
Qwen2.5-1M: Un modelo Qwen de código abierto compatible con un millón de contextos de tokens

1. Introducción
Hace dos meses, el equipo de Qwen actualizó Qwen2.5-Turbo para soportar longitudes de contexto de hasta un millón de Tokens. Hoy, Qwen ha lanzado oficialmente el modelo de código abierto Qwen2.5-1M y su correspondiente marco de inferencia. Estos son los aspectos más destacados del lanzamiento:
Modelos de código abierto: Se han lanzado dos nuevos modelos de código abierto, que son Qwen2.5-7B-Instruct-1M responder cantando Qwen2.5-14B-Instruct-1MEs la primera vez que Qwen amplía el contexto del modelo Qwen de código abierto a 1M de longitud.
Marco de razonamiento: Para ayudar a los desarrolladores a desplegar la familia de modelos Qwen2.5-1M de forma más eficiente, el equipo de Qwen ha abierto completamente el modelo Qwen 2.5-1M basado en el modelo vLLM con un enfoque integrado de atención dispersa, que hace que el marco sea más rápido en el procesamiento de 1M entradas etiquetadas por 3x a 7x.
Informe técnico: El equipo de Qwen también compartió los detalles técnicos de la serie Qwen2.5-1M, incluido el diseño de los marcos de formación e inferencia y los resultados de los experimentos de ablación.
Modelo Link:https://www.modelscope.cn/collections/Qwen25-1M-d6cf9fd33f0a40
Informe técnico:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-1M/Qwen2_5_1M_Technical_Report.pdf
Enlaces de experiencia:https://modelscope.cn/studios/Qwen/Qwen2.5-1M-Demo
2. Rendimiento del modelo
En primer lugar, veamos el rendimiento de la familia de modelos Qwen2.5-1M en tareas de contexto largo y tareas de texto corto.
tarea de contexto largo
Con una longitud de contexto de 1 millón Fichas En la tarea Passkey Retrieval, la familia de modelos Qwen2.5-1M recuperó con precisión información oculta de documentos de 1M de longitud, con sólo unos pocos errores en el modelo 7B.
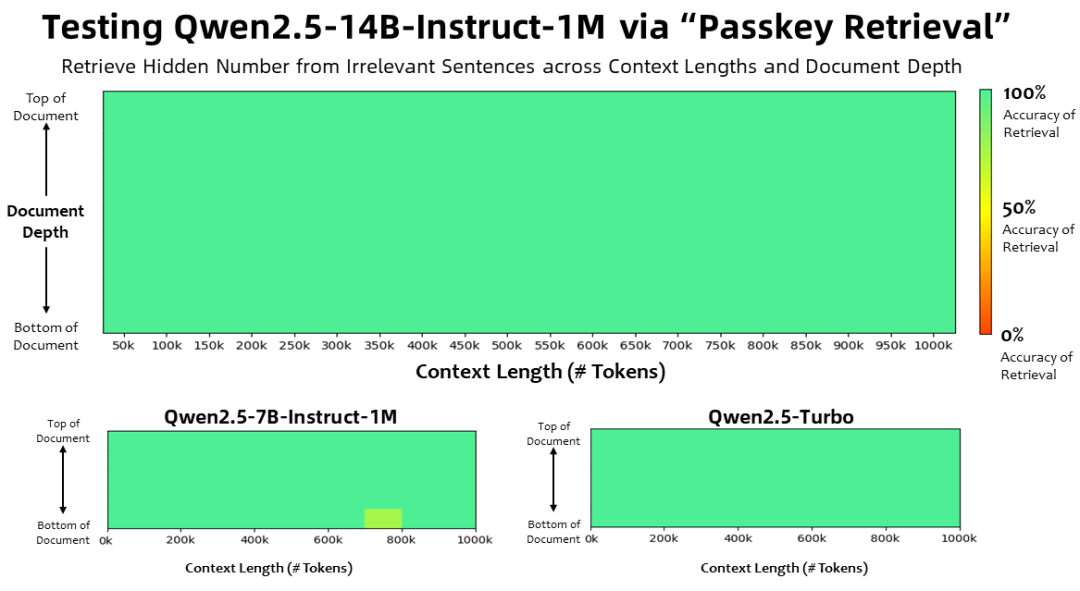
Para tareas más complejas de comprensión de contextos largos, se eligieron los conjuntos de pruebas RULER, LV-Eval y LongbenchChat.
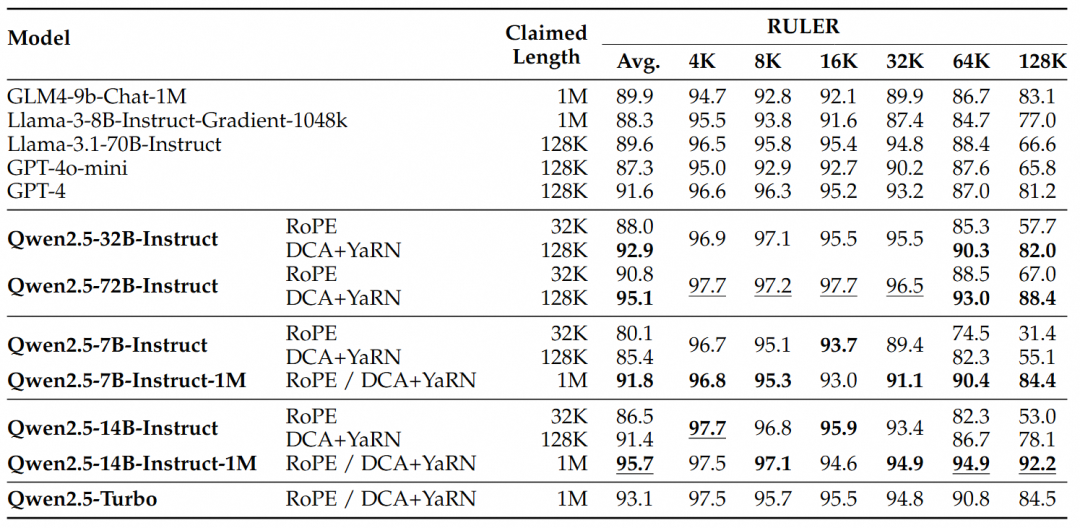
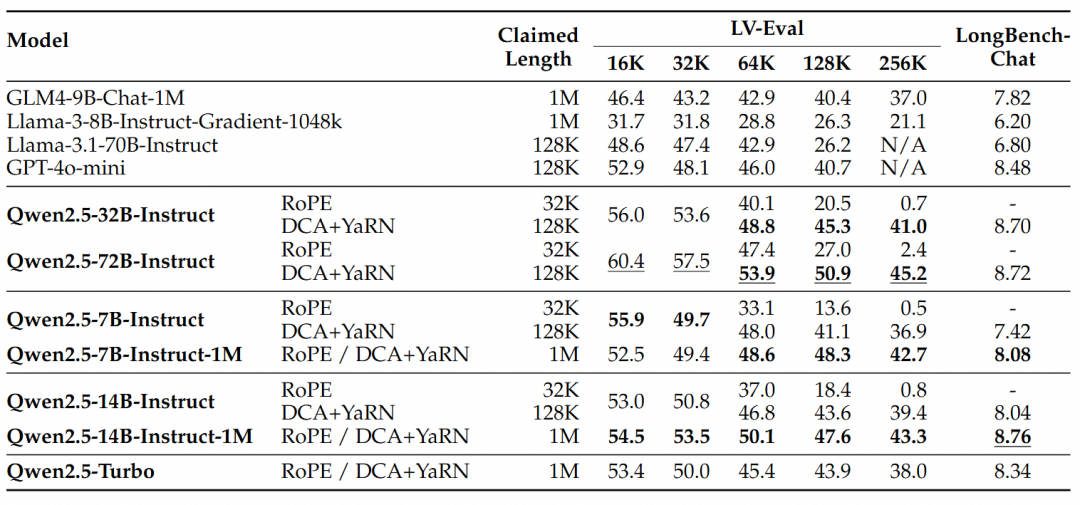
De estos resultados pueden extraerse las siguientes conclusiones clave:
- Supera significativamente a la versión de 128K:La familia de modelos Qwen2.5-1M supera con creces a la versión anterior de 128K en la mayoría de las tareas de contexto largo, especialmente cuando se trata de tareas de más de 64K de longitud.
- Las ventajas de rendimiento son evidentes:El modelo Qwen2.5-14B-Instruct-1M no sólo supera a Qwen2.5-Turbo, sino que también supera sistemáticamente a GPT-4o-mini en múltiples conjuntos de datos, proporcionando un modelo de código abierto de elección para tareas de contexto largo.
tarea secuencial corta
Además del rendimiento en tareas de secuencias largas, es igualmente importante el rendimiento del modelo en secuencias cortas. La serie de modelos Qwen2.5-1M y las versiones anteriores de 128K se compararon en pruebas de referencia académicas de uso generalizado, a las que se añadió GPT-4o-mini a efectos comparativos. 
Se puede encontrar:
- El rendimiento de Qwen2.5-7B-Instruct-1M y Qwen2.5-14B-Instruct-1M en la tarea de texto corto es comparable al de sus versiones de 128K, lo que garantiza que las capacidades básicas no se han visto comprometidas por la adición de capacidades de procesamiento de secuencias largas.
- En comparación con GPT-4o-mini, Qwen2.5-14B-Instruct-1M y Qwen2.5-Turbo consiguen un rendimiento similar en la tarea de texto corto, mientras que la longitud del contexto es ocho veces superior a la de GPT-4o-mini.
3. Tecnologías clave
Formación en contexto prolongado
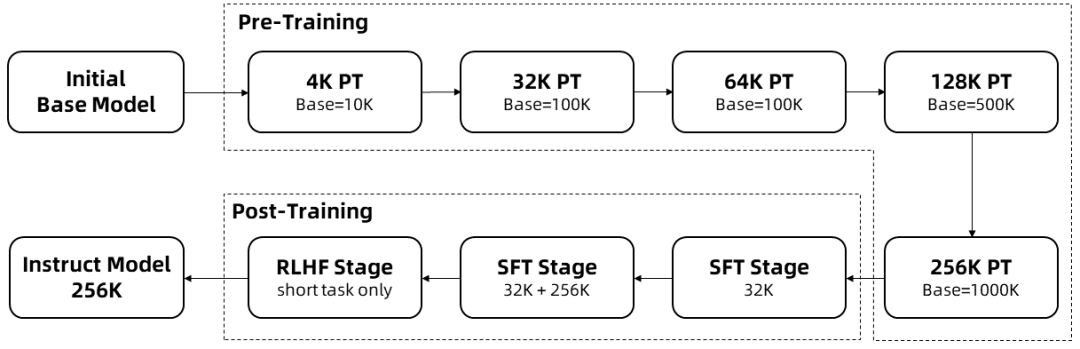
El entrenamiento de secuencias largas requiere muchos recursos computacionales, por lo que se utilizó una expansión escalonada de la longitud para ampliar la longitud de contexto de Qwen2.5-1M de 4K a 256K en múltiples etapas:
Partiendo de un Checkpoint intermedio del Qwen 2.5 pre-entrenado, la longitud del contexto es 4K en este punto.
Durante la fase de preentrenamientoAdemás, la longitud del contexto se aumentó gradualmente de 4K a 256K, mientras que la frecuencia base RoPE se incrementó de 10.000 a 10.000.000 utilizando el esquema de Frecuencia Base Ajustada.
Durante la fase de ajuste de la supervisiónen dos etapas para mantener el rendimiento en secuencias cortas:
Fase I: El ajuste fino sólo se realiza en instrucciones cortas (de hasta 32K de longitud), en las que se utilizan los mismos datos y el mismo número de pasos que en la versión de 128K de Qwen2.5.
Fase II: Se implementa una mezcla de instrucciones cortas (hasta 32K) y largas (hasta 256K) para mejorar el rendimiento de las tareas largas manteniendo la calidad de las cortas.
En la fase de aprendizaje intensivoque entrena el modelo con textos cortos (hasta 8.000 tokens). Comprobamos que, incluso cuando se entrena con libros de texto cortos, el aumento de la alineación preferida por los humanos se generaliza bien a tareas de contexto largo. Con el entrenamiento anterior, obtenemos un modelo Instruct capaz de manejar secuencias de hasta 256.000 tokens.
Con el entrenamiento anterior, se obtiene un modelo de ajuste fino de instrucciones con 256K de longitud de contexto.
Extrapolación de la longitud
En el proceso de entrenamiento anterior, la longitud de contexto del modelo es de sólo 256K tokens. Para escalarlo a 1M de tokens, se utiliza la extrapolación de longitud.
En la actualidad, los modelos lingüísticos a gran escala basados en la codificación de posición rotacional producen una degradación del rendimiento en tareas de contexto largo, que se debe principalmente a la gran distancia de posición relativa entre Query y Key, que no se ve durante el proceso de entrenamiento, al calcular los pesos de atención. Para resolver este problema, Qwen2.5-1M utiliza el método de atención a trozos dobles (DCA), que resuelve este problema tomando las posiciones relativas excesivamente grandes y reasignándolas a valores más pequeños.
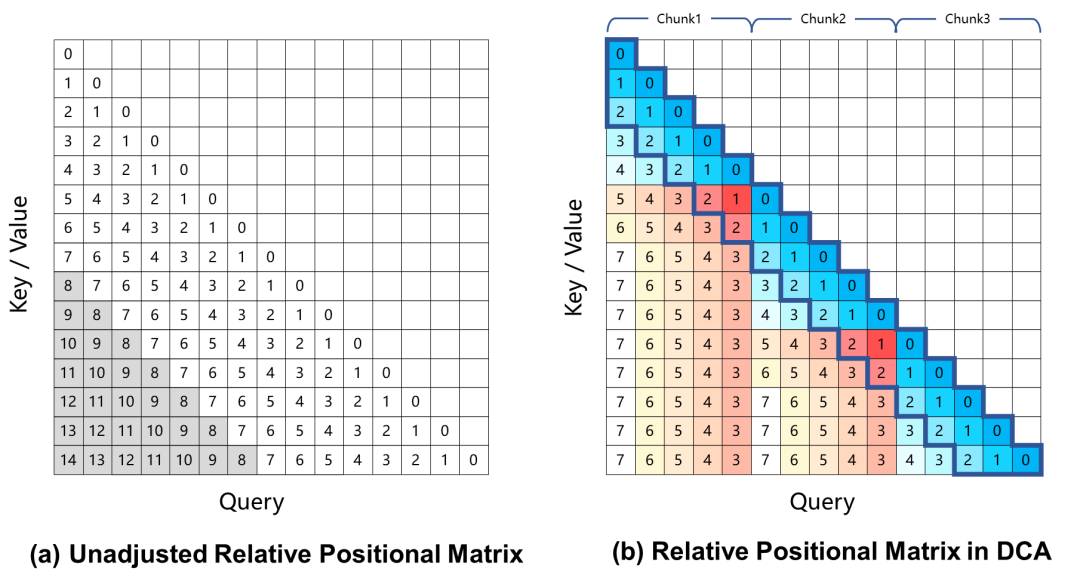
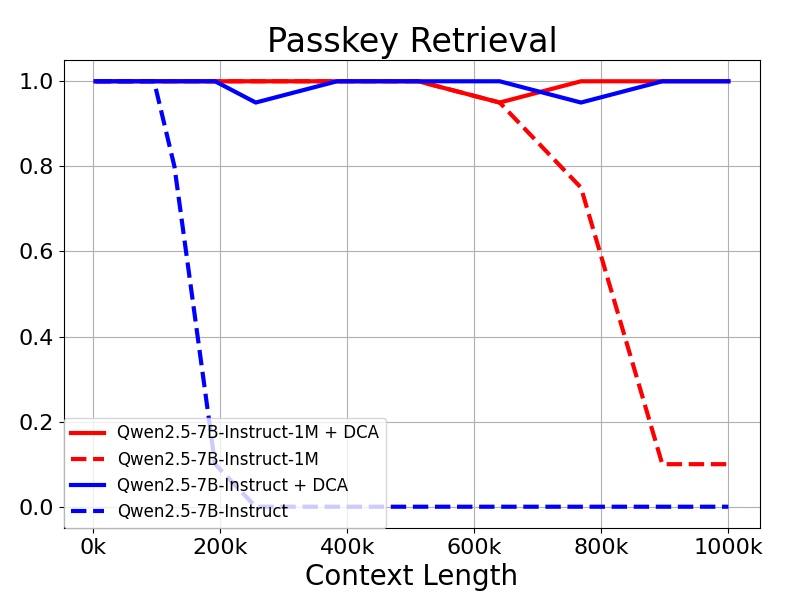
El modelo Qwen2.5-1M y las versiones anteriores de 128K se evaluaron con y sin el método de extrapolación de longitudes.
Los resultados muestran que incluso los modelos entrenados sólo con 32.000 tokens, como Qwen2.5-7B-Instruct, no son capaces de manejar el contexto de 1M de tokens de Passkey. Recuperación La tarea también alcanza una precisión casi perfecta. Esto demuestra la capacidad de DCA para ampliar significativamente la longitud de los contextos admitidos sin formación adicional.
mecanismo de atención dispersa (en física de partículas)
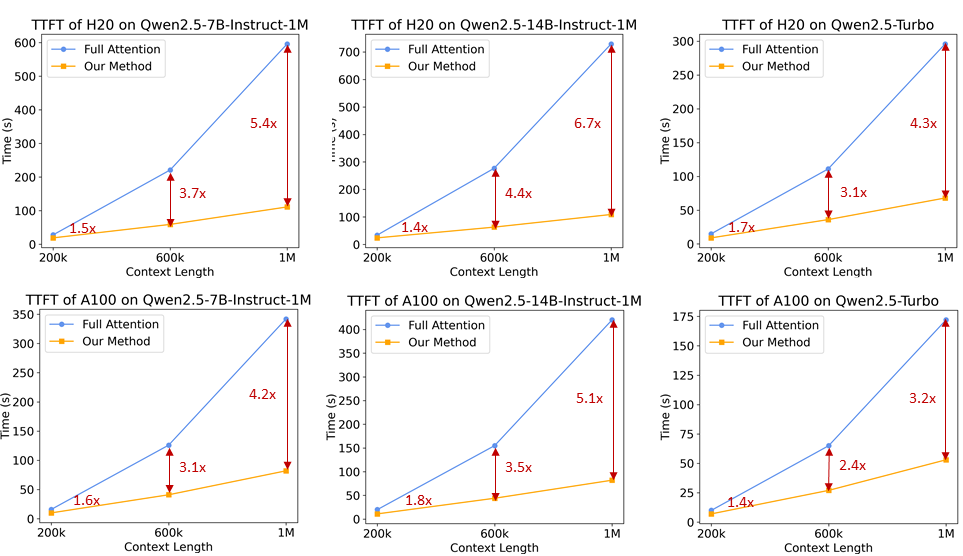
Para los modelos lingüísticos de contexto largo, la velocidad de inferencia es crucial para la experiencia del usuario. Para acelerar la fase de prepoblación, el equipo de investigación introdujo un mecanismo de atención dispersa basado en MInference. Además, se proponen varias mejoras:
- Chunked Prefill: si el modelo se utiliza directamente para procesar secuencias de hasta 1 millón de longitud, los pesos de activación de la capa MLP incurren en una enorme sobrecarga de memoria, de hasta 71 GB en el caso de Qwen2-5-7B. Tomando como ejemplo Qwen2.5-7B, esta parte de la sobrecarga es de 71 GB. Tomando Qwen2.5-7B como ejemplo, esta parte de la sobrecarga asciende a 71 GB. Adaptando Chunked Prefill con Sparse Attention, la secuencia de entrada puede dividirse en trozos de 32768 longitudes y rellenarse previamente uno a uno, y el uso de memoria de los pesos de activación en la capa MLP puede reducirse en 96,7%, lo que puede reducir significativamente los requisitos de memoria del dispositivo.
- Esquema de extrapolación de longitud integrado: Integramos además un esquema de extrapolación de longitud basado en DCA en el mecanismo de atención dispersa, lo que permite a nuestro marco de inferencia disfrutar tanto de una mayor eficiencia de inferencia como de una mayor precisión para tareas de secuencias largas.
- Optimización de la dispersión: El método original de MInference requiere una búsqueda fuera de línea para determinar la configuración óptima de dispersión para cada cabeza de atención. Esta búsqueda suele realizarse en secuencias cortas y no funciona necesariamente bien con secuencias más largas debido a los grandes requisitos de memoria de los pesos de atención completa. Proponemos un método que puede optimizar la configuración de dispersión en secuencias de 1 millón de longitud, reduciendo así significativamente la pérdida de precisión debida a la atención dispersa.
- Otras optimizaciones: Hemos introducido otras optimizaciones, como la eficiencia de los operadores y el paralelismo dinámico de las canalizaciones, para aprovechar todo el potencial del marco.
Con estas mejoras, el marco de inferencia es capaz de reducir el número de 1M ficha La velocidad de prepoblación de secuencias de longitud pasó de 3,2 veces a 6,7 veces.
4. Despliegue del modelo
Preparación del sistema
Para obtener el mejor rendimiento, se recomienda utilizar una GPU con arquitectura Ampere o Hopper que admita núcleos optimizados.
Asegúrese de que se cumplen los siguientes requisitos:
- Versión de CUDA: 12.1 o 12.3
- Versión de Python: >=3.9 y <=3.12
Requisitos de memoria, para procesar secuencias de 1M de longitud:
- Qwen2.5-7B-Instruct-1M: Requiere al menos 120 GB de memoria de vídeo (suma multi-GPU).
- Qwen2.5-14B-Instruct-1M: Requiere al menos 320 GB de memoria de vídeo (suma multi-GPU).
Si la memoria de la GPU no cumple estos requisitos, puedes seguir utilizando Qwen2.5-1M para tareas más cortas.
Instalación de dependencias
Por el momento, es necesario clonar el repositorio vLLM desde una rama personalizada e instalarlo manualmente. El equipo de investigación está trabajando para incorporar esa rama al proyecto vLLM.
git clone -b dev/dual-chunk-attn git@github.com:QwenLM/vllm.git cd vllm pip install -e . -v
Iniciar un servicio API compatible con OpenAI
Especifica que el modelo debe descargarse de ModelScope
export VLLM_USE_MODELSCOPE=True
Lanzamiento de servicios API compatibles con OpenAI
vllm serve Qwen/Qwen2.5-7B-Instruct-1M \ --tensor-parallel-size 4 \ --max-model-len 1010000 \ --enable-chunked-prefill --max-num-batched-tokens 131072 \ --enforce-eager \ --max-num-seqs 1
Descripción de los parámetros:
--tensor-parallel-size- Los modelos 7B admiten hasta 4 GPU y los modelos 14B hasta 8 GPU.
--max-model-len- Define la longitud máxima de la secuencia de entrada. Reduce este valor si tienes problemas de falta de memoria.
--max-num-batched-tokens- Establece el tamaño de bloque del Chunked Prefill. Un valor más pequeño reduce el uso de memoria de activación, pero puede ralentizar el razonamiento.
- El valor recomendado es 131072 para un rendimiento óptimo.
--max-num-seqs- Limitar el número de secuencias procesadas simultáneamente.
Interacción con los modelos
Se pueden utilizar los siguientes métodos para interactuar con el modelo desplegado:
Opción 1.
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-7B-Instruct-1M",
"messages": [
{
"role": "user",
"content": "Tell me something about large language models."
}
],
"temperature": 0.7,
"top_p": 0.8,
"repetition_penalty": 1.05,
"max_tokens": 512
}'
Opción 2. Utilizar Python
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
prompt = (
"""There is an important info hidden inside a lot of irrelevant text.
Find it and memorize them. I will quiz you about the important information there.\n\n
The pass key is 28884. Remember it. 28884 is the pass key.\n"""
+ "The grass is green. The sky is blue. The sun is yellow. Here we go. There and back again. " * 800
+ "\nWhat is the pass key?"
)
# The prompt is 20k long. You can try a longer prompt by replacing 800 with 40000.
chat_response = client.chat.completions.create(
model="Qwen/Qwen2.5-7B-Instruct-1M",
messages=[
{"role": "user", "content": prompt},
],
temperature=0.7,
top_p=0.8,
max_tokens=512,
extra_body={
"repetition_penalty": 1.05,
},
)
print("Chat response:", chat_response)
También puede explorar otros marcos, como Qwen-Agent, para que los modelos puedan leer archivos PDF, etc.
5. Utilice la API-Inferencia de Magic Hitch para llamar directamente al
La API-Inference de la plataforma Magic Match también ofrece por primera vez soporte para los modelos Qwen2.5-7B-Instruct-1M y Qwen2.5-14B-Instruct-1M. Los usuarios de Magic Hitch pueden utilizar el modelo directamente mediante llamadas a la API. El uso específico de la API-Inference puede describirse en la página del modelo (por ejemplo, https://modelscope.cn/models/Qwen/Qwen2.5-14B-Instruct-1M ):

O consulte la documentación de API-Inference: https://www.modelscope.cn/docs/model-service/API-Inference/intro
Gracias a AliCloud Hundred Refinement Platform por proporcionar soporte aritmético entre bastidores.
Uso de Ollama y llamafile
Para facilitar su uso local, Magic Hitch proporciona la versión GGUF y la versión llamafile del modelo Qwen2.5-7B-Instruct-1M por primera vez. Puede ser llamado por el framework Ollama, o utilizar llamafile directamente.
1. Llamada de Ollama
En primer lugar configurar ollama en habilitar:
ollama serve
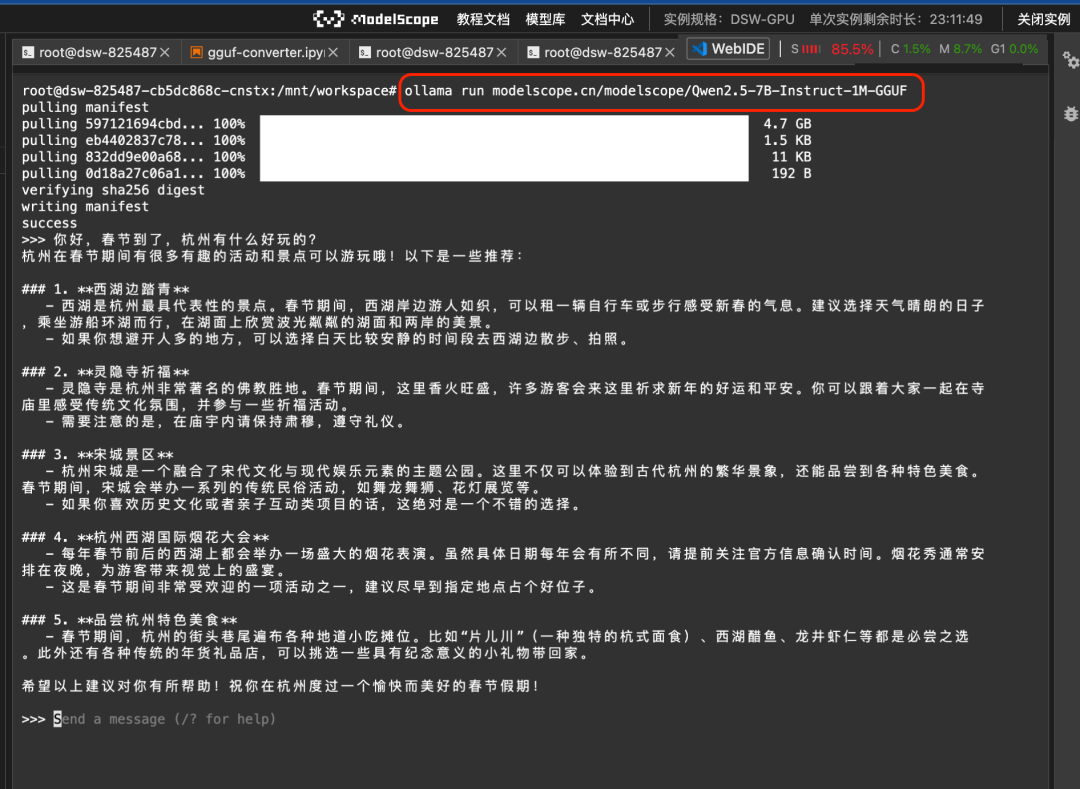
A continuación, puede ejecutar el modelo GGUF en el Magic Hitch directamente utilizando el comando ollama run:
ollama run modelscope.cn/modelscope/Qwen2.5-7B-Instruct-1M-GGUFResultados de la carrera:
2. llamafile modelo pull-up directamente
Llamafile Proporciona una solución en la que el modelo grande y el entorno de ejecución están todos encapsulados en un archivo ejecutable. Mediante la integración de la línea de comandos Magic Ride y llamafile, puede ejecutar realmente el modelo grande con un solo clic en diferentes entornos de sistemas operativos como Linux/Mac/Windows:
modelscope llamafile --model Qwen-Llamafile/Qwen2.5-7B-Instruct-1M-llamafileResultados de la carrera:
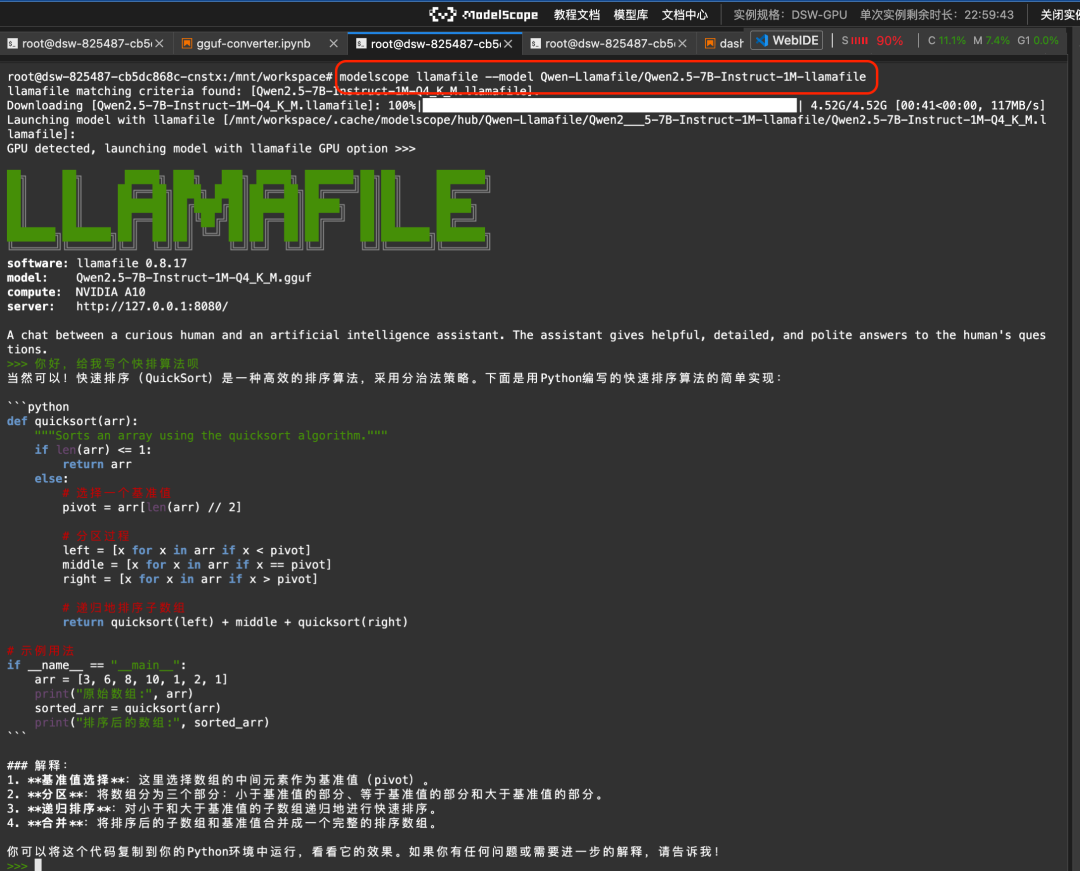
Encontrará más documentación en https://www.modelscope.cn/docs/models/advanced-usage/llamafile
6. Ajuste del modelo
Aquí presentamos el ajuste fino de Qwen/Qwen2.5-7B-Instruct-1M utilizando ms-swift.
Antes de empezar a afinar, asegúrate de que tu entorno está correctamente instalado:
# 安装ms-swift git clone https://github.com/modelscope/ms-swift.git cd ms-swift pip install -e .
Damos demos y estilos de ajuste fino ejecutables para conjuntos de datos personalizados, y los scripts de ajuste fino son los siguientes:
CUDA_VISIBLE_DEVICES=0
swift sft \
--model Qwen/Qwen2.5-7B-Instruct-1M \
--train_type lora \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_author swift \
--model_name swift-robot
Uso de la memoria de vídeo de entrenamiento:

Formato de conjunto de datos personalizado: (especifíquelo directamente con `--dataset `)
{"messages": [{"role": "user", "content": "<query>"}, {"role": "assistant", "content": "<response>"}, {"role": "user", "content": "<query2>"}, {"role": "assistant", "content": "<response2>"}]}
Guión de razonamiento:
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--max_new_tokens 2048
Empuja el modelo a ModelScope:
CUDA_VISIBLE_DEVICES=0 swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '' \
--hub_token ''
7. ¿Y ahora qué?
Aunque la familia Qwen2.5-1M aporta excelentes opciones de código abierto para tareas de procesamiento de secuencias largas, el equipo de investigación es plenamente consciente de que los modelos de contexto largo aún tienen mucho margen de mejora. Nuestro objetivo es construir modelos que destaquen tanto en las tareas cortas como en las largas para garantizar que sean realmente útiles en los escenarios de aplicación del mundo real. Para ello, el equipo está trabajando en métodos de entrenamiento, arquitecturas de modelos y enfoques de razonamiento más eficientes, de modo que estos modelos puedan desplegarse con eficacia y un rendimiento óptimo, incluso en entornos con recursos limitados. El equipo confía en que estos esfuerzos abran nuevas posibilidades para los modelos de contexto largo, amplíen drásticamente su ámbito de aplicación y sigan empujando los límites del campo, así que ¡estén atentos!
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...