
Sesame lanza el modelo de voz conversacional CSM: para que la interacción vocal con IA sea más natural

Una reciente entrada en el blog de Brendan Iribe, Ankit Kumar y el equipo de Sesame describe las últimas investigaciones de la empresa en el campo de la generación del habla conversacional, el Conversational Speech Model (CSM). CSM). El modelo está diseñado para abordar la falta de emoción y naturalidad en las interacciones actuales de los asistentes de voz, acercando las interacciones de voz de la IA al nivel humano.
Cruzar el "Valle del Terror" en busca de la "presencia de la voz".
El equipo de Sesame cree que la voz es el medio de comunicación más íntimo para los humanos y contiene una gran cantidad de información que va mucho más allá del significado literal. Sin embargo, los asistentes de voz existentes suelen carecer de expresión emocional y tener un tono plano, lo que dificulta establecer una conexión profunda con los usuarios. Al utilizar estos asistentes de voz durante un largo periodo de tiempo, los usuarios no sólo se sentirán decepcionados, sino incluso cansados.
Para resolver este problema, Sesame ha desarrollado el concepto de "presencia de voz", que significa que las interacciones de voz se sientan reales, comprendidas y valoradas, y el modelo CSM es un paso clave hacia este objetivo. El equipo de Sesame subraya que no están creando sólo una herramienta, sino un interlocutor que construye una relación de confianza con el usuario.
Conseguir "presencia de voz" no es tarea fácil y requiere una combinación de los siguientes elementos clave:
- Inteligencia emocional: Reconocer y responder a los cambios de humor del usuario.
- Dinámica de diálogo: Captar el ritmo natural del diálogo, incluidos el ritmo del habla, las pausas, las interrupciones y el énfasis.
- Conocimiento de la situación: Ajustar el tono y la expresión a diferentes escenarios de diálogo.
- Personalidad coherente: Mantener la coherencia y fiabilidad de la personalidad del asistente de IA.
Modelo CSM: monoetapa, multimodal, más eficiente
Para alcanzar estos objetivos, el equipo de Sesame ha propuesto un nuevo modelo de habla conversacional, CSM, que utiliza un marco de aprendizaje multimodal de extremo a extremo para generar un habla más natural y coherente utilizando la información del historial de la conversación.
A diferencia de los modelos tradicionales de conversión de texto a voz (TTS), el modelo CSM opera directamente sobre los tokens RVQ (cuantificación vectorial residual). Este diseño evita el cuello de botella informativo que pueden causar los tokens semánticos en los modelos TTS tradicionales, lo que permite captar mejor los matices del habla.
CSM El diseño arquitectónico del modelo también es bastante impresionante. Emplea dos transformadores autorregresivos:
- Red troncal multimodal: Procesamiento de información intercalada de texto y audio para predecir la capa cero del libro de códigos RVQ.
- Descodificador de audio: Utilizando una cabecera lineal diferente para cada libro de códigos, se predicen las N-1 capas restantes para reconstruir el habla.
Este diseño permite que el descodificador sea mucho más pequeño que el tronco, lo que se traduce en una generación de voz de baja latencia al tiempo que se mantiene el modelo de extremo a extremo.

Proceso de inferencia del modelo CSM
Además, para resolver el problema del cuello de botella de memoria durante el proceso de entrenamiento, el equipo de Sesame propuso un esquema de reparto computacional. Este esquema entrena al descodificador de audio sólo en un subconjunto aleatorio de fotogramas de audio, lo que reduce significativamente el consumo de memoria sin afectar al rendimiento del modelo.

Reparto del proceso de formación
Resultados experimentales: se acerca al nivel humano, pero sigue habiendo una brecha
El equipo de Sesame entrenó el modelo CSM en un conjunto de datos que contenía alrededor de un millón de horas de audio en inglés y utilizó una serie de métricas para evaluar a fondo el rendimiento del modelo.
Los resultados de la evaluación muestran que el modelo CSM se aproxima al nivel humano en las métricas tradicionales de tasa de error de palabra (WER) y similitud de hablante (SIM).
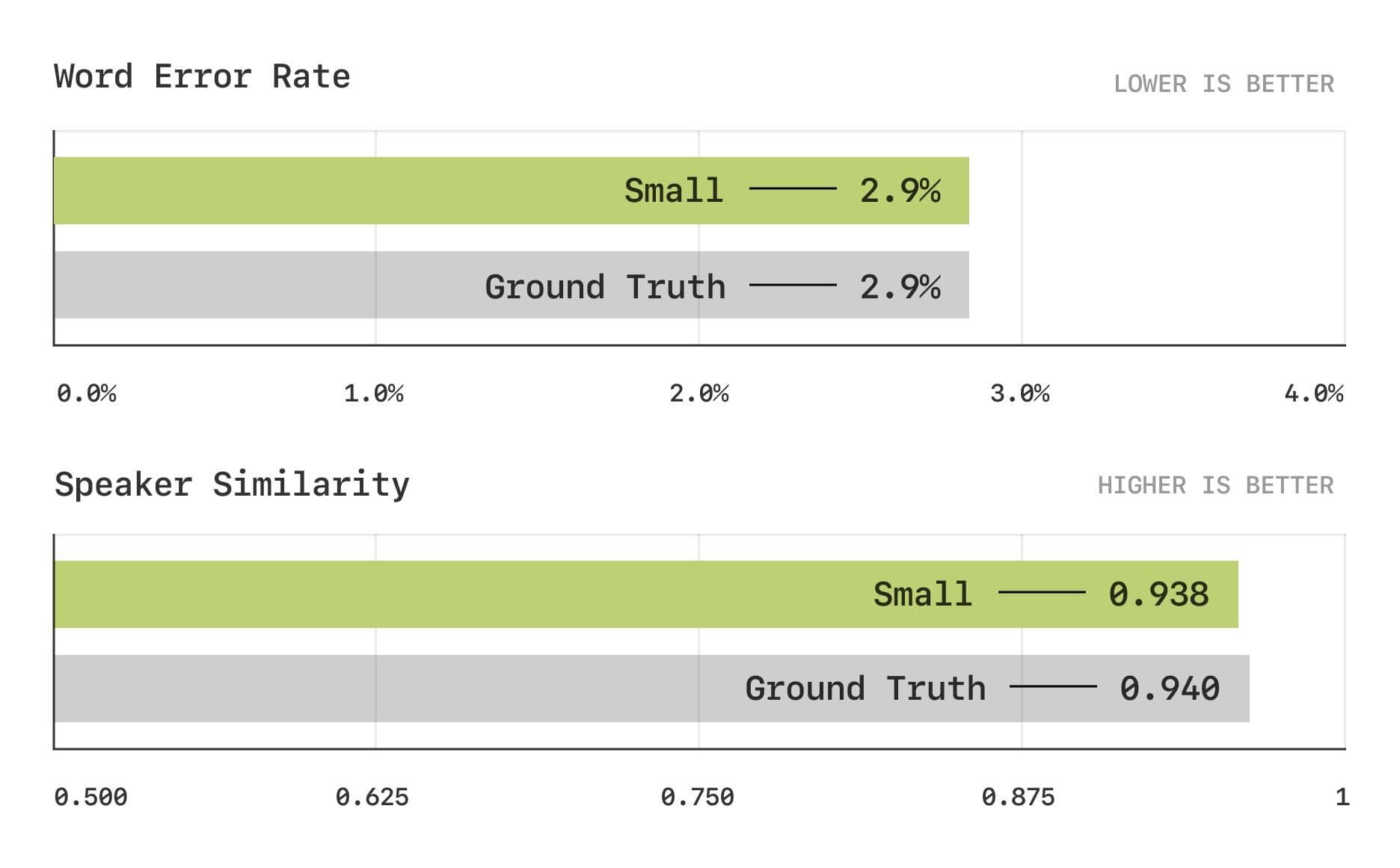
Tasa de error en las palabras y pruebas de similitud entre hablantes
Para evaluar más a fondo las capacidades del modelo en cuanto a pronunciación y comprensión del contexto, el equipo de Sesame introdujo también un nuevo conjunto de pruebas de referencia basadas en la transcripción del habla, que incluyen pruebas de desambiguación de homófonos y de coherencia de la pronunciación. Los resultados muestran que el modelo CSM también funciona bien en estas áreas y que el rendimiento mejora a medida que aumenta el tamaño del modelo.
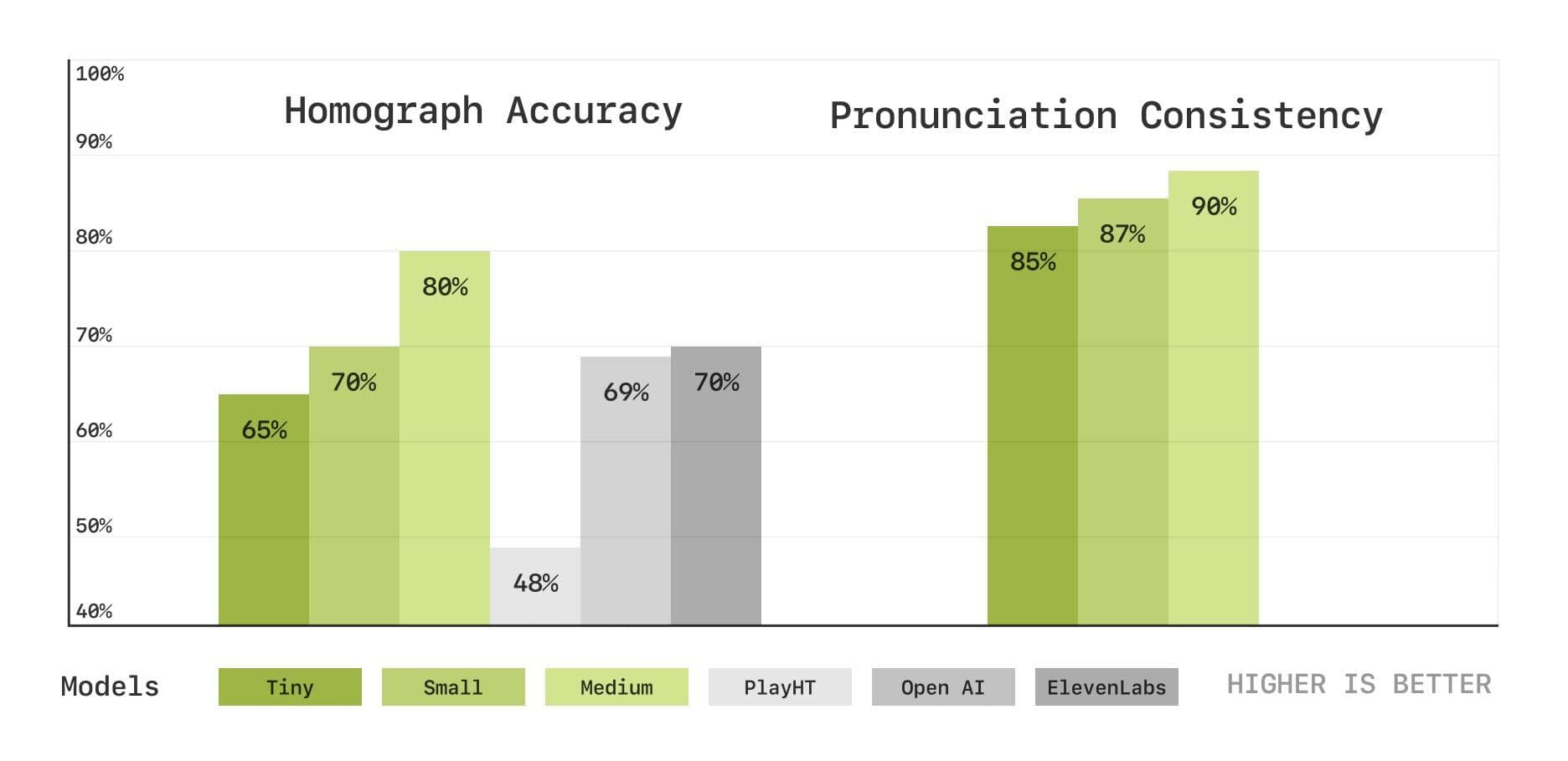
Pruebas de desambiguación de homófonos y de coherencia de la pronunciación
El equipo de Sesame llevó a cabo dos estudios de Comparative Mean Opinion Score (CMOS) utilizando el conjunto de datos Expresso. Los resultados mostraron que, sin contexto, los oyentes tenían preferencias comparables por el habla generada por CSM y el habla humana real. Sin embargo, cuando se les proporcionaba información contextual, los oyentes preferían significativamente el habla humana real. Esto sugiere que el modelo CSM aún puede mejorar a la hora de captar cambios rítmicos sutiles en el diálogo.
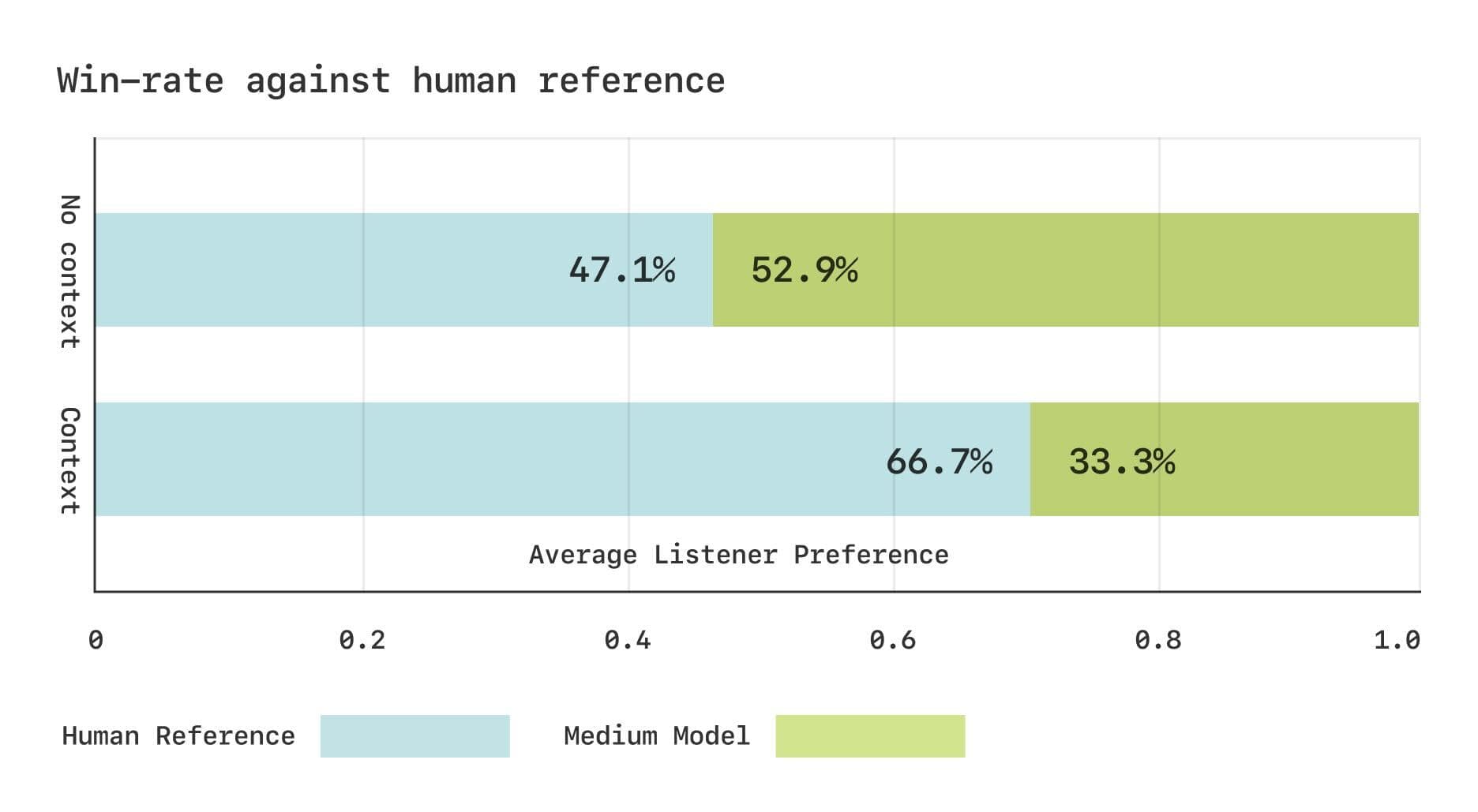
Resultados de la evaluación subjetiva del conjunto de datos Expresso
Compartir código abierto, perspectivas de futuro
Siguiendo el espíritu del código abierto, el equipo de Sesame planea abrir componentes clave del modelo CSM para el desarrollo mutuo de la comunidad.
https://github.com/SesameAILabs/csm
Aunque el modelo CSM ha hecho progresos significativos, aún tiene algunas limitaciones, como el hecho de soportar principalmente el inglés, con capacidades multilingües que deben mejorarse. el equipo de Sesame afirma que en el futuro seguirán ampliando el tamaño del modelo, aumentando la capacidad del conjunto de datos, ampliando el soporte lingüístico y explorando el uso de modelos lingüísticos de preentrenamiento para mejorar aún más el rendimiento del modelo CSM. el equipo de Sesame confía en la futura dirección de su investigación. El equipo de Sesame confía en que el futuro de la IA del diálogo esté en los modelos dúplex completos, es decir, modelos que puedan aprender implícitamente la dinámica del diálogo a partir de los datos.
En general, el modelo CSM lanzado por Sesame es un importante paso adelante en el campo de la generación de voz conversacional, que aporta nuevas ideas para construir interacciones de voz con IA más naturales y emocionales. Aunque todavía se puede mejorar, el espíritu de código abierto del equipo de Sesame y sus planes de futuro son dignos de admiración.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...