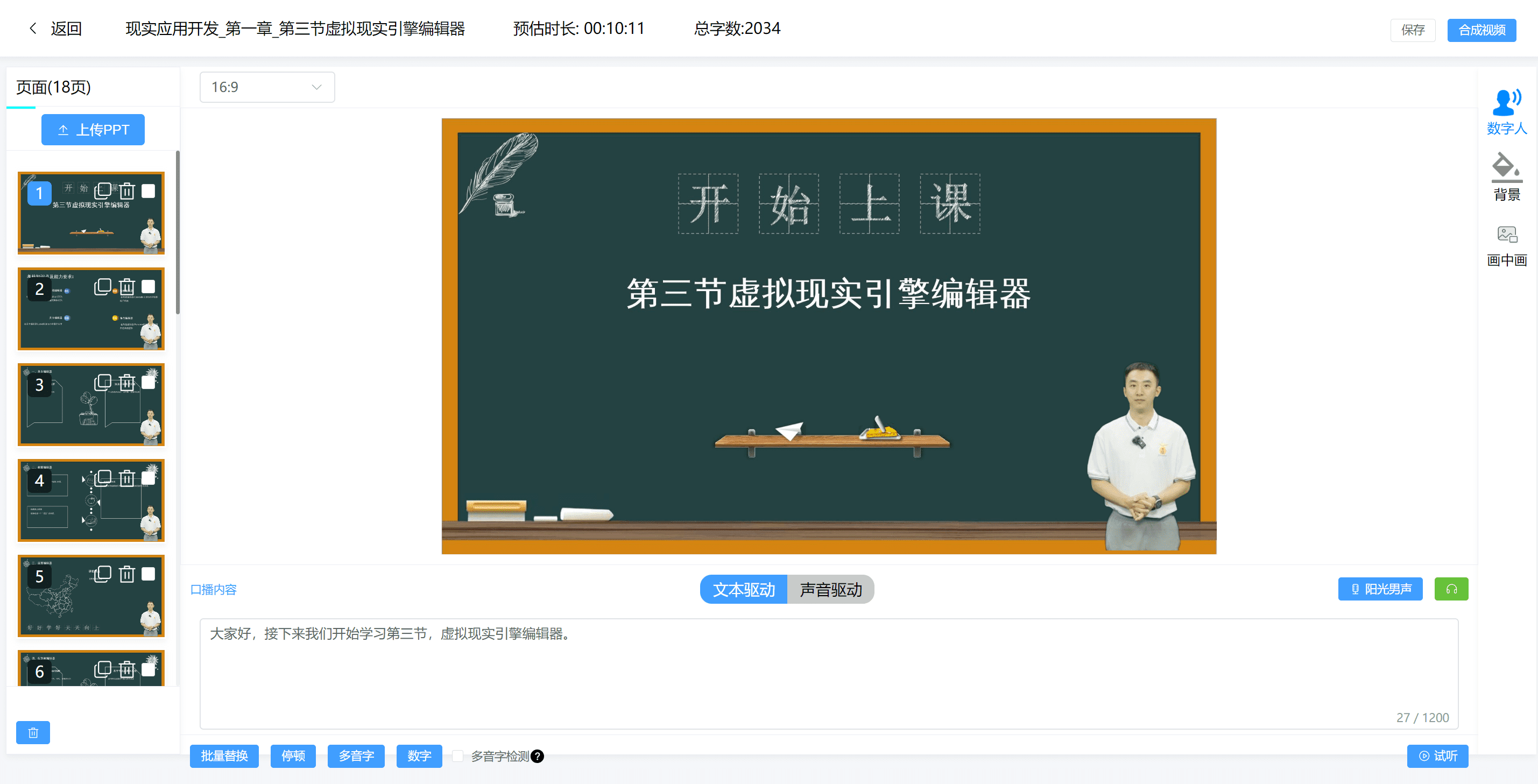
MockingBird: clonación de voz rápida y formación de modelos, conversión de texto a voz basada en xtts v2
Últimos recursos sobre IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 63.9K 00

Introducción general
MockingBird es un proyecto de código abierto cuyo objetivo es lograr una rápida clonación de voz y conversión de texto a voz mediante tecnología de IA. Los usuarios sólo tienen que proporcionar 5 segundos de muestras de voz para generar cualquier contenido de voz. El proyecto es compatible con diversos conjuntos de datos chinos y funciona bien en sistemas Windows y Linux.MockingBird utiliza el marco PyTorch y ofrece herramientas fáciles de usar e instrucciones detalladas de instalación para desarrolladores e investigadores.


Lista de funciones
- Clonación de voz: genere contenido de voz arbitrario a partir de muestras de voz de 5 segundos.
- Texto a voz: introducción de texto para generar la voz correspondiente
- Compatibilidad multilingüe: admite mandarín y múltiples conjuntos de datos chinos.
- Funcionamiento multiplataforma: compatible con sistemas Windows y Linux
- Procesamiento en tiempo real: genera voz en tiempo real
- Código fuente abierto: el código es abierto para facilitar el desarrollo secundario y la investigación.
Utilizar la ayuda
Proceso de instalación
- Preparación medioambiental::
- Instale Python 3.7 o posterior.
- Instale PyTorch (se recomienda la versión 1.9.0).
- Instala ffmpeg.
- Descargar proyecto::
- Abra la dirección del proyecto MockingBird, haga clic en el botón verde "Código" y seleccione "Descargar ZIP" para descargar el archivo del proyecto.
- O utiliza el comando git para descargarlo:
git clone https://github.com/babysor/MockingBird.git
- Instalación de dependencias::
- Vaya al directorio del proyecto y ejecute
pip install -r requirements.txtInstale los paquetes Python necesarios. - Si es necesario, puede utilizar conda para crear un entorno virtual e instalar dependencias:
conda env create -n env_name -f env.ymly, a continuación, active el entorno:conda activate env_name.
- Vaya al directorio del proyecto y ejecute
- modelo de transcripción fonética
Con el fin de reducir el tamaño del archivo principal no contiene el modelo de sonido a sonido, si necesita descargar por separado, haga clic para ir aDescargar modelo (3G)
Proceso de utilización
- Caja de herramientas de tiempo de ejecución::
- estar en movimiento
demo_toolbox.pypara abrir la pantalla Caja de herramientas. - Seleccione el archivo de muestra de voz en la caja de herramientas, introduzca el contenido del texto y haga clic en el botón Generar para generar el archivo de voz correspondiente.
- estar en movimiento
- Modelos de formación::
- Si necesitas entrenar tu propio modelo, puedes seguir el tutorial de entrenamiento del proyecto.
- Descargue y prepare el conjunto de datos de entrenamiento, ejecute
train.pyEmpieza a entrenar. - Archivo de ayuda en chino para modelos de formación
- llamada remota::
- MockingBird proporciona una función de servidor web que permite utilizar los resultados de voz generados mediante una invocación remota.
- Configure e inicie el servidor web al que se llamará mediante la interfaz API.
problemas comunes
- fallo de instalaciónAsegúrese de que su versión de Python cumple los requisitos y preste atención a la compatibilidad de versiones cuando instale PyTorch.
- calidad de vozLa calidad de las muestras de habla y la riqueza del conjunto de datos de entrenamiento afectan a la eficacia del habla generada, por lo que se recomienda utilizar muestras de habla de alta calidad y conjuntos de datos diversos para el entrenamiento.
Descarga preempaquetada para Windows (3,7 G/con modelado de texto a sonido)
Enlace de descarga de Baidu.com
Descargue/sobrescriba el paquete de actualización directamente en el directorio app.exe.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...