Lanzamiento de Qwen2.5-VL: admite comprensión de vídeo de larga duración, localización visual, salida estructurada, código abierto ajustable con precisión

1.Introducción del modelo
En los cinco meses transcurridos desde la publicación de Qwen2-VL, numerosos desarrolladores han creado nuevos modelos a partir del modelo de lenguaje visual Qwen2-VL, proporcionando valiosos comentarios al equipo de Qwen. Durante este tiempo, el equipo de Qwen se ha centrado en crear modelos de lenguaje visual más útiles. Hoy, el equipo de Qwen se complace en presentar al nuevo miembro de la familia Qwen: Qwen2.5-VL.
Mejoras importantes:
- Comprensión visual: Qwen 2.5-VL no sólo es capaz de reconocer objetos comunes como flores, pájaros, peces e insectos, sino también de analizar textos, tablas, iconos, gráficos y diseños en imágenes.
- Agenticidad: Qwen2.5-VL desempeña directamente el papel de un agente visual, con la funcionalidad de una herramienta de razonamiento y mando dinámico que puede utilizarse en ordenadores y teléfonos móviles.
- Comprender vídeos largos y capturar eventos: Qwen 2.5-VL puede comprender vídeos de más de 1 hora de duración, y esta vez cuenta con la nueva capacidad de capturar eventos mediante la localización de clips de vídeo relevantes.
- Capacidad de localización visual en diferentes formatos: Qwen2.5-VL puede localizar con precisión objetos en una imagen generando cajas delimitadoras o puntos, y puede proporcionar una salida JSON estable para coordenadas y atributos.
- Generación de salida estructurada: Para datos escaneados como facturas, formularios, tablas, etc., Qwen 2.5-VL soporta la salida estructurada de sus contenidos, lo que es beneficioso para su uso en finanzas, negocios y otros campos.
Modelo de arquitectura:
- Entrenamiento en resolución dinámica y frecuencia de imagen para la comprensión de vídeo:
La ampliación de la resolución dinámica a la dimensión temporal mediante el empleo del muestreo dinámico de FPS permite al modelo comprender el vídeo a distintas frecuencias de muestreo. En consecuencia, el equipo de Qwen actualizó mRoPE con ID y alineación temporal absoluta en la dimensión temporal, lo que permite al modelo aprender el orden temporal y la velocidad y, en última instancia, obtener la capacidad de identificar momentos específicos.
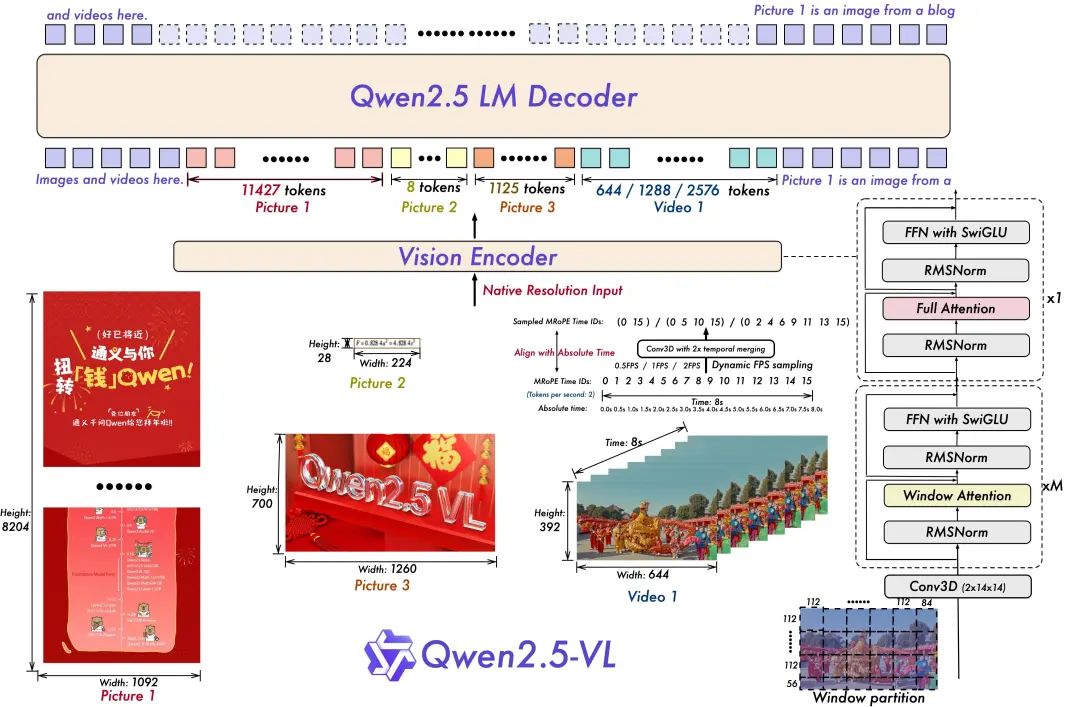
- Codificador visual ágil y eficaz
El equipo de Qwen ha mejorado el entrenamiento y la velocidad de inferencia introduciendo estratégicamente el mecanismo de atención por ventanas en ViT. La arquitectura de ViT se ha optimizado aún más con SwiGLU y RMSNorm para alinearla con la estructura del LLM 2.5 de Qwen.
Hay tres modelos en este código abierto, con parámetros de 3.000, 7.000 y 72.000 millones. Este repositorio contiene el modelo 72B ajustado por comandos. Qwen2.5-VL Modelos.
Conjunto modelo:
https://www.modelscope.cn/collections/Qwen25-VL-58fbb5d31f1d47
Experiencia en modelización:
https://chat.qwenlm.ai/
Blog de tecnología:
https://qwenlm.github.io/blog/qwen2.5-vl/
Código Dirección:
https://github.com/QwenLM/Qwen2.5-VL
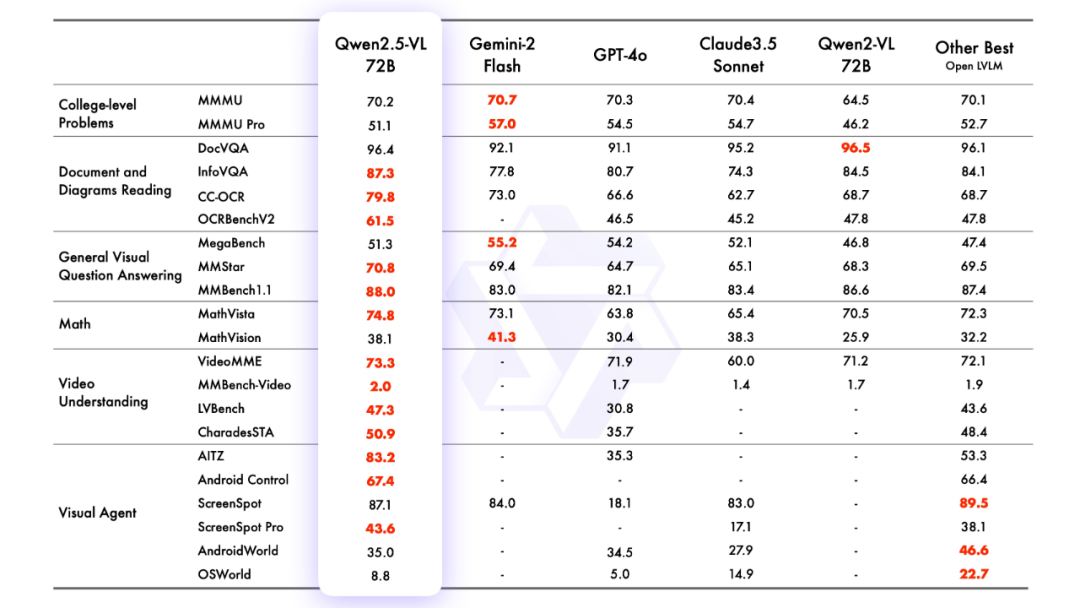
2.efecto de modelización
evaluación de modelos
Sr. José María González
3.razonamiento modelizado
Razonamiento con transformadores
El código para Qwen2.5-VL está en los últimos transformadores, y se recomienda construir desde el código fuente utilizando el comando:
pip install git+https://github.com/huggingface/transformersSe proporciona un conjunto de herramientas para facilitar el trabajo con distintos tipos de entradas visuales, como si se tratara de una API. Incluye base64, URL e imágenes y vídeos intercalados. Se puede instalar utilizando el siguiente comando:
pip install qwen-vl-utils[decord]==0.0.8Razonamiento sobre el código:
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
from modelscope import snapshot_download
# Download and load the model
model_dir = snapshot_download("Qwen/Qwen2.5-VL-3B-Instruct")
# Default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_dir, torch_dtype="auto", device_map="auto"
)
# Optional: Enable flash_attention_2 for better acceleration and memory saving
# model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-VL-3B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# Load the default processor
processor = AutoProcessor.from_pretrained(model_dir)
# Optional: Set custom min and max pixels for visual token range
# min_pixels = 256 * 28 * 28
# max_pixels = 1280 * 28 * 28
# processor = AutoProcessor.from_pretrained(
# "Qwen/Qwen2.5-VL-3B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels
# )
# Define input messages
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Prepare inputs for inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generate output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
# Print the generated output
print(output_text)
Llamada directa utilizando la API-Inferencia de Magic Hitch
La API-Inference de la plataforma Magic Match es también la primera en ofrecer soporte para la serie de modelos Qwen2.5-VL. Los usuarios de Magic Match pueden utilizarla directamente a través de la llamada API. La forma específica de utilizar API-Inference se puede encontrar en la página del modelo (por ejemplo, https://www.modelscope.cn/models/Qwen/Qwen2.5-VL-72B-Instruct):

O consulte la documentación de API-Inference:
https://www.modelscope.cn/docs/model-service/API-Inference/intro
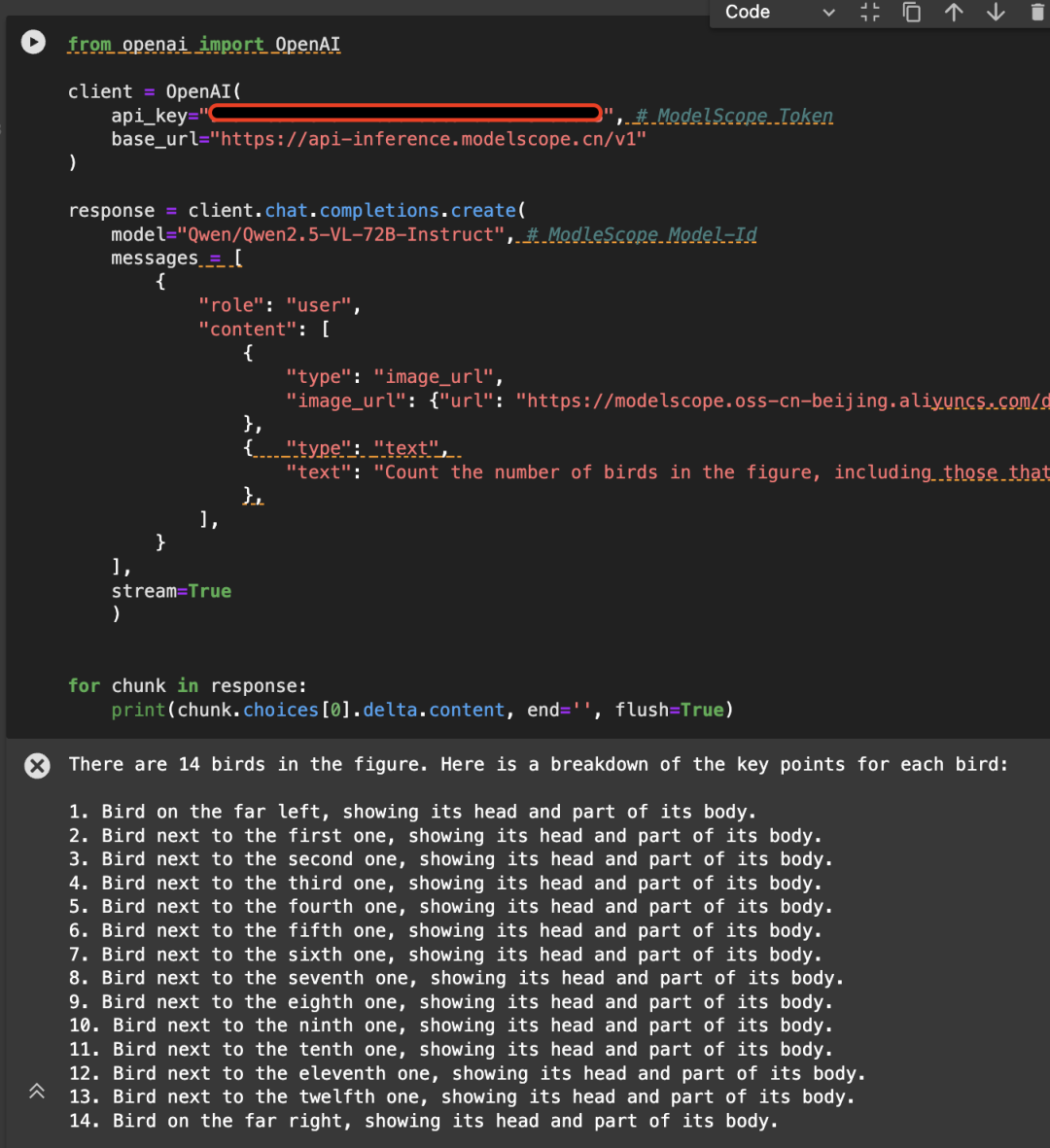
He aquí un ejemplo de la siguiente imagen, llamando a la API utilizando el modelo Qwen/Qwen2.5-VL-72B-Instruct:

from openai import OpenAI
# Initialize the OpenAI client
client = OpenAI(
api_key="<MODELSCOPE_SDK_TOKEN>", # ModelScope Token
base_url="https://api-inference.modelscope.cn/v1"
)
# Create a chat completion request
response = client.chat.completions.create(
model="Qwen/Qwen2.5-VL-72B-Instruct", # ModelScope Model-Id
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://modelscope.oss-cn-beijing.aliyuncs.com/demo/images/bird-vl.jpg"
}
},
{
"type": "text",
"text": (
"Count the number of birds in the figure, including those that "
"are only showing their heads. To ensure accuracy, first detect "
"their key points, then give the total number."
)
},
],
}
],
stream=True
)
# Stream the response
for chunk in response:
print(chunk.choices[0].delta.content, end='', flush=True)
4. Ajuste del modelo
Introducimos el uso de ms-swift en Qwen/Qwen2.5-VL-7B-Instruct ajuste fino. ms-swift es la comunidad paseo mágico proporcionado oficialmente por el modelo grande y multimodal gran marco de despliegue de ajuste fino modelo. ms-swift dirección de código abierto:
https://github.com/modelscope/ms-swift
Aquí mostraremos demostraciones de ajuste fino ejecutables y daremos el formato del conjunto de datos autodefinido.
Asegúrese de que su entorno está listo antes de empezar a afinar.
git clone https://github.com/modelscope/ms-swift.git cd ms-swift pip install -e .
El script de ajuste fino del OCR de imágenes es el siguiente:
MAX_PIXELS=1003520 \
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset AI-ModelScope/LaTeX_OCR:human_handwrite#20000 \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4
Recursos de memoria de vídeo de entrenamiento:

El guión de ajuste del vídeo está más abajo:
# VIDEO_MAX_PIXELS等参数含义可以查看:
# https://swift.readthedocs.io/zh-cn/latest/Instruction/%E5%91%BD%E4%BB%A4%E8%A1%8C%E5%8F%82%E6%95%B0.html#id18
nproc_per_node=2
CUDA_VISIBLE_DEVICES=0,1 \
NPROC_PER_NODE=$nproc_per_node \
VIDEO_MAX_PIXELS=100352 \
FPS_MAX_FRAMES=24 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset swift/VideoChatGPT:all \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--deepspeed zero2
Recursos de memoria de vídeo de entrenamiento:

El formato del conjunto de datos personalizado es el siguiente (el campo de sistema es opcional), basta con especificar `--dataset `:
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}
{"messages": [{"role": "user", "content": "<image><image>两张图片有什么区别"}, {"role": "assistant", "content": "前一张是小猫,后一张是小狗"}], "images": ["/xxx/x.jpg", "xxx/x.png"]}
{"messages": [{"role": "system", "content": "你是个有用无害的助手"}, {"role": "user", "content": "<video>视频中是什么"}, {"role": "assistant", "content": "视频中是一只小狗在草地上奔跑"}], "videos": ["/xxx/x.mp4"]}
El guión de ajuste de la tarea de puesta a tierra es el siguiente:
CUDA_VISIBLE_DEVICES=0 \
MAX_PIXELS=1003520 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset 'AI-ModelScope/coco#20000' \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--dataset_num_proc 4
Recursos de memoria de vídeo de entrenamiento:

El formato del conjunto de datos personalizado de la tarea de puesta a tierra es el siguiente:
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "<image>描述图像"}, {"role": "assistant", "content": "<ref-object><bbox>和<ref-object><bbox>正在沙滩上玩耍"}], "images": ["/xxx/x.jpg"], "objects": {"ref": ["一只狗", "一个女人"], "bbox": [[331.5, 761.4, 853.5, 1594.8], [676.5, 685.8, 1099.5, 1427.4]]}}
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "<image>找到图像中的<ref-object>"}, {"role": "assistant", "content": "<bbox><bbox>"}], "images": ["/xxx/x.jpg"], "objects": {"ref": ["羊"], "bbox": [[90.9, 160.8, 135, 212.8], [360.9, 480.8, 495, 532.8]]}}
Una vez completado el entrenamiento, la inferencia se realiza sobre el conjunto de validación del entrenamiento utilizando el siguiente comando.
Aquí `--adapters` debe ser reemplazado por la última carpeta de puntos de control generada por el entrenamiento. Dado que la carpeta de adaptadores contiene los archivos de parámetros para el entrenamiento, no es necesario especificar `--model` adicionalmente:
CUDA_VISIBLE_DEVICES=0swift infer--adapters output/vx-xxx/checkpoint-xxx--stream false--max_batch_size 1--load_data_args true--max_new_tokens 2048
Empuja el modelo a ModelScope:
CUDA_VISIBLE_DEVICES=0swift export--adapters output/vx-xxx/checkpoint-xxx--push_to_hub true--hub_model_id '<your-model-id>'--hub_token '<your-sdk-token>'
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...