Summary": "This article discusses a visit. It is about a president visiting a country. The president is American. The country is Poland. This is related to international relations. The visit is happening during a time of conflict. This conflict involves Russia and Ukraine. The visit aims to show support and discuss important matters. More details will be provided."
},
{
"Missing_Entities": ["Joe Biden"; "Andrzej Duda"],
"Denser_Summary": "U.S. President Joe Biden visited Poland and met with Polish President Andrzej Duda. This visit is about international relations and is happening during the Russia-Ukraine conflict. They will discuss support and security. More details are expected."
},
{
"Missing_Entities": ["one-year anniversary of the Russia-Ukraine conflict"; "regional security"; "support for Ukraine"],
"Denser_Summary": "U.S. President Joe Biden met Polish President Andrzej Duda in Poland on the one-year anniversary of the Russia-Ukraine conflict. They discussed regional security and support for Ukraine, focusing on international relations."
},
{
"Missing_Entities": ["strengthening NATO's eastern flank"; "support for Ukrainian refugees"; "military aid to Ukraine"],
"Denser_Summary": "On the Russia-Ukraine conflict's one-year anniversary, U.S. President Joe Biden visited Poland, meeting President Andrzej Duda to discuss regional security, support for Ukraine (including refugees and military aid), and strengthening NATO's eastern flank."
},
{
"Missing_Entities": ["Warsaw"; "major speech"; "U.S. troops in Poland"],
"Denser_Summary": "To mark the Russia-Ukraine conflict's one-year mark, U.S. President Joe Biden visited Warsaw, Poland, meeting President Andrzej Duda to discuss regional security, Ukrainian refugee and military aid support, strengthening NATO's eastern flank, and Biden's planned major speech and meeting with U.S. troops in Poland."
}
]
Vous pouvez choisir la bonne densité de résumés en fonction de vos besoins. Par exemple, si vous avez besoin d'un résumé très court, vous pouvez choisir le premier ou le deuxième ; si vous avez besoin d'un résumé plus détaillé mais toujours concis, vous pouvez choisir le quatrième ou le cinquième.
Scénarios d'application pratique :
- Agrégation de nouvelles et recommandation de contenu : fournir différentes densités de résumés pour différents utilisateurs ou plateformes afin de répondre à différents besoins d'information.
- Recherche d'informations : afficher différentes densités de résumés dans les résultats de recherche pour aider les utilisateurs à juger rapidement de la pertinence des articles.
- Aide à la compréhension de la lecture : aide le lecteur à comprendre le contenu du texte du début à la fin en augmentant progressivement la densité des résumés.
- Génération de contenu pour les médias sociaux : générer des résumés de différentes longueurs et densités pour différentes plateformes de médias sociaux (par exemple, Twitter, Facebook).
Grâce aux étapes ci-dessus, vous pouvez utiliser efficacement les mots-clés CoD dans la pratique pour générer des résumés de texte de haute qualité et à densité multiple avec le GPT-4.
3. données statistiques
3.1 Statistiques directes
Dans le tableau 1, nous calculons les tokens à l'aide de NLTK, mesurons les entités uniques à l'aide de Spacy et calculons les densités d'entités sous forme de ratios. En fait, la deuxième étape conduit à une réduction moyenne de 5 tokens (de 72 à 67) car les mots inutiles sont supprimés du résumé initialement long. La densité des entités a augmenté, passant d'un niveau initial de 0,089, inférieur à celui de l'humain et du GPT-4 normal (0,151 et 0,122, respectivement), à 0,167 après cinq étapes de densification.
| Les étapes de CoD | Jeton | chose qui a une existence matérielle (par opposition à une existence conceptuelle, virtuelle ou en ligne) | Densité (E/T) |
|---|---|---|---|
| 1 | 72 | 6.4 | 0.089 |
| 2 | 67 | 8.7 | 0.129 |
| 3 | 67 | 9.9 | 0.148 |
| 4 | 69 | 10.8 | 0.158 |
| 5 | 72 | 12.1 | 0.167 |
| humanité | 60 | 8.8 | 0.151 |
| Général GPT-4 | 70 | 8.5 | 0.122 |
3.2 Statistiques indirectes
À chaque étape de la CdC, l'abstraction devrait augmenter puisque le résumé est réécrit à plusieurs reprises pour faire de la place à chaque entité supplémentaire. Nous mesurons l'abstraction à l'aide de la densité d'extraction : la longueur moyenne au carré des fragments extraits. De même, le niveau de fusion devrait augmenter de façon monotone au fur et à mesure que des entités sont ajoutées à un résumé de longueur fixe. Nous mesurons la fusion comme le nombre moyen de phrases sources alignées pour chaque phrase du résumé. Pour l'alignement, nous utilisons la méthode du gain relatif de ROUGE, qui aligne les phrases sources sur les phrases cibles jusqu'à ce que le gain relatif de ROUGE des phrases ajoutées ne soit plus positif. Nous nous attendons également à ce que la distribution du contenu - la position dans l'article d'où provient le contenu du résumé - change. Plus précisément, nous nous attendons à ce que les résumés CoD présentent initialement un fort biais d'ouverture (Lead Bias), mais commencent progressivement à introduire des entités provenant du milieu et de la fin de l'article. Pour mesurer cela, nous utilisons l'alignement dans la fusion et mesurons le rang moyen des phrases de toutes les phrases sources alignées. La figure 2 confirme ces hypothèses : au fur et à mesure que l'étape de réécriture augmente, l'abstraction augmente (panneau de gauche), le taux de fusion augmente (panneau du milieu) et les résumés commencent à inclure du contenu provenant du milieu et de la fin de l'article (panneau de droite). Il est intéressant de noter que tous les résumés CoD sont plus abstraits que les résumés rédigés manuellement et les résumés de référence.

Figure 2Les résumés générés par CoD deviennent de plus en plus abstraits, tout en montrant plus de convergence et moins de biais de départ.
4. résultats
4.1 Préférences humaines
Pour mieux comprendre les compromis présentés par les résumés de CdC, nous avons mené une étude basée sur les préférences avec une évaluation de la notation du GPT-4.
| Les étapes de CoD | Pourcentage de votes de première place (un seul annotateur) | faire le total | ||
|---|---|---|---|---|
| 1 | 3.0 2.0 | 13.0 | 17.4 | 8.3 |
| 2 | 25.0 28.0 | 43.0 | 31.4 | 30.8 |
| 3 | 22.0 28.0 21.0 | 24.4 | 23.0 | |
| 4 | 29.0 25.0 13.0 | 26.7 | 22.5 | |
| 5 | 21.0 17.0 10.0 | 16.3 | 15.5 |
Tableau 1Les préférences combinées sont les suivantes : CoD résumé des pourcentages de votes à la première place par étape. Sur la base des préférences combinées, les étapes du CdD ont une pluralité de 2, une médiane de 3 et une valeur attendue de 3,06.
Tout d'abord, nous signalons une faible valeur de 0,112 pour le kappa de Fleiss (Fleiss, 1971), ce qui suggère que les différences subtiles entre les résumés et la nature de la tâche sont subjectives. Des études récentes ont également noté un faible accord au niveau de l'instance lors de l'évaluation des résumés basés sur le GPT (Goyal et al., 2022).
Toutefois, au niveau du système, certaines tendances commencent à se dessiner. Pour 3 des 4 annotateurs, l'étape 1 du CdD a reçu la plus grande part des votes de première place sur 100 exemples (28%, 43% et 31,4%, respectivement). Cependant, le résumé de 61% (23,0+22,5+15,5) en première position impliquait ≥3 étapes de densification. Le nombre médian d'étapes CoD préférées se situait au milieu (3), avec une étape souhaitée de 3,06.
Sur la base de la densité moyenne des résumés de l'étape 3, nous pouvons déduire approximativement que la densité de l'entité préférée parmi les candidats à la CdC est d'environ 0,15. Comme nous pouvons le voir dans le tableau 1, cette densité est cohérente avec les résumés rédigés manuellement (0,151), mais significativement plus élevée que les résumés générés à l'aide de l'invite normale du GPT-4 (0,122).
4.2 Indicateurs automatiques
En tant qu'évaluateur, il a été démontré que le GPT-4 s'aligne correctement sur le jugement humain (Fu et al., 2023 ; Liu et al., 2023a) et peut même être plus performant que les travailleurs de la foule pour certaines tâches d'annotation (Gilardi et al., 2023). En complément de notre évaluation humaine, nous avons demandé au GPT-4 d'évaluer les résumés de CdC sur une échelle de 1 à 5 selon les dimensions suivantes : quantité d'informations, qualité, cohérence, attribuabilité et globalité. Les définitions de l'informativité, de la qualité et de l'attribuabilité sont tirées de Aharoni et al. (2023), tandis que la cohérence est tirée de Fabbri et al. (2021). L'objectif global est de saisir la qualité conjointe. Voir l'annexe A pour les astuces utilisées pour obtenir des scores pour chaque dimension. Le tableau 3 montre que la densification est corrélée à l'informativité, mais qu'il y a une limite, les scores atteignant leur maximum à l'étape 4 (4,74). Les dimensions relatives à l'absence d'article, à savoir la qualité et la cohérence, ont diminué après les étapes 2 et 1, respectivement. Tous les résumés ont été considérés comme attribuables à l'article source. Les scores globaux étaient biaisés en faveur des résumés plus denses et plus informatifs, avec les scores les plus élevés à l'étape 4. En moyenne, la première et la dernière étape du CdD ont été les moins appréciées, tandis que les trois étapes intermédiaires ont obtenu des scores proches (4,78, 4,77 et 4,76, respectivement).
Dans l'annexe A, nous indiquons la corrélation la plus élevée entre les résumés et le jugement humain (corrélation de Pearson de 0,31), mais nous notons que la corrélation globale reste faible - un phénomène également observé dans l'étude de Deutsch et al. (2022) lorsque les résumés étaient de qualité similaire.
4.3 Analyse qualitative
Il existe un compromis évident entre la cohérence/lisibilité des résumés et la quantité d'informations qu'ils contiennent. Pour illustrer ce point, la figure 4 présente deux étapes de CdD : un résumé est amélioré par davantage de détails et l'autre est compromis. En moyenne, c'est le résumé CoD du milieu qui atteint le mieux cet équilibre, mais nous laissons aux travaux futurs le soin de définir et de quantifier précisément ce compromis.

Figure 4Exemples d'étapes de densification préférées par l'homme (à gauche) et exemple d'étapes non préférées (à droite). Pour l'exemple de gauche, le résumé du bas est préféré parce que l'ajout de "Liverpool" et du buteur est pertinent pour le sujet. Le deuxième résumé permet une compression judicieuse, par exemple en synthétisant les "voies potentielles pour revenir dans le match" en "contre-attaques". Pour la droite, l'ajout de détails sur "TVMonde" ne compense pas la fusion maladroite d'entités ("Cyber Attack" et "Yves Bigot"), qui est le résultat direct de la nécessité de resserrer le texte. qui résulte directement de la nécessité de resserrer le résumé précédent.
5. travaux connexes
Résumé GPT
Goyal et al. (2022) ont comparé GPT-3 à la génération de résumés d'articles de presse et ont constaté que les humains préféraient les résumés de GPT-3 à une base de référence supervisée antérieure, qui ne reflétait pas les métriques existantes basées sur les références et sans référence. Zhang et al. (2023) ont constaté qu'en sollicitant des résumés de haute qualité auprès de pigistes, les résumés GPT-3 à zéro échantillon étaient comparables à la performance humaine.
Synthèse par entité
Narayan et al. (2021) proposent de générer des chaînes d'entités en tant qu'étape de planification pour l'affinement supervisé du modèle de résumé, contrairement aux mots clés (Li et al., 2020 ; Dou et al., 2021) ou aux unités purement extraites (Dou et al., 2021 ; Adams et al., 2023a). Des entités ont également été incluses dans des extraits comme forme de contrôle (Liu et Chen, 2021 ; He et al., 2022 ; Maddela et al., 2022) pour accroître la fidélité (Nan et al., 2021 ; Adams et al., 2022) et comme unités d'évaluation (Cao et al., 2022 ; Adams et al., 2023b).
6. conclusion
Nous avons étudié l'effet de la densification des résumés sur les préférences humaines en matière de qualité globale. Nous avons constaté qu'un certain niveau de densification est bienvenu, mais qu'il est difficile de maintenir la lisibilité et la cohérence lorsque les résumés contiennent trop d'entités. Nous avons mis en libre accès l'ensemble de test avec annotations ainsi qu'un ensemble d'entraînement plus important non annoté afin d'étudier plus avant le sujet des résumés de longueur fixe et de densité variable.
7. les limites
Nous n'avons analysé les CoDs que pour un seul domaine, à savoir les résumés de nouvelles. Les annotations ne montrent pas de cohérence au niveau des résumés, mais commencent à montrer des tendances au niveau du système, ce qui est cohérent avec les travaux précédents sur les évaluations basées sur le LLM (Goyal et al., 2022). Enfin, GPT-4 est un modèle à source fermée, nous n'avons donc pas pu partager les poids du modèle. Cependant, nous avons publié toutes les données d'évaluation, les annotations et 5 000 CoD non annotés pour des cas d'utilisation en aval, par exemple, l'extraction de densités dans des modèles à source ouverte tels que LLAMA-2 (Touvron et al., 2023).
bibliographie
(liste de références omise ici)
Indicateurs GPT-4
Pour l'évaluation de style Likert du GPT-4, nous utilisons le modèle de question suivant.
摘要: {{摘要}} {{定义}}
Les exemples suivants illustrent les définitions fournies pour chaque indicateur de qualité.
- volume d'informations: : Les résumés informatifs reprennent les informations importantes de l'article et les présentent de manière précise et concise.
- masse (en physique)Les résumés de haute qualité sont faciles à comprendre.
- cohérenceLes résumés cohérents sont bien structurés et organisés.
- attribuableLe résumé : Toutes les informations contenues dans le résumé sont-elles entièrement attribuables à l'article ?
- préférence généraleRésumé : Un bon résumé doit transmettre les idées principales de l'article de manière concise, logique et cohérente.
Les indices de qualité et de cohérence ne comprennent pas les indices dans les articles. Ces définitions ont été adaptées à partir de travaux antérieurs sur l'annotation des résumés : (Fabbri et al., 2021 ; Aharoni et al., 2023).
| dimension (math.) | pertinence |
|---|---|
| volume d'informations | 0.215 |
| masse (en physique) | 0.120 |
| cohérence | 0.178 |
| attribuable | 0.245 |
| population (statistiques) | 0.311 |
Tableau 2Coefficients de corrélation de Pearson au niveau du résumé entre les préférences humaines et les scores de Likert du GPT-4.
méta-évaluation
Pour calculer les corrélations au niveau du résumé, nous avons d'abord converti les données de préférence en un vecteur indiquant le nombre de fois où le résumé a reçu un vote de première place. Le tableau 4 montre que, sans surprise, les indices conçus pour capturer les évaluations globales des résumés présentent la corrélation de Pearson la plus élevée au niveau global avec les préférences globales (0,31), mais la corrélation globale reste faible.
résumés
Cet article étudie la manière dont le GPT-4 peut être utilisé pour générer des résumés de plus en plus denses par le biais de la méthode Chained Density Cueing (CoD). Il constate qu'un certain niveau de densification améliore la qualité des résumés, mais qu'une densité trop importante nuit à la lisibilité et à la cohérence. L'équipe de recherche a validé cette conclusion au moyen d'études sur les préférences humaines et d'une évaluation automatisée GPT-4, et a mis en libre accès les données de résumé annotées et non annotées correspondantes, fournissant ainsi une ressource précieuse pour les recherches futures.
Résumé des points clés :
- Repères de densité enchaînés (CoD)Les résumés : Générer des résumés plus denses en ajoutant progressivement les entités manquantes sans augmenter la longueur du résumé.
- densité physiqueLa densité d'entités comme mesure de l'informativité des résumés a permis de constater que les préférences humaines se rapprochent de la densité des résumés rédigés manuellement.
- Abstraction et intégrationLe CoD génère des résumés plus abstraits et convergents, avec moins de biais de départ.
- préférence humaineLes humains préfèrent les résumés GPT-4 plus denses que la normale, mais une trop grande densité réduit la lisibilité.
- Évaluation automatiséeLes résultats de l'évaluation automatisée du GPT-4 étaient généralement cohérents avec les préférences humaines, mais la corrélation globale était faible.
Orientations futures de la recherche :
- Une définition plus précise des compromis: : De futures recherches pourraient définir et quantifier davantage le compromis entre le contenu de l'information et la lisibilité.
- Applications pluridisciplinaires: appliquer la méthodologie CoD à d'autres domaines, tels que les articles universitaires, la documentation technique, etc. afin de valider sa généralisation.
- Amélioration de la modélisation: : Explorer comment la modélisation peut être améliorée afin d'accroître la lisibilité tout en conservant un niveau élevé d'information.
Cet article montre que l'IA a fait des progrès impressionnants dans le traitement et la génération de textes, mais qu'elle doit encore relever le défi de trouver un équilibre entre le contenu de l'information et la lisibilité. À l'avenir, à mesure que la technologie continuera de progresser, nous avons des raisons de croire que les résumés générés par l'IA seront encore plus intelligents et plus conviviaux.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...