VideoChat: persona digital interactiva de voz en tiempo real con clonación personalizada de imágenes y tonos, compatible con soluciones de voz de extremo a extremo y soluciones en cascada.
Últimos recursos sobre IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 60.9K 00

Introducción general
VideoChat es un proyecto de humano digital de interacción vocal en tiempo real basado en tecnología de código abierto, compatible con esquemas de voz de extremo a extremo (GLM-4-Voice - THG) y en cascada (ASR-LLM-TTS-THG). El proyecto permite a los usuarios personalizar la imagen y el timbre del humano digital, y admite clonación de timbre y sincronización labial, salida de streaming de vídeo y latencia del primer paquete tan baja como 3 segundos. Los usuarios pueden experimentar su funcionalidad a través de demostraciones en línea, o desplegarlo y utilizarlo localmente gracias a una detallada documentación técnica.
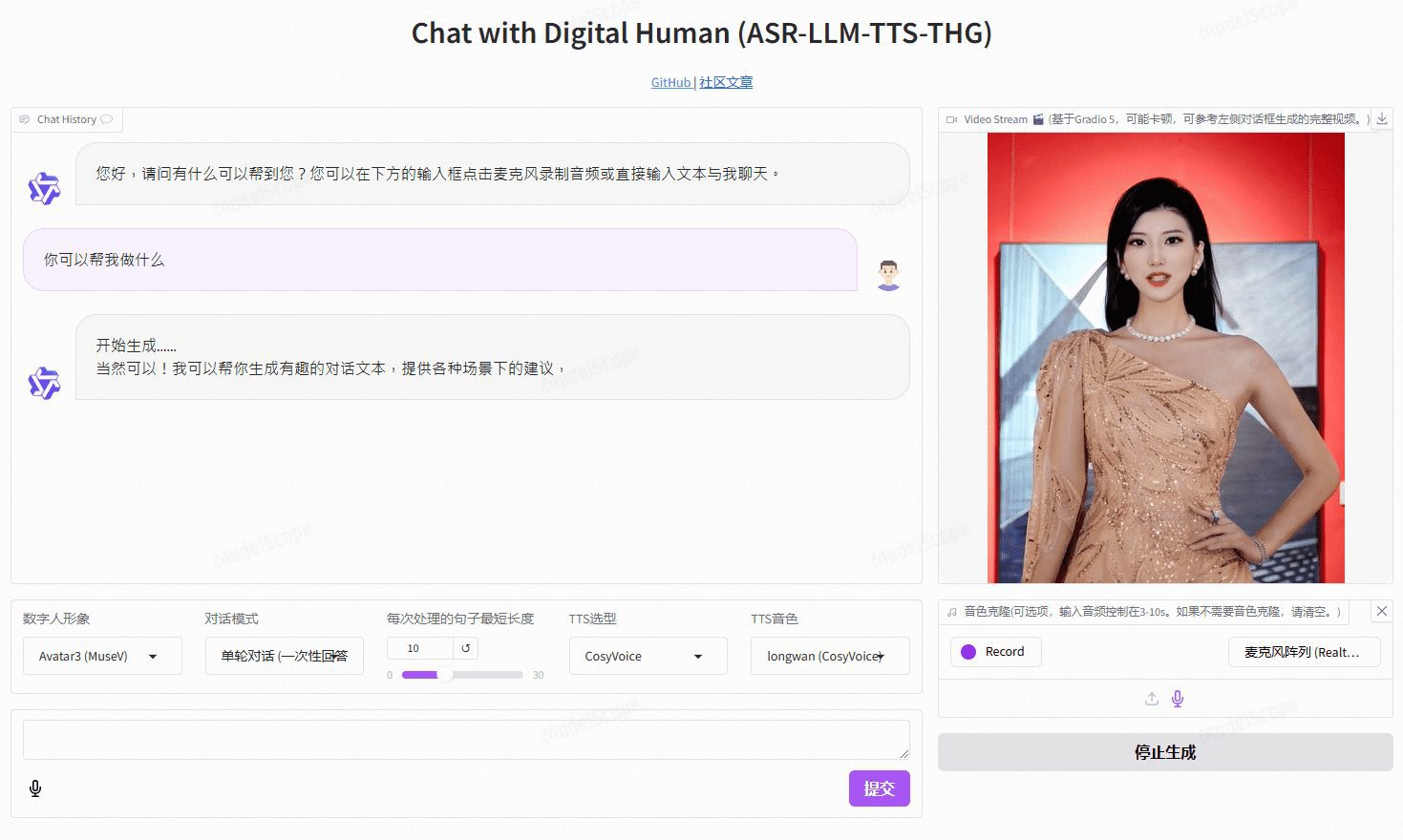
Dirección de demostración: https://www.modelscope.cn/studios/AI-ModelScope/video_chat
Lista de funciones
- Interacción vocal en tiempo real: compatibilidad con soluciones vocales integrales y en cascada
- Imagen y tono personalizados: los usuarios pueden personalizar el aspecto y el sonido de la persona digital según sus necesidades.
- Clonación de voz: permite clonar la voz del usuario para ofrecer una experiencia de voz personalizada.
- Baja latencia: latencia del primer paquete tan baja como 3 segundos para garantizar una experiencia de interacción fluida.
- Proyecto de código abierto: basado en tecnología de código abierto, los usuarios pueden modificar y ampliar libremente la función
Utilizar la ayuda
Proceso de instalación
- Configuración del entorno
- Sistema operativo: Ubuntu 22.04
- Versión de Python: 3.10
- Versión de CUDA: 12.2
- Versión de la linterna: 2.1.2
- proyecto de clonación
git lfs install git clone https://github.com/Henry-23/VideoChat.git cd video_chat - Creación de un entorno virtual e instalación de dependencias
conda create -n metahuman python=3.10 conda activate metahuman pip install -r requirements.txt pip install --upgrade gradio - Descargar el archivo de pesos
- Se recomienda utilizar CreateSpace para descargar, han configurado git lfs para realizar un seguimiento de los archivos de peso
git clone https://www.modelscope.cn/studios/AI-ModelScope/video_chat.git - Inicio de los servicios
python app.py
Proceso de utilización
- Configuración de la API-KEY::
- Si el rendimiento de la máquina local es limitado, puede utilizar la API Qwen y la API CosyVoice proporcionadas por la plataforma de servicios de grandes modelos de Aliyun, Hundred Refine, en la máquina local.
app.pyConfigure la API-KEY en el
- Si el rendimiento de la máquina local es limitado, puede utilizar la API Qwen y la API CosyVoice proporcionadas por la plataforma de servicios de grandes modelos de Aliyun, Hundred Refine, en la máquina local.
- inferencia local::
- Si no utiliza la API-KEY, puede utilizarla en el campo
src/llm.pyresponder cantandosrc/tts.pyConfigure el método de inferencia local en para eliminar el código de llamada a la API innecesario.
- Si no utiliza la API-KEY, puede utilizarla en el campo
- Inicio de los servicios::
- estar en movimiento
python app.pyInicie el servicio.
- estar en movimiento
- Personalización de la persona digital::
- existe
/data/video/Catálogo para añadir un vídeo grabado de la imagen digital de la persona. - modificaciones
/src/thg.pyen la avatar_list de la clase Muse_Talk, añadiendo el nombre de la imagen y bbox_shift. - existe
app.pyTras añadir el nombre de la persona digital a avatar_name en Gradio, reinicia el servicio y espera a que se complete la inicialización.
- existe
Procedimiento de funcionamiento detallado
- Imagen y tono personalizados: en
/data/video/directorio para añadir un vídeo grabado de la imagen humana digital alsrc/thg.pymodificaciónMuse_Talkclaseavatar_listañada el nombre de la imagen ybbox_shiftParámetros. - clonación de voz: en
app.pyConfiguración mediaCosyVoice APIo utilizandoEdge_TTSRealiza un razonamiento local. - Soluciones de voz de extremo a extremo: Uso
GLM-4-Voicepara ofrecer una generación y un reconocimiento eficaces del habla.
- Visite la dirección del servicio desplegado localmente y vaya a la interfaz de Gradio.
- Seleccione o cargue un vídeo personalizado de persona digital.
- Configure la función de clonación de voz para cargar la muestra de voz de un usuario.
- Inicie la interacción por voz en tiempo real y experimente las funciones de diálogo de baja latencia.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...