TPO-LLM-WebUI: un marco de IA en el que se pueden introducir preguntas para entrenar un modelo en tiempo real y obtener los resultados.
Últimos recursos sobre IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 55.8K 00

Introducción general
TPO-LLM-WebUI es un proyecto innovador de código abierto de Airmomo en GitHub que permite la optimización en tiempo real de grandes modelos lingüísticos (LLM) a través de una interfaz web intuitiva. Adopta el marco TPO (Test-Time Prompt Optimization), con lo que se despide por completo del tedioso proceso de ajuste fino tradicional y optimiza directamente el resultado del modelo sin necesidad de entrenamiento. Después de que el usuario introduzca una pregunta, el sistema utiliza modelos de recompensa y retroalimentación iterativa para permitir que el modelo evolucione dinámicamente durante el proceso de razonamiento, haciéndolo cada vez más inteligente y mejorando la calidad del resultado hasta en 50%. Ya sea para pulir documentos técnicos o generar respuestas de seguridad, esta herramienta ligera y eficaz ofrece un potente apoyo a desarrolladores e investigadores.


Lista de funciones
- Evolución en tiempo realOptimización del resultado mediante la fase de inferencia: cuanto más se utiliza, más se ajusta a las necesidades del usuario.
- No requiere ajuste fino: No actualizar los pesos del modelo y mejorar directamente la calidad de la generación.
- Compatible con varios modelos: Soporte para cargar diferentes modelos de base y recompensa.
- Alineación dinámica de preferencias: Ajuste de la producción basado en la retroalimentación de recompensa para aproximarse a las expectativas humanas.
- Visualización del razonamientoDemostrar el proceso de iteración de optimización para facilitar la comprensión y la depuración.
- Ligero y eficazLa informática es barata y fácil de implantar.
- Código abierto y flexible: Proporciona el código fuente y admite el desarrollo definido por el usuario.
Utilizar la ayuda
Proceso de instalación
El despliegue de TPO-LLM-WebUI requiere una configuración básica del entorno. A continuación se detallan los pasos para ayudar a los usuarios a empezar rápidamente.
1. Preparar el entorno
Asegúrese de que las siguientes herramientas están instaladas:
- Python 3.10: Entorno operativo básico.
- GitPermite obtener el código del proyecto.
- GPU (recomendada): Las GPU NVIDIA aceleran la inferencia.
Crear un entorno virtual:
Usa a Condi:
conda create -n tpo python=3.10
conda activate tpo
o las herramientas propias de Python:
python -m venv tpo
source tpo/bin/activate # Linux/Mac
tpo\Scripts\activate # Windows
Descargue e instale las dependencias:
git clone https://github.com/Airmomo/tpo-llm-webui.git
cd tpo-llm-webui
pip install -r requirements.txt
Instala TextGrad:
TPO depende de TextGrad, que requiere una instalación adicional:
cd textgrad-main
pip install -e .
cd ..
2. Modelo de configuración
Tienes que descargar manualmente el modelo base y el modelo de bonificación:
- modelo básicoEn
deepseek-ai/DeepSeek-R1-Distill-Qwen-32B(Cara de abrazo) - modelización de incentivosEn
sfairXC/FsfairX-LLaMA3-RM-v0.1(Cara de abrazo)
Coloca el modelo en el directorio especificado (por ejemplo/model/HuggingFace/), y enconfig.yamlEstablezca la ruta en
3. Inicie el servicio vLLM
utilizar vLLM Modelo base de alojamiento. Tomemos como ejemplo 2 GPUs:
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
--dtype auto
--api-key token-abc123
--tensor-parallel-size 2
--max-model-len 59968
--port 8000
Una vez que el servicio esté en marcha, escuche el mensaje http://127.0.0.1:8000.
4. Ejecutar WebUI
Inicie la interfaz web en un nuevo terminal:
python gradio_app.py
acceso al navegador http://127.0.0.1:7860A continuación se ofrece una lista de los productos más populares y demandados del mercado.
Funciones principales
Función 1: Inicialización del modelo
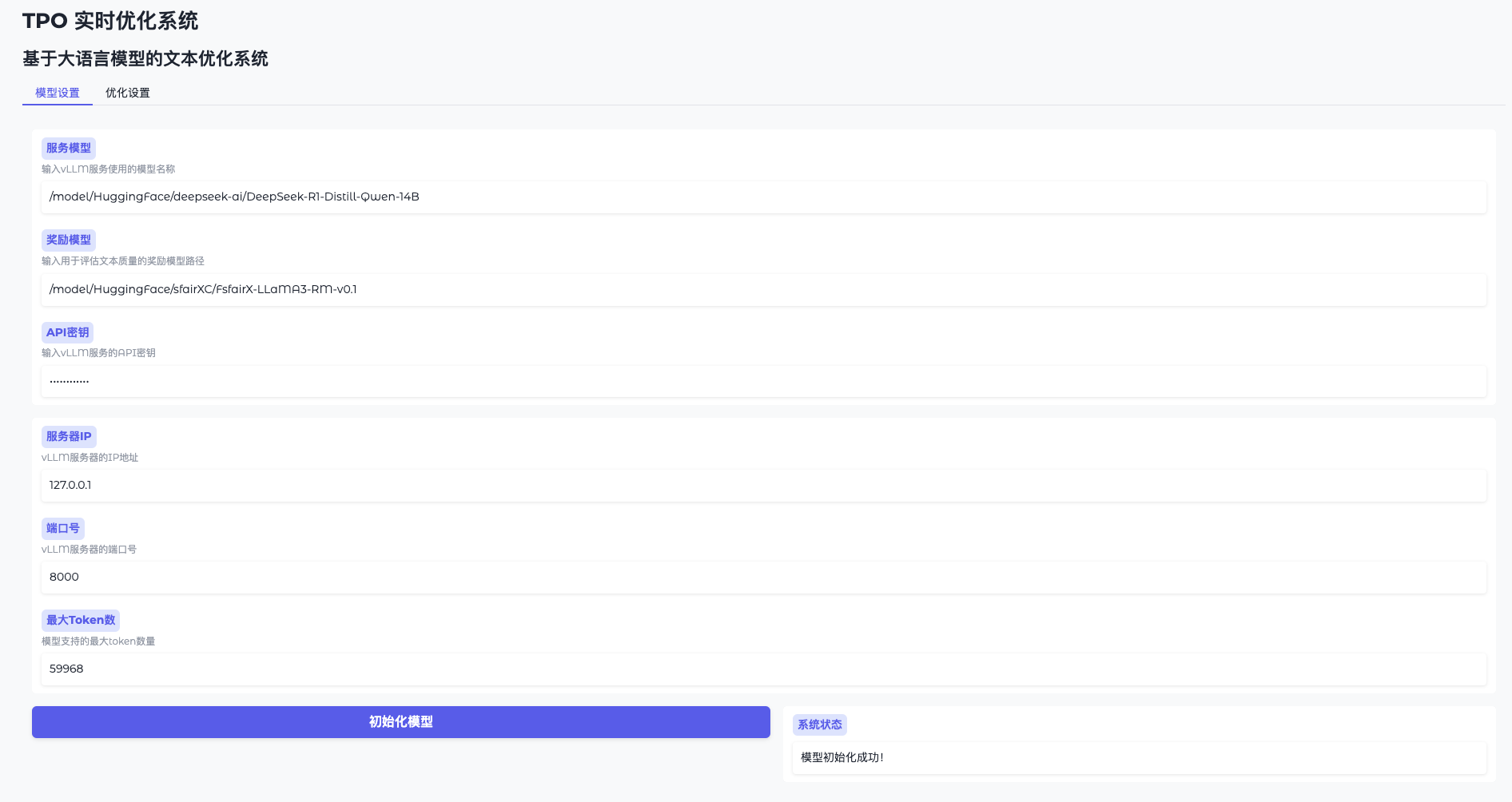
- Abrir la configuración del modelo
Vaya a WebUI y haga clic en "Configuración del modelo". - Conexión a vLLM
Introduzca la dirección (por ejemplohttp://127.0.0.1:8000) y la tecla (token-abc123). - Cargar el modelo de recompensa
Especifique la ruta (por ejemplo/model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1Haga clic en "Inicializar" y espere 1-2 minutos. - Confirmación de disponibilidad
La interfaz indica "Modelo listo" y puede continuar.
Función 2: Optimizar la producción en tiempo real
- Página de optimización de Toggle
Vaya a "Optimizar ajustes". - Cuestiones de entrada
Introduzca contenidos como "Retoque este documento técnico". - Optimización operativa
Haga clic en "Iniciar optimización" y el sistema generará múltiples resultados candidatos y los mejorará iterativamente. - Compruebe el proceso evolutivo
La página de resultados muestra la salida inicial y la optimizada, con un aumento gradual de la calidad.
Función 3: optimización del modo script
Si no utilizas la WebUI, puedes ejecutar un script:
python run.py
--data_path data/sample.json
--ip 0.0.0.1
--port 8000
--server_model /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
--reward_model /model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1
--tpo_mode tpo
--max_iterations 2
--sample_size 5
Los resultados de la optimización se guardan en logs/ Carpeta.
Descripción detallada de las características especiales
Diga adiós al ajuste fino, evolucione en tiempo real
- procedimiento::
- Introduzca la pregunta y el sistema generará la respuesta inicial.
- Recompensar la evaluación del modelo y los comentarios para orientar la siguiente iteración.
- Tras varias iteraciones, el resultado se vuelve "más inteligente" y la calidad mejora notablemente.
- vanguardia: Ahorre tiempo y aritmética optimizando en cualquier momento sin formación.
Cuanto más lo usas, más inteligente se vuelve.
- procedimiento::
- Utilice el mismo modelo varias veces con distintas entradas para distintos problemas.
- El sistema acumula experiencia en función de cada respuesta y el resultado se adapta mejor a las necesidades.
- vanguardia: Aprende dinámicamente las preferencias del usuario para obtener mejores resultados a largo plazo.
advertencia
- requisitos de hardwareSe recomiendan 16 GB de memoria de vídeo o más y varias GPU para garantizar que los recursos estén libres y disponibles.
export CUDA_VISIBLE_DEVICES=2,3Designación. - Resolución de problemas: Cuando la memoria de vídeo se desborde, baje el
sample_sizeo comprueba la ocupación de la GPU. - Apoyo comunitarioConsulte el LÉEME de GitHub o las incidencias para obtener ayuda.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...