NVIDIA abre el modelo gráfico SANA de Vincennes: imágenes 4K sobre la marcha para implantaciones locales

Recientemente, NVIDIA (NVIDIA), en colaboración con el Instituto Tecnológico de Massachusetts y la Universidad de Tsinghua, ha lanzado un modelo de generación de imágenes de código abierto denominado SANA, que no sólo es capaz de generar imágenes con una resolución de hasta 4096 × 4096, sino que además tiene una velocidad de generación muy rápida.
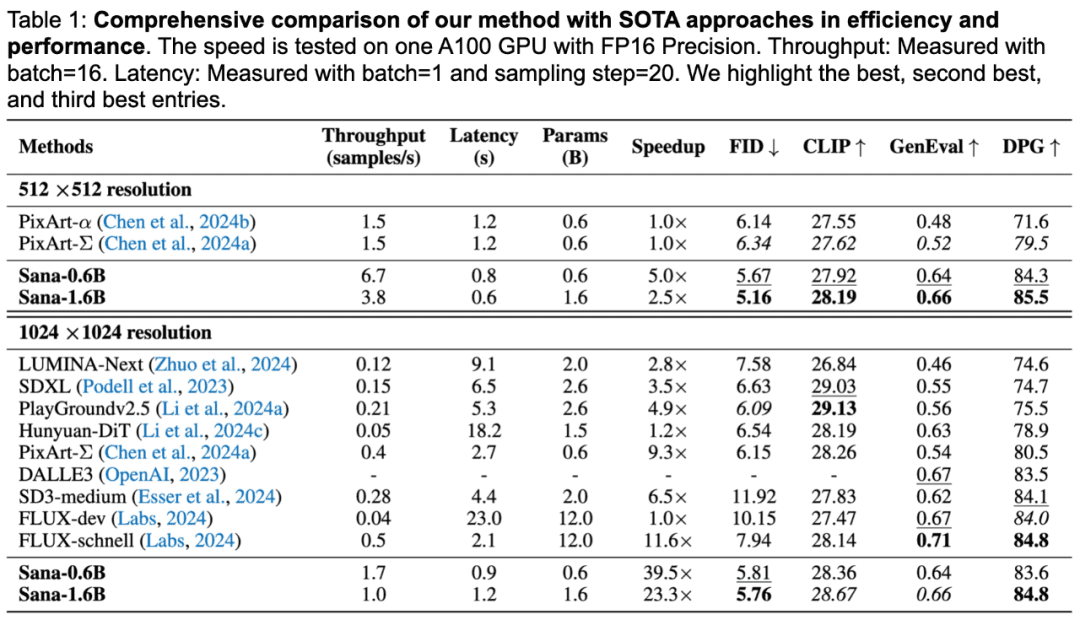
Actuación de SANA
SANA se caracteriza por la palabra rápido. SANA-0.6B tarda menos de un segundo en generar imágenes de 1024×1024 de resolución, 25 veces más rápido que Flux-Dev, mientras que generar imágenes de 4096×4096 de resolución es 106 veces más rápido que Flux-Dev.

En cuanto a la calidad de la generación, SANA obtiene la misma puntuación que Flux en la prueba de referencia DPG-Bench y sólo se sitúa ligeramente por debajo del modelo Flux en la métrica GenEval.
Diseño básico de SANA
El éxito de SANA se debe a sus cuatro diseños básicos:
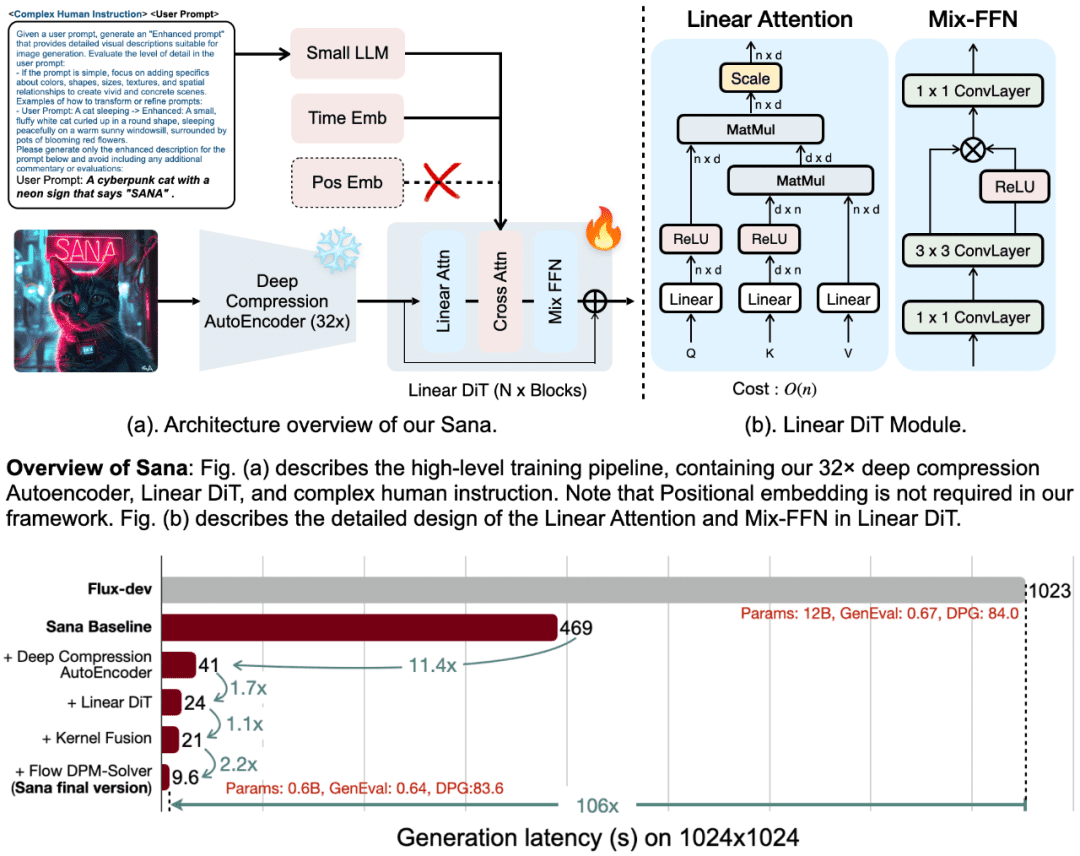
1. Autocodificador de compresión profunda (DC-AE)
Mientras que los autocodificadores (AEs) convencionales suelen comprimir las imágenes por un factor de 8, SANA introduce un autocodificador de compresión profunda que aumenta el factor de compresión hasta 32. Este diseño reduce drásticamente el número de marcadores potenciales, lo que permite a SANA generar eficientemente imágenes de resolución ultraalta (por ejemplo, resolución 4K) al tiempo que reduce significativamente el coste computacional de entrenamiento y generación.
2. DIT lineal (transformador de imagen de difusión)
SANA emplea un nuevo mecanismo de atención lineal en lugar del mecanismo de atención cuadrática tradicional, lo que reduce la complejidad de O(N²) a O(N). Esta mejora no sólo aumenta la eficiencia de la generación de imágenes de alta resolución, sino que también elimina la necesidad de codificación posicional, marcando el primer modelo DIT que no requiere incrustación posicional.
3. Pequeños LLM sólo decodificadores como codificadores de texto
SANA utiliza pequeños modelos lingüísticos sólo descodificadores, como Gemma 2, como codificadores de texto, en sustitución de los modelos tradicionales CLIP o T5.Gemma tiene capacidades superiores de comprensión de texto y adherencia a las instrucciones, lo que, combinado con un sofisticado diseño de instrucciones manuales, mejora significativamente la alineación imagen-texto.
4. Estrategias eficaces de formación y razonamiento
SANA propone una estrategia automática de etiquetado y entrenamiento que genera diferentes re-captions con múltiples Visual Language Models (VLMs) y selecciona subtítulos de alta calidad basándose en CLIPScore, acelerando así la convergencia de modelos y mejorando la alineación texto-imagen. Además, SANA introduce Flow-DPM-Solver, que reduce drásticamente los pasos de inferencia y mejora aún más la eficiencia de la generación.
Implantación de bajo coste y código abierto
SANA-0.6B puede ejecutarse en la GPU de un portátil de 16 GB, generando imágenes de 1024×1024 de resolución en menos de 1 segundo, y 22 GB de memoria de vídeo pueden enderezar imágenes de 4096×4096 de resolución, una característica que hace que SANA no sólo sea adecuado para dispositivos informáticos de gama alta, sino que también puede ejecutarse eficientemente en los ordenadores portátiles de los usuarios normales. usuarios normales. Además, NVIDIA también ha anunciado que hará públicos el código y el modelo de SANA, lo que promoverá aún más la popularidad y la aplicación de la tecnología de generación de texto a imagen.
utilizar
NVIDIA ha creado ocho interfaces de uso web 3090 que pueden probarse gratuitamente. Cabe destacar que el modelo SANA puede utilizarse directamente con palabras de aviso chinas.
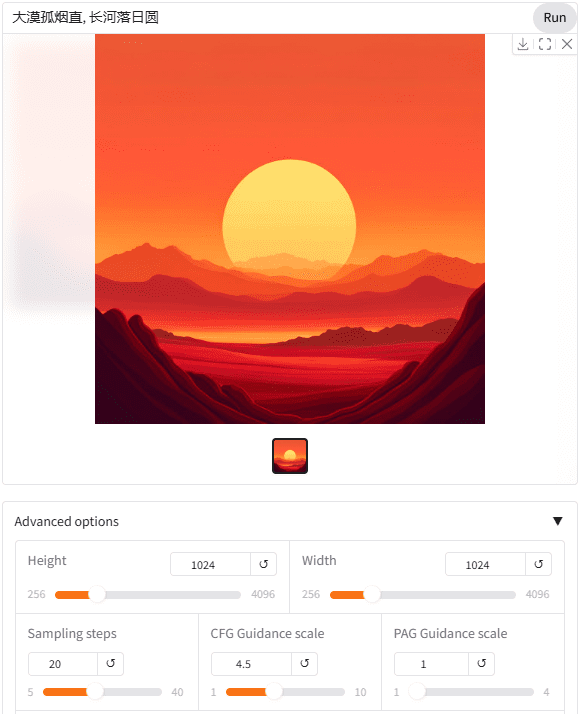
Incluso es posible el uso de palabras clave con símbolos de icono, lo que debería beneficiarse del uso del modelo de lenguaje visual Gemma2 2B como codificador de texto.

Con el plugin ComfyUI_ExtraModels, es muy fácil utilizar modelos SANA en Comfyui nativo también. Instalación del plugin es muy simple, no es necesario configurar sus propias dependencias, ejecutar después de la instalación se descargará automáticamente los archivos de modelo necesarios.
Con autoencoder de compresión profunda, DIT lineal, LLM pequeño sólo para el decodificador, y estrategias eficientes de formación e inferencia, SANA no sólo es capaz de generar eficientemente imágenes de resolución ultra alta, sino que también tiene fuertes capacidades de alineación texto-imagen y ventajas de despliegue de bajo coste. Para quienes necesiten producir imágenes rápidamente, SANA sigue siendo bueno, es decir, en términos de ecología no puede compararse con Flux.

Página del proyecto:
github.com/NVlabs/Sana
Uso de la web:
nv-sana.mit.edu
Plugin Comfyui:
github.com/Efficient-Large-Model/ComfyUI_ExtraModels
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados




Sin comentarios...