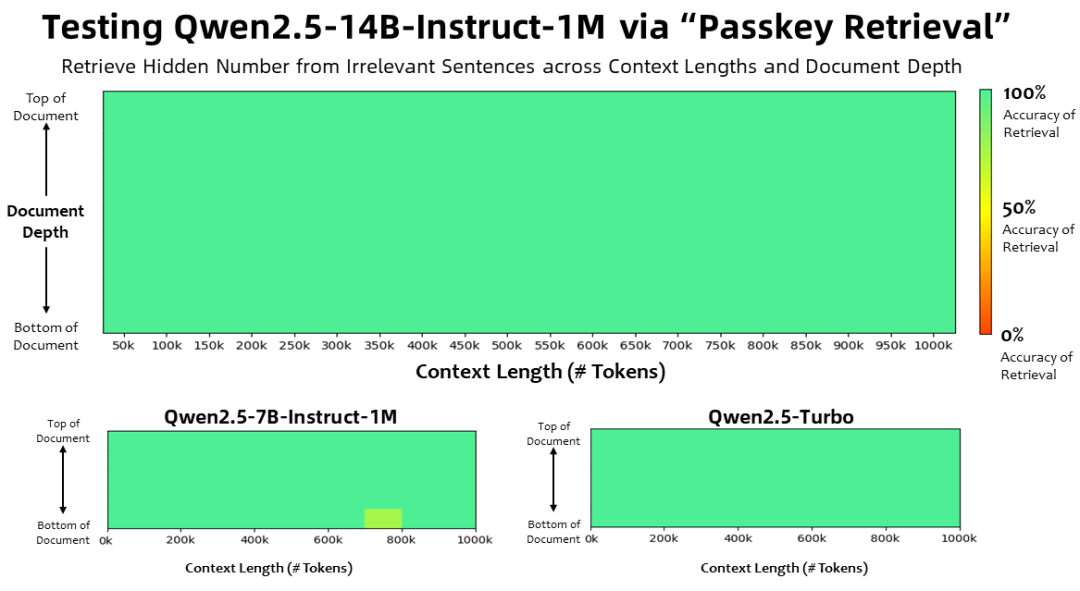
Cómo los bots de OpenAI 'actuaron como un ataque DDoS' para destruir la web de la empresa de siete personas

El sábado, el CEO de Triplegangers, Oleksandr Tomchuk, recibió la notificación de que el sitio de comercio electrónico de su empresa no funcionaba. Parecía un ataque de denegación de servicio distribuido.
Pronto descubre que el culpable es uno de los bots de OpenAI, que intenta rastrear sin descanso todo su enorme sitio web.
"Tenemos más de 65.000 productos, y cada producto tiene una página", explica Tomchuk a TechCrunch. "Cada página tiene al menos tres fotos".
OpenAI envió "decenas de miles" de peticiones al servidor intentando descargar todo este contenido, incluidos cientos de miles de fotos y sus descripciones detalladas.
"OpenAI utilizó 600 IP para rastrear los datos, y todavía estamos analizando los registros de la semana pasada, así que puede que el número sea aún mayor", dijo sobre las direcciones IP que el bot utilizó para intentar acceder a su sitio.
"Sus rastreadores estaban destruyendo nuestro sitio", dijo, "Era básicamente un ataque DDoS".
El sitio web de Triplegangers es su negocio. Esta empresa de siete empleados lleva más de una década reuniendo lo que denomina la mayor base de datos de "dobles digitales humanos" de la Red, es decir, archivos de imágenes en 3D escaneados a partir de maniquíes reales.
Vende archivos de objetos en 3D y fotografías a artistas tridimensionales, productores de videojuegos y a cualquiera que necesite reconstruir digitalmente los rasgos del cuerpo humano real, desde las manos hasta el pelo, la piel y el cuerpo entero.
El equipo de Tomchuk tiene su sede en Ucrania, pero también tiene licencia en Tampa (Florida, EE.UU.), y su sitio web tiene una página de términos de servicio que prohíbe a los bots acceder a sus imágenes sin permiso. Pero eso en sí mismo no hace nada. El sitio debe utilizar un archivo robot.txt correctamente configurado que contenga etiquetas que indiquen explícitamente al robot de OpenAI, GPTBot, que no acceda al sitio. (OpenAI tiene otros robots, ChatGPT-User y OAI-SearchBot, que tienen sus propias etiquetas, basadas en sus páginas de información sobre el rastreador).
Robot.txt, también conocido como Protocolo de Exclusión de Robots, está diseñado para indicar a los sitios web de los motores de búsqueda qué no deben rastrear porque indexan la web. openAI afirma en su página de información que cumplirá con dichos archivos cuando se configuren con su propia etiqueta de no rastreo, aunque también advierte de que sus robots pueden tardar hasta 24 horas en reconocer un archivo robot.txt actualizado.
Como experimentó Tomchuk, si un sitio no utiliza el robot.txt correctamente, OpenAI y otros lo interpretan como que pueden rastrear el contenido a voluntad. No se trata de un sistema opt-in.
Para empeorar las cosas, el bot de OpenAI no sólo está desconectando a los Tripleganger en horario laboral en Estados Unidos, sino que Tomchuk espera un aumento significativo de las facturas de AWS debido a toda la actividad de CPU y descarga del bot.
Robot.txt tampoco es infalible. Las empresas de IA lo cumplen voluntariamente. Otra startup de IA, Perplexity, adquirió notoriedad el verano pasado a raíz de una investigación de la revista Wired cuando algunas de las pruebas implicaban que Perplejidad No hay tiempo para cumplirlo.

No se puede determinar a qué se está accediendo
El miércoles, unos días después de que regresara el bot de OpenAI, los Tripleganger habían configurado correctamente el archivo robot.txt y creado una cuenta de Cloudflare para bloquear su GPTBot y algunos otros bots que encontró, como Barkrowler (un rastreador SEO) y Bytespider ( Tomchuk también espera haber bloqueado los rastreadores de otras empresas de modelado de inteligencia artificial. Según Tomchuk, el sitio no se cayó el jueves por la mañana.
Pero Tomchuk todavía no tiene una manera razonable de averiguar exactamente lo que OpenAI logró acceder o eliminar el material. OpenAI no respondió a la solicitud de comentarios de TechCrunch. OpenAI no respondió a la solicitud de comentarios de TechCrunch, y OpenAI hasta ahora no ha cumplido con su largamente prometida herramienta de exclusión, como TechCrunch informó recientemente.
Se trata de una cuestión especialmente espinosa para Triplegangers. "Los derechos son un tema serio en el negocio en el que estamos porque escaneamos a personas reales", dice. Según leyes como la GDPR europea, "no pueden simplemente tomar una foto de cualquiera en la web y usarla".
El sitio web de Triplegangers es también un hallazgo especialmente apetitoso para los rastreadores de IA. Se han fundado empresas multimillonarias, como Scale AI, en las que los humanos etiquetan minuciosamente las imágenes para entrenar a la IA. El sitio web de Triplegangers contiene fotos etiquetadas detalladas: raza, edad, tatuajes y cicatrices, todos los tipos de cuerpo, etc.
Irónicamente, la avaricia del bot de OpenAI es lo que hace que los Triplegangers se den cuenta de lo expuesto que está. Dice que si se hubiera rascado con más suavidad, Tomchuk nunca se habría enterado.
"Da miedo porque estas empresas parecen aprovecharse de un resquicio legal para rastrear datos, y dicen: 'si actualizas tu robot.txt con nuestras etiquetas, puedes excluirte'", explica Tomchuk, pero eso pone en manos de los en los propietarios de las empresas.

Quiere que otras pequeñas empresas en línea sepan que la única manera de averiguar si un robot de inteligencia artificial está accediendo a contenidos protegidos por derechos de autor en un sitio web es buscarlo activamente. Desde luego, no es el único al que aterrorizan. Otros propietarios de sitios web contaron recientemente a Business Insider cómo los bots de OpenAI estaban destruyendo sus sitios web y aumentando sus facturas de AWS.
En 2024, el problema crece exponencialmente. Un nuevo estudio de la empresa de publicidad digital DoubleVerify ha descubierto que los rastreadores de IA y las herramientas de rastreo han provocado un aumento de 861 TP3T en "tráfico general no válido" en 2024, es decir, tráfico que no procede de usuarios reales.
Sin embargo, "la mayoría de los sitios aún no saben que están siendo rastreados por estos bots", advierte Tomchuk. "Ahora tenemos que vigilar a diario la actividad de los registros para detectar estos bots".
Si lo piensas, todo el modelo funciona un poco como la extorsión mafiosa: a menos que estés protegido, los robots de la IA se llevarán lo que quieran.
"Deberían pedir permiso, no limitarse a acaparar datos", afirma Tomchuk.
Lectura relacionada.
1. OpenAI ha lanzado una nueva herramienta de rastreo web llamada GPTBot para abordar los problemas de privacidad y propiedad intelectual que plantea la recopilación de datos en sitios web públicos. La tecnología pretende recopilar de forma transparente datos de webs públicas y utilizarlos para entrenar sus modelos de IA, todo ello bajo la bandera de OpenAI.
2. OpenAI utiliza rastreadores web ("bots") y agentes de usuario para realizar acciones para sus productos que son automatizadas o desencadenadas por peticiones de los usuarios. openAI utiliza la siguiente etiqueta robots.txt para que los webmasters puedan gestionar cómo funcionan sus sitios web y contenidos con la IA . Cada configuración es independiente de las demás; por ejemplo, el administrador de un sitio puede permitir que OAI-SearchBot aparezca en los resultados de búsqueda y desactivar GPTbot para indicar que el contenido rastreado no debe utilizarse para entrenar el modelo base de IA generativa de openAI. Para los resultados de búsqueda, tenga en cuenta que pueden transcurrir unas 24 horas hasta que se realicen los ajustes desde la actualización del robots.txt de un sitio a nuestro sistema.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...