
Modelo de generación de imágenes CogView4, ¡anunciado como código abierto!


Fusión de arte clásico chino y elementos modernos, esta imagen se inspira en la obra Mil millas de ríos y montañas, del pintor de la dinastía Song del Norte Wang Ximeng. La imagen muestra un magnífico paisaje en pergamino, con la técnica del paisaje verde que da como resultado colinas ondulantes y vastos ríos, ricas capas de color y exquisitos detalles. Sobre este pintoresco paisaje, aparece sutilmente un carácter de pincel "CogView4", con una fuente fuerte y poderosa, y la tinta tiene el tono adecuado, como si fuera una pincelada improvisada hecha por un antiguo literato mientras disfrutaba del paisaje. Las palabras "CogView4" complementan el paisaje circundante, sin ser demasiado abruptas ni demasiado armoniosas, sino más bien añadiendo una sensación de diálogo a través del tiempo y el espacio. Todo el cuadro tiene el sabor del paisaje clásico, pero también incorpora elementos de la tecnología moderna, presentando una tensión artística única, que permite a la gente apreciar la estética tradicional y al mismo tiempo sentir la colisión y fusión de la creatividad moderna.
Hoy hemos lanzado oficialmente nuestro último modelo de generación de imágenes, CogView4.
El modelo tiene una gran capacidad de alineación semántica compleja y de seguimiento de comandos, admite entradas bilingües de longitud arbitraria, genera imágenes de resolución arbitraria dentro de un rango determinado y tiene una gran capacidad de generación de texto. También es el primer modelo de generación de imágenes de código abierto bajo el protocolo Apache 2.0.
I. Evaluación
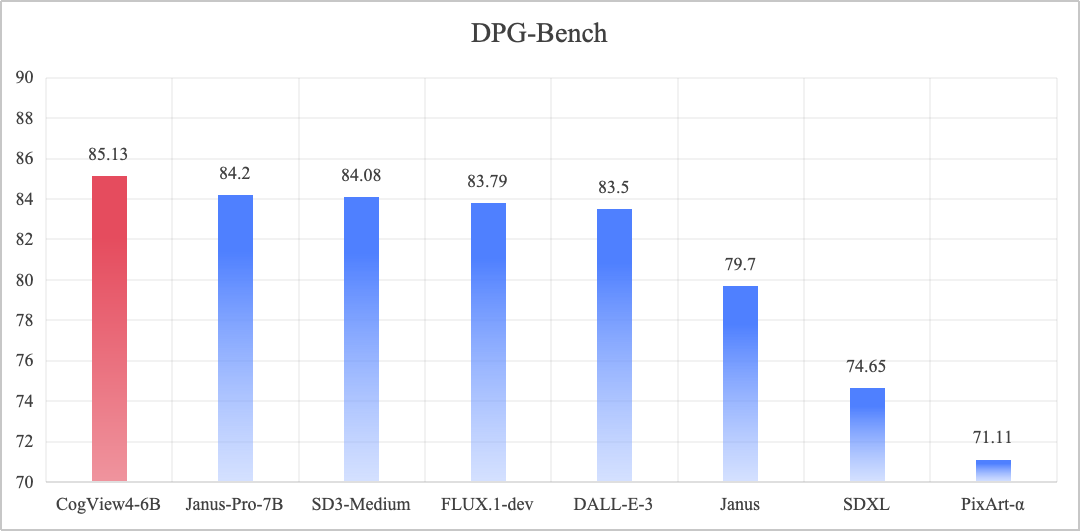
DPG-Bench (Dense Prompt Graph Benchmark) es una prueba de referencia para evaluar modelos de generación de texto a imagen, centrada en el rendimiento de los modelos en términos de alineación semántica compleja y capacidades de seguimiento de instrucciones.
CogView4-6B, que tiene la puntuación global nº 1 en las pruebas comparativas DPG-Bench y alcanza SOTA en el modelo gráfico de código abierto Vincennes.
II. Longitud arbitraria y resolución arbitraria
El modelo CogView4 aplica un paradigma de entrenamiento híbrido de descripciones de texto de longitud arbitraria e imágenes de resolución arbitraria.
1、Codificación de la posición de la imagen
CogView4 utiliza 2D Rotational Position Encoding (2D RoPE) para modelar la información posicional de una imagen y soporta tareas de generación de imágenes a diferentes resoluciones interpolando la codificación posicional.
2. Modelización de la generación de difusión
El modelo se modela utilizando un esquema Flow-matching para la generación de difusión, combinado con una planificación dinámica lineal paramétrica del ruido para adaptarse a los requisitos de relación señal-ruido de las imágenes de diferente resolución.
3、Diseño arquitectónico
En cuanto a la arquitectura del modelo DiT, CogView4 continúa la arquitectura Share-param DiT de su predecesor y diseña capas LayerNorm adaptativas independientes para las modalidades de texto e imagen por separado para lograr una adaptación intermodal eficiente.
4. Formación en varias etapas
CogView4 emplea una estrategia de formación por etapas que incluye la formación en resolución base, la formación en resolución panorámica, el ajuste de datos de alta calidad y la formación en alineación con las preferencias humanas. Este enfoque de formación por etapas no solo cubre una amplia gama de distribuciones de imágenes, sino que también garantiza que las imágenes generadas sean muy agradables estéticamente y se ajusten a las preferencias humanas.
5. Optimización del marco de formación
Desde el punto de vista textual, CogView4 supera la limitación tradicional de la longitud fija de los tokens al permitir límites superiores de tokens más altos y reducir significativamente la redundancia textual de tokens durante el entrenamiento. Cuando la longitud media del subtítulo de entrenamiento se sitúa en el rango de 200-300 tokens, CogView4 reduce la redundancia de tokens en unos 50% en comparación con el esquema tradicional con 512 tokens fijos, y logra una mejora de la eficiencia de 5%-30% en la fase de entrenamiento progresivo del modelo.
Desde el punto de vista de la imagen, el entrenamiento con resoluciones mixtas permite al modelo generar resoluciones arbitrarias en un amplio rango, lo que aumenta enormemente la libertad creativa. La resolución de destino solo tiene que cumplir las siguientes condiciones:
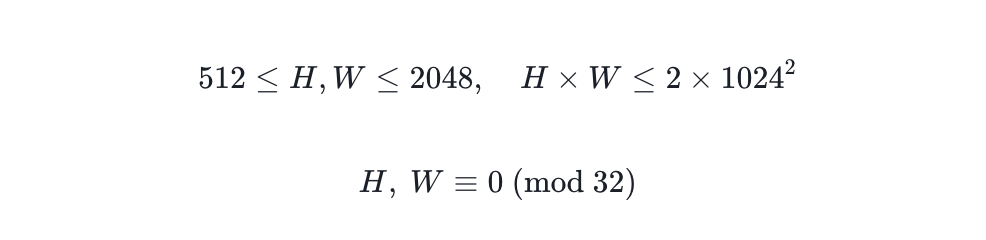
Ambas cosas pueden aumentar enormemente la libertad creativa.
Ejemplo: historia extralarga (cómic de cuatro viñetas)

Princesa: una hembra humana, bella y elegante, vestida con un precioso traje de princesa, encarcelada en la guarida de un monstruo.
El Rey: un varón humano, majestuoso y benévolo, vestido con un ornamentado atuendo real y sentado en el trono del reino.
Dragón de llamas: un monstruo cubierto de escamas llameantes, que escupe llamas y tiene un tamaño enorme.
Señor Oscuro: Monstruo, de enorme tamaño y envuelto en oscuridad, posee un gran poder mágico.
Escena 1: Xiao Ming emprende un viaje
Crea una escena de estilo anime con un magnífico patio del reino de fondo. El protagonista de la escena es Kotomine (un niño humano de corazón valiente, que sostiene una espada y viste un sencillo traje de guerrero), que aparece en una pose embarcándose en un viaje. Incluye detalles de las flores del patio y el castillo a lo lejos, con la luz del sol matutino que transmite valentía y determinación. Calidad: obra maestra, mejor calidad, superdetallado, 4k
Escena 2: Ming derrota al Dragón de Llamas
Crea una escena de estilo anime con un cráter ardiente de fondo. El protagonista de la escena es Kotomine (un niño humano de corazón valiente, que sostiene una espada y viste un sencillo traje de guerrero), que se encuentra en el momento de la victoria sobre un dragón en llamas. Incluye detalles de las rocas y la lava del cráter, y la ardiente iluminación roja transmite fiereza y valentía. Calidad: obra maestra, la mejor calidad, superdetallado, 4k
Escena 3: ¡Ming lucha contra el Señor Oscuro!
Crea una escena de estilo anime con una tenebrosa guarida de monstruos de fondo. El protagonista de la escena es Ming (un niño humano de corazón valiente, espada en mano y un sencillo traje de guerrero), que se encuentra en medio de una feroz batalla contra el Señor Oscuro. Incluye detalles de la oscuridad y la energía mágica de la guarida, y la sombría iluminación transmite intensidad y tensión. Calidad: obra maestra, mejor calidad, superdetallado, 4k
Escena 4: Ming rescata a la Princesa
Crea una escena de estilo anime con el interior de un castillo desierto de fondo. Los personajes principales de la escena son Ming (un niño humano de corazón valiente, que sostiene una espada y viste un sencillo traje de guerrero) y la Princesa (una mujer humana, bella y elegante, que viste un precioso traje de princesa), que protagonizan la conmovedora escena en la que Ming rescata a la Princesa. Incluye detalles de las ruinas interiores del castillo y una iluminación tenue, y la suave iluminación transmite conmoción y redención. Calidad: obra maestra, la mejor calidad, superdetallado, 4k
C. Soporte para chino e inglés
En cuanto a la implementación técnica, CogView4 cambia el codificador de texto de un codificador T5 exclusivamente inglés a un codificador bilingüe GLM-4, y se entrena con pares gráficos bilingües, de modo que el modelo CogView4 tiene la capacidad de introducir palabras prontas bilingües.
Hasta la fecha, CogView4 es el primer modelo gráfico de código abierto generado por texto que admite la introducción bilingüe de palabras clave, y es especialmente bueno en la comprensión y el seguimiento de claves chinas y en la generación de caracteres chinos en la pantalla. Estas dos características son más adecuadas para una amplia gama de necesidades creativas en publicidad nacional, vídeos cortos y otros campos.

IV. Protocolo Apache
El modelo CogView4-6B es compatible con el protocolo Apache2.0, y posteriormente añadirá ControlNet, ComfyUI y otros eco-soportes, pronto estará disponible un conjunto completo de herramientas de ajuste.
Almacén Modelo:
https://huggingface.co/THUDM/CogView4-6B
https://modelscope.cn/models/ZhipuAI/CogView4-6B
actualizado CogView4 El modelo se pondrá en marcha el 13 de marzo en chatglm.cn.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...