
SiliconCloud x FastGPT: 200.000 usuarios construyen una exclusiva base de conocimientos de IA


FastGPT es un sistema de preguntas y respuestas de base de conocimientos basado en el modelo LLM, desarrollado por el equipo de Circle Cloud, que proporciona procesamiento de datos out-of-the-box, invocación de modelos y otras capacidades. FastGPT ha recibido 19,4k estrellas en Github.
SiliconCloud de Silicon Flow es una gran plataforma de servicios en la nube de modelos con su propio motor de aceleración, SiliconCloud puede ayudar a los usuarios a probar y utilizar modelos de código abierto de una manera económica y rápida. La experiencia real es que la velocidad y la estabilidad de sus modelos son muy buenas, y son ricos en variedad, cubriendo docenas de modelos como idiomas, vectores, reordenación, TTS, STT, dibujo, generación de vídeo, etc., que pueden satisfacer todas las necesidades de modelos en FastGPT.
Este artículo es un tutorial escrito por el equipo FastGPT para presentar una solución para desplegar FastGPT en el desarrollo local utilizando exclusivamente modelos SiliconCloud.
1 Obtención de la clave API de la Plataforma SiliconCloud
- Abre el sitio web de SiliconCloud y regístrate para obtener una cuenta.
- Una vez completado el registro, abra Clave API , cree una nueva Clave API y haga clic en la clave para copiarla y utilizarla en el futuro.

2 Modificación de las variables de entorno de FastGPT
OPENAI_BASE_URL=https://api.siliconflow.cn/v1 # 填写 SiliconCloud 控制台提供的 Api Key CHAT_API_KEY=sk-xxxxxx
Documentación sobre desarrollo e implantación de FastGPT: https://doc.fastgpt.cn
3 Modificación del archivo de configuración de FastGPT
Los modelos en SiliconCloud se seleccionaron como configuraciones FastGPT. Aquí Qwen2.5 72b está configurado con modelos puros de lenguaje y visión; bge-m3 está seleccionado como modelo vectorial; bge-reranker-v2-m3 está seleccionado como modelo de reordenación. Elija fish-speech-1.5 como modelo de habla; elija SenseVoiceSmall como modelo de entrada de habla.
Nota: El modelo ReRank debe configurarse una vez con la clave de la API.
{
"llmModels": [
{
"provider": "Other", // 模型提供商,主要用于分类展示,目前已经内置提供商包括:https://github.com/labring/FastGPT/blob/main/packages/global/core/ai/provider.ts, 可 pr 提供新的提供商,或直接填写 Other
"model": "Qwen/Qwen2.5-72B-Instruct", // 模型名(对应OneAPI中渠道的模型名)
"name": "Qwen2.5-72B-Instruct", // 模型别名
"maxContext": 32000, // 最大上下文
"maxResponse": 4000, // 最大回复
"quoteMaxToken": 30000, // 最大引用内容
"maxTemperature": 1, // 最大温度
"charsPointsPrice": 0, // n积分/1k token(商业版)
"censor": false, // 是否开启敏感校验(商业版)
"vision": false, // 是否支持图片输入
"datasetProcess": true, // 是否设置为文本理解模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig": {}, // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
"fieldMap": {} // 字段映射(o1 模型需要把 max_tokens 映射为 max_completion_tokens)
},
{
"provider": "Other",
"model": "Qwen/Qwen2-VL-72B-Instruct",
"name": "Qwen2-VL-72B-Instruct",
"maxContext": 32000,
"maxResponse": 4000,
"quoteMaxToken": 30000,
"maxTemperature": 1,
"charsPointsPrice": 0,
"censor": false,
"vision": true,
"datasetProcess": false,
"usedInClassify": false,
"usedInExtractFields": false,
"usedInToolCall": false,
"usedInQueryExtension": false,
"toolChoice": false,
"functionCall": false,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {}
}
],
"vectorModels": [
{
"provider": "Other",
"model": "Pro/BAAI/bge-m3",
"name": "Pro/BAAI/bge-m3",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 5000,
"weight": 100
}
],
"reRankModels": [
{
"model": "BAAI/bge-reranker-v2-m3", // 这里的model需要对应 siliconflow 的模型名
"name": "BAAI/bge-reranker-v2-m3",
"requestUrl": "https://api.siliconflow.cn/v1/rerank",
"requestAuth": "siliconflow 上申请的 key"
}
],
"audioSpeechModels": [
{
"model": "fishaudio/fish-speech-1.5",
"name": "fish-speech-1.5",
"voices": [
{
"label": "fish-alex",
"value": "fishaudio/fish-speech-1.5:alex",
"bufferId": "fish-alex"
},
{
"label": "fish-anna",
"value": "fishaudio/fish-speech-1.5:anna",
"bufferId": "fish-anna"
},
{
"label": "fish-bella",
"value": "fishaudio/fish-speech-1.5:bella",
"bufferId": "fish-bella"
},
{
"label": "fish-benjamin",
"value": "fishaudio/fish-speech-1.5:benjamin",
"bufferId": "fish-benjamin"
},
{
"label": "fish-charles",
"value": "fishaudio/fish-speech-1.5:charles",
"bufferId": "fish-charles"
},
{
"label": "fish-claire",
"value": "fishaudio/fish-speech-1.5:claire",
"bufferId": "fish-claire"
},
{
"label": "fish-david",
"value": "fishaudio/fish-speech-1.5:david",
"bufferId": "fish-david"
},
{
"label": "fish-diana",
"value": "fishaudio/fish-speech-1.5:diana",
"bufferId": "fish-diana"
}
]
}
],
"whisperModel": {
"model": "FunAudioLLM/SenseVoiceSmall",
"name": "SenseVoiceSmall",
"charsPointsPrice": 0
}
}
4 Reinicie FastGPT
5 Prueba de experiencia
Prueba de diálogo y reconocimiento de imágenes
Puede crear una nueva aplicación sencilla, seleccionar el modelo correspondiente y probarlo con la carga de imágenes activada.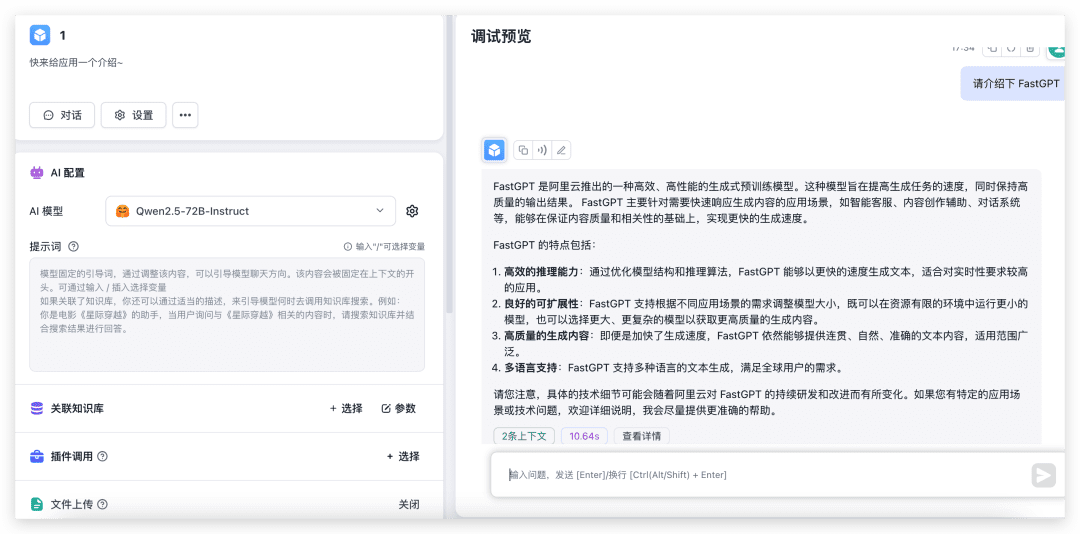
Como se puede ver, el modelo de 72B, el rendimiento es muy rápido, que si no hay unos 4090 locales, por no hablar de la configuración del medio ambiente, me temo que la salida se llevará a 30s.
Prueba de importación de la base de conocimientos y cuestionario de la base de conocimientos
Cree una nueva base de conocimientos (dado que sólo se ha configurado un modelo vectorial, la selección del modelo vectorial no se mostrará en la página).
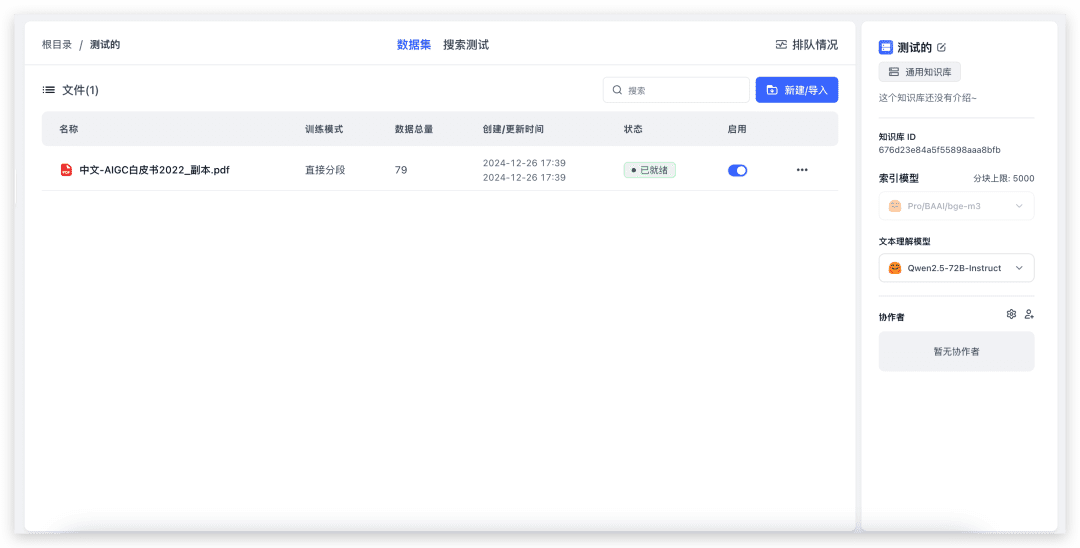
Para importar un archivo local, sólo tienes que seleccionar el archivo e ir hasta siguiente. 79 índices y tardó unos 20s en completarse. Ahora vamos a probar el cuestionario de la Base de Conocimientos.
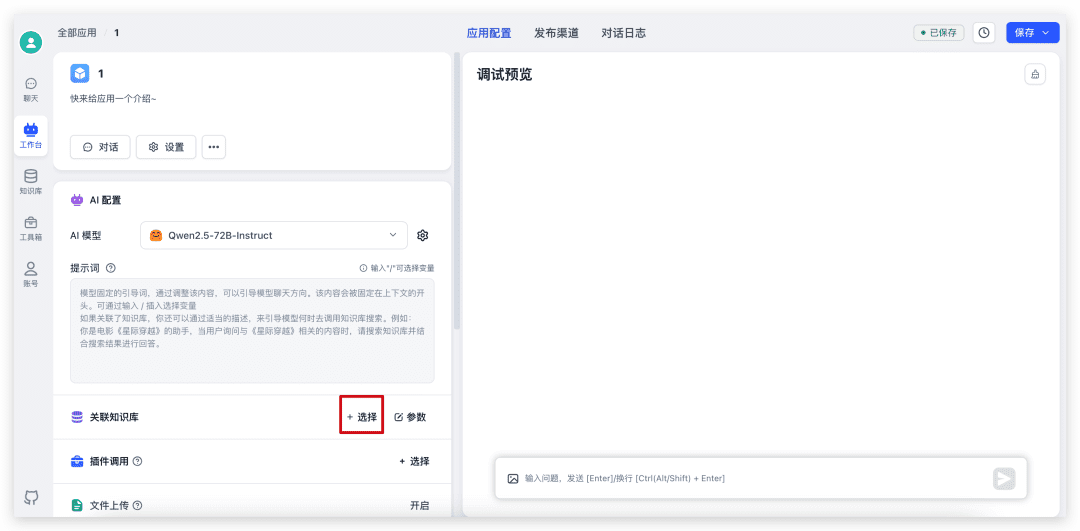
Primero vuelve a la aplicación que acabamos de crear, selecciona Base de conocimientos, ajusta los parámetros e inicia el diálogo.
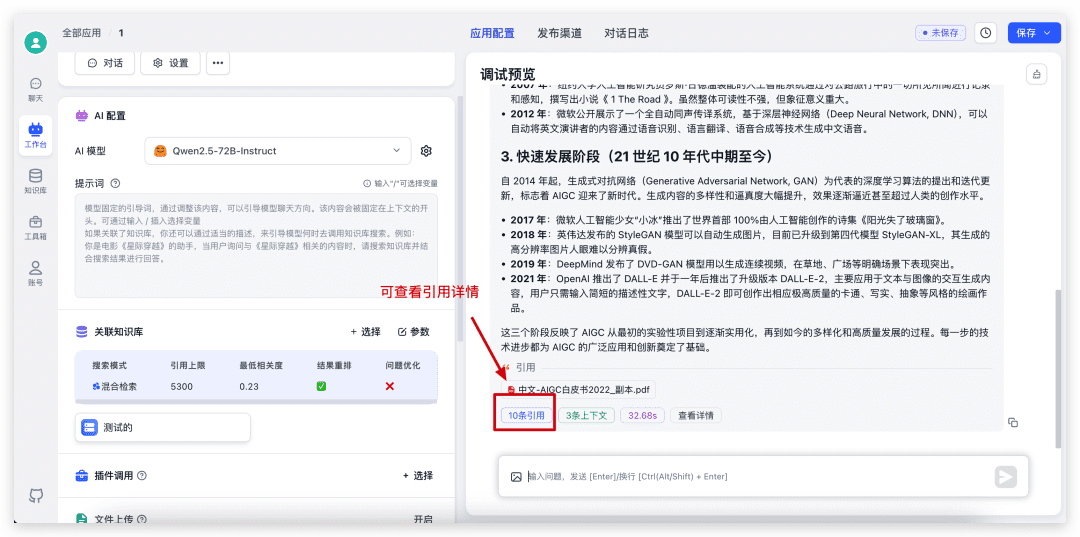
Una vez completado el diálogo, haga clic en la cita en la parte inferior para ver los detalles de la cita, así como para ver las puntuaciones específicas de recuperación y reordenación.
Prueba de reproducción de voz
Siguiendo con la aplicación, busca Voice Play en la parte izquierda de la configuración y pulsa sobre ella para seleccionar un modelo de voz en la ventana emergente y probarlo.
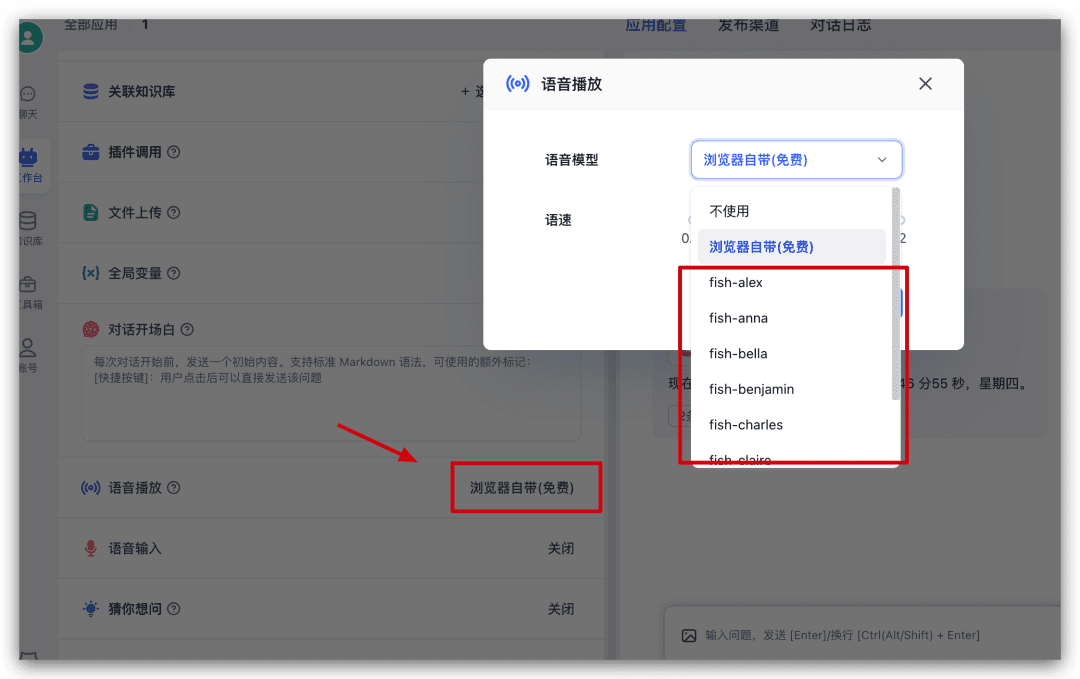
Entrada de lengua de prueba
Siga buscando la entrada de voz en la configuración del lado izquierdo en la aplicación justo ahora y haga clic en él para habilitar la entrada de idioma de la ventana emergente.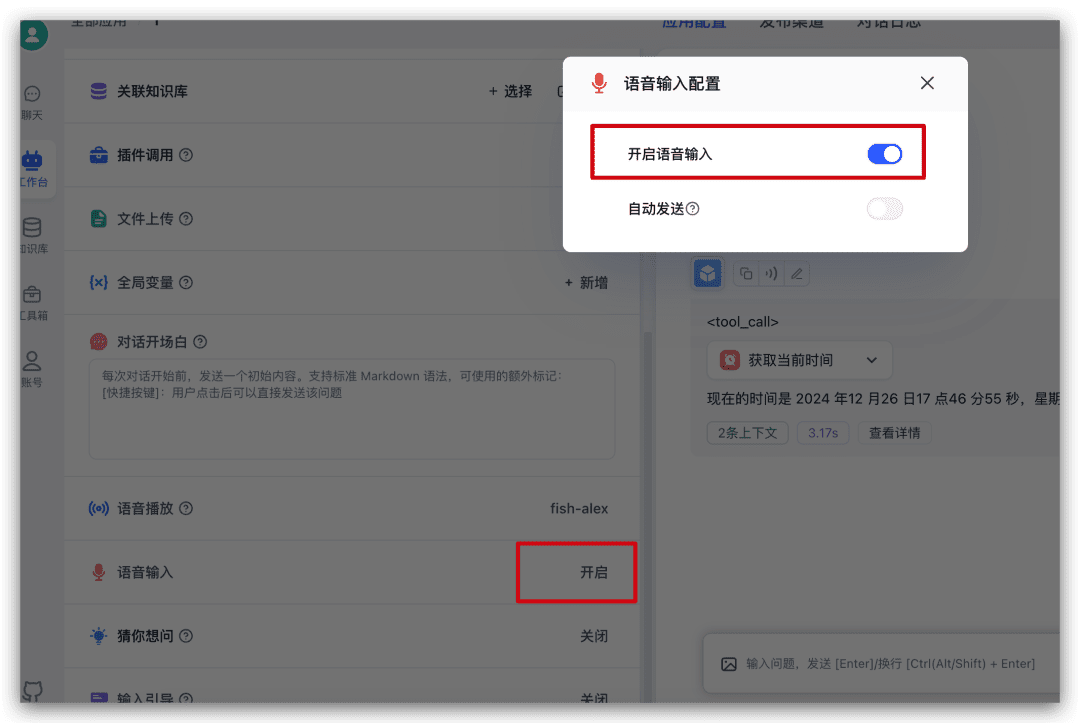
Cuando lo actives, se añadirá un icono de micrófono al cuadro de entrada de diálogo y podrás pulsarlo para introducir la voz.
resúmenes
Si quieres experimentar rápidamente el modelo de código abierto o utilizar rápidamente FastGPT, y no quieres solicitar todo tipo de API Key en diferentes proveedores de servicios, entonces puedes elegir el modelo de SiliconCloud para una experiencia rápida.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...