
Baichuan Intelligence publie le grand modèle omnimodal Baichuan-Omni-1.5, qui surpasse le GPT-4o Mini dans plusieurs mesures.
Vers la fin de l'année, le secteur des grands modèles nationaux a de nouveau répandu de bonnes nouvelles. BCinks Intelligence a récemment publié un certain nombre de produits grand modèle, dans la foulée de la campagne d'information de la Commission européenne.Modèle d'inférence profonde en pleine scène Baichuan-M1-previewrépondre en chantantAmélioration médicale Modèle Open Source Baichuan-M1-14BElle a été suivie par la relance deModèle modal complet Baichuan-Omni-1.5.
Baichuan-Omni-1.5 est connu sous le nom de "Big Model Generalist", ce qui marque le progrès significatif du Big Model domestique dans la technologie de fusion multimodale.Baichuan-Omni-1.5 est équipé d'une excellente capacité de compréhension et de génération omni-modale, qui est non seulement capable de traiter simultanémentTexte, images, audio, vidéoet d'autres informations multimodales, ainsi qu'un soutien accru à l'utilisation de l'Internet.Texte et audioGénération de contenu bimodal.
Dans le même temps, Baichuan Intelligence a également mis en libre accès les informations suivantesOpenMM-Médicalrépondre en chantantOpenAudioBenchLes deux ensembles de données d'évaluation de haute qualité visent à promouvoir le développement prospère de l'écosystème technologique national des modèles multimodaux. D'après les résultats complets de l'évaluation qui ont été rendus publics, Baichuan-Omni-1.5 possède un certain nombre de capacités multimodalesLes performances globales dépassent celles du GPT-4o MiniL'intelligence des BCinks n'a cessé de s'approfondir, en particulier dans le domaine médical.Les résultats de l'examen de l'image médicale constituent une avance significativeCela démontre pleinement la force et la détermination de BCinks Intelligence en tant que leader dans le domaine des grands modèles. Cela démontre pleinement que Baichuan Intelligence, en tant qu'entreprise leader dans le domaine des grands modèles nationaux, fait preuve d'une grande force et d'une ferme détermination dans le domaine de l'innovation technologique et de l'atterrissage des applications industrielles.
Adresse du poids du modèle :
Baichuan-Omini-1.5 : https://huggingface.co/baichuan-inc/Baichuan-Omni-1d5 https://modelers.cn/models/Baichuan/Baichuan-Omni-1d5
Base Baichuan-Omini-1.5 : https://huggingface.co/baichuan-inc/Baichuan-Omni-1d5-Base https://modelers.cn/models/Baichuan/Baichuan- Omni-1d5-Base
Adresse GitHub : https://github.com/baichuan-inc/Baichuan-Omni-1.5
Rapport technique : https://github.com/baichuan-inc/Baichuan-Omni-1.5/blob/main/baichuan_omni_1_5.pdf
01 . Une avancée considérable dans les capacités multimodales : des performances exceptionnelles dans l'évaluation du traitement du texte, des graphiques, de l'audio et de la vidéo
Les points forts du Baichuan-Omni-1.5 peuvent être résumés comme suit : ".Des capacités étendues et des performances élevées". La caractéristique la plus remarquable du modèle est sonde manière exhaustiveLa capacité de compréhension et de génération multimodale, plus précisément, non seulement comprend le contenu multimodal tel que le texte, l'image, la vidéo et l'audio, mais prend également en charge la génération bimodale de texte et d'audio.
En termes de compréhension des images, selon les résultats des tests effectués sur des bancs d'essai d'évaluation d'images courants tels que MMBench-dev, TextVQA val, etc.Meilleur que le GPT-4o Mini. Il est particulièrement intéressant de noter que, outre ses capacités générales, le modèle entièrement modal de Baichuan Intelligence est particulièrement performant dans le domaine des soins de santé. En effet, enEnsemble de données d'examen d'images médicales Les évaluations de GMAI-MMBench et Openmm-Medical ont montré que les capacités de Baichuan-Omni-1.5 en matière de compréhension d'images médicales ont été améliorées.Des performances nettement supérieures à celles du GPT-4o Mini.
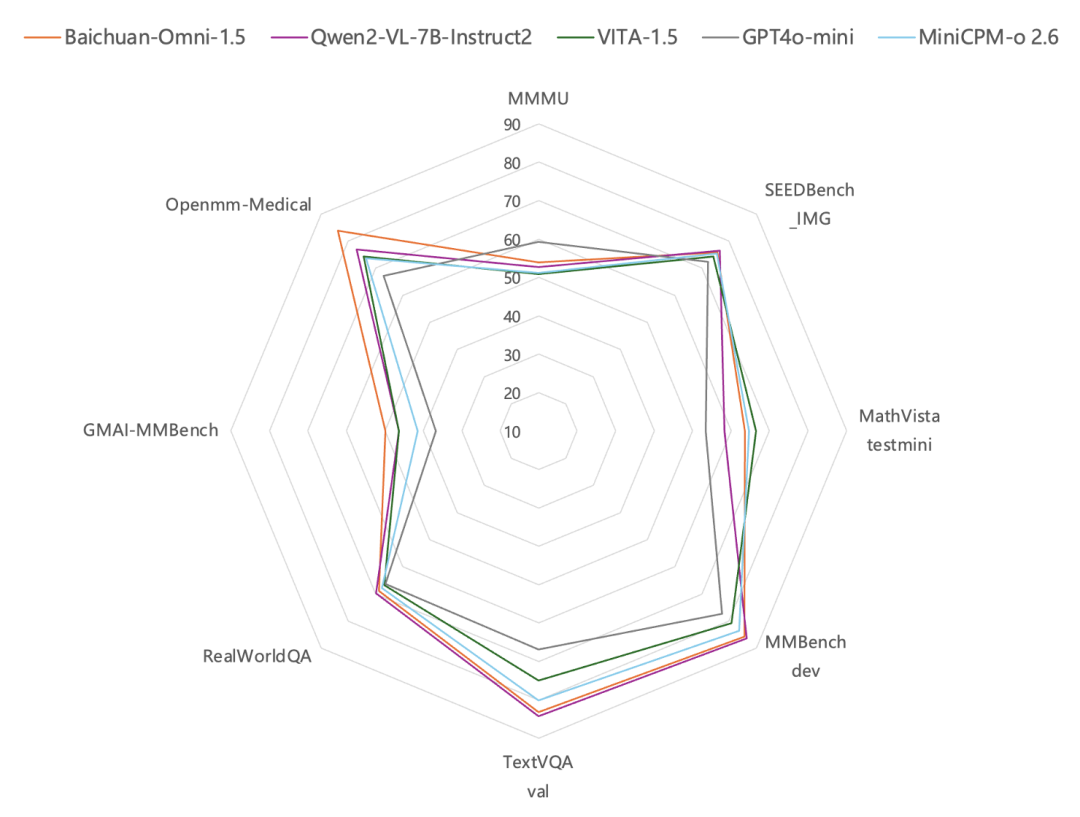
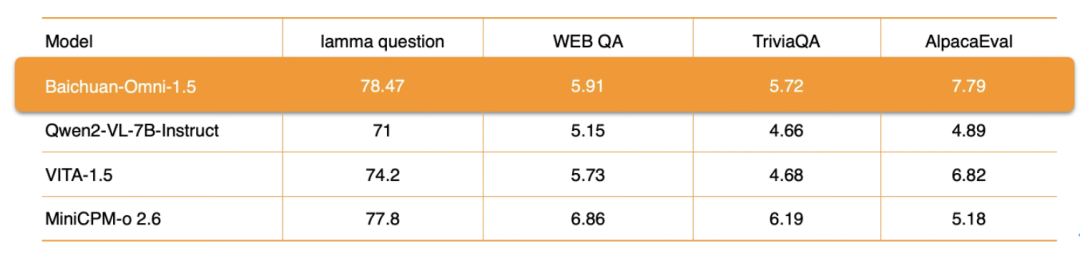
En ce qui concerne le traitement audio, Baichuan-Omni-1.5 prend en charge non seulement la fonctiondialogue multilingueIl s'appuie également sur ses capacités de synthèse audio de bout en bout, en intégrant les éléments suivants ASR (Reconnaissance Automatique de la Parole) répondre en chantant TTS (synthèse vocale) fonctions. En outre, le modèle soutient également la mise en œuvre de laInteraction audio-vidéo en temps réel. En termes de performances spécifiques, les performances globales de Baichuan-Omni-1.5 sur des ensembles de données tels que lamma question et AlpacaEvalnettement supérieure à celle de Qwen2-VL-2B-Instruct, VITA-1.5 et MiniCPM-o 2.6 sont des modèles similaires.
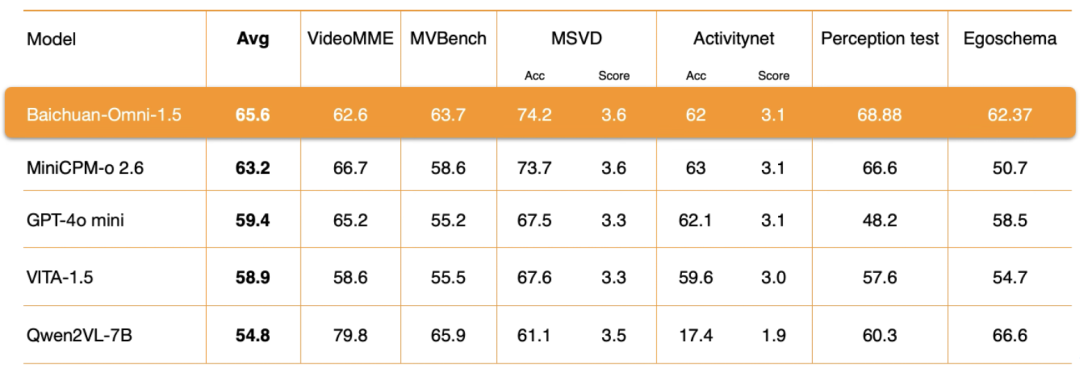
Compréhension vidéoAu niveau de Baichuan-Omni-1.5, Baichuan Intelligence a procédé à une optimisation approfondie de plusieurs aspects clés tels que l'architecture de l'encodeur, la qualité des données d'entraînement et la stratégie de la méthode d'entraînement. Les résultats de l'évaluation montrent que sa compréhension des vidéosLes performances globales sont également nettement supérieures à celles du GPT-4o-mini..
En résumé, Baichuan-Omni-1.5 surpasse non seulement GPT4o-mini en termes de capacité générale dans son ensemble, mais plus important encore, il réalise les objectifs de l'UE en matière de sécurité et de protection de l'environnement.Unité de la compréhension et de la génération modale complètequi jette les bases de la construction de systèmes d'IA plus généralisés.
Pour faire progresser la recherche sur la modélisation multimodale, Baichuan Intelligence a mis en libre accès deux ensembles de données d'examens professionnels :OpenMM-Medical et OpenAudioBench. Parmi eux OpenMM-Médical ensemble de donnéesConçu pour évaluer les performances du modèle dans des tâches médicales multimodalesIl intègre des données provenant de 42 ensembles de données d'images médicales accessibles au public, tels que ACRIMA (images de fond d'œil), BioMediTech (images de microscopie) et CoronaHack (rayons X), pour un total de 88 996 images.
Adresse de téléchargement :
https://huggingface.co/datasets/baichuan-inc/OpenMM_Medical
OpenAudioBench il s'agit alors d'unUne plateforme d'évaluation complète pour évaluer efficacement les compétences de compréhension audio des modèlesIl contient 5 sous-ensembles d'évaluation pour la compréhension audio de bout en bout, dont 4 sont dérivés d'ensembles de données d'évaluation publiques (Llama Question, WEB QA, TriviaQA, AlpacaEval), et l'autre est un ensemble d'évaluation du raisonnement logique vocal auto-construit par Baichuan Intelligence, qui contient 2 701 éléments de données.
Adresse de téléchargement :
https://huggingface.co/datasets/baichuan-inc/OpenAudioBench
BCinks Intelligence participe activement à la construction et à la prospérité de l'écosystème national des logiciels libres. L'ensemble de données d'évaluation en source ouverte fournit aux chercheurs et aux développeurs un outil d'évaluation unifié et standardisé, qui permet d'effectuer une analyse comparative objective et équitable des performances de différents modèles multimodaux, favorisant ainsi le développement innovant d'algorithmes de compréhension du langage et d'architectures de modèles de nouvelle génération.
02 . Optimisation technologique globale : synergie des données, de l'architecture et des processus pour éliminer les goulets d'étranglement des modèles multimodaux.
Des premiers modèles unimodaux à la fusion multimodale, puis aux modèles entièrement modaux d'aujourd'hui, cette évolution technologique a élargi l'espace pour l'application de la technologie de l'IA dans diverses industries. Cependant, avec le développement approfondi de la technologie de l'IA, lesLa question de savoir comment réaliser efficacement l'unité de compréhension et de génération dans les modèles multimodaux est devenue un point névralgique et une difficulté technique dans la recherche actuelle dans le domaine de la multimodalité..
D'une part, l'unité de la compréhension et de la génération est la clé pour simuler l'interaction humaine naturelle et réaliser une communication homme-ordinateur plus naturelle et plus efficace, ainsi qu'un lien important avec l'intelligence artificielle générale (AGI) ; d'autre part, il existe des différences significatives entre les différentes données modales en termes de représentation des caractéristiques, de structures de données et de connotations sémantiques, etc. Ainsi, la manière d'extraire efficacement les caractéristiques multimodales et de parvenir à une interaction et une fusion efficaces des informations intermodales est reconnue comme l'un des plus grands défis auxquels est confrontée la formation de modèles tous modes.
La publication de Baichuan-Omni-1.5 montre que Baichuan Intelligence a réalisé des progrès significatifs dans la résolution des problèmes techniques susmentionnés et a exploré une voie technique efficace. Afin de surmonter le problème courant de la "dégradation intellectuelle" dans la formation des modèles omnimodaux, l'équipe de recherche de Baichuan a procédé à une optimisation approfondie de l'ensemble du processus, de la conception de la structure du modèle à l'optimisation de la stratégie de formation et à la construction des données de formation, pour finalement parvenir à une unification efficace de la compréhension et de la génération.
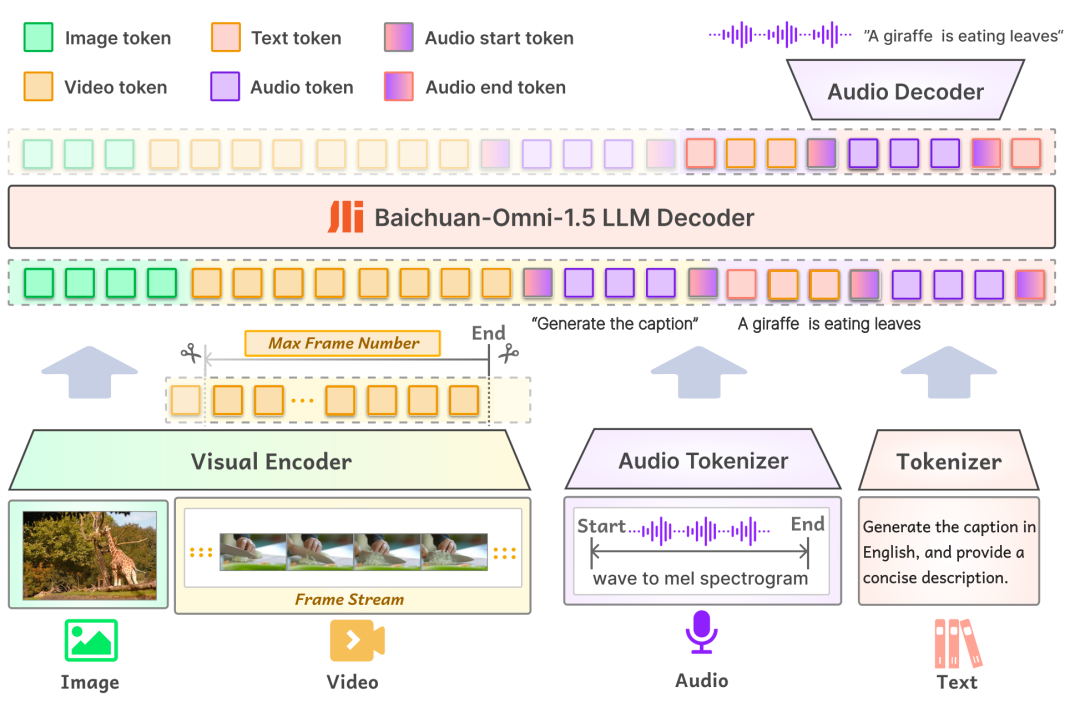
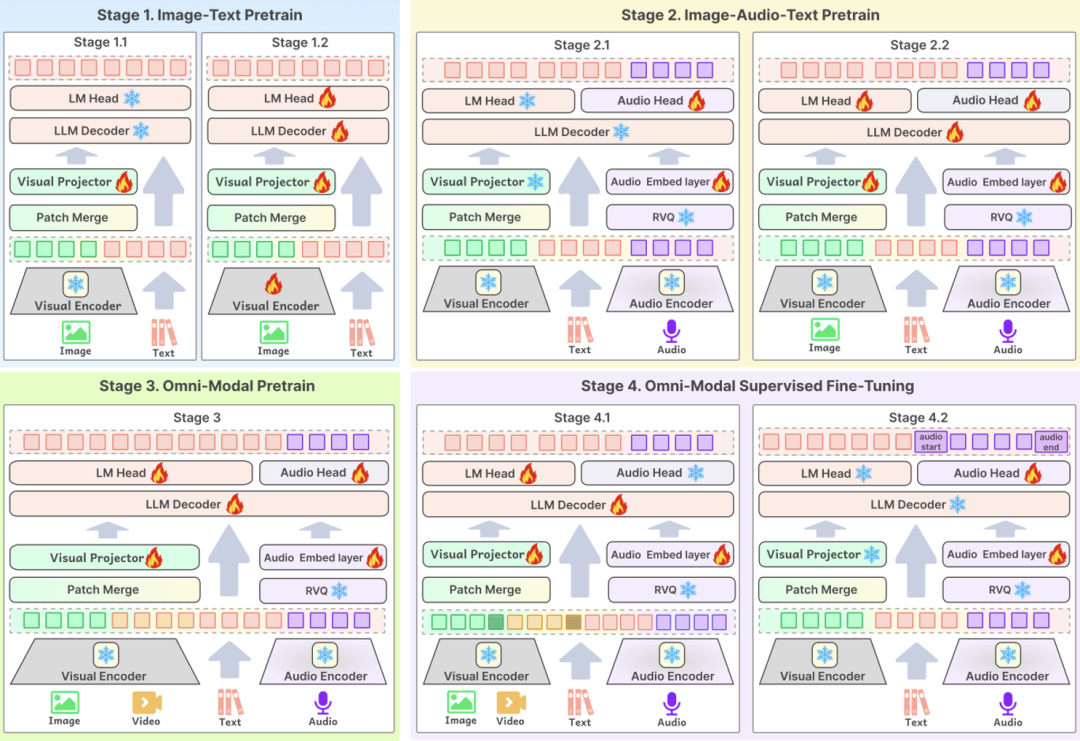
premier enmodélisationLa couche d'entrée de Baichuan-Omni-1.5 prend en charge des données modales multiples, qui sont introduites dans le modèle linguistique à grande échelle pour être traitées par l'encodeur/le tokeniseur correspondant ; dans la couche de sortie, le modèle adopte une conception de sortie entrelacée texte-audio, qui peut générer simultanément un contenu textuel et audio grâce au tokeniseur de texte et au décodeur audio. Dans la couche de sortie, le modèle adopte une conception de sortie entrelacée texte-audio, qui permet de générer simultanément des modalités textuelles et audio grâce au tokeniseur de texte et au décodeur audio. Le tokenizer audio est basé sur le modèle de reconnaissance vocale et de traduction OpenAI. Chuchotement Le modèle est entraîné de manière incrémentale pour fournir une extraction sémantique avancée et une reconstruction audio de haute fidélité. Afin de permettre au modèle de traiter des images de différentes résolutions, Baichuan-Omni-1.5 introduit le modèle NaViT, qui prend en charge les entrées d'images jusqu'à une résolution de 4K et l'inférence multi-image, garantissant ainsi que le modèle peut capturer pleinement les informations de l'image et comprendre avec précision le contenu de l'image.
Deuxièmement, enNiveau des donnéesBCI a construit une base de données massive contenant 340 millions de données image/vidéo-texte de haute qualité et près d'un million d'heures de données audio, à partir desquelles 17 millions de données entièrement modales ont été sélectionnées pour la phase SFT (réglage fin supervisé) du modèle. Contrairement à la composition des données des modèles traditionnels, l'apprentissage des modèles omnimodaux nécessite non seulement une grande quantité de données, mais aussi une diversité de types de données et une inter-modalité. Dans le monde réel, les informations sont généralement présentées sous la forme d'une fusion de plusieurs modalités, et les données de différentes modalités contiennent des informations complémentaires. La fusion efficace des données multimodales aide le modèle à apprendre des modèles et des lois plus généraux, améliorant ainsi la capacité de généralisation du modèle. C'est l'un des éléments clés de la construction de modèles multimodaux performants.
Afin d'améliorer la capacité de compréhension multimodale du modèle, Baichuan Intelligence a construit des données entrelacées visuelles-audio-textes de haute qualité et a entraîné le modèle avec un alignement utilisant 16 millions de données graphiques, 300 000 données de texte en clair, 400 000 données audio, ainsi que les données multimodales mentionnées ci-dessus. En outre, afin de permettre au modèle d'effectuer simultanément diverses tâches audio telles que l'ASR, le TTS, la commutation de timbre et le Q&A audio de bout en bout, l'équipe de recherche a également construit des échantillons de données spécifiquement liés à ces tâches dans les données alignées.
Le troisième point technologique clé est le suivantProcessus de formationLa conception optimale du modèle est le maillon central qui permet de garantir que des données de haute qualité peuvent améliorer efficacement les performances du modèle. BCinks Intelligence adopte un schéma de formation en plusieurs étapes dans les phases de préformation et de SFT afin d'améliorer globalement l'effet du modèle. Le processus de formation est divisé en quatre phases : la première phase est basée sur la formation des données graphiques ; la deuxième phase ajoute des données audio pour la préformation ; la troisième phase introduit des données vidéo pour la formation ; et la dernière phase est la phase d'alignement multimodal, qui permet finalement au modèle d'avoir une compréhension complète du contenu multimodal.
La publication de Baichuan-Omni-1.5 n'est pas seulement une nouvelle étape importante dans la recherche et le développement technologique de Baichuan Intelligence, elle signifie également que le centre de développement de l'IA s'accélère, passant de l'amélioration de la capacité de base du modèle à l'application pratique.
Auparavant, l'amélioration des capacités du grand modèle était principalement axée sur des capacités de base telles que la compréhension du langage et la reconnaissance d'images, tandis que la puissante capacité de fusion multimodale de Baichuan-Omni-1.5 aidera la technologie à s'intégrer plus étroitement dans les scénarios d'application du monde réel. En améliorant les capacités globales du modèle en matière de traitement des informations multimodales, telles que le langage, la vision, l'audio, etc., Baichuan-Omni-1.5 est en mesure de répondre efficacement à des tâches d'application pratique plus complexes et plus diverses. Par exemple, dans l'industrie médicale, les puissantes capacités de compréhension et de génération du modèle omnimodal peuvent être utilisées pour aider les médecins à diagnostiquer les maladies, en améliorant la précision et l'efficacité du diagnostic, ce qui est d'une grande valeur exploratoire pour promouvoir l'application approfondie de la technologie de l'IA dans le domaine médical. À l'avenir, la publication de Baichuan-Omni-1.5 pourrait marquer le début de l'application de la technologie de l'IA dans les domaines de la médecine et des soins de santé à l'ère de l'IAG, et nous avons des raisons de penser que l'IA jouera un rôle plus important dans le domaine médical et dans d'autres domaines dans un avenir proche, ce qui changera profondément nos vies.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...