
OpenAvatarChat: una herramienta digital de diálogo humano de diseño modular
Últimos recursos sobre IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 72.5K 00

Introducción general
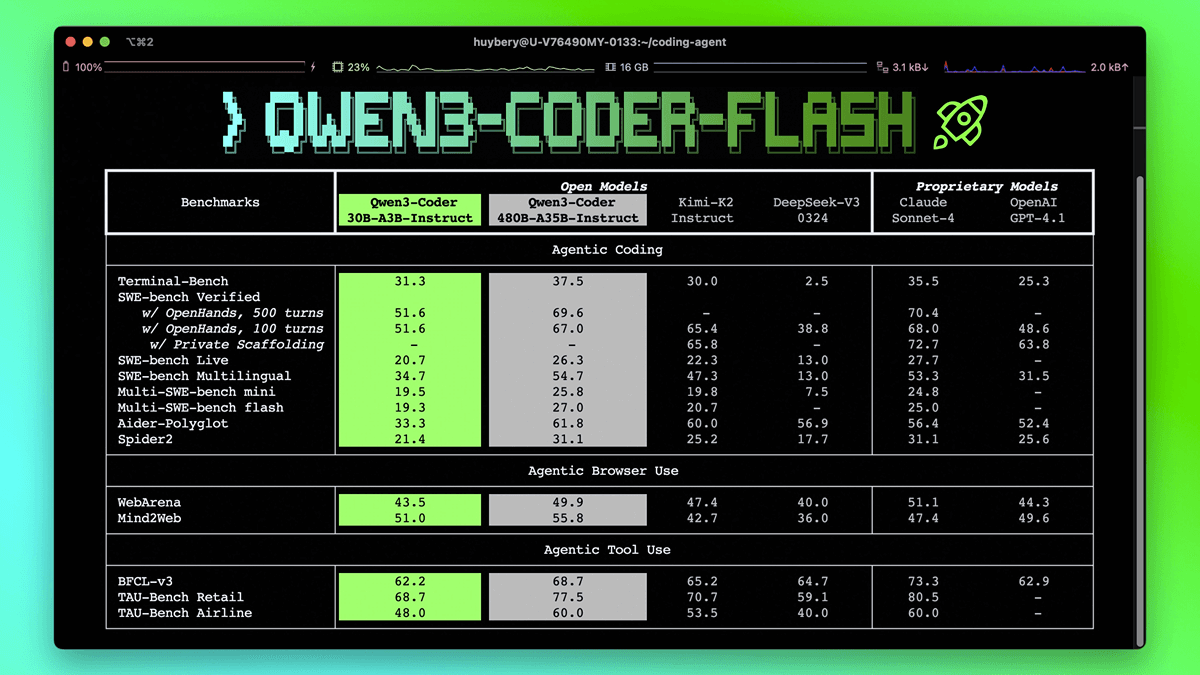
OpenAvatarChat es un proyecto de código abierto desarrollado por el equipo HumanAIGC-Engineering y alojado en GitHub. Se trata de una herramienta modular de diálogo humano digital que permite a los usuarios ejecutar todas sus funciones en un único PC. El proyecto combina vídeo en tiempo real, reconocimiento del habla y tecnología humana digital, con un diseño modular flexible y una interacción de baja latencia como características principales. El componente de audio utiliza SenseVoice, qwen-plus y CosyVoice La parte de vídeo se basa en el algoritmo LiteAvatar. El código está completamente abierto para que los desarrolladores lo estudien y mejoren.

Lista de funciones
- Diálogo humano digital modular: admite la interacción en tiempo real con voz y vídeo, los módulos pueden combinarse libremente.
- Transmisión de audio y vídeo en tiempo real: comunicación de audio y vídeo de baja latencia mediante gradio-webrtc.
- Reconocimiento y generación de voz: integración de SenseVoice y CosyVoice para gestionar la entrada y salida de voz.
- Animación humana digital: Genere expresiones y movimientos humanos digitales suaves con LiteAvatar.
- Soporte de código abierto: se proporciona el código completo y los usuarios pueden modificarlo u optimizarlo según sus necesidades.
Utilizar la ayuda
OpenAvatarChat es un proyecto de código abierto que requiere que los usuarios descarguen el código y configuren el entorno por su cuenta. A continuación se detallan los pasos de instalación y uso para ayudarte a empezar rápidamente.
Proceso de instalación
- Comprobar los requisitos del sistema
Antes de empezar, asegúrate de que tu dispositivo cumple las siguientes condiciones:- Python 3.10 o posterior.
- GPU compatible con CUDA con al menos 10 GB de memoria gráfica (20 GB o más para modelos no cuantificados).
- El rendimiento de la CPU es sólido (probado a 30FPS con i9-13980HX).
Puede comprobar la versión de Python con el siguiente comando:
python --version
- Instalación de Git LFS
El proyecto utiliza Git LFS para gestionar archivos grandes, así que instálalo primero:
sudo apt install git-lfs
git lfs install
- Descargar código
Clona el proyecto localmente introduciendo el siguiente comando en el terminal:
git clone https://github.com/HumanAIGC-Engineering/OpenAvatarChat.git
cd OpenAvatarChat
- Actualización de submódulos
El proyecto depende de varios submódulos, que se actualizan ejecutando el siguiente comando:
git submodule update --init --recursive
- Descargar modelos
El modelo de lenguaje multimodal MiniCPM-o-2.6 debe descargarse manualmente. Puede descargarlo desde Cara abrazada tal vez Modelscope Consigue. Coloque el modelo en elmodels/o ejecute un script para descargarlo automáticamente:
scripts/download_MiniCPM-o_2.6.sh
Si no hay suficiente memoria de vídeo, puedes descargar la versión int4 quantised:
scripts/download_MiniCPM-o_2.6-int4.sh
- Instalación de dependencias
Ejecútelo en el directorio raíz del proyecto:
pip install -r requirements.txt
- Generar certificado SSL
Si se requiere acceso remoto, genere un certificado autofirmado:
scripts/create_ssl_certs.sh
Los certificados se almacenan por defecto en la carpeta ssl_certs/ Carpeta.
- programa de carrera
Hay dos tipos de puesta en marcha:
- ejecutar directamente::
python src/demo.py - Operación en contenedores(Se requiere Nvidia Docker):
build_and_run.sh
Funciones principales
- Lanzamiento del diálogo humano digital
Después de ejecutar el programa, abra un navegador y visitehttps://localhost:8282(Los puertos están disponibles enconfigs/sample.yaml(Modificar). La interfaz mostrará la persona digital, haga clic en "Inicio", el programa llamará a la cámara y el micrófono, y entrar en el modo de diálogo. - interacción por voz
Al hablar por el micrófono, el sistema reconocerá la voz a través de SenseVoice, MiniCPM-o generará la respuesta y CosyVoice la convertirá en salida de voz. El digitalizador sincronizará la expresión y la forma de la boca. Las pruebas muestran una latencia de respuesta de unos 2,2 segundos (basado en i9-13900KF y RTX 4090). - Ajuste de la configuración
compiladorconfigs/sample.yamlDocumentación. Ejemplo: - Modificar el puerto: establecer el
service.portCambia a otro valor. - Ajuste la velocidad de fotogramas: ajuste
Tts2Face.fpsAjústalo a 30.
Guarde y reinicie el programa para que la configuración surta efecto.
flujo de trabajo
- Inicie el programa y espere a que la interfaz termine de cargarse.
- Comprueba que la cámara y el micrófono funcionan correctamente.
- Inicia un diálogo y el sistema procesará automáticamente la voz y el vídeo.
- Para parar, pulsa Ctrl+C para cerrar el terminal o salir de la interfaz.
Alternativas en la nube
Si la configuración local es insuficiente, puede sustituir MiniCPM-o por un LLM en la nube:
- modificaciones
src/demo.pyPara activar los procesadores ASR, LLM y TTS, consulte la sección MiniCPM. - existe
configs/sample.yamlconfigureLLM_Bailianrellene la dirección y la clave de la API, por ejemplo:
LLM_Bailian:
model_name: "qwen-plus"
api_url: "https://dashscope.aliyuncs.com/compatible-mode/v1"
api_key: "yourapikey"
- Reinicie el programa para utilizarlo.
advertencia
- Una memoria GPU insuficiente puede hacer que la aplicación se bloquee, se recomienda utilizar el modelo int4 o la API de la nube.
- Una red inestable afectará a la transmisión en tiempo real, se recomienda la conexión por cable.
- Las rutas de configuración admiten rutas relativas (basadas en el directorio raíz del proyecto) o absolutas.
escenario de aplicación
- Estudios técnicos
Los desarrolladores pueden utilizarlo para estudiar técnicas de diálogo humano digital y analizar la aplicación de diseños modulares. - prueba personal
Los usuarios pueden crear servicios locales y experimentar una interacción humana digital impulsada por la voz. - Educación y formación
Los estudiantes pueden aprender los principios del reconocimiento del habla, el modelado del lenguaje y la animación humana digital a través del código.
CONTROL DE CALIDAD
- ¿Qué pasa si no tengo suficiente memoria de vídeo?
Descargue el modelo cuantitativo int4 o utilice la API LLM basada en la nube en lugar de un modelo local. - ¿Admite diálogo multijugador?
La versión actual es adecuada para el diálogo de un solo jugador, la función multijugador debe ser desarrollada por ti mismo. - ¿Y el retraso en la carrera?
Comprueba el rendimiento de la CPU/GPU, reduce la velocidad de fotogramas o desactiva el modo rápido.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...