
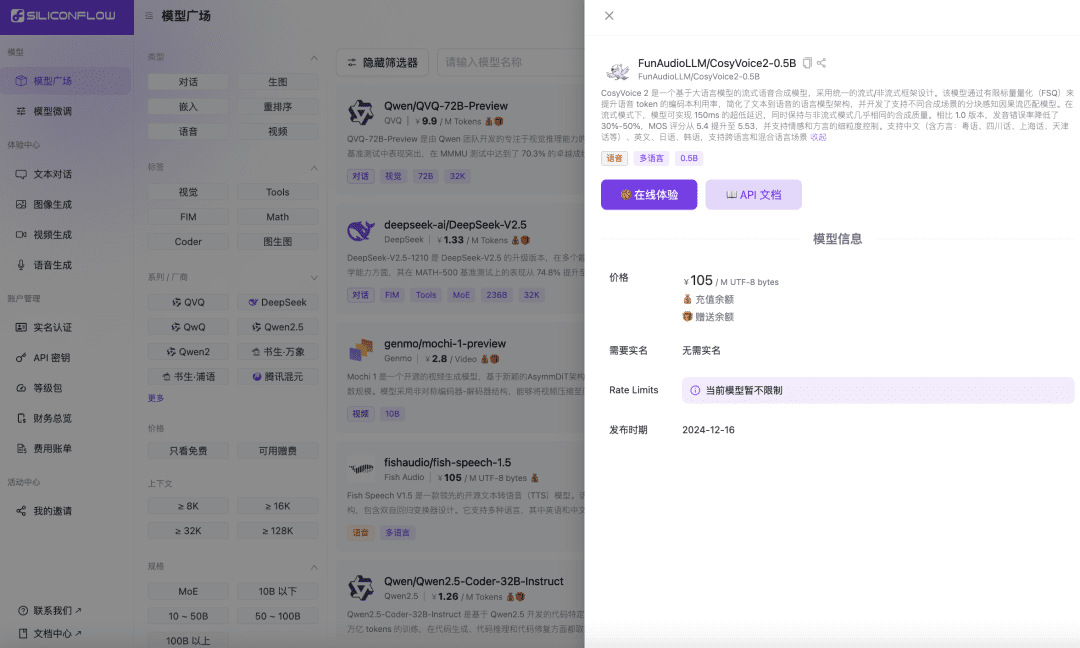
Siliconcloud lanza CosyVoice2 acelerado: síntesis de voz en tiempo real de 150 ms y compatibilidad con varios idiomas y dialectos


Recientemente, el equipo del habla de Ali Tongyi Lab ha presentado oficialmente el modelo de síntesis del hablaCosyVoice2. El modelo admite la transmisión bidireccional de texto y voz, admite el multilingüismo, las lenguas mixtas y los dialectos, y proporciona capacidades de generación de voz más precisas, estables, rápidas y mejores. Ahora, Siliconcloud, el flujo basado en silicio Siliconcloud está oficialmente en línea con la versión de aceleración de inferencia CosyVoice2-0.5B (precio ¥105/ M UTF-8 bytes, cada carácter ocupa de 1 a 4 bytes), que incluye el tiempo de transmisión de red, haciendo que la latencia de salida del modelo sea tan baja como 150ms, aportando una experiencia de usuario más eficiente a sus aplicaciones de IA generativa. Al igual que otros modelos de síntesis lingüística de SiliconCloud, CosyVoice2 admite 8 tonos preestablecidos, tonos preestablecidos por el usuario y tonos dinámicos, así como velocidad de voz, ganancia de audio y frecuencia de muestreo de salida personalizables.
Experiencia en línea
https://cloud.siliconflow.cn/playground/text-to-speech/17885302679
Documentación API
https://docs.siliconflow.cn/api-reference/audio/create-speech
Conozca la versión acelerada por inferencia de CosyVoice 2.0 de SiliconCloud.
Combinado con el programa de SiliconCloudAli Speech Recognition Model SenseVoice-Small (disponible gratuitamente)Con la ayuda del modelo de API, los desarrolladores pueden desarrollar con eficacia aplicaciones de interacción por voz de extremo a extremo, incluidos audiolibros, salidas de audio en streaming, asistentes virtuales y otras aplicaciones.
Características y prestaciones del modelo
CosyVoice2 es un modelo de síntesis de voz en flujo basado en un gran modelo de lenguaje, diseñado utilizando un marco unificado de flujo y no flujo. El modelo mejora la utilización del libro de códigos de los tokens de voz mediante la cuantificación escalar finita (FSQ), simplifica la arquitectura del modelo de lenguaje de texto a voz y desarrolla un modelo de correspondencia de flujo causal consciente de los trozos que admite distintos escenarios de síntesis. En el modo streaming, el modelo logra una latencia ultrabaja de 150 ms, manteniendo prácticamente la misma calidad de síntesis que en el modo no streaming.
Además, CosyVoice2 ha avanzado significativamente en la integración del modelo base y el modelo de comandos, no sólo manteniendo la compatibilidad con las emociones, los estilos de habla y los comandos de control detallados, sino también añadiendo la capacidad de manejar comandos en chino. CosyVoice2 también ha introducido funciones de juego de rol, como la posibilidad de imitar a robots y el estilo de habla de Peppa Pig.
En concreto, la versión 2.0 presenta las siguientes ventajas con respecto a la versión 1.0 de CosyVoice:
Soporte multilingüe
- Idiomas compatibles: chino, inglés, japonés, coreano y dialectos chinos (cantonés, sichuanés, shanghainés, tianjinés, wuhanés, etc.).
- Multilingüe y multilingüe: admite la clonación de muestras de voz cero en situaciones multilingües y de cambio de código.
latencia ultrabaja
- Compatibilidad con streaming bidireccional: CosyVoice 2.0 integra las tecnologías de modelado offline y streaming.
- Síntesis rápida del primer paquete: consigue retardos de tan sólo 150 milisegundos manteniendo una salida de audio de alta calidad.
muy preciso
- Mejora de la pronunciación: los errores de pronunciación se han reducido de 30% a 50% en comparación con CosyVoice 1.0.
- Logro del parámetro: Conseguir la tasa de error de caracteres más baja en el conjunto de pruebas difíciles del conjunto de evaluación Seed-TTS.
alta estabilidad
- Consistencia tonal: garantiza una consistencia tonal fiable para la síntesis de voz con muestra cero y multilingüe.
- Síntesis multilingüe: mejoras significativas con respecto a la versión 1.0.
fluidez natural
- Mejora rítmica y tonal: aumentó la puntuación de la evaluación MOS de 5,4 a 5,53.
- Emoción y flexibilidad dialectal: favorece un control más fino de la emoción y el ajuste del acento dialectal.
Evaluación de desarrolladores
Una vez lanzada CosyVoice 2.0, algunos desarrolladores la experimentaron primero. Algunos desarrolladores dijeron que admite funciones de control ultrafinas y una síntesis de voz más realista y natural. 
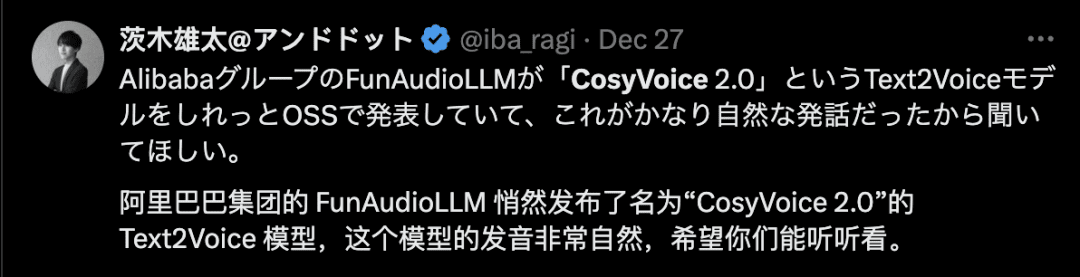 Sin embargo, algunos usuarios afirmaron que, a pesar de sentirse atraídos por su excelente rendimiento en la generación de voz, la implantación se convirtió en un gran reto.
Sin embargo, algunos usuarios afirmaron que, a pesar de sentirse atraídos por su excelente rendimiento en la generación de voz, la implantación se convirtió en un gran reto. 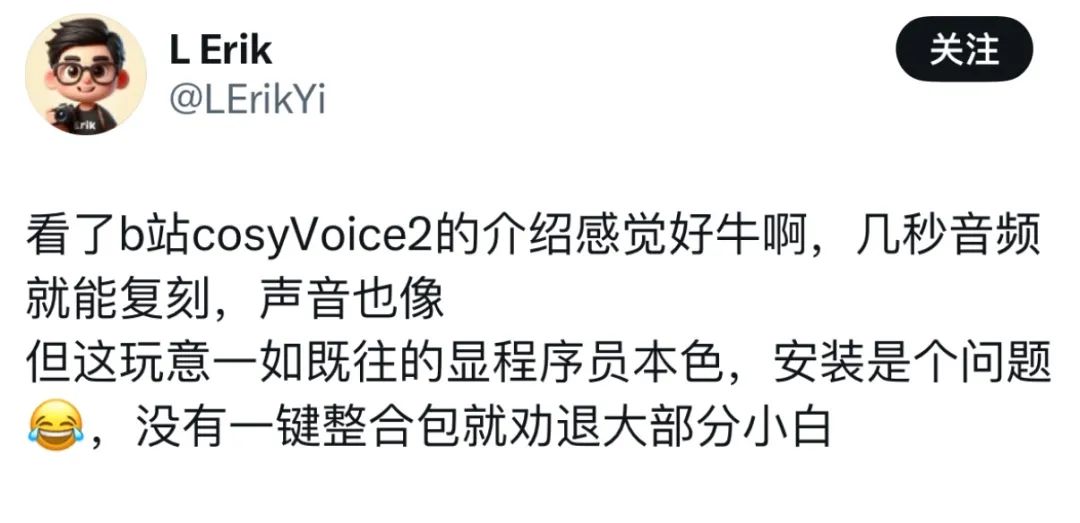 Ahora que Siliconcloud ha puesto en marcha CosyVoice 2.0, eliminando la necesidad de despliegues complejos, puedes llamar fácilmente a la API y acceder a tus propias aplicaciones.
Ahora que Siliconcloud ha puesto en marcha CosyVoice 2.0, eliminando la necesidad de despliegues complejos, puedes llamar fácilmente a la API y acceder a tus propias aplicaciones.
¡Token Factory SiliconCloud Qwen 2.5 (7B) y más de 20 modelos gratis!
Como plataforma integral de servicios de modelos en la nube, SiliconCloud se compromete a ofrecer a los desarrolladores API de modelos extremadamente ágiles, asequibles, completas y suaves como la seda. Además de CosyVoice2, SiliconCloud ya ha dado salida a una serie de API de modelos, como QVQ-72B-Preview, DeepSeek-VL2, DeepSeek- V2.5-1210, mochi-1-preview, Llama-3.3-70B-Instruct, HunyuanVideo, fish-speech-1.5, QwQ-32B-Preview, Qwen2.5-Coder-32B-Instruct, InternVL2 Qwen2.5-7B/14B/32B/72B, FLUX.1, InternLM2.5-20B-Chat, BCE, BGE, SenseVoice-Small, GLM-4-9B-Chat, y docenas de grandes modelos lingüísticos de código abierto, modelos de generación de imágenes/vídeos, modelos del habla, modelos de código/matemáticos y modelos vectoriales y de reordenación. vectoriales y de reordenación. 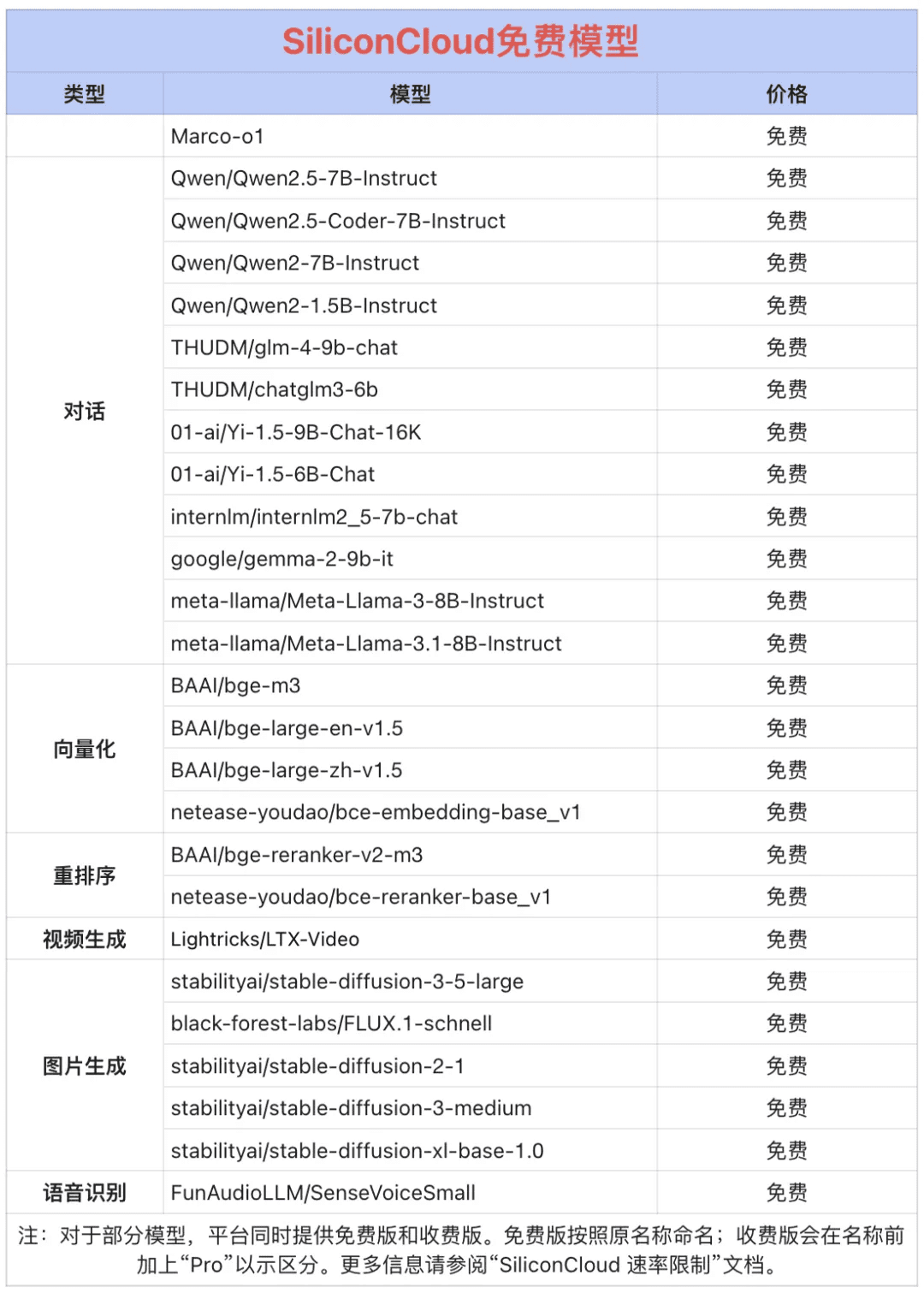 Entre ellas, Qwen2.5 (7B), Llama3.1 (8B) y otras más de 20 API de grandes modelos son de uso gratuito, de modo que los desarrolladores y gestores de productos no tienen que preocuparse por el coste aritmético de la fase de investigación y desarrollo y la promoción a gran escala, y hacen realidad la "libertad de fichas".
Entre ellas, Qwen2.5 (7B), Llama3.1 (8B) y otras más de 20 API de grandes modelos son de uso gratuito, de modo que los desarrolladores y gestores de productos no tienen que preocuparse por el coste aritmético de la fase de investigación y desarrollo y la promoción a gran escala, y hacen realidad la "libertad de fichas".
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...