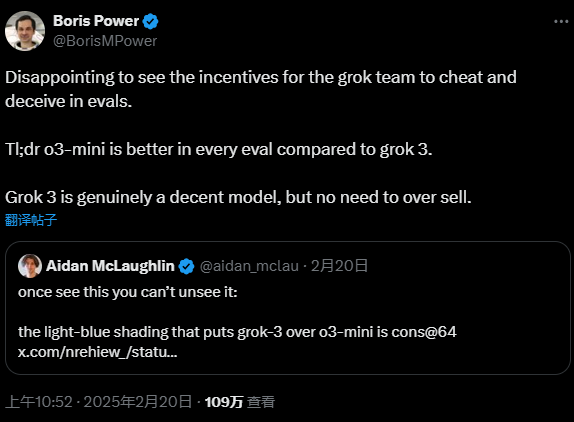
Modelo de generación de vídeo Mochi 1: SOTA en los modelos de generación de vídeo de código abierto

Genmo AI es un laboratorio de inteligencia artificial de vanguardia dedicado al desarrollo de modelos de generación de vídeo de código abierto de última generación. Su producto estrella, Mochi 1, es un modelo de generación de vídeo de código abierto capaz de generar vídeos de alta calidad a partir de pistas textuales.El objetivo de Genmo es impulsar la innovación en inteligencia artificial a través de la tecnología de generación de vídeo, ofreciendo posibilidades ilimitadas de exploración y creación virtual.

Models es una biblioteca de código abierto de modelos de generación de vídeo, que incluye los últimos modelos Mochi 1. Mochi 1 se basa en la difusión asimétrica. Transformador (AsymmDiT), con 1.000 millones de parámetros, es el mayor modelo de generación de vídeo publicado. El modelo es capaz de generar vídeos de acción fluidos y de alta calidad, y es muy sensible a las señales textuales.
Mochi 1 Preview es un modelo abierto de generación avanzada de vídeo con movimiento de alta fidelidad y fuerte seguimiento de pistas. Nuestro nuevo modelo acorta significativamente la distancia entre los sistemas de generación de vídeo cerrados y abiertos. Publicaremos el modelo bajo una licencia liberal Apache 2.0.
Mochi 1 dirección previa
Cara de abrazo (pesos del modelo)
Playground (demostración en línea)
[bilibili]https://www.bilibili.com/video/BV1FRy6YeEui/[/bilibili]
Lista de funciones
- Generación de vídeo: Genere contenidos de vídeo de alta calidad introduciendo indicaciones de texto.
- modelo de código abierto: Mochi 1 está disponible como modelo de código abierto, lo que permite la adaptación individual y el desarrollo secundario por parte del usuario.
- Calidad de movimiento de alta fidelidad: Genera vídeos con movimientos suaves y física de alta fidelidad.
- Potente alineación de tacosLa capacidad de generar vídeos que se ajusten con precisión a las necesidades del usuario basándose en indicaciones de texto.
- Apoyo comunitarioProporcionar una plataforma comunitaria en la que los usuarios puedan compartir y debatir los contenidos de vídeo generados.
- Soporte multiplataformaCompatibilidad con múltiples plataformas, incluidas la web y los dispositivos móviles.
Arquitectura del modelo Mochi 1
Mochi 1 representa un avance significativo en la generación de vídeo de código abierto con un modelo de difusión de 10.000 millones de parámetros basado en nuestra novedosa arquitectura Asymmetric Diffusion Transformer (AsymmDiT). Entrenado completamente desde cero, es el mayor modelo de generación de vídeo jamás lanzado públicamente. Y lo que es más importante, se trata de una arquitectura sencilla y pirateable.
La eficiencia es fundamental para garantizar que la comunidad pueda ejecutar nuestros modelos. Además de Mochi, también hemos puesto en código abierto nuestro VAE de vídeo, que comprime el vídeo a un tamaño reducido de 128x, utilizando un espacio de 8x8 y una compresión temporal de 6x a 12 canales de espacio potencial.
AsymmDiT procesa eficazmente las indicaciones del usuario y los marcadores de vídeo comprimidos simplificando el procesamiento del texto y centrando la capacidad de la red neuronal en la inferencia visual.AsymmDiT utiliza un mecanismo de autoatención multimodal para centrarse conjuntamente en el texto y los marcadores visuales y aprende una capa MLP independiente para cada modalidad, de forma similar a Stable Diffusion.3 Sin embargo, debido a las grandes dimensiones ocultas, nuestra tienen casi cuatro veces más parámetros para el flujo visual que para el flujo de texto. Para unificar las modalidades en el mecanismo de autoatención, utilizamos un QKV asimétrico y una capa de proyección de salida. Este diseño asimétrico reduce los requisitos de memoria de inferencia.
Muchos modelos de propagación modernos utilizan varios modelos lingüísticos preentrenados para representar las indicaciones del usuario. En cambio, Mochi 1 codifica las indicaciones con un único modelo lingüístico T5-XXL.
Mochi 1 utiliza un mecanismo atencional tridimensional completo para razonar conjuntamente sobre una ventana contextual de 44.520 marcadores de vídeo. Para localizar cada marcador, ampliamos la incrustación de posición rotacional (RoPE) a 3 dimensiones. La red aprende una mezcla de frecuencias de ejes espaciales y temporales de extremo a extremo.
Mochi se beneficia de algunas de las últimas mejoras en extensiones de modelos lingüísticos, como la capa de avance SwiGLU, la normalización de claves de consulta para mejorar la estabilidad y la normalización de entrepiso para controlar la activación interna.
A continuación se publicará un documento técnico que ofrecerá más detalles para facilitar los avances en la generación de vídeo.
Proceso de instalación de Mochi 1
- almacén de clones ::
git clone https://github.com/genmoai/models
cd models
- Instalación de dependencias ::
pip install uv
uv venv .venv
source .venv/bin/activate
uv pip install -e .
- Descargar modelos de pesos Descarga el archivo de pesos de Hugging Face o a través de un enlace magnético y guárdalo en una carpeta local.
Proceso de utilización
- Iniciar la interfaz de usuario ::
python3 -m mochi_preview.gradio_ui --model_dir "<path_to_downloaded_directory>"
intercambiabilidad<path_to_downloaded_directory>es el directorio donde se encuentran los pesos del modelo.
- Generación de vídeo por línea de comandos ::
python3 -m mochi_preview.infer --prompt "A hand with delicate fingers picks up a bright yellow lemon from a wooden bowl filled with lemons and sprigs of mint against a peach-colored background. The hand gently tosses the lemon up and catches it, showcasing its smooth texture. A beige string bag sits beside the bowl, adding a rustic touch to the scene. Additional lemons, one halved, are scattered around the base of the bowl. The even lighting enhances the vibrant colors and creates a fresh, inviting atmosphere." --seed 1710977262 --cfg_scale 4.5 --model_dir "<path_to_downloaded_directory>"
intercambiabilidad<path_to_downloaded_directory>es el directorio donde se encuentran los pesos del modelo.
Vive Mochi 1 en línea
- Ir a la página de generación: Tras identificarte, haz clic en "Playground" para acceder a la página de generación de vídeos.
- pregunta de entradaIntroduzca la descripción del vídeo que desea generar en la casilla correspondiente. Por ejemplo: "Tráiler de las aventuras de un astronauta de 30 años con un casco de moto de lana roja".
- Selección de ajustesSeleccione el estilo de vídeo, la resolución y otros ajustes según sea necesario.
- Generar vídeoHaga clic en el botón "Generar" y el sistema generará el vídeo según sus indicaciones.
- Descargar y compartirUna vez generado, el vídeo puede previsualizarse y descargarse localmente, o compartirse directamente en las redes sociales.
Funciones avanzadas
- Modelos personalizadosLos usuarios pueden descargar los pesos del modelo para Mochi 1 y entrenarlos y ajustarlos localmente para personalizarlos.
- Interacción comunitariaÚnete a la comunidad Discord de Genmo para intercambiar experiencias y compartir vídeos generados con otros usuarios.
- Interfaz APILos desarrolladores pueden utilizar la interfaz API proporcionada por Genmo para integrar funciones de generación de vídeo en sus aplicaciones.
problemas comunes
- Fallo de generación de vídeoAsegúrese de que los enunciados introducidos son claros y específicos, evitando descripciones vagas o complejas.
- Problemas de inicio de sesiónSi no puede conectarse, compruebe su conexión a Internet o pruebe con otro navegador.
- Descarga de modelos: Visita la página GitHub de Genmo para descargar los últimos pesos del modelo Mochi 1.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...