PP-OCRv5 - Modelo de IA de código abierto de Baidu para el reconocimiento de texto de nueva generación
Últimos recursos sobre IAPublicado hace 6 meses Círculo de intercambio de inteligencia artificial 57.4K 00

Qué es PP-OCRv5
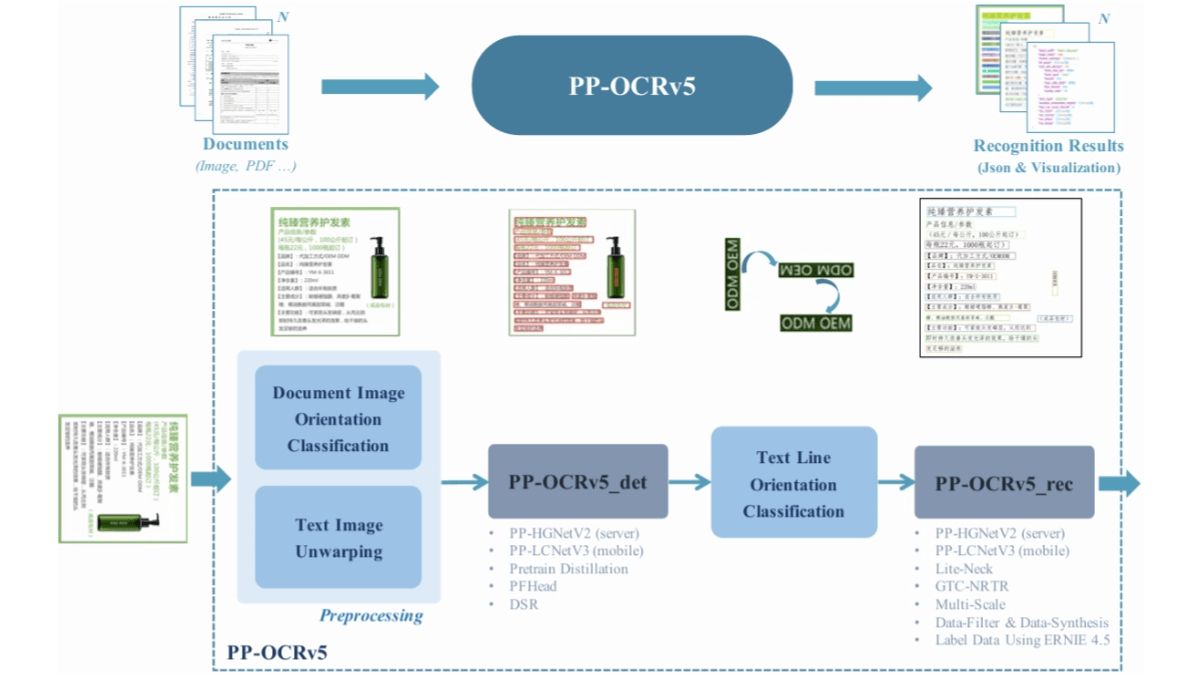
PP-OCRv5 es el modelo de IA de reconocimiento de texto de última generación lanzado por Baidu. Con un diseño ligero y un recuento de referencias de sólo 0,07B, es adecuado para funcionar de forma eficiente en CPU y dispositivos edge, y puede procesar más de 370 caracteres por segundo. El modelo admite cinco tipos de texto: chino simplificado, chino tradicional, inglés, japonés y pinyin, y puede reconocer más de 40 idiomas, lo que lo hace idóneo para el procesamiento de documentos multilingües. PP-OCRv5 adopta un proceso modular en dos fases que incluye cuatro componentes básicos: preprocesamiento de imágenes, detección de texto, clasificación de la dirección de las líneas de texto y reconocimiento de texto. En comparación con PP-OCRv4, la precisión de escenarios como la detección de escritura a mano en chino, la detección de texto antiguo, el reconocimiento de texto vertical, el reconocimiento de caracteres aislados y el reconocimiento de escritura a mano en inglés ha mejorado en 13,8%, 43%, 71%, 96% y 118%, respectivamente.PP-OCRv5 ha mejorado la columna vertebral de su proceso de preprocesamiento de imágenes, que incluye los cuatro componentes principales de preprocesamiento de imágenes, clasificación de la dirección de las líneas de texto y reconocimiento de texto. OCRv5 ha mejorado la red troncal, ha adoptado una arquitectura de doble rama y ha optimizado la estrategia de construcción de datos combinando el mecanismo de atención y la pérdida CTC para obtener datos anotados de alta calidad a partir de documentos como PDF y libros electrónicos.
Características de PP-OCRv5
- Diseño ligeroLa versión móvil puede procesar más de 370 caracteres por segundo en CPU Intel Xeon Gold 6271C, lo que permite procesar con rapidez grandes cantidades de datos de texto.
- Soporte multilingüeEs compatible con cinco tipos de texto: chino simplificado, chino tradicional, inglés, japonés y pinyin, y puede reconocer más de 40 idiomas, lo que resulta idóneo para el tratamiento de documentos multilingües y satisface las necesidades de reconocimiento de texto en distintos entornos lingüísticos.
- Reconocimiento de gran precisiónEn comparación con PP - OCRv4, su precisión en situaciones como la detección de escritura a mano en chino, la detección de texto antiguo, el reconocimiento de texto vertical, el reconocimiento de caracteres aislados y el reconocimiento de escritura a mano en inglés ha mejorado en 13,81 TP3T, 431 TP3T, 711 TP3T, 961 TP3T y 1.181 TP3T, respectivamente. reconocer varios tipos de texto con mayor precisión.
- Posicionamiento preciso del textoEl suministro de coordenadas precisas de las cajas delimitadoras de las líneas de texto es un requisito clave para la extracción de datos estructurados y el análisis de contenidos, y ayuda en el posterior trabajo de procesamiento y análisis de textos.
- Reconocimiento multilingüe con un único modeloEs el primer modelo ultraligero (<100M) de código abierto del sector que admite cinco tipos de texto en un único modelo. Consigue un reconocimiento sin fisuras de cinco tipos de texto mediante una arquitectura de modelo unificada, lo que elimina la necesidad de implantar modelos independientes para distintos tipos de texto, simplifica el proceso de implantación y mejora también la precisión y velocidad generales del reconocimiento.
- Gran capacidad de adaptación a situaciones complejasReconocimiento de texto: admite el reconocimiento de una gran variedad de situaciones difíciles, como escritura compleja en chino e inglés, texto vertical y caracteres poco comunes, y puede hacer frente a una gran variedad de formatos y contenidos de texto complejos, lo que mejora la versatilidad y viabilidad del modelo.
- Mejora de la red troncalSe utiliza una arquitectura de dos ramas con PP - HGNetV2 como columna vertebral, en la que una rama utiliza el entrenamiento basado en la atención para mejorar el modelado de secuencias, y la otra rama se centra en la inferencia eficiente utilizando la pérdida CTC. Las dos ramas colaboran entre sí durante el entrenamiento, pero sólo se utilizan ramas ligeras durante la predicción, garantizando así la precisión y la velocidad.
- Optimización de las estrategias de creación de datosCombinación de modelos tradicionales con ERNIE - 4.5 - VL - 424B - A47B para anotar y filtrar automáticamente muestras de escritura manuscrita de alta calidad, incluidos caracteres raros generados mediante síntesis. Los datos anotados a gran escala de documentos como PDF y libros electrónicos se obtienen mediante análisis sintáctico automático y filtrado por distancia de edición, lo que sienta una sólida base de datos para el rendimiento general del modelo.
Principales ventajas de PP-OCRv5
- Diseño ligeroLa versión móvil puede procesar más de 370 caracteres por segundo en una CPU Intel Xeon Gold 6271C. La versión móvil puede procesar más de 370 caracteres por segundo en una CPU Intel Xeon Gold 6271C.
- Reconocimiento de gran precisiónSupera a los modelos lingüísticos visuales de uso general, como Gemini 2.5 Pro, Qwen2.5-VL y GPT-4o, en pruebas comparativas específicas de OCR, incluidos textos manuscritos e impresos en chino e inglés, así como en pinyin.
- Soporte multilingüeAdmite cinco tipos de texto: chino simplificado, chino tradicional, inglés, japonés y pinyin, y puede reconocer más de 40 idiomas.
- Posicionamiento preciso del textoEl suministro de coordenadas precisas de los cuadros delimitadores de las líneas de texto es un requisito clave para la extracción de datos estructurados y el análisis de contenidos.
¿Cuál es el sitio web oficial de PP-OCRv5?
- Página web del proyecto:: https://huggingface.co/blog/baidu/ppocrv5
- Biblioteca de modelos HuggingFace:: https://huggingface.co/collections/PaddlePaddle/pp-ocrv5-684a5356aef5b4b1d7b85e4b
¿Para quién es PP-OCRv5?
- Desarrolladores empresarialesLa tecnología de reconocimiento de texto permite a las empresas que necesitan integrar funciones de reconocimiento de texto de alta eficacia en sus sistemas de negocio, como los sectores financiero, médico y educativo, utilizarla en situaciones como el análisis sintáctico de contratos, la digitalización de historiales médicos y la corrección de exámenes.
- investigador (científico)Los investigadores dedicados a la visión por ordenador, el procesamiento del lenguaje natural y otros campos de la inteligencia artificial pueden utilizar PP-OCRv5 para la investigación académica y la comparación de modelos.
- desarrollador de softwareLos desarrolladores de aplicaciones que requieran la funcionalidad de reconocimiento de texto, como aplicaciones móviles, software de escritorio, etc., pueden integrar rápidamente PP-OCRv5 para conseguir dicha funcionalidad.
- Analista de datos: Analistas de datos que necesitan extraer datos estructurados de un gran número de documentos para procesar y analizar rápidamente datos de texto.
- educadorEl sistema de corrección automática y análisis de contenido es ideal para profesores que necesitan procesar y analizar textos escritos a mano, como trabajos y exámenes de los alumnos.
- gestor de archivos: archiveros responsables de la gestión y digitalización de grandes cantidades de documentos en papel, y puede utilizarse para identificar y clasificar rápidamente los documentos.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...