Recomendados 12 programas gratuitos de Digital People para implantación local

En el rápido desarrollo de la IA, los Humanos Digitales (Digital Humans) han madurado y pueden generarse rápidamente a bajo coste. Debido a la amplia gama de escenarios de aplicación comercial, ha recibido atención. Ya sea en la realidad virtual (RV), la realidad aumentada (RA) o la producción de cine y televisión, el desarrollo de juegos o la promoción de marcas, los Humanos Digitales desempeñan un papel importante.
En términos generales, existen personas digitales modeladas en 3D (incluida la captura de movimiento), personas digitales de imagen estática en 2D (incluidas las personas reales) y personas digitales de tipo intercambio de caras reales.
Este trabajo se centra en la clase de imagen de clonación de imagen personal hombre digital, pertenece a la imagen 2D estática hombre digital, contiene tres puntos de función básica: imagen real, clonación de voz, sincronización de la boca.
Nota 1: Algunos proyectos no incluyen la generación de voz (clonación) parte, este no es el punto, por favor, puede ser desplegado por separado, el mercado tiene muchos excelentesProyecto de clonación de voz por IA.
Nota 2: Actualmente, la calidad de las figuras estáticas 2D varía principalmente en la sincronización de sus bocas y la naturalidad de sus "movimientos de vídeo". Puedes intentar optimizar esto por separadosincronización labialNodos.
Nota 3: El cambio de cara + clonación de voz es también una forma rápida de generar una persona digital, que es adecuada para mantener la imagen y la voz de los oradores públicos sin cambios, y no se incluye en los siguientes programas. La tecnología universal avanzada de intercambio de rostros por vídeo es arriesgada cuando se populariza, por lo que no se presenta.
AIGCPanel: clon de código abierto del sistema de integración digital man, despliegue en un clic del cliente gratuito digital man.
AigcPanel es un sistema de producción humana digital de AI para todos los usuarios, desarrollado con la pila de tecnología electron+vue3+typescript, que admite la implementación con un solo clic en el sistema Windows. El sistema está diseñado para ser fácil de usar como el núcleo, por lo que incluso los usuarios con una base técnica débil puede dominar fácilmente. Las funciones principales incluyen la síntesis humana digital de vídeo, la síntesis de voz, la clonación de voz, etc., y proporciona funciones perfectas de gestión de modelos locales. El sistema admite una interfaz multilingüe (incluidos el chino simplificado y el inglés) e integra MuseTalk, cosyvoice y otros paquetes de inicio con un solo clic para varios modelos maduros. Cabe destacar que el sistema es compatible con la tecnología de coincidencia de fotogramas de vídeo y transcripción de voz para la síntesis de vídeo, y ofrece amplias opciones de configuración de parámetros de sonido para la síntesis de voz. Como proyecto de código abierto, AigcPanel se libera basándose en el protocolo AGPL-3.0, al tiempo que hace hincapié en el uso conforme a las normas y prohíbe explícitamente su utilización en cualquier negocio ilegal e ilícito.

DUIX: personas digitales inteligentes e interactivas en tiempo real con soporte de despliegue multiplataforma con un solo clic
DUIX (Dialogue User Interface System) es una plataforma de interacción humana digital basada en IA creada por Silicon Intelligence. Con capacidades de interacción humana digital de código abierto, los desarrolladores pueden integrar fácilmente modelos a gran escala, reconocimiento automático del habla (ASR) y funcionalidad de texto a voz (TTS) para la interacción en tiempo real con humanos digitales.DUIX admite la implementación con un solo clic en múltiples plataformas como Android e iOS, lo que facilita a todos los desarrolladores la creación de agentes humanos digitales inteligentes y personalizados que se pueden aplicar a una amplia gama de industrias. Gracias a su bajo coste de implantación, su escasa dependencia de la red y sus diversas funcionalidades, la plataforma es capaz de satisfacer las necesidades de múltiples sectores como el vídeo, los medios de comunicación, la atención al cliente, las finanzas, la radio y la televisión.

EchoMimic: animación sonora de retratos realistas
EchoMimic es un proyecto de código abierto cuyo objetivo es generar animaciones de retratos realistas basadas en audio. Desarrollado por la división Terminal Technologies de Ant Group, el proyecto utiliza condiciones de puntos marcadores editables para generar vídeos de retratos dinámicos combinando audio y puntos marcadores faciales.EchoMimic se ha comparado exhaustivamente en múltiples conjuntos de datos públicos y propios, demostrando su rendimiento superior en evaluaciones cuantitativas y cualitativas.
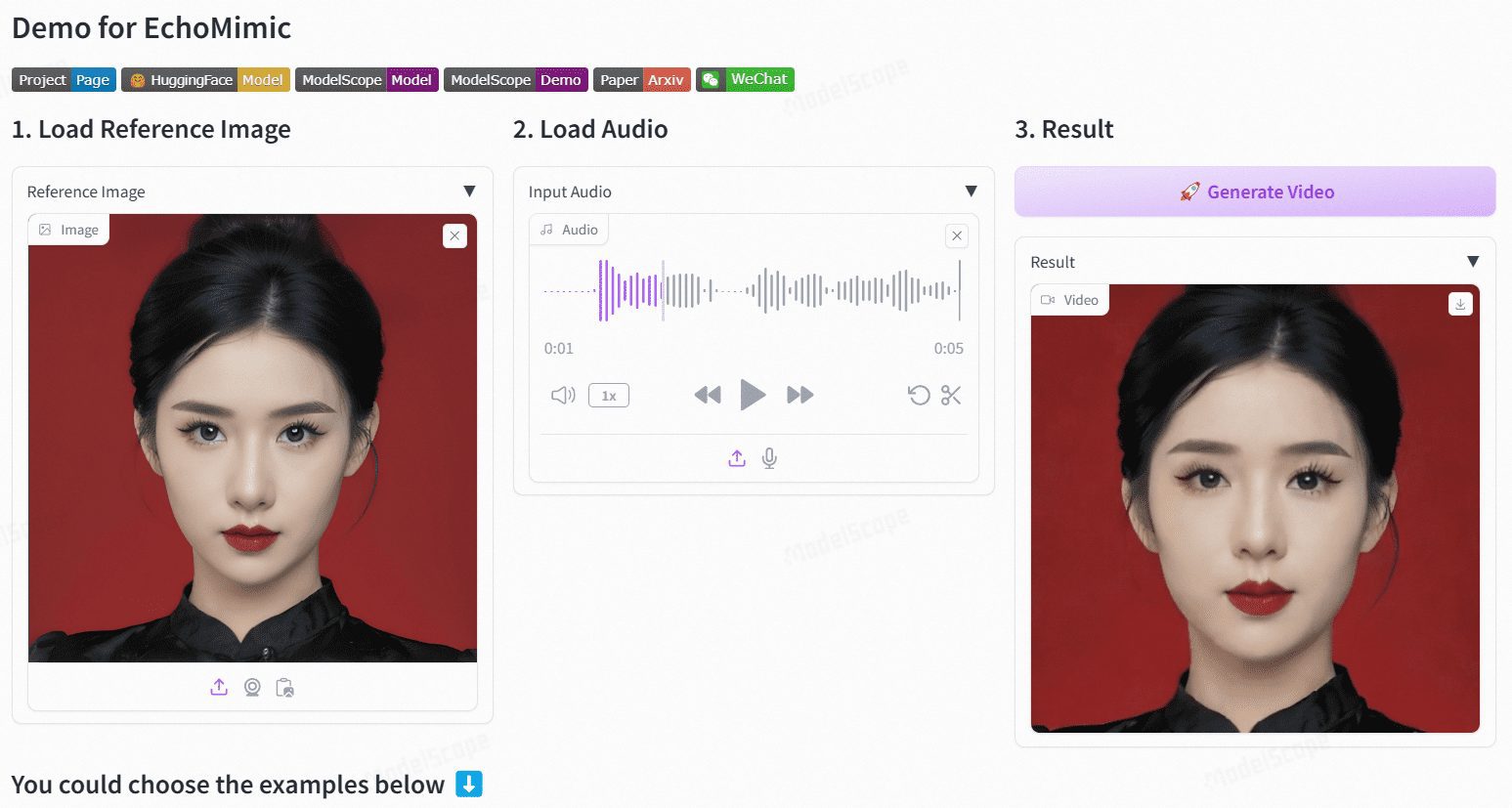
Sonic: Una nueva solución de código abierto para humanos digitales, generación basada en audio de vídeos animados con expresiones faciales para ventanas emergentes digitales.
Sónico Sonic es una innovadora plataforma centrada en la percepción global del audio, diseñada para generar vívidas animaciones de retratos impulsadas por el audio. Desarrollada por un equipo de investigadores de Tencent y la Universidad de Zhejiang, la plataforma utiliza la información de audio para controlar las expresiones faciales y los movimientos de la cabeza con el fin de generar vídeos animados naturales y fluidos.Las tecnologías básicas de Sonic incluyen el aprendizaje de audio mejorado por el contexto, controladores desacoplados del movimiento y un módulo de fusión de cambio de posición consciente del tiempo. Estas tecnologías permiten a Sonic generar vídeos largos estables y realistas con distintos estilos de imágenes y varios tipos de entradas de audio.
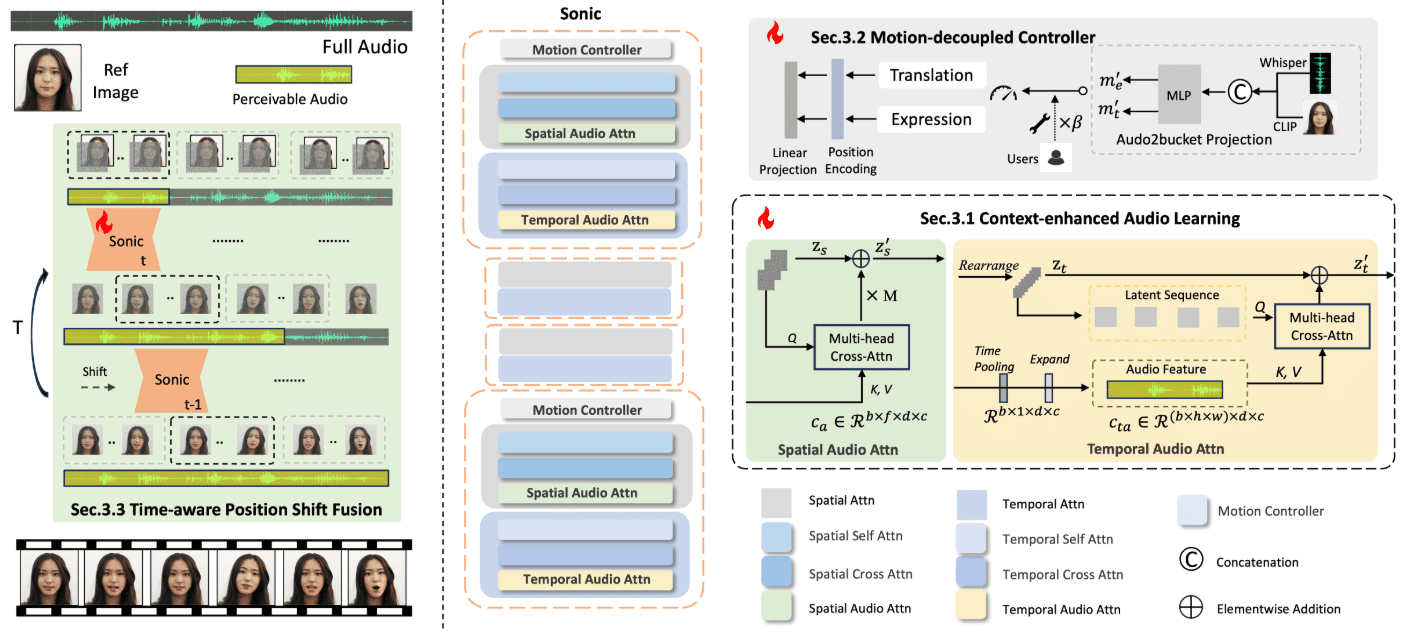
Hallo2: generación de vídeos de retratos con sincronización de labios y expresiones basada en audio (con instalación de Windows con un solo clic)
Hallo2 es un proyecto de código abierto desarrollado conjuntamente por la Universidad de Fudan y Baidu para generar animaciones de retratos de alta resolución mediante la generación basada en audio. El proyecto utiliza redes generativas adversariales (GAN) avanzadas y técnicas de alineación temporal para lograr una resolución de 4K y hasta una hora de generación de vídeo.
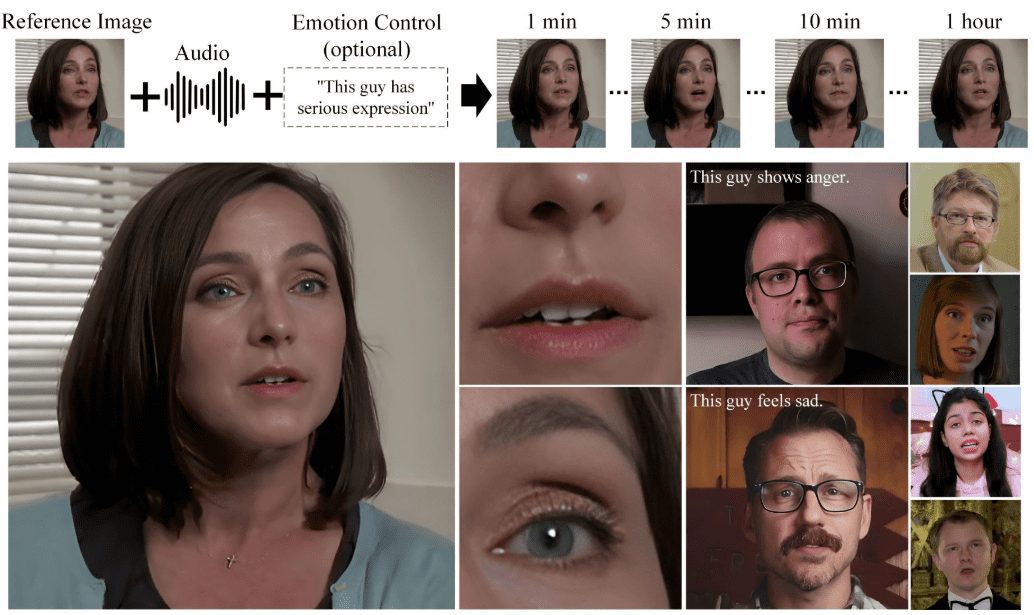
VideoChat: persona digital interactiva de voz en tiempo real con clonación personalizada de imágenes y tonos, compatible con soluciones de voz de extremo a extremo y soluciones en cascada.
VideoChat es un proyecto de humano digital de interacción vocal en tiempo real basado en tecnología de código abierto, compatible con esquemas de voz de extremo a extremo (GLM-4-Voice - THG) y en cascada (ASR-LLM-TTS-THG). El proyecto permite a los usuarios personalizar la imagen y el timbre del humano digital, y admite clonación de timbre y sincronización labial, salida de streaming de vídeo y latencia del primer paquete tan baja como 3 segundos. Los usuarios pueden experimentar su funcionalidad a través de demostraciones en línea, o desplegarlo y utilizarlo localmente gracias a una detallada documentación técnica.
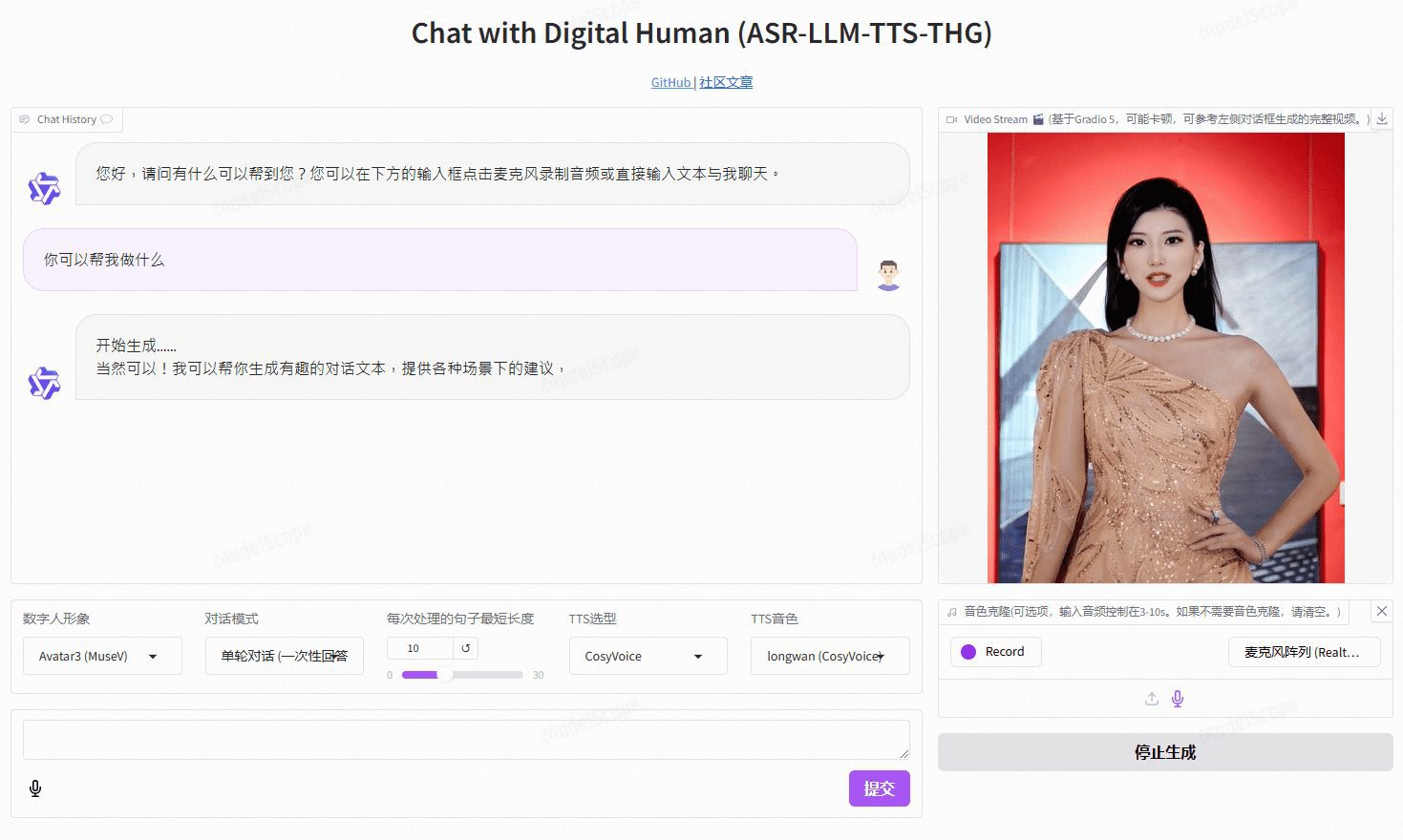
TalkingAvatar: plataforma de vídeo de avatares de IA para crear y editar avatares de IA, basada en el cliente Windows de aritmética nativa.
TalkingAvatar es una plataforma líder de avatares de IA que ofrece una solución completa de persona digital de IA. Ofrece a los usuarios una forma revolucionaria de crear, editar y personalizar contenidos de vídeo. Gracias a su avanzada tecnología de IA, los usuarios pueden reescribir fácilmente vídeos, clonar voces, sincronizar labios y crear vídeos personalizados. Tanto si se trata de volver a doblar un vídeo existente como de crear una nueva historia desde cero, TalkingAvatar tiene todo lo que necesitas.

SadTalker: Haz Hablar a las Fotos | Audio Sincronizado con la Boca | Vídeo Sincronizado con la Boca Sintetizado | Gente Digital Gratis
SadTalker es una herramienta de código abierto que combina una única foto de retrato con un archivo de audio para crear vídeos realistas de cabezas parlantes para una amplia gama de escenarios, como mensajes personalizados, contenidos educativos y mucho más. El revolucionario uso de tecnologías de modelado 3D como ExpNet y PoseVAE destaca en la captura de sutiles expresiones faciales y movimientos de la cabeza. Los usuarios pueden utilizar la tecnología SadTalker tanto para proyectos personales como comerciales, como mensajería, enseñanza o marketing.

AniPortrait: movimiento de imagen o vídeo basado en audio para generar vídeo digital realista de habla humana
AniPortrait es un marco innovador para generar animaciones realistas de retratos a partir de audio. Desarrollado por Huawei, Zechun Yang y Zhisheng Wang de Tencent Game Know Yourself Lab, AniPortrait es capaz de generar animaciones de alta calidad a partir de audio e imágenes de retrato de referencia, e incluso puede serProporcionar vídeo para la recreación facial. Mediante el uso de técnicas avanzadas de representación intermedia en 3D y animación facial en 2D, el marco es capaz de generar efectos de animación naturales y suaves para diversos escenarios de aplicación, como la producción de cine y televisión, los presentadores virtuales y las personas digitales.

MuseV+Muse Talk: Marco completo de generación de vídeo humano digital | Retrato a vídeo | Pose a vídeo | Sincronización de labios
MuseV es un proyecto público en GitHub cuyo objetivo es la generación de vídeo avatar de longitud ilimitada y alta fidelidad. Se basa en la tecnología de difusión y proporciona varias funciones como Image2Video, Text2Image2Video, Video2Video y más. Se proporcionan detalles de la estructura del modelo, casos de uso, guía de inicio rápido, scripts de inferencia y agradecimientos.

DreamTalk: ¡Genera expresivos vídeos parlantes con una sola imagen de avatar!
DreamTalk es un marco de generación de cabezas parlantes expresivas basado en modelos de difusión, desarrollado conjuntamente por la Universidad de Tsinghua, Alibaba Group y la Universidad de Ciencia y Tecnología de Huazhong. Consta de tres componentes principales: una red de reducción de ruido, un experto en estilo labial y un predictor de estilo, y es capaz de generar cabezas parlantes diversas y realistas a partir de una entrada de audio. El marco es capaz de manejar audio multilingüe y ruidoso, y proporciona un movimiento facial de alta calidad y una sincronización precisa de la boca.

Translation Starter: Herramienta de código abierto para la sincronización de contenidos de vídeo | Conversión de idiomas | Sincronización labial
Translation Starter es un proyecto de código abierto desarrollado por Sync Labs para ayudar a los desarrolladores a integrar rápidamente soporte multilingüe para contenidos de vídeo. Proporciona las API y la documentación necesarias para que los desarrolladores puedan crear fácilmente aplicaciones que requieran traducción de vídeo con sincronización labial. Se basa en potentes tecnologías de IA como Perfect Lip Sync de Sync Labs, la tecnología de traducción de susurros de Open AI y la síntesis de sonido de Eleven Labs.

© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...