
Tongyi Wanxiang actualización de vídeo, superó VBench, soporte de vídeo para la generación de chino, la textura de la lente tirando de lleno

¿Está a punto de producirse un gran avance tecnológico en la generación de vídeo con IA cuando 2025 no ha hecho más que empezar?
Esta mañana, el modelo de generación de vídeo Tongyi Wanphase de Ali ha anunciado una fuerte actualización a la versión 2.1.
Existen dos versiones del modelo recién lanzado, que sonTomix 2.1 Extreme y Professional, el primero centrado en el alto rendimiento y el segundo en la alta expresividad..
Según la presentación, Tongyi Wanxiang ha mejorado ampliamente el rendimiento general del modelo esta vez, especialmente en el procesamiento de movimientos complejos, la restauración de las leyes físicas reales, la mejora de la textura de la película y la optimización de las instrucciones a seguir, lo que abre una nueva puerta a la creación artística de la IA.
Echemos un vistazo al efecto de generación de vídeo y veamos si puede sorprenderte.
Tomemos como ejemplo el clásico "corte de bistec". Se puede ver que la textura del bistec es claramente visible, la superficie está cubierta de una fina capa de grasa que brilla, y la cuchilla corta lentamente a lo largo de las fibras musculares, haciendo que la carne quede Q-bouncy y llena de detalles. 
Prompt: En un restaurante, un hombre corta un filete humeante. En un primer plano cenital, el hombre sostiene un cuchillo afilado en la mano derecha, coloca el cuchillo sobre el filete y corta a lo largo del centro del filete. La persona está vestida de negro con esmalte de uñas blanco en las manos, el fondo es bokeh con un plato blanco con comida amarilla y una mesa marrón.
Y luego mira un efecto de generación de primeros planos de un personaje, la expresión facial de la niña, los movimientos de las manos y el cuerpo son muy naturales y coordinados, el viento que se agita en el pelo también está en consonancia con las leyes del movimiento.

Prompt:Una chica muy mona de pie en un arbusto de flores con las manos comparando su corazón y todo tipo de corazoncitos bailando a su alrededor. Lleva un vestido rosa, su larga melena ondea al viento y su sonrisa es dulce. El fondo es un jardín de primavera con flores en plena floración y sol brillante. Fotografía realista HD, primer plano, luz natural suave.
¿Es el modelo lo suficientemente fuerte como para obtener otra puntuación? Actualmente, en VBench Leaderboard, la lista definitiva de análisis de generación de vídeo, elEl Tongyi Wanxiang actualizado ha alcanzado el primer puesto de la lista con una puntuación total de 84,7%, superando a modelos de generación de vídeo nacionales e internacionales como Gen3, Pika y CausVid... Parece que el panorama competitivo de la generación de vídeo ha sufrido otra oleada de cambios.
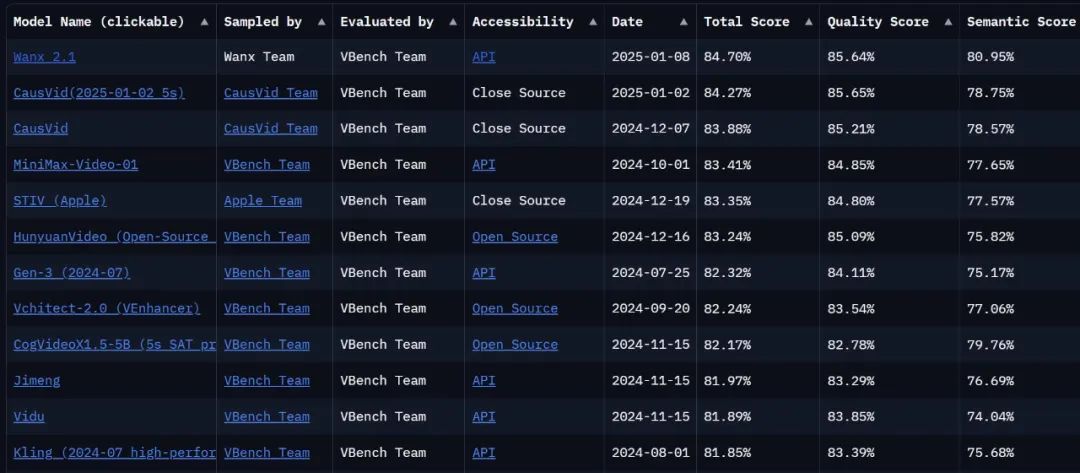
Enlace a la lista: https://huggingface.co/spaces/Vchitect/VBench_Leaderboard
A partir de ahora, los usuarios podrán utilizar la última generación de modelos en el sitio web de Tongyi Wanxiang. Del mismo modo, los desarrolladores también pueden llamar a la API de grandes modelos en AliCloud Bai Lian.
Dirección oficial del sitio web: https://tongyi.aliyun.com/wanxiang/
experiencia de primera manoMayor expresividad y posibilidad de jugar con fuentes de efectos especiales
En los últimos tiempos, se ha producido un rápido ritmo de iteración de grandes modelos para la generación de vídeo, ¿ha logrado la nueva versión de Tongyi Wanxiang un nivel de mejora generacional? Hicimos algunas pruebas en el mundo real.
El vídeo de IA ya puede escribir.
En primer lugar, los vídeos generados por IA pueden decir adiós por fin a la "escritura fantasma".
Anteriormente, el principal modelo de generación de vídeo AI en el mercado ha sido incapaz de generar con precisión chino e Inglés, siempre y cuando el lugar donde el texto debe ser, es un montón de basura ilegible. Ahora este problema de la industria ha sido resuelto por Tongyi Wanxiang 2.1.
Se convirtió enEl primer modelo de generación de vídeo que admite la generación de texto en chino y efectos de texto tanto en inglés como en chino..
Ahora los usuarios pueden generar texto y animaciones con efectos cinematográficos con sólo introducir una breve descripción de texto.
Por ejemplo, un gatito está escribiendo delante de un ordenador y en la pantalla aparecen siete grandes palabras: "Trabajar o comer".

En el vídeo generado por Tongyi Wanxiang, el gato se sienta en una estación de trabajo y toca el teclado y el ratón con seriedad, como si fuera una máquina de escribir contemporánea, y los subtítulos emergentes, junto con la banda sonora autogenerada, dan a toda la imagen un toque más ingenioso.
Luego está la palabra inglesa "Synced" que sale de un cuadradito naranja.

Tanto si genera chino como inglés, Tongyi Wanxiang lo hace bien, sin erratas ni "escritura fantasma".
No sólo eso, sino que también admite la aplicación de fuentes en una variedad de escenarios, laIncluye fuentes para efectos especiales, fuentes para carteles y fuentes mostradas en escenarios reales..
Por ejemplo, cerca de la Torre Eiffel, a orillas del Sena, los fuegos artificiales brillan en el aire y, a medida que la cámara se acerca, el número rosa "2025" aumenta gradualmente de tamaño hasta llenar todo el encuadre.

El movimiento vigoroso ya no es "espeluznante"
El movimiento complejo de los personajes era antes una "pesadilla" para los modelos de generación de vídeos de IA, y en el pasado, los vídeos generados por IA tenían manos y pies voladores, se transformaban en una persona viva o tenían movimientos extraños que "sólo giraban pero no la cabeza". 
Gracias a la optimización avanzada de algoritmos y al entrenamiento de datos, Tongyi Wanxiang es capaz de generar movimientos estables y complejos en diversos escenarios, especialmente en lo que se refiere al movimiento de extremidades a gran escala y a la rotación precisa de las mismas, y el breakdance generado en la imagen de arriba es muy suave como la seda.
Por otra parte, en el vídeo generado a continuación, los movimientos del hombre son suaves y naturales mientras corre, sin problemas de que las piernas izquierda y derecha sean indistinguibles o estén torcidas. Y también se presta mucha atención a los detalles, ya que cada vez que los dedos del pie del hombre tocan el suelo, dejan una marca y levantan ligeramente la fina arena.

Prompt: la luz dorada del sol sobre el mar al atardecer, un joven guapo corriendo por la playa, plano fijo de seguimiento.
La fotografía es propia de un maestro del cine.
El gran director Spielberg dijo una vez que el secreto de una buena película reside en el lenguaje de la cámara. Para producir impresionantes secuencias cinematográficas, los directores de fotografía odian subir al cielo y sobrevolar las paredes. 
Pero en esta era de la IA, es mucho más fácil "hacer" una película.
Todo lo que tenemos que hacer es introducir un simple comando de texto, como lente a la izquierda, lente más lejos, avance de lente, etc., y Tongyi Wanxiang será capaz deEmite automáticamente un vídeo razonable según el contenido principal del vídeo y las necesidades de la cámara..
Escribimos Prompt: banda de rock tocando en el jardín delantero, a medida que la cámara avanza, se centra en el guitarrista, vestido con una chaqueta de cuero, con su larga melena desordenada balanceándose al compás. Los dedos del guitarrista saltan rápidamente por las cuerdas mientras el resto de la banda, al fondo, se entrega al máximo.

una imagen completa de todo 2.1 Se siguieron estrictamente las instrucciones. El vídeo comienza con el guitarrista y el batería tocando apasionadamente y, a medida que la cámara se acerca lentamente, el fondo se difumina y se aleja para resaltar la actitud y los movimientos de las manos del guitarrista.
Los comandos de texto largos no se pierden
Para que los vídeos generados por IA sean impactantes, es esencial que las indicaciones de texto sean precisas.
Sin embargo, a veces el modelo grande tiene una memoria limitada, y cuando se enfrenta a órdenes textuales que contienen varios cambios de escena, interacciones de personajes y acciones complejas, tiende a perder la noción de los detalles o a confundirse sobre el orden lógico.
El nuevo Tongyi Manxiang es un gran paso adelante en cuanto a instrucciones de texto largo a seguir.
Prompt: Un motociclista avanza a toda velocidad por una estrecha calle de la ciudad, esquivando una enorme explosión en un edificio cercano, mientras las llamas rugen violentamente, proyectando un brillante resplandor naranja, y los escombros y fragmentos de metal vuelan por el aire, aumentando el caos en la escena. El piloto, vestido con ropa de color oscuro, agachado y agarrando con fuerza el manillar, parece concentrado mientras avanza a una velocidad vertiginosa, sin inmutarse por el fuego que arrasa a sus espaldas. El espeso humo negro dejado por la explosión llena el aire, envolviendo el fondo en un caos apocalíptico. Sin embargo, el piloto se mantiene implacable, zigzagueando a través del caos con precisión y una cinematografía extrema, con detalles ultrafinos, inmersiva, en 3D, y una acción coherente.

En esta larga descripción textual de arriba, las calles estrechas, las llamas brillantes, el humo negro que llena, los escombros volando y los jinetes con equipo de color oscuro ...... son todos detalles captados por Tongyi Manxiang.
Tongyi Wanxiang también tiene una capacidad más poderosa para combinar conceptos con el fin de comprender con precisión una variedad de ideas, elementos o estilos diferentes y combinarlos entre sí para crear contenidos de vídeo totalmente nuevos.
La imagen de un anciano trajeado saliendo de un huevo y mirando con los ojos muy abiertos al anciano canoso de la cámara es bastante hilarante, unida al sonido del cacareo de un gallo.

Especializado en dibujos animados al óleo y otros estilos
La nueva versión de Tongyi Manphase también genera imágenes de vídeo cinematográficas y es compatible con varios estilos artísticos, como dibujos animados, cine en color, estilo 3D, pintura al óleo, estilo clásico, etc.
Echa un vistazo a este simpático monstruito animado en 3D que baila sobre una parra.

Prompt: un esponjoso y feliz monstruito titi verde está de pie sobre una rama de vid cantando alegremente, gira la cámara en el sentido contrario a las agujas del reloj.
Además, admite distintas relaciones de aspecto, como 1:1, 3:4, 4:3, 16:9 y 9:16, que pueden adaptarse mejor a distintos dispositivos finales, como televisores, ordenadores y teléfonos móviles. 
A partir de la actuación anterior, ya podemos realizar un trabajo creativo utilizando Tongyi Manxiang para transformar la inspiración en "realidad".
Por supuesto, esta serie de avances también se atribuyen a las mejoras de AliCloud en el modelo básico de generación de vídeo.
Modelo básico optimizadoEstructura, formación y evaluación de todos los aspectos de la "transformación"
El 19 de septiembre del año pasado, AliCloud lanzó el modelo de generación de vídeo Tongyi Wanphase en la Conferencia Yunqi, aportando la capacidad de generar vídeos HD de calidad cinematográfica y televisiva. Como modelo de generación visual totalmente autodesarrollado de AliCloud, adopta Diffusion + Transformador La arquitectura admite tareas de clase de generación de imágenes y vídeos, y proporciona capacidades de generación visual líderes en el sector con numerosas innovaciones en marcos de modelos, datos de entrenamiento, métodos de anotación y diseño de productos.
En este modelo mejorado, el equipo de Tongyi Wanxiang (en lo sucesivo, el equipo) ademásArquitecturas VAE y DiT eficientes de desarrollo propioEl sistema, mejorado para la modelización de relaciones contextuales espaciotemporales, optimiza significativamente la generación.
Flow Matching es un marco emergente para el entrenamiento de modelos generativos en los últimos años, que es más sencillo de entrenar, consigue una calidad comparable o incluso mejor que los modelos de difusión mediante Continuous Normalising Flow, y tiene velocidades de inferencia más rápidas, y se está aplicando gradualmente al campo de la generación de vídeo. Por ejemplo, el modelo de vídeo Movie Gen, lanzado anteriormente por Meta, utiliza Flow Matching.
Para la selección de los métodos de formación, Tongyi Wanxiang 2.1 utiliza el métodoEsquema de correspondencia de flujos basado en trayectorias lineales de ruidoy se ha diseñado en profundidad para el marco, lo que ha permitido mejorar la convergencia del modelo, la calidad de la generación y la eficacia.

Tongyi Wanxiang 2.1 Diagrama de la arquitectura de generación de vídeo
Para la VAE de vídeo, el equipo diseñó un innovador esquema de códec de vídeo combinando el mecanismo de caché y la convolución causal.. Entre ellos, el mecanismo de caché puede mantener la información necesaria en el procesamiento de vídeo, reduciendo así el cómputo repetido y mejorando la eficiencia computacional; la convolución causal puede capturar las características temporales del vídeo y adaptarse a los cambios incrementales del contenido del vídeo.
En lugar del proceso directo de descodificación E2E para vídeos largos, la implementación sustituye el proceso directo de descodificación E2E para vídeos largos dividiendo el vídeo en trozos y almacenando en caché las características intermedias, de modo que el uso de la tarjeta gráfica sólo está relacionado con el tamaño de los trozos, independientemente de la longitud del vídeo original, lo que permite al modelo codificar y descodificar eficientemente longitudes ilimitadas de vídeo 1080P. El equipo afirma que esta tecnología clave ofrece una vía viable para entrenar vídeos de longitud arbitraria.
La siguiente figura muestra la comparación de los resultados de distintos modelos de VAE. En cuanto a las métricas de eficiencia computacional del modelo (fotogramas/retraso) y de reconstrucción de la compresión de vídeo (relación señal/ruido pico, PSNR), la VAE utilizada por Tongyi Wanxiang sigue obteniendo los siguientes resultados sin parámetros dominantesCalidad de compresión y reconstrucción de vídeo líder en el sector.
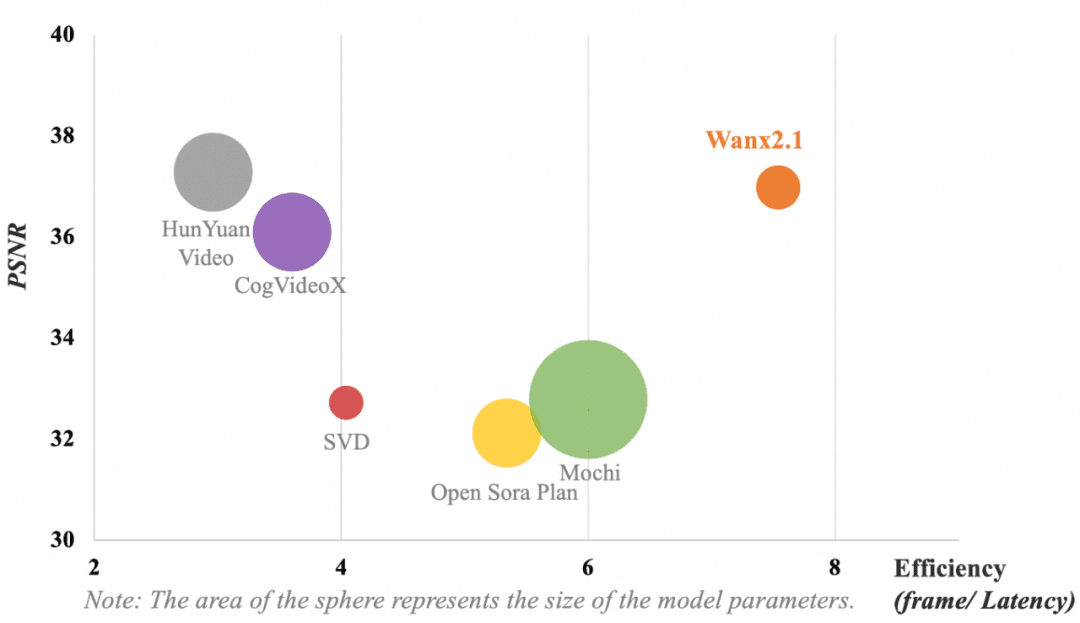
Nota: El área del círculo representa el tamaño de los parámetros del modelo.
El objetivo principal del equipo de diseño de DiT (Diffusion Transformer) era conseguir una sólida capacidad de modelización espaciotemporal manteniendo al mismo tiempo un proceso de formación eficaz. Para ello fue necesario introducir una serie de cambios innovadores.
En primer lugar, para mejorar la capacidad de modelización de las relaciones espaciotemporales, el equipo adoptó el mecanismo de atención plena espaciotemporal, que permite al modelo simular con mayor precisión la compleja dinámica del mundo real. En segundo lugar, la introducción del mecanismo de reparto de parámetros reduce eficazmente el coste de formación al tiempo que mejora el rendimiento. Además, el equipo optimizó el rendimiento de la incrustación de texto utilizando el mecanismo de atención cruzada para incrustar características textuales, lo que permite controlar mejor el texto y reducir los requisitos computacionales.
Gracias a estas mejoras e intentos, la estructura DiT de la Fase Universal generalizada consigue una superioridad de convergencia más pronunciada con el mismo coste computacional.
Además de las innovaciones en la arquitectura de los modelos, el equipoSe han realizado algunas optimizaciones en las áreas de entrenamiento e inferencia de secuencias ultralargas, construcción de datos y evaluación de modelos., lo que permite al modelo gestionar eficazmente tareas generativas complejas con mayores ventajas de eficiencia.
Cómo entrenar eficazmente con millones de secuencias ultralargas
Cuando se trabaja con secuencias visuales ultralargas, los modelos de gran tamaño suelen enfrentarse a retos a múltiples niveles, como el cálculo, la memoria, la estabilidad del entrenamiento y la latencia de la inferencia, por lo que se necesitan soluciones eficientes para hacerles frente.
Para ello, el equipo combinó las características de la carga de trabajo del nuevo modelo y el rendimiento del hardware del clúster de entrenamiento para desarrollar una estrategia de entrenamiento distribuida y optimizada en memoria con el fin de optimizar el rendimiento del entrenamiento bajo la premisa de garantizar el tiempo de iteración del modelo, y finalmenteConsigue una MFU líder en el sector y una formación eficiente de 1 millón de secuencias ultralargas.
Por un lado, el equipo innova la estrategia distribuida adoptando el entrenamiento paralelo 4D con DP, FSDP, RingAttention y Ulysses, lo que mejora tanto el rendimiento del entrenamiento como la escalabilidad distribuida. Por otro lado, para lograr la optimización de la memoria, el equipo adopta una estrategia de optimización jerárquica de la memoria para optimizar la memoria de activación y resolver el problema de fragmentación de la memoria en función del volumen de cálculo y comunicación causado por la longitud de la secuencia.
Además, la optimización computacional puede mejorar la eficiencia del entrenamiento del modelo y ahorrar recursos, por lo que el equipo adopta FlashAttention3 para el cálculo espaciotemporal de la atención plena y elige la estrategia de CP adecuada para la partición combinando el rendimiento computacional de los clústeres de entrenamiento de diferentes tamaños. Al mismo tiempo, el equipo elimina la redundancia computacional de algunos módulos clave, reduce la sobrecarga de acceso y mejora la eficiencia computacional mediante una implementación eficiente del núcleo. En cuanto al sistema de archivos, el equipo aprovecha al máximo las características de lectura/escritura del sistema de archivos de alto rendimiento del clúster de entrenamiento AliCloud, y mejora el rendimiento de lectura/escritura mediante la fragmentación Save/Load.

Estrategia de formación distribuida en paralelo 4D
Al mismo tiempo, el equipo eligió un esquema de uso de memoria escalonado para abordar los problemas de OOM causados por Dataloader Prefetch, CPU Offloading y Save Checkpoint durante el entrenamiento. Además, para garantizar la estabilidad de la formación, el equipo aprovechó la programación inteligente, la detección de máquinas lentas y las capacidades de autorreparación de los clústeres de formación de AliCloud para identificar automáticamente los nodos defectuosos y reiniciar las tareas rápidamente.
Introducción de la automatización en la construcción de datos y la evaluación de modelos
Los grandes modelos de generación de vídeo no pueden entrenarse sin datos de alta calidad a escala y una evaluación eficaz del modeloEl primero garantiza que el modelo aprenda escenarios diversos, dependencias espaciotemporales complejas y mejore la generalización, constituyendo la piedra angular del entrenamiento del modelo; el segundo ayuda a controlar el rendimiento del modelo para que alcance mejor los resultados esperados, y sirve de veleta para el entrenamiento del modelo.
En cuanto a la construcción de datos, el equipo ha creado un proceso automatizado de construcción de datos con la alta calidad como criterio, que es muy coherente con la distribución de preferencias humanas en términos de calidad visual, calidad de movimiento, etc., de modo que los datos de vídeo de alta calidad pueden construirse automáticamente con alta diversidad, distribución equilibrada y otras características.
Para la evaluación de los modelos, el equipo diseñó igualmente un amplio conjunto de métricas automatizadas que incorporaban más de dos docenas de dimensiones, como la puntuación estética, el análisis del movimiento y la adherencia a los comandos, y seleccionó y formó a puntuadores profesionales capaces de alinearse con las preferencias humanas. Gracias a la eficacia de estos parámetros, el proceso de iteración y optimización del modelo se aceleró considerablemente.
Puede decirse que las innovaciones sinérgicas en varios aspectos, como la arquitectura, la formación y la evaluación, han permitido al modelo actualizado de generación de vídeo Tongyi Wanphase cosechar importantes mejoras generacionales en la experiencia del mundo real.
Momentos GPT-3 para la generación de vídeo¿Cuánto tiempo más?
Desde el pasado mes de febrero, OpenAI Sora Desde su introducción, el modelo de generación de vídeo se ha convertido en el campo más competitivo del mundo tecnológico. Desde las empresas nacionales hasta las extranjeras, desde las startups hasta los gigantes tecnológicos están lanzando sus propias herramientas de generación de vídeo. Sin embargo, en comparación con la generación de texto, la IA de vídeo tiene más de un nivel de dificultad para alcanzar el grado de aceptabilidad.
Si, como dice Sam Altman, CEO de OpenAI, Sora representa el momento GPT-1 en el gran modelo de generación de vídeo, entonces podemos basarnos en él para lograr el control preciso de los comandos textuales y la capacidad de ajustar los ángulos y las posiciones de la cámara para garantizar la coherencia de los personajes. Si partimos de esta base para lograr un control preciso de la IA con comandos textuales, ángulos y posiciones de cámara ajustables, y una caracterización coherente y otras capacidades de generación de vídeo, y añadimos la capacidad única de la IA para cambiar rápidamente de estilos y escenas, puede que pronto veamos un nuevo "momento GPT-3".
Desde la perspectiva del camino del desarrollo tecnológico, los modelos de generación de vídeo son un proceso de verificación de las Leyes de Escalado. A medida que mejore la capacidad del modelo básico, la IA entenderá cada vez más órdenes humanas y podrá crear entornos cada vez más realistas y razonables.
Desde un punto de vista práctico, en realidad no podemos esperar: desde el año pasado, la gente de los vídeos cortos, la animación e incluso el cine y la televisión ha empezado a utilizar la IA de generación de vídeo para la exploración creativa. Si podemos superar las limitaciones de la realidad y hacer cosas antes inimaginables con la IA de generación de vídeo, una nueva ronda de cambios en la industria está a la vuelta de la esquina.
Ahora parece que Tongyi Manxiang ha dado el primer paso.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...