
¡El primer gran modelo de razonamiento de la industria financiera Regulus-FinX1 de código abierto! Du Xiaoman producción pesada, centrándose en el análisis financiero complejo y la toma de decisiones

Du Xiaoman abre el primer gran modelo mundial de razonamiento de la industria financiera: Regulus-FinX1.
El modelo es el primer macromodelo de inferencia de tipo GPT-O1 en el ámbito financiero, que utiliza un innovador"Cadena de pensamiento + Proceso de recompensas + Aprendizaje por refuerzo"El paradigma de entrenamiento mejora significativamente el razonamiento lógico y puede demostrar el proceso de pensamiento completo no revelado por el modelo O1, proporcionando una visión más profunda para la toma de decisiones financieras. Objetivos de Regulus-FinX1Tareas de análisis, toma de decisiones y tratamiento de datos en escenarios financierosSe llevó a cabo una optimización en profundidad.
Xuan Yuan-FinX1 ha sido desarrollado por Du Xiaoman AI-Lab, y este lanzamiento es una versión preliminar, que ahora está abierta a la comunidad de código abierto.Descargar gratis. Las versiones optimizadas posteriores también seguirán siendo de código abierto para su descarga y uso.
Dirección de Github: https://github.com/Duxiaoman-DI/XuanYuan
Resultados de la evaluación comparativa
La primera generación de Regulus-FinX1 demostró un excelente rendimiento en FinanceIQ, una referencia financiera. En elCPA, cualificación bancaria10 tipos de cualificaciones financieras, como cualificaciones en valores, etc.En la categoría de Actuarios, las puntuaciones de todos los grandes modelos anteriores son generalmente bajas, mientras que XuanYuan-FinX1 ha mejorado significativamente su puntuación de 37,5 a 65,7, lo que demuestra que puede utilizarse para el razonamiento lógico financiero y el razonamiento matemático. Especialmente en la categoría Actuario, todos los grandes modelos anteriores obtuvieron en general una puntuación baja, mientras que XuanYuan-FinX1 mejoró su puntuación de 37,5 a 65,7, lo que demostró significativamente su gran ventaja en razonamiento lógico financiero y cálculo matemático. 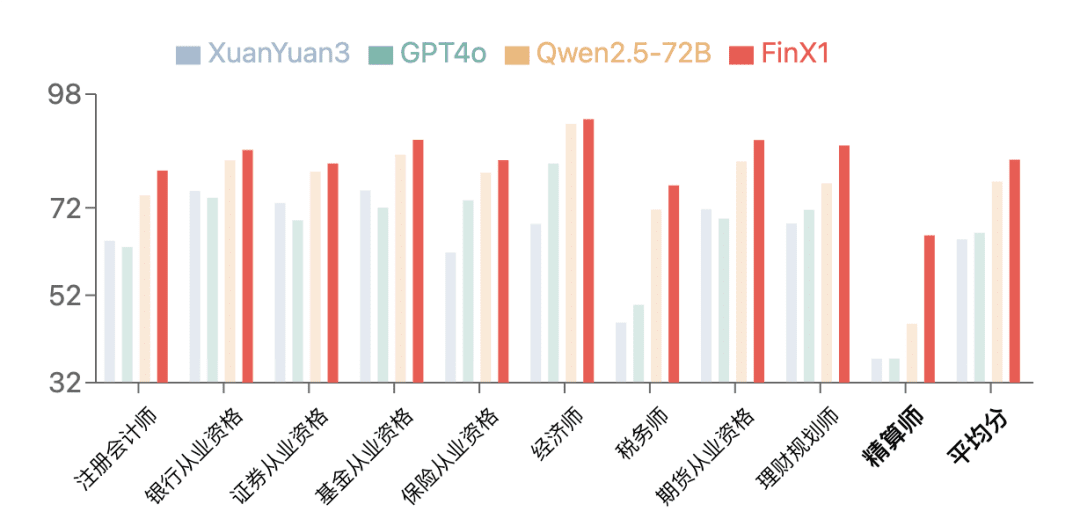
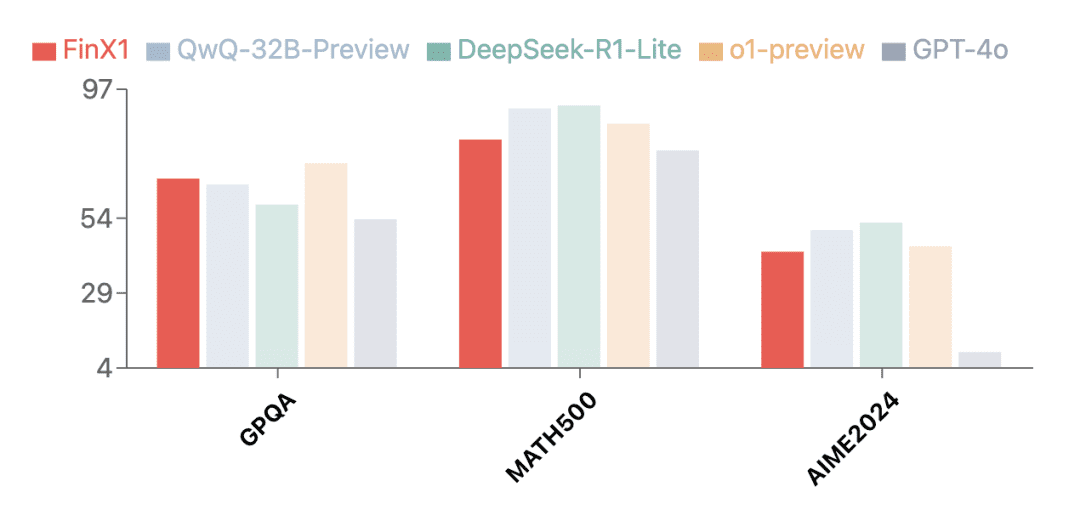
Además de en el ámbito financiero, la primera generación de Regulus-FinX1 también ha demostrado sus extraordinarias capacidades de uso general. Los resultados de las pruebas en varios conjuntos de evaluación autorizados muestran que Regulus-FinX1 no sólo está en elGPQA (Razonamiento científico)yMATH-500 (Matemáticas)responder cantandoAIME2024 (Concurso de Matemáticas)También ha superado a GPT-4o, situándose en el escalón superior junto con O1 y la versión de inferencia recién lanzada del Big Model en China, lo que verifica su gran capacidad de inferencia básica.
Romper la "caja negra": presentar toda la cadena de pensamiento
Una de las características de Regulus FinX1 es que puede presentar el proceso de pensamiento completo antes de generar una respuesta, construyendo una cadena de pensamiento totalmente transparente desde el desmontaje del problema hasta la conclusión final. Mediante este mecanismo, Regulus FinX1 no solo mejora la interpretabilidad del razonamiento, sino que también resuelve el problema de la "caja negra" de los grandes modelos tradicionales, proporcionando a las instituciones financieras una herramienta de apoyo a la toma de decisiones más creíble.

Regulus Ejemplo de generación de cadena de pensamiento para FinX1
Centrarse en la complejidad financiera y la toma de decisiones analíticas
Cuando la GPT-O1 de OpenAI llamó la atención del sector por su superior "capacidad de pensamiento", surgió una propuesta clave:¿Cómo podemos hacer que esta capacidad de razonamiento profundo cree un valor sustancial en los escenarios profesionales financieros?Du Xiaoman Regulus FinX1 da respuestas innovadoras -Por primera vez, la capacidad de razonamiento profundo de los grandes modelos se ha inyectado en el ámbito financiero, fomentando así la aplicación de los grandes modelos a laSe utiliza para profundizar desde los escenarios genéricos hasta los niveles empresariales básicos, como las decisiones de control de riesgos.
En la ola de transformación de la inteligencia digital en el sector financiero, la"Capacidades de toma de decisiones y control de riesgos", "Capacidades de investigación y análisis" y "Capacidades de inteligencia de datos".constituyen las dimensiones clave que impulsan la innovación empresarial y la mejora del valor. Estas capacidades aportan un crecimiento sostenido del valor a la entidad mediante la identificación y el control precisos del riesgo, la investigación en profundidad del mercado y el descubrimiento de valor, y la modelización y el análisis eficientes de los datos, respectivamente.
Regulus FinX1 integra profundamente las capacidades de razonamiento profundo con la experiencia financiera a través de un innovador paradigma de formación, permitiendo que estas tres capacidades se desplieguen plenamente en escenarios específicos y aportando nuevas soluciones inteligentes a la industria financiera.

01 Capacidad de decisión y control de riesgos
La capacidad de toma de decisiones y de control de riesgos es la línea vital de las instituciones financieras, que está relacionada con su buen funcionamiento y su desarrollo sostenible. En las tareas principales de identificación y predicción de riesgos, construcción de modelos de control de riesgos y formulación de estrategias, Regulus FinX1 puede analizar sistemáticamente la correlación y las rutas de conducción entre los factores de riesgo con su potente capacidad de razonamiento y su completo mecanismo de cadena mental, proporcionando a las instituciones una visión completa y en profundidad de los riesgos. Por ejemplo, basándose en el agua bancaria cargada por la autorización del usuario, Regulus FinX1 es capaz de identificar con precisión señales de riesgo como el consumo de lotería de alta frecuencia, el consumo de juegos, etc. a partir de miles de registros de transacciones, y evaluar científicamente la capacidad de reembolso y el riesgo de crédito del usuario junto con el nivel de ingresos y la carga de la deuda.

Regulus FinX1 ha respondido al clip
02 Capacidad de investigación y análisis
La capacidad de investigación y análisis es el soporte básico para la toma de decisiones financieras, que mejora la ciencia de la asignación de capital a través de una visión en profundidad a nivel macroeconómico, industrial y empresarial. Regulus FinX1 es capaz de realizar análisis multidimensionales de datos macroeconómicos, sentimiento del mercado, impactos políticos, etc., y desmontar gradualmente cuestiones complejas mediante una clara cadena lógica. Por ejemplo, a la hora de predecir la bajada de tipos de interés de la Fed en 2025 basándose en datos económicos, el modelo explora un amplio abanico de posibilidades analizando diversos factores económicos y basándose en diferentes escenarios hipotéticos, demostrando de forma exhaustiva y objetiva la perspectiva de una bajada de tipos de interés de la Fed en 2025, que actualmente coincide con las opiniones analíticas predictivas de varias instituciones. 
03 Capacidades de inteligencia de datos
La capacidad de inteligencia de datos es un apoyo importante para que las instituciones financieras logren una toma de decisiones precisa, cuyo núcleo es la capacidad eficiente de procesamiento de datos y la capacidad de análisis en profundidad. Regulus FinX1 puede ayudar a las instituciones financieras a explorar rápidamente la lógica empresarial y el valor que hay detrás de los datos. Por ejemplo, si se introducen en Regulus FinX1 los datos financieros trimestrales de una empresa, el modelo puede extraer con precisión la información esencial y mostrar visualmente la calidad de los activos, la liquidez y la dinámica empresarial. Analizando indicadores clave como "presión de liquidez" e "impulso de expansión de activos", Regulus FinX1 añade explicaciones cualitativas basadas en comparaciones cuantitativas, revelando riesgos potenciales y oportunidades de crecimiento detrás de los datos financieros y ayudando a las empresas a optimizar su toma de decisiones. 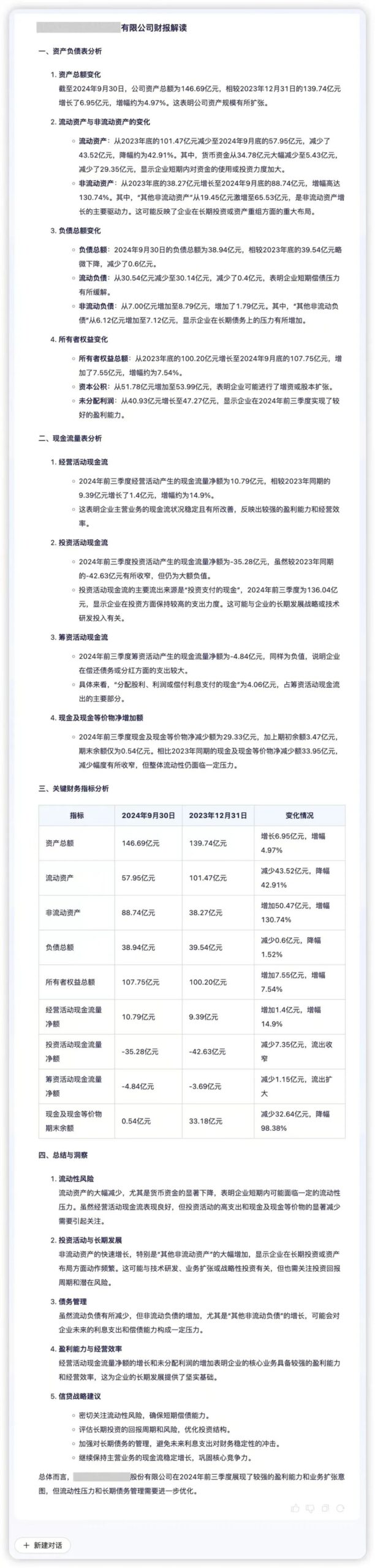
Aplicación técnica de Regulus-FinX1
Para conseguir grandes modelos con capacidades de razonamiento similares a las de O1, especialmente en escenarios complejos de análisis de decisiones en el ámbito financiero, proponemos una solución técnica que contiene tres pasos clave tras una amplia exploración y validación:Hacia un modelo estable de generación de cadenas de pensamiento, un modelo de doble recompensa para la mejora de las decisiones financieras y el ajuste del aprendizaje por refuerzo bajo la doble dirección de la PRM y la ORM.
01 Construcción inicial de un modelo generativo estable de la cadena de pensamiento
Para los escenarios de análisis de decisiones complejas en el ámbito financiero, hemos construido un modelo básico con capacidad de generación de cadenas de pensamiento estables. El primer paso es la síntesis de datos de alta calidad COT/Respuesta, que primero genera el proceso de pensamiento basado en la pregunta, y después genera la respuesta final basada en la pregunta y el proceso de pensamiento. Con esta estrategia, el modelo es capaz de centrarse en cada etapa de la tarea y generar cadenas de razonamiento y respuestas más coherentes.
Para diferentes dominios (por ejemplo, matemáticas, razonamiento lógico, análisis financiero, etc.), diseñamos métodos especiales de síntesis de datos, por ejemplo, para tareas de análisis financiero, diseñamos un método de síntesis iterativo para garantizar la exhaustividad del proceso analítico, seguido de un entrenamiento basado en el modelo XuanYuan 3.0 utilizando el ajuste fino de comandos, y adoptando un formato de salida unificado proceso de pensamiento <respuesta (esta vez también expondremos los datos de texto largo de grano grueso para mejorar el modelo). thinking> answer output format (esta vez también expondremos los nodos de pensamiento de grano grueso), y al mismo tiempo nos centraremos en construir un mayor número de datos de texto largo para mejorar la capacidad del modelo para procesar contextos largos, de modo que pueda "generar un proceso de pensamiento detallado antes de generar una respuesta". Así se sientan unas bases sólidas para el posterior entrenamiento supervisado por procesos y la optimización del aprendizaje por refuerzo.
02 Un modelo de doble recompensa para mejorar las decisiones financieras
Para evaluar el rendimiento del modelo en escenarios de toma de decisiones financieras, diseñamos elDos modelos de recompensa complementarios, orientados a los resultados (ORM) y a los procesos (PRM). Entre ellos, ORM continúa la solución técnica de XuanYuan 3.0, que se entrena mediante aprendizaje por contraste y aprendizaje por refuerzo inverso; PRM es nuestra innovación para el proceso de razonamiento, que se centra en resolver la dificultad de evaluar problemas financieros abiertos (por ejemplo, análisis de mercado, decisiones de inversión, etc.).
Para la construcción de los datos de entrenamiento de la PRM, adoptamos diferentes estrategias para distintos escenarios: para las preguntas con respuestas definidas, como las calificaciones de riesgo, utilizamos un método de validación inversa basado en MCTS; para las preguntas abiertas de análisis financiero, las anotamos en términos de dimensiones como corrección, necesidad y lógica a través de múltiples modelos de gran tamaño, y resolvemos el problema del desequilibrio de datos mediante downsampling y aprendizaje activo. En la fase de aprendizaje por refuerzo, utilizamos el algoritmo PPO para la optimización del modelo, que utiliza PRM y ORM como señales de recompensa. Para el proceso de pensamiento entre y , se utiliza PRM para puntuar cada paso del pensamiento, de modo que los errores en la ruta de pensamiento puedan detectarse y corregirse a tiempo; para la parte de la respuesta, se utilizan diferentes estrategias de evaluación para los distintos tipos de preguntas: la correspondencia de reglas se utiliza para calcular las recompensas de las preguntas financieras con una respuesta definida (por ejemplo, la evaluación del nivel de riesgo), y la correspondencia de reglas se utiliza para calcular las recompensas de las preguntas abiertas ( por ejemplo, análisis de mercado) se puntúan de forma holística utilizando ORM. Simultáneamente, se introducen técnicas como los coeficientes KL dinámicos y la normalización de la función de dominancia para estabilizar el proceso de formación. EsteMecanismos de formación basados en la doble recompensaque no sólo supera las limitaciones de un modelo de recompensa única, sino que también mejora significativamente la capacidad de razonamiento del modelo en escenarios de toma de decisiones financieras mediante un entrenamiento estable de aprendizaje por refuerzo.
Como puede verse, la clave en la ruta anterior es la construcción de datos de la cadena de pensamiento y la evaluación de modelos de recompensa para problemas abiertos en el análisis financiero que son diferentes de las matemáticas o la lógica, y todavía estamos optimizando e iterando, y seguiremos explorando rutas técnicas más eficaces.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...