Ming-flash-omni-Preview - Macromodelo totalmente modal de código abierto del Grupo Ant
Últimos recursos sobre IAPublicado hace 5 meses Círculo de intercambio de inteligencia artificial 30.8K 00

¿Qué es Ming-flash-omni-Preview?
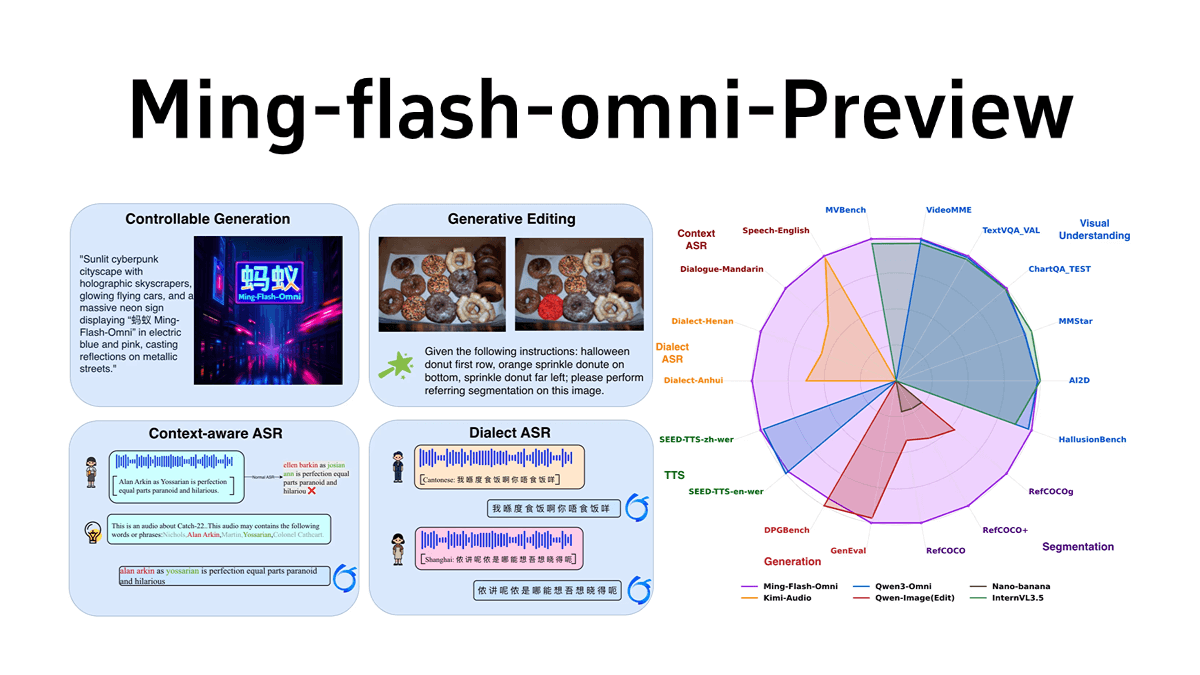
Ming-flash-omni-Preview es un macromodelo full-modal de código abierto publicado por inclusionAI de Ant Group, con una escala de parámetros de cientos de miles de millones, basado en la arquitectura sparse MoE de Ling 2.0, con un total de parámetros de 103B y activaciones de 9B. destaca en la comprensión y generación full-modal, especialmente en la generación de imágenes controlables, la comprensión de vídeo streaming, el habla y el reconocimiento dialectal. En concreto, presenta ventajas significativas en la generación de imágenes controlables, la comprensión de vídeo en streaming, el reconocimiento del habla y de dialectos, y la clonación de timbres. El primer "paradigma de segmentación generativa" consigue un control semántico espacial detallado y una generación de imágenes altamente controlable; el modelo puede comprender vídeo en streaming a un nivel detallado y ofrecer explicaciones en tiempo real; en el campo del habla, admite la comprensión del habla y el reconocimiento dialectal conscientes del contexto, y su capacidad para comprender 15 dialectos chinos ha mejorado notablemente, así como su capacidad de clonación tímbrica. La arquitectura de entrenamiento del modelo es eficiente y el rendimiento del entrenamiento se ha mejorado gracias a varias optimizaciones.
Características de Ming-flash-omni-Preview
- Capacidad modal total: Admite múltiples entradas y salidas modales, como imagen, texto, vídeo y audio, con potentes funciones de comprensión y generación multimodal.
- Generación controlada de imágenesEl primer "paradigma de segmentación generativa", que permite un control semántico espacial detallado y mejora significativamente la capacidad de control de la generación y edición de imágenes.
- Comprensión del vídeo en streamingpermite una comprensión detallada de las secuencias de vídeo, proporciona descripciones en tiempo real de los objetos y las interacciones pertinentes, y admite el diálogo continuo basado en escenarios realistas.
- Fonética y comprensión dialectal: Admite el reconocimiento de voz basado en el contexto (ContextASR) y el reconocimiento de dialectos, con una comprensión muy mejorada de 15 dialectos chinos.
- clonación de tonosCapacidad de generación de voz mejorada, capaz de clonar eficazmente el timbre del diálogo original en el nuevo diálogo generado, con pronunciación mixta estable en chino e inglés.
- Marco de formación eficazBasándose en la arquitectura MoE dispersa, se mejora el rendimiento del entrenamiento a través de varias optimizaciones para lograr "gran capacidad y pequeña activación" para cada modo.
- Código abierto y apoyo comunitarioEl modelo y el código son de código abierto y se pueden encontrar recursos en GitHub, HuggingFace y ModelScope para que los desarrolladores los prueben y den su opinión.
Principales ventajas de Ming-flash-omni-Preview
- 100.000 millones de parámetrosEl primer macromodelo modal completo de código abierto, con una escala de parámetros de cientos de miles de millones, posee potentes capacidades computacionales y una rica comprensión semántica.
- Arquitectura de ME dispersaLa arquitectura MoE dispersa basada en Ling 2.0 consigue "gran capacidad, pequeña activación", lo que mejora el rendimiento y la flexibilidad del modelo manteniendo una alta eficiencia computacional.
- Rendimiento del liderazgo multimodal: Alcanza el nivel líder de los modelos full-modal de código abierto en tareas multimodales como la generación de imágenes, la comprensión de vídeo y el reconocimiento del habla, y destaca especialmente en la generación de imágenes controladas y el reconocimiento de dialectos.
- Paradigma innovador de segmentación generativaSe propone un paradigma de formación colaborativa de "segmentación generativa como edición" para reconstruir la segmentación de imágenes en una tarea de edición que preserva la semántica, lo que mejora significativamente la capacidad de control de la generación de imágenes y la calidad de la edición.
- Formación y optimización eficacesEl problema de la heterogeneidad de los datos y de los modelos en el entrenamiento multimodal se resuelve mediante técnicas como el empaquetado de secuencias y el corte elástico del codificador, que mejoran drásticamente el rendimiento del entrenamiento.
¿Cuál es la página web oficial de Ming-flash-omni-Preview?
- Repositorio GitHub: https://github.com/inclusionAI/Ming
- Biblioteca de modelos HuggingFace: https://huggingface.co/inclusionAI/Ming-flash-omni-Preview
Ming-flash-omni-Preview's Multitud Aplicable
- Investigadores en inteligencia artificialDedicado a la investigación multimodal, el modelo puede utilizarse para explorar nuevos métodos y escenarios de aplicación para la fusión multimodal de imagen, vídeo y habla.
- ingeniero de desarrollo: Quienes deseen integrar funciones multimodales en sus proyectos, como el desarrollo de aplicaciones para el análisis inteligente de vídeo, la interacción por voz, la generación de imágenes, etc., pueden conseguirlo rápidamente gracias a sus potentes capacidades multimodales.
- científico de datosEl preprocesamiento de datos, la extracción de características, etc., mejoran la eficacia y la calidad del tratamiento de datos.
- Diseñador de productos: Centrada en la experiencia del usuario y la innovación de productos, su capacidad de generación multimodal puede aprovecharse para diseñar funciones de producto más creativas e interactivas.
- educadorLa tecnología de la información: puede aplicarse en el campo de la educación, como el desarrollo de software educativo inteligente para mejorar la eficacia de la enseñanza y la interactividad mediante el reconocimiento de voz, la generación de imágenes y otras funciones.
- creador de contenidos: como productores de vídeo, diseñadores, escritores, etc., pueden utilizar sus capacidades generativas para generar rápidamente contenidos creativos y mejorar la eficacia creativa.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...