
Déploiement local des grands modèles QwQ-32B : un guide simple pour les PC
Le domaine de la modélisation de l'intelligence artificielle (IA) est toujours plein de surprises, et chaque percée technologique peut toucher les nerfs de l'industrie. Récemment, l'équipe QwQ d'Alibaba a publié son dernier modèle d'inférence, QwQ-32B, aux petites heures du matin, ce qui a une fois de plus attiré beaucoup d'attention.

Selon le communiqué officielQwQ-32B est un modèle d'inférence avec une échelle de paramètres de seulement 32 milliards.Et pourtant, ils prétendent pouvoir rivaliser avec les autres pays de l'Union européenne. Profondeur de l'eau-R1 et d'autres modèles de pointe de l'industrie. L'annonce a fait l'effet d'une bombe et a instantanément enflammé la communauté technologique, avec des liens vers le blog officiel, la bibliothèque de modèles Hugging Face, les téléchargements de modèles, les démonstrations en ligne et un site web permettant aux utilisateurs d'en savoir plus sur le produit et d'en faire l'expérience.
Bien que les informations publiées soient brèves et concises, la force technique qui les sous-tend est loin d'être simple. La phrase "32 milliards de paramètres comparables à DeepSeek-R1" est déjà impressionnante, sachant qu'en général, plus le nombre de paramètres d'un modèle est important, plus les performances tendent à être élevées, mais cela signifie également une demande plus importante de ressources informatiques. QwQ-32B Atteindre une performance similaire à celle du méga-modèle avec un petit nombre de paramètres est sans aucun doute une avancée majeure, qui a naturellement suscité un vif intérêt parmi les passionnés et les professionnels de la technologie.
Afin de démontrer les performances de QwQ-32B de manière plus intuitive, un tableau de référence officiel a été rendu public simultanément. L'étalonnage est un moyen important d'évaluer les capacités d'un modèle d'IA, qui mesure les performances du modèle pour différentes tâches en le testant sur une série d'ensembles de données prédéfinis et standardisés, fournissant ainsi aux utilisateurs une référence objective en matière de performances.

Ce tableau d'analyse comparative nous permet d'obtenir rapidement les informations clés suivantes :
- Vitesse d'épandage phénoménale : Les informations relatives à la publication du modèle достига́ть ont été lues par plus de 1,69 million de personnes en seulement 12 heures, ce qui reflète parfaitement la demande urgente du marché pour des modèles d'IA performants et les attentes élevées de QwQ-32B.
- Excellente performance : Avec seulement 32 milliards de paramètres, QwQ-32B est capable de rivaliser avec la version à paramètres complets de DeepSeek-R1, qui compte 671 milliards de paramètres, dans le test de référence, montrant ainsi un rapport énergie-efficacité étonnant. Ce phénomène d'un petit modèle surpassant un grand modèle rompt définitivement avec la perception traditionnelle de la relation entre la performance du modèle et la taille des paramètres.
- Surpasse les modèles de distillation de sa catégorie : QwQ-32B surpasse de manière significative la version de distillation 32B de DeepSeek-R1. La distillation est une technique de compression de modèles qui vise à imiter le comportement d'un modèle plus grand en entraînant un modèle plus petit, réduisant ainsi les coûts de calcul tout en maintenant les performances. Le fait que QwQ-32B surpasse le modèle de distillation 32B démontre la sophistication de son architecture et de sa méthodologie d'apprentissage.
- Leadership de performance multidimensionnel : QwQ-32B surpasse le modèle fermé d'OpenAI, o1-mini, dans plusieurs domaines d'évaluation, ce qui montre que QwQ-32B est capable de rivaliser avec les meilleurs modèles fermés en termes de capacités générales.
Il est particulièrement intéressant de noter que QwQ-32B, avec seulement 32 milliards de paramètres, est capable de surpasser des modèles géants avec plus de 20 fois le nombre de paramètres, ce qui représente un nouveau bond en avant dans la technologie de l'IA. Plus intéressant encore, les utilisateurs peuvent désormais facilement exécuter la version quantifiée de QwQ-32B localement avec une carte graphique grand public de classe RTX3090 ou RTX4090. Le déploiement local réduit non seulement la barrière à l'utilisation, mais ouvre également de nouvelles possibilités en matière de sécurité des données et d'applications personnalisées. Les utilisateurs dont la carte graphique est moins performante peuvent essayer de démarrer avec la solution de déploiement en nuage recommandée :Déploiement en ligne du modèle open-source DeepSeek-R1 avec une puissance GPU gratuiteou demander directement à utiliser l'API gratuite.Alibaba (volcan) fournit 1 million de jetons par jour (pendant 180 jours), et la Akash L'API est gratuite et peut être utilisée directement sans enregistrement.
DeepSeek n'est plus un poney à un coup, alors comment OpenAI peut-elle rester au top ?
Avec la forte concurrence du QwQ-32B, les produits existants d'OpenAI, tant la version Pro à 200 $ que la version Plus à 20 $, sont confrontés à un sérieux défi en termes de rapport prix/performance. Le QwQ-32B a donné au marché matière à réflexion, surtout si l'on considère les fluctuations de performances que les modèles OpenAI présentent parfois et qui ont été critiquées par les utilisateurs comme étant "abrutissantes". Néanmoins, OpenAI a toujours une histoire profonde et un écosystème étendu dans le domaine de l'IA, et il peut encore avoir un avantage pour affiner les modèles et optimiser les applications dans des domaines spécifiques. Cependant, la sortie de QwQ-32B rompt sans aucun doute avec le modèle original du marché, obligeant tous les acteurs à réexaminer leurs propres avantages techniques et leurs stratégies de marché.
Afin d'évaluer plus complètement les capacités réelles de QwQ-32B, il est nécessaire de l'installer localement et de le tester en détail, en particulier pour examiner ses performances de raisonnement et son niveau de "QI" dans un environnement opérationnel local.
Heureusement, grâce à la Ollama Avec l'avènement d'outils tels qu'Ollama, il est devenu très simple de déployer et d'exécuter localement de grands modèles linguistiques sur des ordinateurs personnels. Ollama, un cadre d'exécution de modèle léger open source, simplifie considérablement le processus de déploiement et de gestion de grands modèles locaux.
Ollama est réputée pour son efficacité et sa facilité d'utilisation. Peu après la sortie du QwQ-32B, Ollama a rapidement annoncé la prise en charge du modèle, abaissant encore la barrière pour les utilisateurs de la dernière technologie d'IA et facilitant l'accès à la puissance du QwQ-32B pour tout le monde.
1) Installation et fonctionnement d'Ollama
Tout d'abord, visitez le site officiel d'Ollama à l'adresse ollama.com et cliquez sur le bouton Download pour télécharger le paquet d'installation approprié à votre système d'exploitation.
Ollama fournit un support complet pour tous les principaux systèmes d'exploitation, y compris macOS (Intel et Apple Silicon), Windows et Linux, garantissant que le modèle QwQ-32B peut être facilement utilisé sur toutes les plateformes.
Une fois le téléchargement terminé, double-cliquez sur le programme d'installation et suivez l'assistant pour terminer le processus d'installation. Une fois l'installation réussie, vous verrez une jolie icône d'alpaga dans la barre des tâches de Windows ou dans la barre des menus de macOS, indiquant qu'Ollama a été lancé avec succès et qu'il fonctionne en arrière-plan, prêt à vous servir.
2. téléchargement du modèle QwQ-32B
À lire absolument :Unsloth résout le problème de l'inférence en double dans la version quantifiée de QwQ-32B
Après avoir installé et lancé Ollama avec succès, vous pouvez maintenant commencer à télécharger le modèle QwQ-32B.

Ouvrez le client Ollama dans la fenêtre Modèles Sur la page Modèles, vous constaterez que le modèle QwQ-32B est rapidement arrivé en tête de la liste des modèles les plus populaires, ce qui témoigne de sa popularité. Trouvez l'entrée du modèle "qwq" et cliquez dessus pour accéder à la page de détails du modèle. Sur la page de détails, copiez les commandes mises en évidence dans le cadre rouge.
Ouvrez un terminal local (macOS/Linux) ou une invite de commande (Windows).
Dans un terminal ou une invite de commande, collez et exécutez la commande suivante :ollama run qwq
ollama run qwq
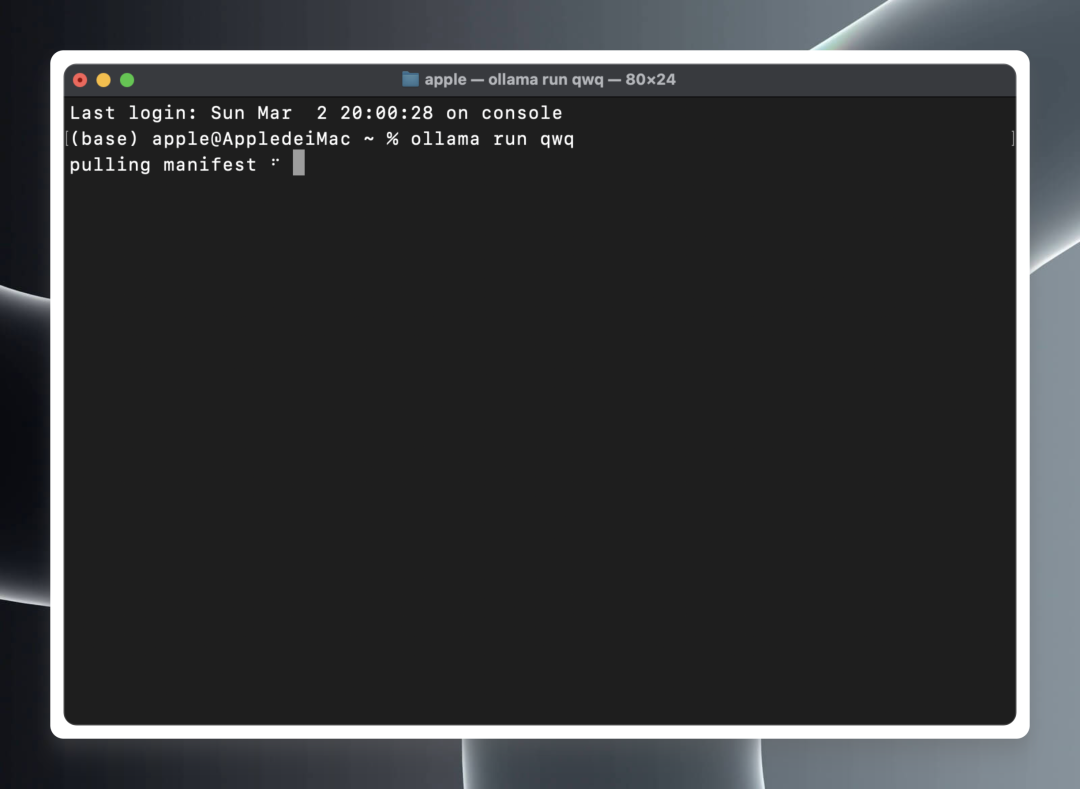
Ollama commencera automatiquement à télécharger les fichiers du modèle QwQ-32B depuis le cloud et lancera automatiquement l'environnement d'exécution du modèle une fois le téléchargement terminé.
Il convient de mentionner queLe processus de téléchargement du modèle ne semble pas nécessiter de configuration réseau supplémentaire de la part de l'utilisateur. Il s'agit sans aucun doute d'une caractéristique très intéressante pour les utilisateurs nationaux. Après tout, un fichier modèle de près de 20 Go réduira considérablement l'expérience de l'utilisateur si la vitesse de téléchargement est trop lente ou si un environnement réseau spécial est nécessaire.
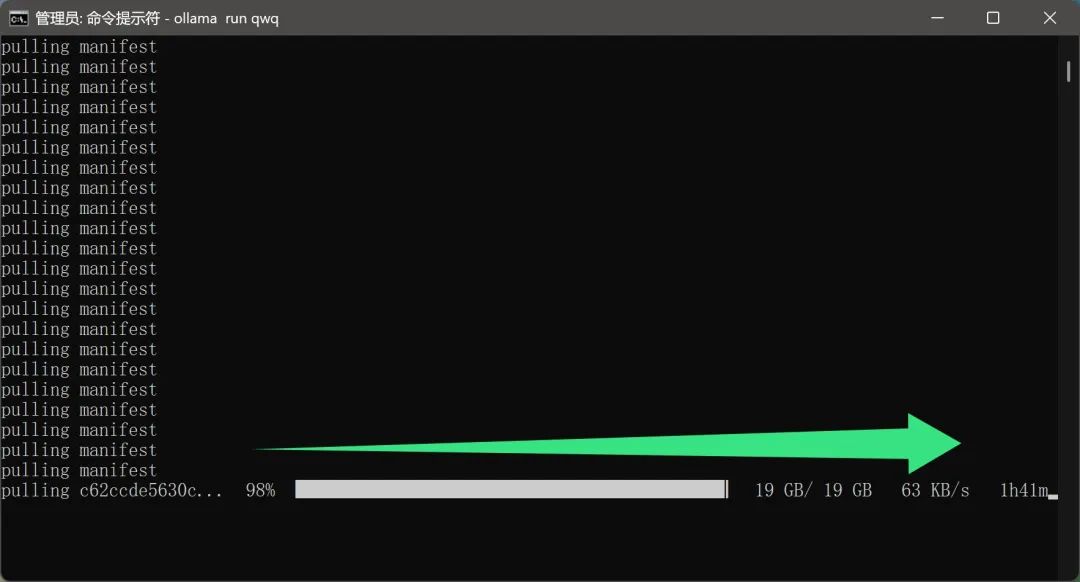
Cependant, comme le modèle QwQ-32B est actuellement très populaire et que de nombreux utilisateurs le téléchargent, la vitesse de téléchargement réelle peut être affectée dans une certaine mesure, ce qui se traduit par un temps de téléchargement plus long, ce qui demande aux utilisateurs d'être patients.
Après un certain temps d'attente, le modèle a finalement été téléchargé. J'ai testé le modèle QwQ-32B sur un ordinateur équipé d'une carte graphique de bureau RTX3060 avec 12 Go de mémoire vidéo, et j'ai été agréablement surpris : non seulement le modèle s'est chargé avec succès, mais il a également été capable de donner des réponses fluides basées sur les entrées de l'utilisateur et, plus important encore, il n'y a eu aucun problème de débordement de la mémoire vidéo pendant toute la durée du processus. Cela signifie que même les cartes graphiques courantes peuvent répondre aux exigences du modèle quantitatif QwQ-32B.

En termes de performance d'inférence, la capacité de QwQ-32B a déjà surpassé certains modèles OpenAI que les utilisateurs appellent en plaisantant "IQ underline". Cela confirme également la supériorité de QwQ-32B en termes de performances.
Grâce au gestionnaire de tâches de Windows, nous pouvons surveiller l'utilisation des ressources du modèle en temps réel. Les résultats montrent que l'unité centrale, la mémoire et la mémoire graphique sont toutes fortement sollicitées pendant le processus d'inférence du modèle, ce qui reflète également les exigences élevées en matière de ressources matérielles pour l'exécution locale de modèles volumineux.
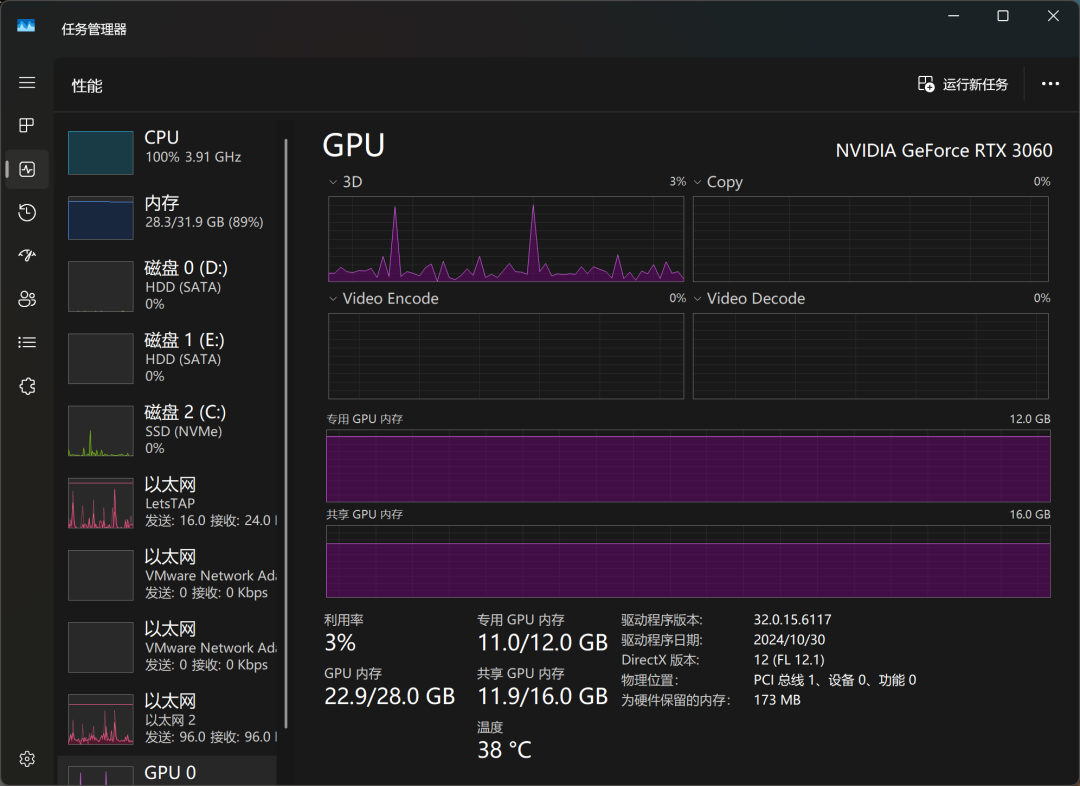
Avec une carte graphique RTX3060, QwQ-32B répond à un rythme d'environ "da, da, da, da...", ce qui peut satisfaire les besoins de base de l'utilisation, mais il y a encore de la place pour l'amélioration en termes de réactivité et de fluidité. Si vous recherchez une expérience d'exécution de modèle local plus extrême, vous aurez peut-être besoin d'un niveau de configuration matérielle plus élevé.
Afin d'améliorer encore la vitesse d'exécution du modèle, j'ai téléchargé et exécuté à nouveau le modèle QwQ-32B sur un appareil équipé d'une carte graphique RTX3090 haut de gamme. Les résultats expérimentaux montrent qu'après le remplacement de la carte graphique haut de gamme, la vitesse d'exécution du modèle a été considérablement améliorée, et il n'est pas exagéré de la décrire comme "aussi rapide que le vol". Cela réaffirme également l'importance de la configuration matérielle pour l'expérience de fonctionnement d'un grand modèle local.
3. intégration du QwQ-32B dans les clients
Bien que parler au modèle directement à partir de l'interface de ligne de commande soit un moyen simple et direct, pour ceux qui ont besoin de l'utiliser fréquemment ou qui recherchent une meilleure expérience d'interaction, l'utilisation d'un client graphique est sans aucun doute un choix plus pratique. Il existe sur le marché un grand nombre d'excellents logiciels clients pour les modèles d'IA, et nous avons déjà présenté plusieurs d'entre eux, tels que ChatWise. La principale raison pour laquelle nous avons choisi ChatWise est la conception simple et intuitive de son interface, sa logique de fonctionnement claire et facile à comprendre, et sa capacité à fournir aux utilisateurs une bonne expérience.
Les étapes suivantes décrivent la configuration d'un modèle QwQ-32B avec le client ChatWise.
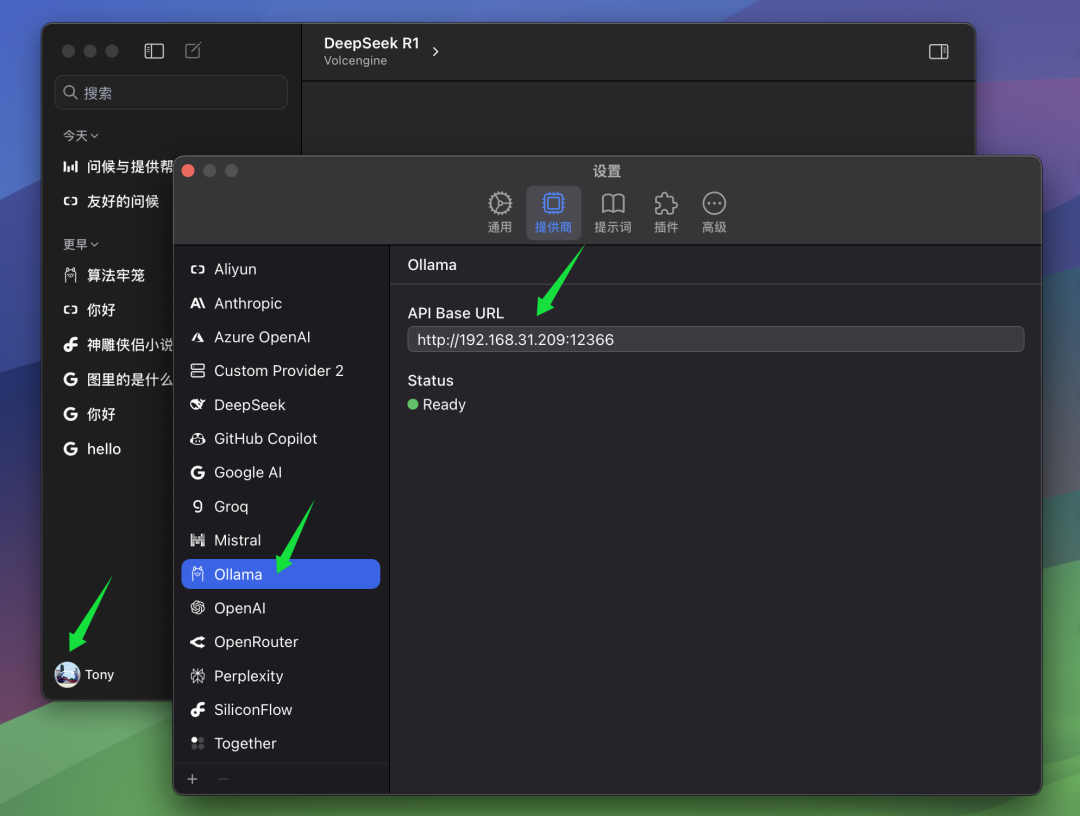
Si votre client ChatWise et le service Ollama fonctionnent sur le même ordinateur, vous pouvez généralement ouvrir le client ChatWise et utiliser directement le modèle QwQ-32B sans configuration supplémentaire. C'est le cas de la plupart des utilisateurs, c'est-à-dire que le service Ollama et l'application client sont installés sur le même appareil.
Cependant, si, comme l'auteur, vous avez installé le service Ollama sur un autre ordinateur (par exemple un serveur) et que le client ChatWise tourne sur votre ordinateur local, vous devrez modifier manuellement les paramètres de ChatWise, à savoir BaseURL afin que les clients puissent se connecter au service Ollama distant. Dans l'interface BaseURL Dans les paramètres, vous devez indiquer l'adresse IP de l'ordinateur qui exécute le service Ollama, ainsi que le numéro de port que vous avez configuré sur le serveur Ollama. Le port par défaut d'Ollama est 13434, donc si vous ne l'avez pas configuré spécifiquement, vous pouvez utiliser le port par défaut.
remplir BaseURL Une fois configuré, vous pouvez sélectionner le modèle que vous souhaitez utiliser dans le client ChatWise.
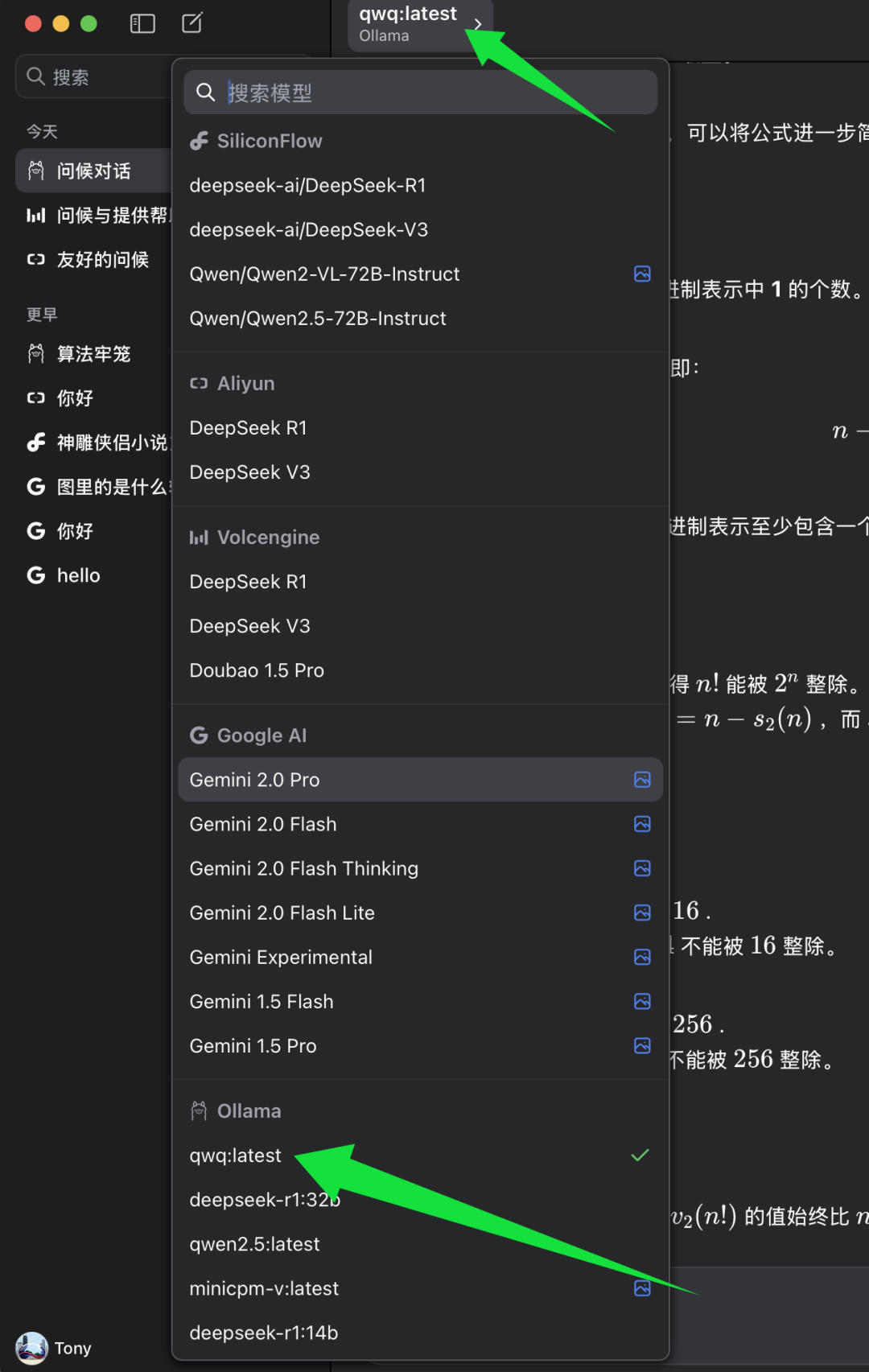
Dans la liste de sélection des modèles de ChatWise, recherchez la catégorie de modèles Ollama et sélectionnez sous celle-ci qwq:dernier. qwq:dernier Représente la dernière version du modèle QwQ-32B, généralement aussi la version quantifiée à 4 bits. Sélectionner qwq:dernier Ensuite, vous pouvez commencer à découvrir la puissance du modèle QwQ-32B dans le client ChatWise.
4. test de niveau d'intelligence du modèle QwQ-32B
Afin d'évaluer plus objectivement le niveau d'intelligence du modèle QwQ-32B, nous avons utilisé un ensemble de questions classiques précédemment développées pour tester le problème de "l'intelligence réduite" du modèle OpenAI. Cet ensemble se compose de quatre questions soigneusement sélectionnées qui se sont avérées empiriquement utiles si le modèle OpenAI est utilisé pour évaluer le niveau d'intelligence. ChatGPT (en particulier pour les modèles GPT-3 ou GPT-4), il est souvent difficile de répondre correctement à ces questions si l'utilisateur fait état d'une "intelligence réduite". Par conséquent, cette série de questions peut être utilisée dans une certaine mesure comme référence pour tester le niveau d'intelligence des grands modèles.
Ensuite, nous testerons le modèle QwQ-32B exécuté localement, un par un, pour voir s'il peut répondre avec succès à toutes les questions.
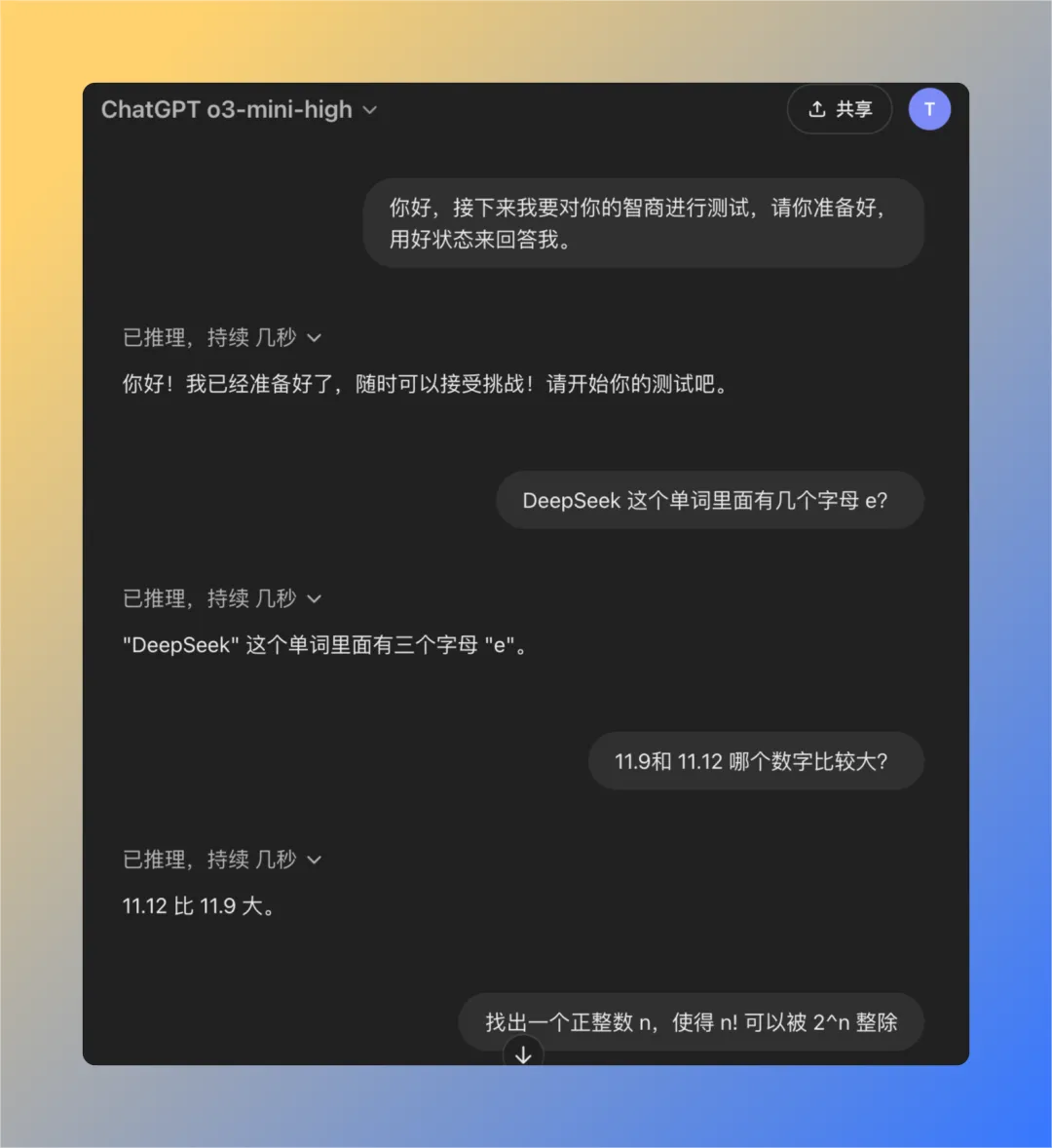
Question 1 : Combien de lettres de la lettre e y a-t-il dans le mot deepseek ?
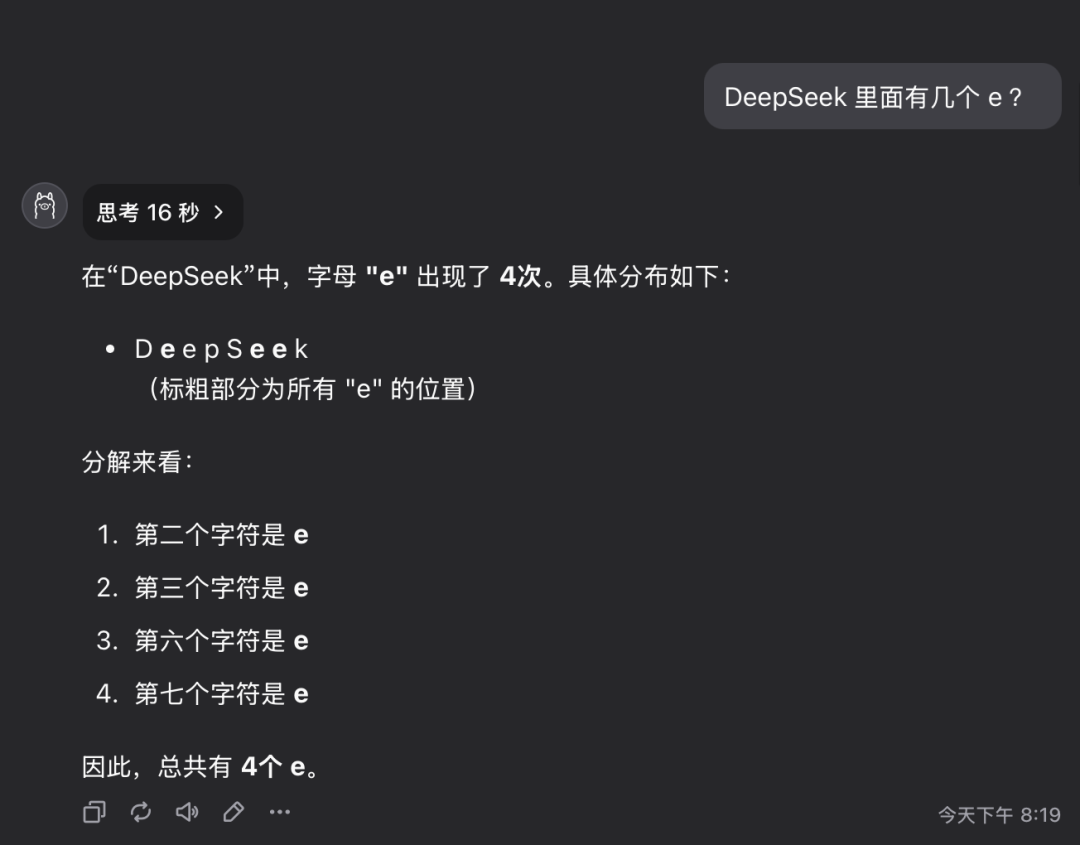
Le modèle QwQ-32B a donné la bonne réponse en 16 secondes : 3. La réponse est correcte..
Cette question peut sembler simple, mais elle examine en fait la capacité du modèle à comprendre et à extraire avec précision des informations détaillées. Il est surprenant de constater qu'un nombre important de grands modèles sont encore incapables de répondre avec précision à ce type de questions.
Question 2 : Quelle est la valeur la plus élevée, 11,9 ou 11,12 ?

Le modèle QwQ-32B a donné la bonne réponse en 47 secondes : 11,12 est plus grand. La réponse est correcte..
Là encore, il s'agit d'un problème apparemment élémentaire mais classique. De nombreux grands modèles sont confus ou évaluent mal de simples comparaisons numériques, ce qui reflète d'éventuelles déficiences dans le raisonnement logique sous-jacent du modèle.
Problème 3 : Trouvez un entier positif n tel que la factorielle de n (n !) soit divisible par la nième puissance de 2 (2^n).

Le modèle QwQ-32B donne la bonne réponse en 121 secondes : un tel entier positif n n'existe pas. La réponse est correcte..
Le but de cette question n'est pas de trouver une réponse numérique spécifique, mais d'examiner si le modèle a la capacité de penser abstraitement et de raisonner logiquement, de comprendre la nature du problème, et finalement d'arriver à la conclusion que "cela n'existe pas". QwQ-32B a pu répondre correctement à cette question, démontrant une certaine capacité de raisonnement logique.
Question 4 : Raisonnement logique classique - Énigme de la couleur du chapeau
"Il y a 5 personnes dans une rangée et chacune d'entre elles porte un chapeau sur la tête, qui peut être rouge ou bleu. Chaque personne ne peut voir que la couleur du chapeau de la personne qui la précède dans la rangée, mais pas la couleur du chapeau qu'elle porte sur sa propre tête. L'animateur dit au groupe à l'avance : "Parmi ces 5 personnes, il y a au moins un chapeau rouge". En commençant par la personne au bout de la rangée et en avançant à tour de rôle, on demande à chaque personne : "Savez-vous de quelle couleur est votre chapeau ?" Chaque personne ne peut répondre que par "oui" ou "non". En supposant que la cinquième personne réponde "non" et que la quatrième réponde "oui", quelle est la distribution de toutes les couleurs de chapeau possibles ?"
Par rapport aux trois premières questions, cette question de raisonnement logique était nettement plus difficile et exigeait davantage d'analyse logique et de capacités de raisonnement de la part du modèle.
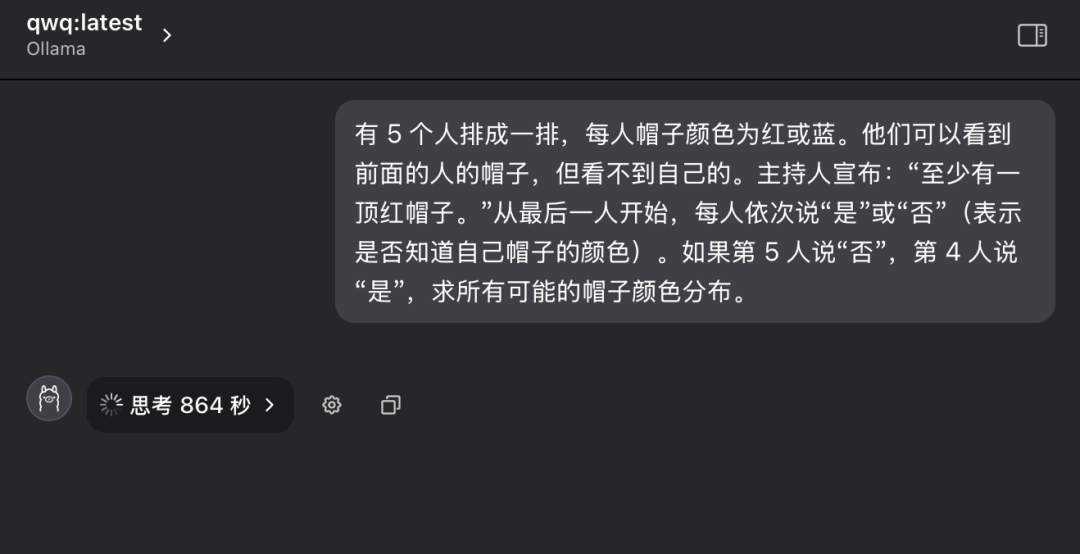
Lors de la première interrogation, le modèle QwQ-32B est entré dans un état de réflexion prolongée, les mots "Thinking..." clignotant à l'écran, comme si le "cerveau" fonctionnait à grande vitesse, ce qui a même suscité des inquiétudes quant à la capacité du matériel à supporter une charge de calcul aussi intense. On se demande même si le matériel peut supporter une charge de calcul aussi intense. Compte tenu du temps et des conditions de fonctionnement du matériel, après plus de dix minutes d'attente, j'ai interrompu manuellement le processus de réflexion du modèle.
L'auteur a ensuite rouvert une nouvelle session de dialogue et a posé à nouveau les mêmes questions au modèle QwQ-32B.

Cette fois, le modèle QwQ-32B a finalement donné une réponse entièrement correcte après 196 secondes et a expliqué son raisonnement en détail. La réponse est correcte..
L'examen de l'enregistrement du processus de raisonnement du modèle montre que, malgré la taille relativement petite des paramètres de QwQ-32B, le modèle fait preuve d'un processus de réflexion et d'analyse très "dur" lorsqu'il est confronté à un problème de raisonnement logique complexe. Le modèle effectue de nombreux calculs logiques et déductions de probabilités en arrière-plan avant de parvenir à la bonne conclusion.
Après cette série de tests de QI rigoureux et détaillés, nous pouvons conclure que la version quantifiée du modèle 4 bits QwQ-32B a démontré des performances globales impressionnantes, en particulier en matière de raisonnement logique et de quiz, et a surpassé les autres modèles de sa catégorie. Il est raisonnable de penser que les performances de la version non quantifiée de QwQ-32B seront encore meilleures. Rapport d'évaluation des performances du modèle 32B Full Blood Edition QwQ-32B fournit des données et des analyses de performance plus complètes. Par conséquent, nous pouvons juger que la promotion des performances faite par l'équipe QwQ d'Alibaba lors de la publication du modèle QwQ-32B n'est pas exagérée, et que QwQ-32B est en effet un excellent nouveau modèle d'inférence, qui parvient à rivaliser avec le modèle DeepSeek-R1 de 671 milliards de paramètres avec une échelle de paramètres de 32 milliards de paramètres.
L'essor rapide des grands modèles open source nationaux démontre pleinement la vigueur de l'innovation et l'énorme potentiel de développement de la Chine dans le domaine de la technologie de l'IA.
Mieux encore, la version QwQ-32B 32B du modèle ne nécessite qu'une carte graphique dotée de 24 Go de mémoire vive pour fonctionner de manière fluide et à des vitesses impressionnantes. Il y a quelques années, l'exécution d'un modèle à grande échelle aussi performant aurait nécessité des millions de dollars d'équipement spécialisé. Aujourd'hui, grâce aux avancées technologiques telles que QwQ-32B et Ollama, les utilisateurs peuvent le déployer et l'expérimenter localement sur un PC de 10 000 dollars. La sortie du modèle QwQ-32B indique que les modèles d'IA à haute performance deviennent de plus en plus populaires, que l'ère de "l'IA pour tous" s'accélère et que la technologie de l'IA à haute performance aura des perspectives d'application plus larges dans les appareils terminaux personnels et dans divers secteurs d'activité.
Le moment est venu de passer à l'action, d'explorer et d'utiliser pleinement la puissance du QwQ-32B ! Embrassons ensemble l'avenir radieux de la technologie de l'IA !
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Postes connexes


Pas de commentaires...