
El nuevo modelo de Microsoft: Phi-4 ya está aquí, con parámetros 14B comparables a los modelos a mayor escala

Con sólo 14.000 millones (14B) de parámetros, Phi-4 demuestra un rendimiento comparable o incluso superior al de algunos modelos a mayor escala mediante métodos de entrenamiento innovadores y datos de alta calidad. En este artículo se describen en detalle la arquitectura, las características, la metodología de entrenamiento y el rendimiento de Phi-4 en aplicaciones y pruebas de referencia reales.
https://github.com/xinyuwei-david/david-share.git
I. Indicadores para medir la capacidad

Mide tres preguntas comparando o1 y Phi-4
Primera pregunta:
phi-4

o1

Segunda pregunta:
Phi-4.

o1:
Tercera pregunta:
Phi-4

o1.
要求五个连续偶数的平均数,已知它们的和为90,下面我们逐步解答。步骤1:设未知数设这五个连续的偶数为:第一个偶数:( n - 4 )第二个偶数:( n - 2 )第三个偶数:( n )第四个偶数:( n + 2 )第五个偶数:( n + 4 )(因为偶数之间相差2,所以相邻的偶数可以这样表示)步骤2:列方程求和根据题目,五个数的和为90:[(n - 4) + (n - 2) + n + (n + 2) + (n + 4) = 90]步骤3:简化方程合并同类项:[5n = 90]步骤4:求解 n[n = frac{90}{5} = 18]步骤5:求出五个偶数第一个偶数:( 18 - 4 = 14 )第二个偶数:( 18 - 2 = 16 )第三个偶数:( 18 )第四个偶数:( 18 + 2 = 20 )第五个偶数:( 18 + 4 = 22 )步骤6:计算平均数平均数等于总和除以数量:[text{平均数} = frac{14 + 16 + 18 + 20 + 22}{5} = frac{90}{5} = 18]答案:这五个连续的偶数的平均数是 18。
Si lo miras así, el razonamiento de Phi-4 sigue siendo correcto.
II. Phi-4 arquitectura modelo
1. Arquitectura del descodificador basado en transformadores
Phi-4 emplea un sistema basado en la Transformador (utilizado como expresión nominal) Sólo decodificador Esta arquitectura es similar a la familia de modelos GPT. Esta arquitectura utiliza el mecanismo de autoatención para capturar eficazmente las dependencias a largo plazo en secuencias de texto y destaca en tareas de generación de lenguaje natural.
2. Tamaño del parámetro y número de capas
- Número total de parámetros: 14 000 millones (14B) Parámetros.
- Número de pisos modelo: 40
3. Longitud del contexto
- Longitud inicial del contexto: 4,096 Ficha.
- Ampliación de la formación a medio plazo: En la fase media de entrenamiento, la longitud del contexto de Phi-4 se amplió a 16,000 Token (16K), que mejora la capacidad del modelo para manejar textos largos.
4. Glosario y lexer
- Separadores: Utilizando OpenAI Divisor de tiktokenLa empresa admite varios idiomas y tiene un mejor efecto de división de palabras.
- Tamaño del glosario: 100,352Esto incluye algunos Token reservados no utilizados.
III. Mecanismos de atención y codificación de la posición
1. Mecanismos globales de atención
Phi-4 utiliza Mecanismo de atención plenaes decir, la autoatención se calcula para toda la secuencia de contextos. Esto contrasta con el modelo predecesor, Phi-3-medio, que utiliza 2.048 Ficha de la ventana deslizante, mientras que Phi-4 realiza el cálculo de la atención global directamente en los contextos de 4.096 Token (inicial) y 16.000 Token (ampliado), lo que mejora la capacidad del modelo para capturar dependencias de largo alcance.
2. Codificación de posición rotativa (RoPE)
Para poder utilizar contextos más largos, Phi-4 se adaptó a mitad de la formación para Incrustaciones de posición rotativa (RoPE) de la frecuencia base:
- Ajuste de la frecuencia base: Aumentar la frecuencia base de RoPE a 250,000para acomodar la longitud de contexto de 16K.
- Papel: RoPE ayuda al modelo a mantener la eficacia de la codificación posicional en secuencias largas, lo que permite al modelo mantener un buen rendimiento en textos más largos.
IV. Estrategias y métodos de formación
1. El concepto de priorizar la calidad de los datos
La estrategia de formación de Phi-4 se basa en Calidad de los datos al núcleo. A diferencia de otros modelos que se entrenan previamente utilizando principalmente datos orgánicos de Internet (por ejemplo, contenido web, código, etc.), Phi-4 introduce estratégicamente a lo largo del proceso de entrenamiento una Datos sintéticos.
2. Generación y aplicación de datos sintéticos
Datos sintéticos desempeñó un papel clave en el preentrenamiento y el entrenamiento intermedio de Phi-4:
- Múltiples técnicas de generación de datos:
- Multi-Agent Prompting: La diversidad de datos se enriquece con el uso de múltiples modelos lingüísticos o agentes para la cogeneración de datos.
- Flujos de trabajo de autorrevisión: Una vez que el modelo genera el resultado inicial, realiza una autoevaluación y corrección para mejorar iterativamente la calidad del resultado.
- Inversión de la instrucción: Generar las instrucciones de entrada correspondientes a partir de las salidas existentes mejora la capacidad del modelo para comprender y generar instrucciones.
- Ventajas de los datos sintéticos:
- Aprendizaje estructurado y progresivo: Los datos sintéticos permiten controlar con precisión la dificultad y el contenido, guiando gradualmente al modelo para que aprenda habilidades complejas de razonamiento y resolución de problemas.
- Mejorar la eficacia de la formación: La generación de datos sintéticos puede proporcionar datos de entrenamiento específicos para los puntos débiles del modelo.
- Evitar la contaminación de datos: Dado que se generan datos sintéticos, se evita el riesgo de que los datos de entrenamiento contengan el contenido del conjunto de revisiones.
3. Cribado fino y filtrado de datos orgánicos
Además de los datos sintéticos, Phi-4 se centra en seleccionar y filtrar cuidadosamente datos de alta calidad procedentes de múltiples fuentes Datos orgánicos::
- Fuentes de datos: Incluye contenidos web, libros, bibliotecas de códigos, artículos académicos y mucho más.
- Filtrado de datos:
- Elimine los contenidos de baja calidad: Utilice métodos automatizados y manuales para filtrar contenidos sin sentido, incorrectos, duplicados o perjudiciales.
- Prevención de la contaminación de datos: Se utilizó un algoritmo híbrido de n-gramas (13-gramas y 7-gramas) para la desduplicación y la descontaminación con el fin de garantizar que los datos de formación no contuvieran contenidos del conjunto de revisiones.
4. Estrategia de mezcla de datos
Phi-4 se optimizó en la composición de los datos de entrenamiento con las siguientes proporciones:
- Datos sintéticos: tomar posesión de 40%.
- Reescrituras web: tomar posesión de 15%En el caso de una nueva muestra de formación, se reescribe a partir de contenidos web de alta calidad para generar una nueva muestra de formación.
- Datos orgánicos de la Web: tomar posesión de 15%Se trata de una selección de contenidos web valiosos.
- Código de datos: tomar posesión de 20%incluyendo el código base público y los datos de síntesis del código generado.
- Adquisiciones selectivas: tomar posesión de 10%como artículos académicos, libros profesionales y otros contenidos de gran valor.
5. Proceso de formación en varias etapas
Fase de preentrenamiento:
- Objetivo: Modelización de la comprensión lingüística subyacente y de las capacidades generativas.
- Volumen de datos: pedir cita 10 billones (10T) Ficha.
Fase de formación a medio plazo:
- Objetivo: Ampliar la longitud del contexto para mejorar el tratamiento de textos largos.
- Volumen de datos: 250.000 millones (250B) Ficha.
Fase posterior al entrenamiento (puesta a punto):
- Ajuste fino supervisado (SFT): El perfeccionamiento mediante datos multidominio de alta calidad mejora la capacidad del modelo para seguir instrucciones y la calidad de las respuestas.
- Optimización directa de preferencias (OPD): utilice Búsqueda de fichas Pivotal (PTS) y otros métodos para optimizar aún más los resultados del modelo.
V. Técnicas de formación innovadoras
1. Búsqueda de fichas Pivotal (PTS)
Metodología STP es una innovación importante en el proceso de formación Phi-4:
- Principio: Al identificar los tokens clave que tienen un impacto significativo en la corrección de la respuesta durante el proceso de generación, el modelo se dirige a optimizar la predicción sobre estos tokens.
- Ventaja:
- Mejorar la eficacia de la formación: Centrar la optimización en las partes que más influyen en los resultados es el doble de eficaz.
- Mejora del rendimiento del modelo: Ayuda al modelo a tomar las decisiones correctas en los momentos clave y mejora la calidad general del resultado.
2. Optimización directa de preferencias (OPD) mejorada
- Método DPO: La optimización se realiza directamente utilizando los datos de preferencias para que el resultado del modelo sea más coherente con las preferencias humanas.
- Puntos de innovación:
- Combinado con PTS: La introducción de pares de datos de entrenamiento generados por la STP en la OPD mejora la optimización.
- Evaluación de los indicadores: Mida la optimización con mayor precisión evaluando el rendimiento del modelo en Token clave.
VI. Características y ventajas del modelo
1. Excelente rendimiento
- Modelos pequeños, grandes capacidades: Aunque la escala de parámetros es sólo 14BSin embargo, Phi-4 obtiene buenos resultados en varias pruebas comparativas, especialmente en tareas de razonamiento y resolución de problemas.
2. Excelente capacidad de razonamiento
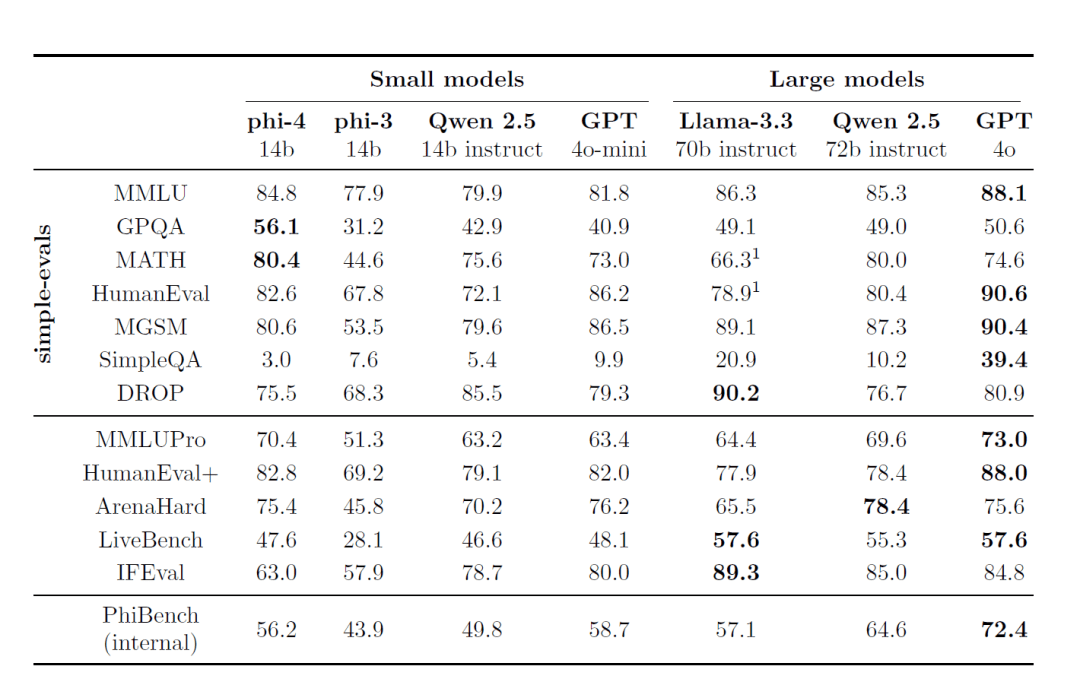
- Resolución de problemas matemáticos y científicos: existe GPQAyMATEMÁTICAS En pruebas de referencia como ésta, Phi-4 obtiene incluso mejores resultados que su modelo para profesores GPT-4o.
3. Gran capacidad de procesamiento contextual
- Ampliación de la longitud del contexto: Al ampliar la longitud del contexto a mitad de la formación a 16,000 Token, Phi-4 es capaz de manejar con mayor eficacia textos largos y dependencias a larga distancia.
4. Soporte multilingüe
- Cobertura de varias lenguas: Los datos de entrenamiento consistieron en Alemán, español, francés, portugués, italiano, hindi, japonés y muchas otras lenguas.
- Competencia interlingüística: Destaca en tareas como la traducción y el cuestionario interlingüístico.
5. Seguridad y conformidad
- Principios de la IA responsable: El proceso de desarrollo sigue estrictamente los Principios de IA Responsable de Microsoft, centrándose en la seguridad y la ética del modelo.
- Descontaminación de datos y protección de la intimidad: Se utilizan estrategias estrictas de desduplicación y filtrado de datos para evitar que se incluyan contenidos sensibles en los datos de formación.
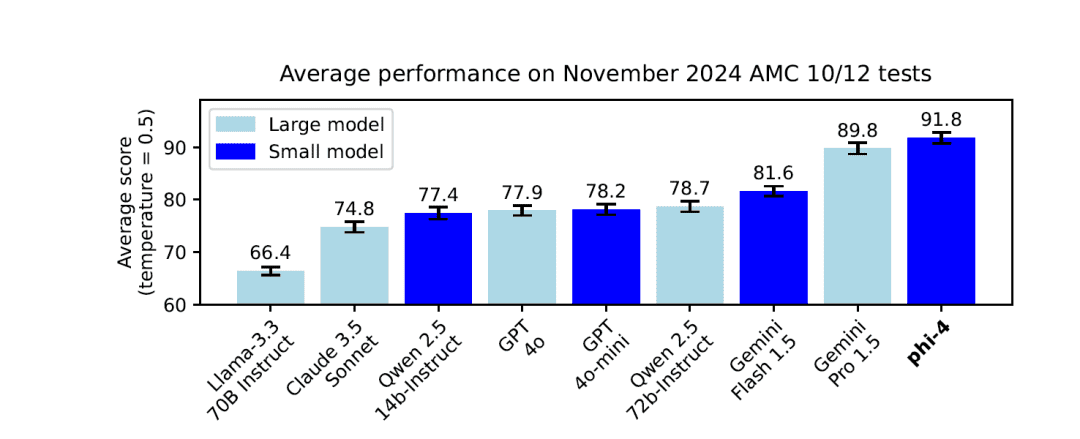
VII. Puntos de referencia y resultados
1. Evaluación comparativa externa
Phi-4 demuestra un rendimiento líder en varios puntos de referencia de revisión disponibles públicamente:
- MMLU (Multitasking Language Understanding): Obtuvo excelentes resultados en pruebas complejas de comprensión multitarea.
- GPQA (cuestionario STEM para licenciados): sobresalió en la difícil prueba STEM, obteniendo una puntuación más alta que algunos de los modelos a mayor escala.
- MATH (concurso de matemáticas): En la resolución de problemas matemáticos, Phi-4 demuestra una gran capacidad de razonamiento y cálculo.
- HumanEval / HumanEval+ (generación de código): En las tareas de generación y comprensión de código, Phi-4 supera a modelos de su tamaño, e incluso se acerca a modelos mayores.
2. Paquete de evaluación interna (PhiBench)
Para conocer las capacidades y deficiencias del modelo, el equipo elaboró un conjunto especializado de evaluación interna PhiBench::
- La tarea de la diversificación: Incluye depuración de código, finalización de código, razonamiento matemático e identificación de errores.
- Orientación sobre la optimización de modelos: Analizando las puntuaciones de PhiBench, el equipo pudo introducir mejoras en el modelo.
VIII. Seguridad y responsabilidad
1. Estrategia estricta de alineación de la seguridad
El desarrollo de Phi-4 se produce después de que Microsoft Principios para una IA responsable, centrándose en la seguridad y la ética del modelo durante el entrenamiento y la puesta a punto:
- Protección contra contenidos nocivos: Reduzca la probabilidad de que el modelo genere contenidos inadecuados incluyendo datos de ajuste de seguridad en la fase posterior al entrenamiento.
- Pruebas de equipo rojo y evaluación automatizada: Se realizaron extensas pruebas de equipo rojo y evaluaciones de seguridad automatizadas, que abarcaron docenas de categorías de riesgos potenciales.
2. Descontaminación de datos y prevención del sobreajuste
- Estrategias mejoradas de descontaminación de datos: Se utiliza un algoritmo híbrido de 13 gramos y 7 gramos para eliminar cualquier posible solapamiento de los datos de entrenamiento con las referencias de revisión y evitar el sobreajuste del modelo.
IX. Recursos y tiempo de formación
1. Tiempo de formación
Aunque el informe oficial no especifica el tiempo total de entrenamiento para el Phi-4, considere:
- Modelo a escala: Parámetros 14B.
- Volumen de datos de formación: Fase de preentrenamiento 10T Token, a mitad de entrenamiento 250B Token.
Cabe suponer que todo el proceso de formación llevó un tiempo considerable.
2. Consumo de recursos de la GPU
| GPUs | 1920 H100-80G |
| Tiempo de formación | 21 días |
| Datos de formación | 9.8T fichas |
X. Aplicaciones y limitaciones
1. Escenarios de aplicación
- Sistema de preguntas y respuestas: Phi-4 rinde bien en tareas de cuestionamiento complejas y es adecuado para todo tipo de aplicaciones de cuestionamiento inteligente.
- Generación y comprensión de códigos: Excelente en tareas de programación y puede utilizarse en escenarios como la tutoría de código, la generación automática y la depuración.
- Traducción y tratamiento multilingües: Soporte multilingüe para servicios lingüísticos globalizados.
2. Limitaciones potenciales
- Límite de conocimientos: El conocimiento del modelo se corta en los datos de entrenamiento y puede no saber nada de los sucesos que ocurren después del entrenamiento.
- Reto de la secuencia larga: Aunque la longitud del contexto se amplía a 16K, aún puede haber problemas cuando se trata de secuencias más largas.
- Control de riesgos: A pesar de las estrictas medidas de seguridad, los modelos pueden ser objeto de ataques de adversarios o de la generación inadvertida de contenidos inapropiados.
El éxito de Phi-4 demuestra la importancia de la calidad de los datos y la estrategia de entrenamiento en el desarrollo de modelos lingüísticos a gran escala. Gracias a innovadores métodos de generación de datos sintéticos, cuidadosas estrategias de mezcla de datos de entrenamiento y avanzadas técnicas de entrenamiento, Phi-4 logra un rendimiento excelente manteniendo un tamaño de parámetros reducido:
- La capacidad de razonamiento es sobresaliente: Destaca en las áreas de matemáticas, ciencias y programación.
- Tratamiento de textos largos: La mayor longitud del contexto confiere al modelo una ventaja en tareas de tratamiento de textos largos.
- Seguridad y responsabilidad: El estricto cumplimiento de los principios de la IA responsable garantiza que los modelos sean seguros y éticos.
Phi-4 establece un nuevo punto de referencia en el desarrollo de modelos cuantitativos paramétricos pequeños, demostrando que, centrándose en la calidad de los datos y las estrategias de entrenamiento, se puede lograr un rendimiento superior incluso a escalas de parámetros más pequeñas.
Referencias: /https://www.microsoft.com/en-us/research/uploads/prod/2024/12/P4TechReport.pdf
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...