
Implantación local de Vanna: conversiones Text2SQL eficientes con facilidad
Tutoriales prácticos sobre IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 63.9K 00

Vanna es un marco de código abierto Text2SQL muy apreciado que transforma el lenguaje natural en sentencias de consulta SQL. En este artículo se detalla cómo implementar Vanna localmente y combinarlo con una base de datos MySQL y la aplicación Búsqueda profunda Los modelos están configurados y probados para ayudarle a empezar a utilizar la herramienta rápidamente. Todas las operaciones se basan en pruebas reales para garantizar que los pasos sean claros y viables.
Configuración del entorno Python
Para ejecutar Vanna, primero necesitas un entorno Python estable. Aquí tienes una guía paso a paso para configurar Vanna, usando Miniconda3 como ejemplo.
Instalación de Miniconda3
- Descargue el paquete de instalación:
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh - Ejecute el script de instalación:
sh Miniconda3-latest-Linux-x86_64.sh - Configurar variables de entorno:
vim /etc/profileAñádelo al archivo:
export PATH="/data/apps/miniconda3/bin:$PATH"Guarde y actualice la configuración:
source /etc/profile - Si necesitas desinstalar, sólo tienes que borrar el directorio de instalación:
rm -rf /data/apps/miniconda3/
Creación de un entorno virtual
- Crea un entorno Python 3.10:
conda create -n test python=3.10 - Activar el entorno (debe surtir efecto en un nuevo terminal o tras un reinicio):
conda activate test - Otros comandos comunes:
- Entorno de salida:
conda deactivate - Ver información medioambiental:
conda info --env
- Entorno de salida:
Después de completar los pasos anteriores, tienes un entorno virtual Python independiente que sienta las bases para el despliegue de Vanna.
Implantación y configuración de Vanna
Con el entorno Python listo, pasemos a la configuración del núcleo de Vanna. Las siguientes operaciones hacen referencia a la documentación oficial (https://vanna.ai/docs/) y utilizan la base de datos MySQL como ejemplo.
Configuración de la conexión a la base de datos
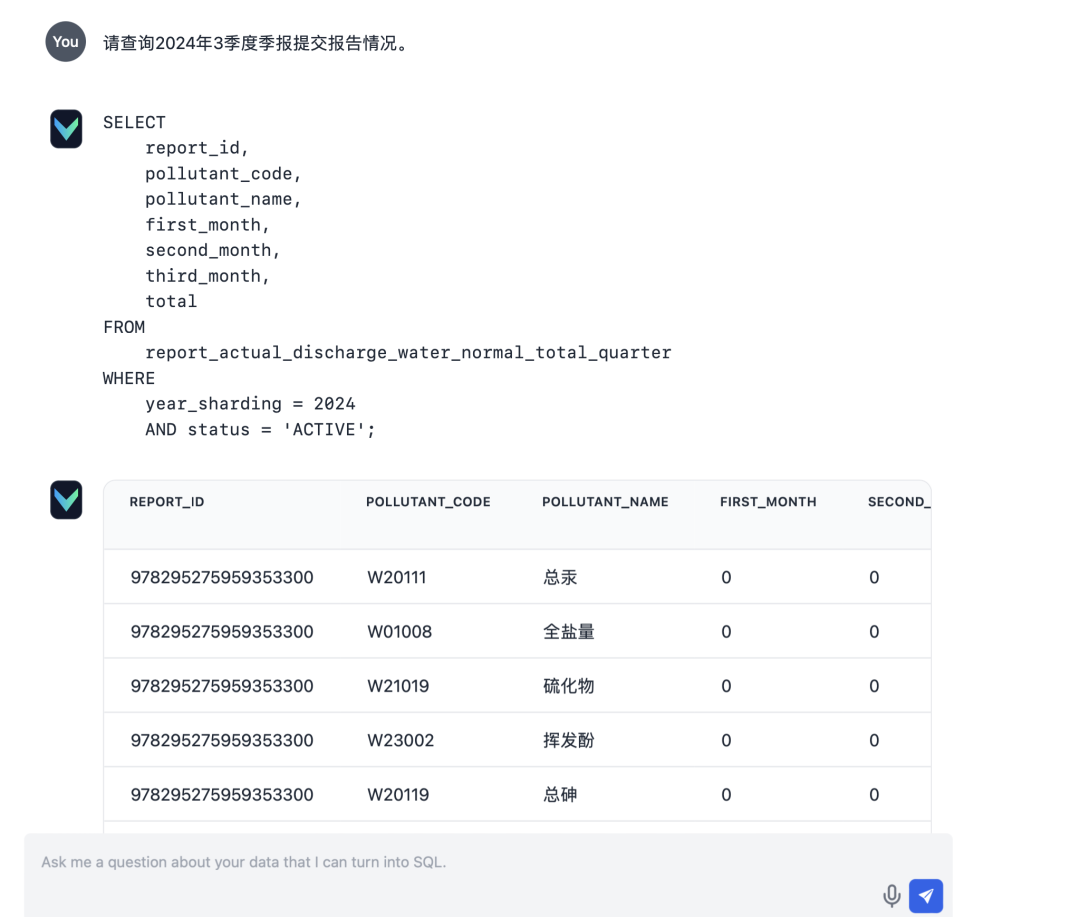
En primer lugar, asegúrate de que puedes conectarte correctamente a la base de datos con tu cuenta MySQL, contraseña y puerto. Después de probar una conexión correcta, abre la página de configuración de MySQL en la documentación oficial de Vanna (selecciona MySQL en la barra de menú de la izquierda). La página mostrará un código de conexión de ejemplo, como se muestra a continuación:
Basándose en la información de su base de datos, ajuste los parámetros en el código (por ejemplo, host, usuario, contraseña, etc.) para asegurarse de que Vanna se conecta sin problemas.
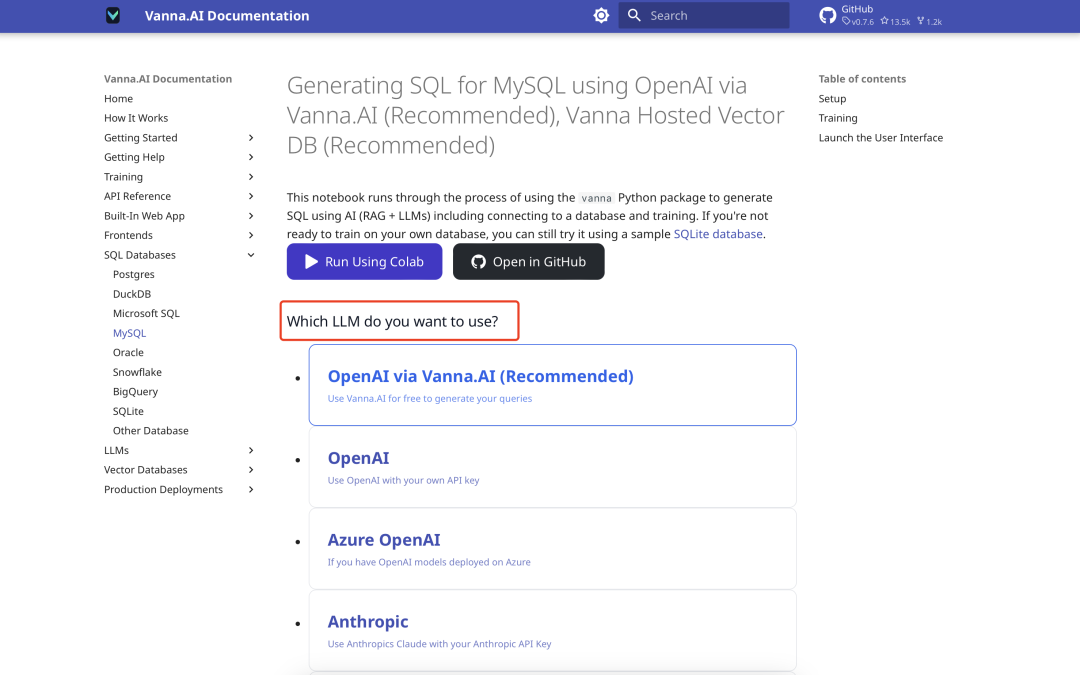
Elegir un modelo lingüístico
Vanna admite una gran variedad de grandes modelos lingüísticos (LLM). La página oficial solicita la selección del modelo, por ejemplo Ollama o llamadas a la API. El modelo Deepseek para flujos basados en silicio se ilustra aquí a modo de ejemplo.
- La experiencia de OllamaSe ha intentado utilizar el modelo cuantificado Deepseek-7b con resultados poco satisfactorios, por lo que se recomienda prescindir de esta opción.
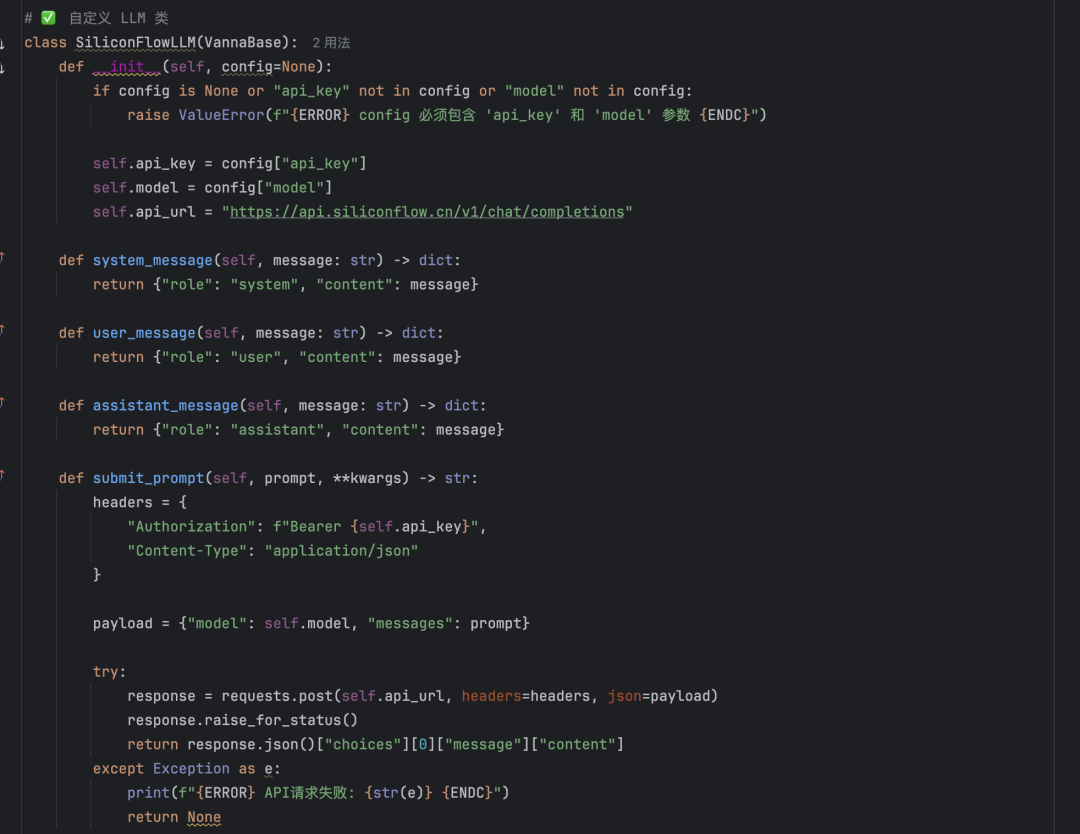
- API de DeepseekLa llamada a modelos Deepseek a través de flujos in silico funciona mejor. Tenga en cuenta, sin embargo, que se requieren clases LLM personalizadas para utilizar modelos que no están soportados oficialmente. Véase el proyecto de código abierto Vanna Mistral (mistral.py), cree una clase adaptada a Deepseek en consecuencia.
La pantalla de configuración es la siguiente:
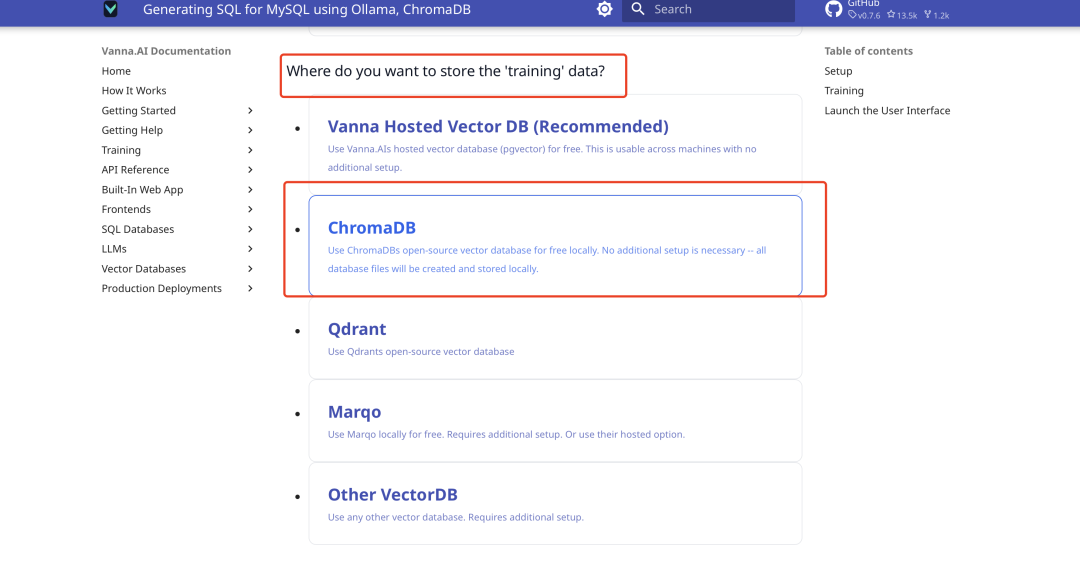
Configuración de la base de datos vectorial
Vanna integra ChromaDB como una pequeña base de datos vectorial por defecto, no requiere instalación adicional. La documentación oficial generará código según su elección, como se muestra a continuación:
Instalación de dependencias y preparación del código
- Instale Vanna y sus dependencias en un entorno virtual activado:
pip install vanna - Crear un
.pycopie en él el código generado oficialmente. A continuación se muestra un fragmento de código de ejemplo para adaptar MySQL y Deepseek (es necesario ajustar los parámetros de acuerdo a la situación real):from vanna.remote import VannaDefault vn = VannaDefault(model='deepseek', api_key='your_api_key') vn.connect_to_mysql(host='localhost', dbname='test_db', user='root', password='your_password', port=3306)
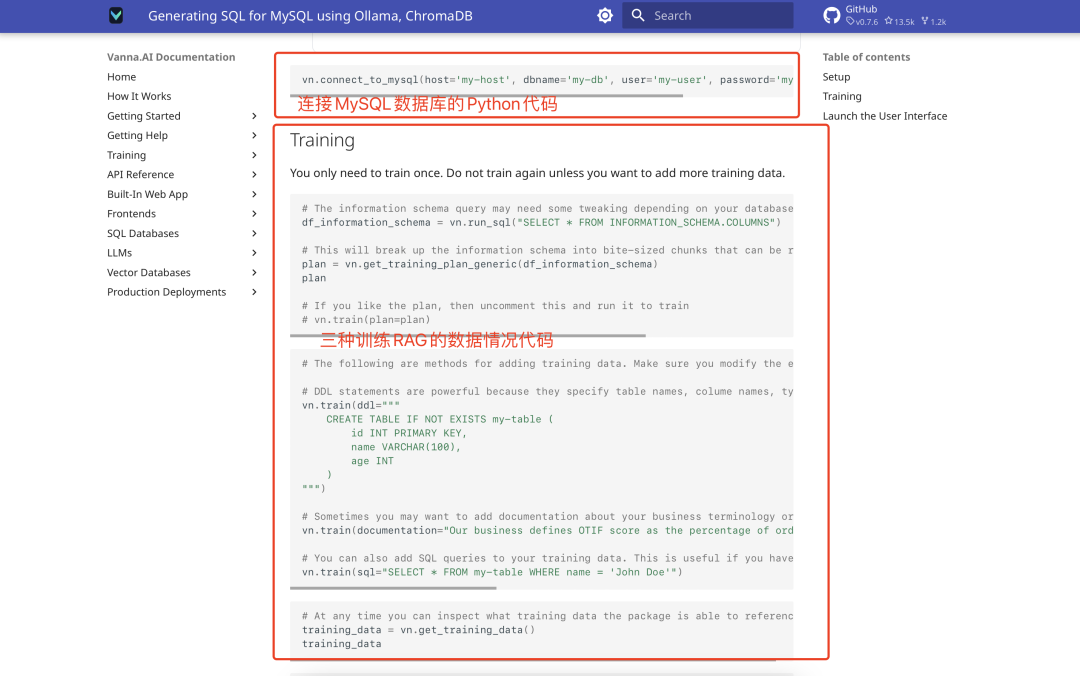
formación de datos
Vanna admite tres tipos de datos de formación: sentencias SQL, documentación de productos y descripciones de la estructura de tablas de bases de datos. Aquí recomendamos utilizar la descripción de la estructura de la tabla, el efecto es más intuitivo. Los pasos de entrenamiento son los siguientes:
- Preparar los datos de la estructura de la tabla (por ejemplo, archivo DDL).
- Utilice el código de formación facilitado oficialmente:
vn.train(ddl="CREATE TABLE employees (id INT, name VARCHAR(255), salary INT)") - A continuación se muestra el proceso de formación:
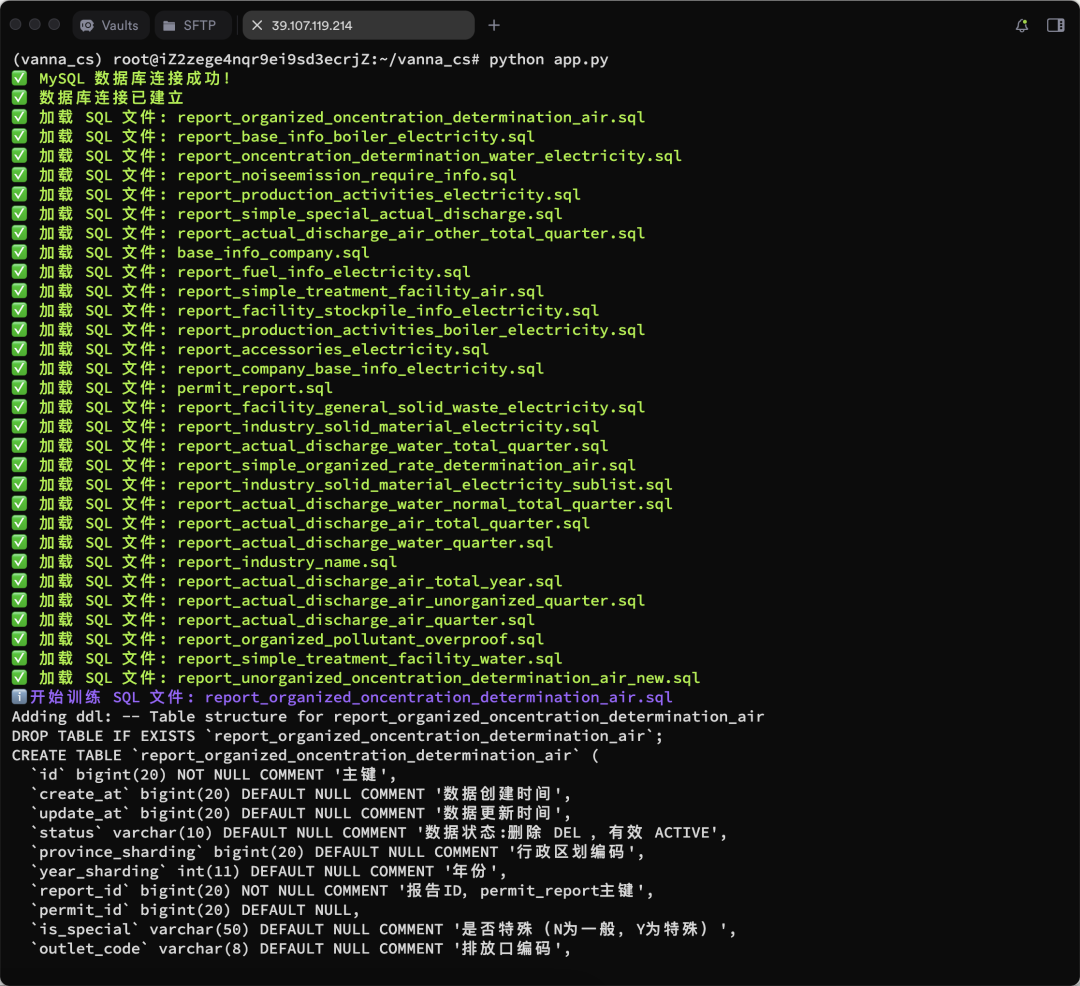
Se muestran más resultados del entrenamiento:
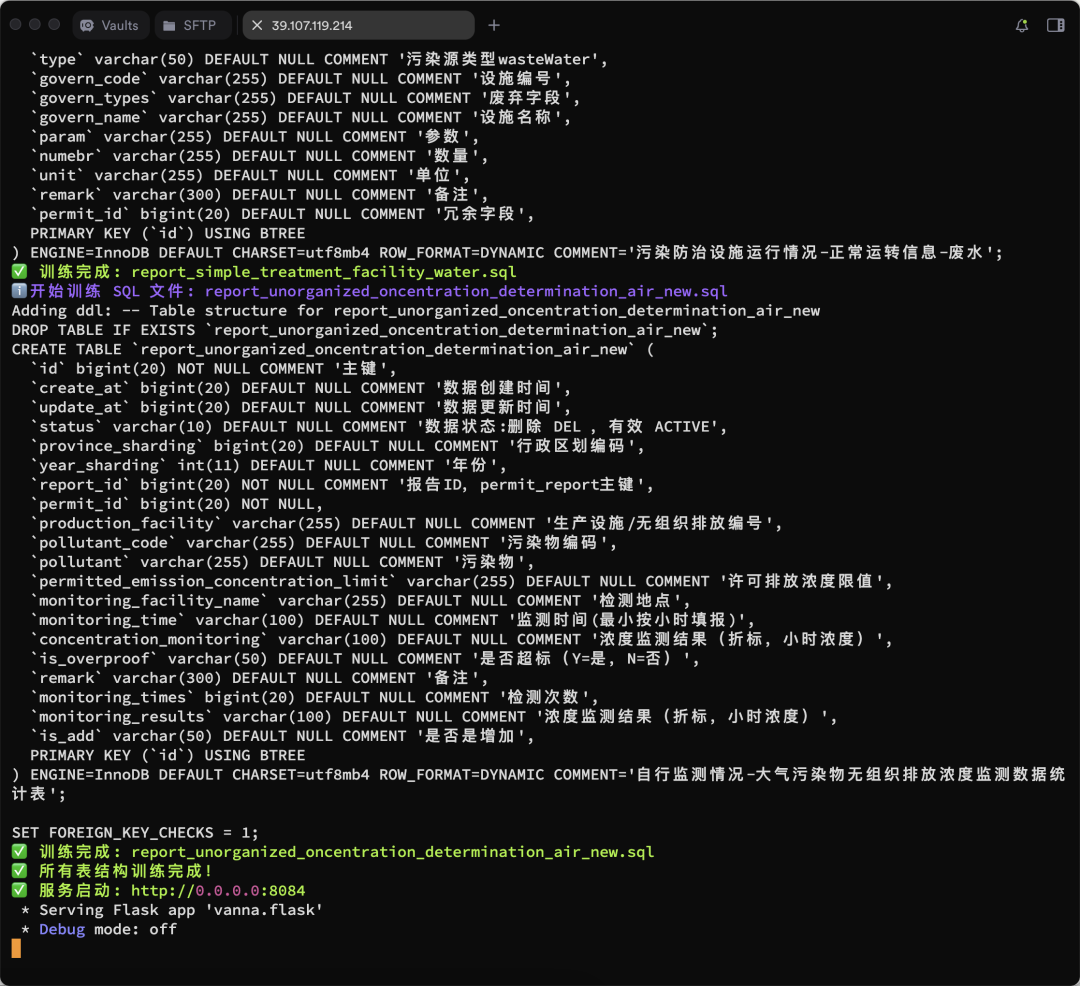
Ejecutar la Interfaz Web
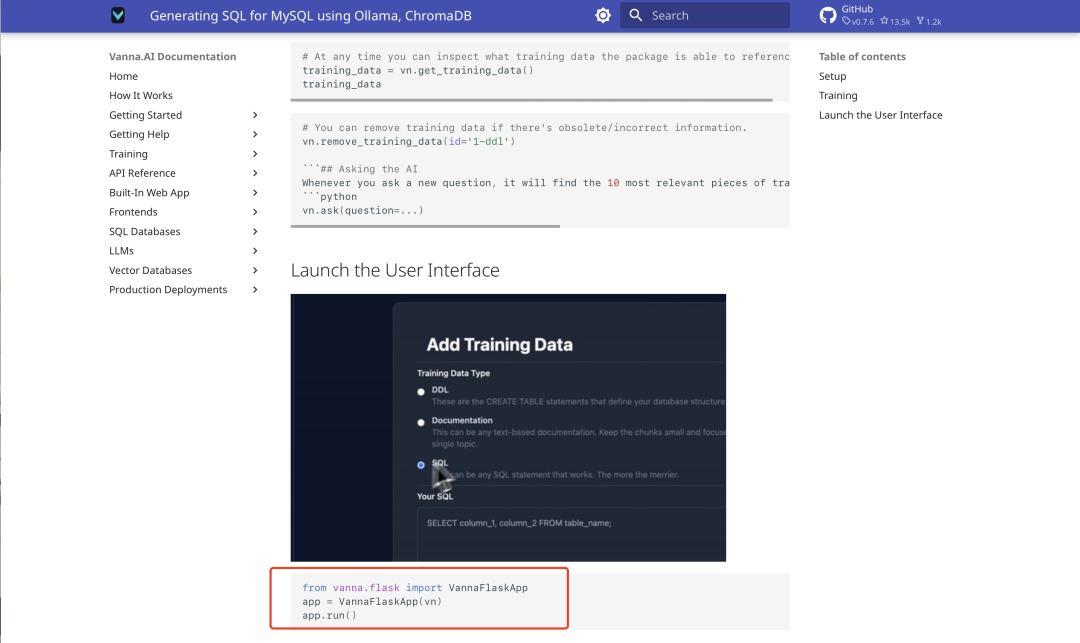
Una vez finalizada la formación, ejecute el siguiente código API de Flask para iniciar la interfaz de usuario web de Vanna:
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()
Acceso a la dirección local (normalmente http://127.0.0.1:5000), puede realizar consultas SQL a través de la interfaz.
Pantalla de efecto consulta
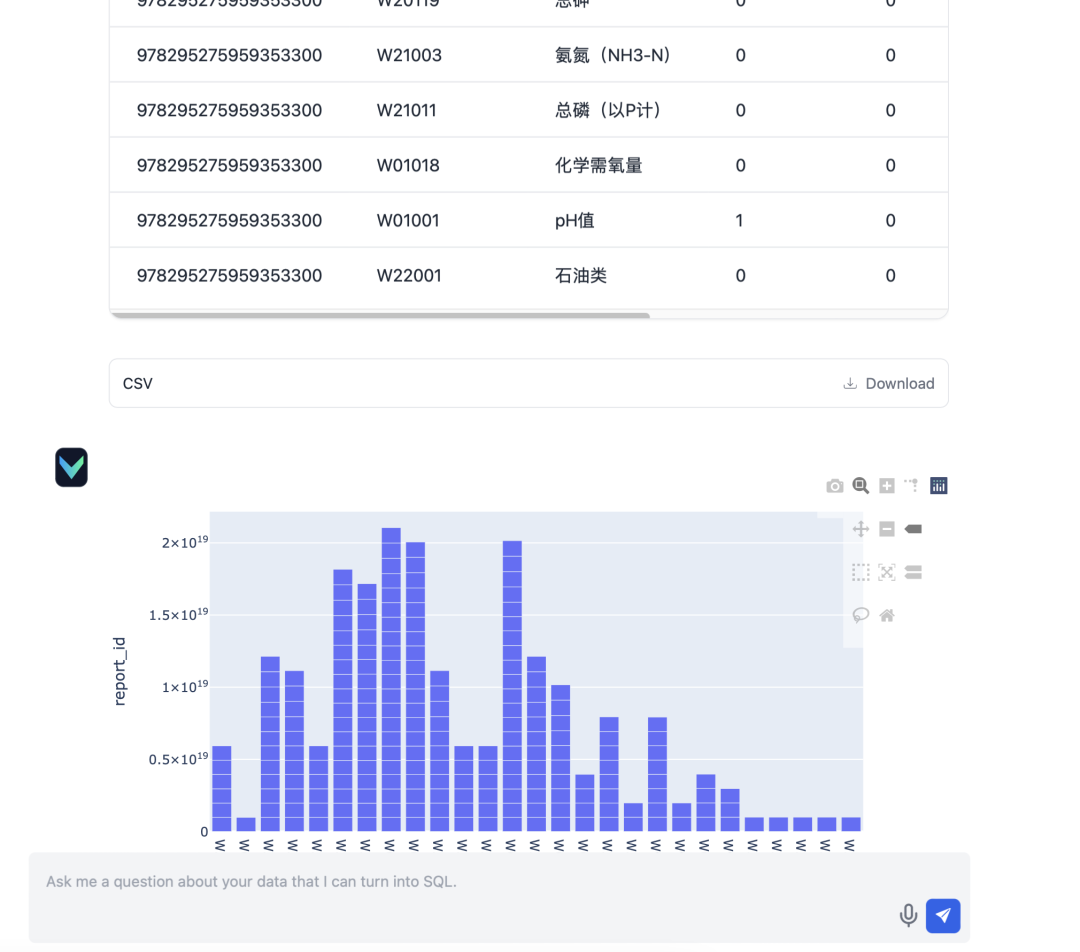
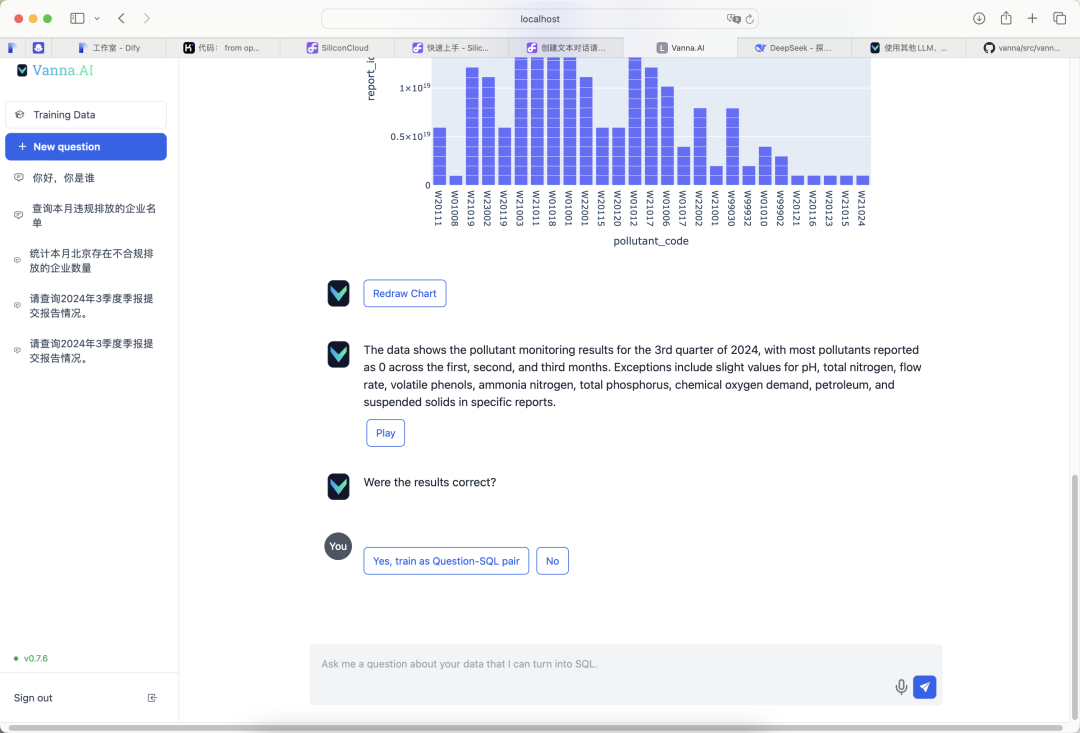
Tras la implantación, la funcionalidad de preguntas y respuestas de Vanna funcionó satisfactoriamente. He aquí algunos resultados de pruebas reales:
- Entrada: "Solicito información sobre el estado de presentación de los informes correspondientes al informe trimestral del trimestre de marzo de 2024."

- Entrada: "Número de estadísticas"
- Entrada: "Estadísticas de contaminantes"
Resumen y recomendaciones
Siguiendo estos pasos, puede desplegar con éxito Vanna localmente e implementar una funcionalidad Text2SQL eficiente en combinación con los modelos MySQL y Deepseek. En comparación con otras herramientas, Vanna presenta ventajas evidentes en cuanto a facilidad de uso y eficacia. Se recomienda a los principiantes dar prioridad al uso de estructuras de tablas para entrenar los datos, y ajustar la configuración del modelo lingüístico en función de las necesidades reales.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...