MiDashengLM: el modelo de comprensión de sonido de código abierto de Xiaomi
Últimos recursos sobre IAActualizado hace 8 meses Círculo de intercambio de inteligencia artificial 44.4K 00

Qué es MiDashengLM
MiDashengLM es el gran modelo de código abierto de Xiaomi para la comprensión eficaz del sonido, con la versión de parámetros específicos MiDashengLM-7B, centrada en el procesamiento y la comprensión del audio. El modelo se basa en el codificador de audio Xiaomi Dasheng y el decodificador Qwen2.5-Omni-7B Thinker, que pueden unificar la comprensión del habla, el sonido ambiente y la música. El modelo tiene una excelente eficacia de inferencia y es el primer Ficha Los datos de entrenamiento de MiDashengLM son completamente de código abierto, lo que permite su uso tanto académico como comercial y proporciona un potente soporte para mejorar la experiencia de interacción multimodal.
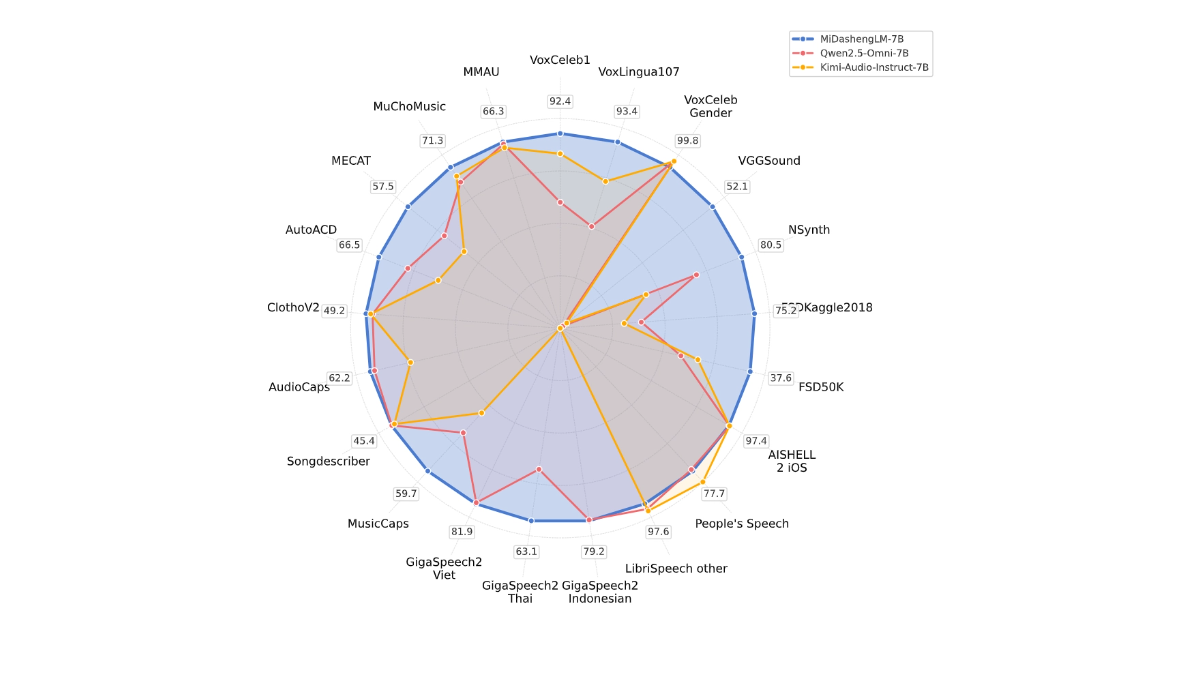
Características principales de MiDashengLM
- Contenido de audio a textoEl modelo traduce varios tipos de audio, como voces habladas, sonidos de la naturaleza o música, en descripciones textuales que ayudan a comprender rápidamente lo que está ocurriendo en el audio.
- Identificar las categorías de audio: El modelo puede decir si un fragmento de audio es habla, sonido ambiente o música, etc., al igual que etiquetar el audio para facilitar su uso en diferentes escenarios.
- reconocimiento de voz: Convierte en texto lo que dice una persona, admite varios idiomas y está especialmente indicado para su uso en asistentes de voz o dispositivos inteligentes.
- Preguntas y respuestas sonoras: Responde a preguntas basadas en el contenido de audio, por ejemplo, pregunta "¿Qué ha sido ese sonido?" en el coche, y el modelo responde.
- interacción multimodalLa capacidad de entender el audio y otra información (por ejemplo, texto, imágenes) conjuntamente, lo que permite interacciones más inteligentes y naturales con los dispositivos.
Dirección del sitio web oficial de MiDashengLM
- Repositorio GitHub:: https://github.com/xiaomi-research/dasheng-lm
- Biblioteca de modelos HuggingFace:: https://huggingface.co/mispeech/midashenglm-7b
- Documentos técnicos:: https://github.com/xiaomi-research/dasheng-lm/blob/main/technical_report/MiDashengLM_techreport.pdf
- Demostración de la experiencia en línea:: https://huggingface.co/spaces/mispeech/MiDashengLM-7B
Cómo utilizar MiDashengLM
- Experiencia en líneaVisite la dirección de demostración de la experiencia en línea de MiDashengLM.
- Cargar archivos de audioCarga un archivo de audio (los formatos admitidos son WAV, MP3, etc.).
- En espera de tratamientoEl modelo procesa automáticamente el audio una vez cargado y genera los resultados.
- Ver resultadosUna vez finalizado el procesamiento, visualice la descripción o los resultados de clasificación generados por el modelo.
Puntos fuertes de MiDashengLM
- Eficacia de la inferenciaMiDashengLM: La eficacia de la inferencia de MiDashengLM es extremadamente alta, la latencia del primer token es muy baja y el rendimiento mejora considerablemente, lo que lo hace adecuado para escenarios de interacción en tiempo real.
- Potente comprensión de audio: permite una comprensión unificada de una amplia gama de audio, incluido el habla, el sonido ambiente y la música, evitando las limitaciones de los métodos tradicionales.
- Datos y modelos Fuente abiertaLos datos de entrenamiento y los modelos son de código abierto, lo que facilita la investigación y el desarrollo secundario por parte de los desarrolladores y favorece el uso académico y comercial.
- Amplia gama de aplicacionesAplicación: Aplicable a diversos campos como la cabina inteligente, el hogar inteligente, el asistente de voz, la creación de contenidos de audio y la educación y el aprendizaje.
- Optimización tecnológicaMiDashengLM: Basado en un diseño optimizado de codificador y decodificador de audio, MiDashengLM destaca en la gestión de tareas de audio complejas al tiempo que reduce la carga computacional.
- Estrategias de formaciónEl modelo se basa en una estrategia de formación basada en la alineación de descripciones de audio genéricas y en el análisis multiexperto, lo que garantiza que el modelo aprenda las asociaciones semánticas profundas del audio y mejore la generalización.
Personas a las que va dirigido MiDashengLM
- Investigadores en inteligencia artificialEl modelo ofrece a los investigadores modelos de comprensión de audio y datos de entrenamiento de código abierto para facilitar la investigación y la innovación en campos relacionados.
- Desarrolladores de dispositivos inteligentesPara los equipos que desarrollan productos como cabinas inteligentes, hogares inteligentes, asistentes de voz, etc., el modelo se integra rápidamente en el producto para mejorar la experiencia de interacción.
- Creadores de contenidos de audio: Los creadores de audio utilizan modelos para generar automáticamente descripciones y etiquetas de audio con el fin de mejorar la eficacia de la creación de contenidos.
- Educadores y alumnosen el ámbito del aprendizaje de idiomas y la educación musical, colaborando con comentarios sobre pronunciación y orientación teórica para ayudar a los alumnos a adquirir mejor los conocimientos.
- usuario empresarial: Una solución eficaz para las empresas que necesitan funciones de comprensión de audio compatibles con el uso comercial y que pueden utilizarse para el desarrollo de productos y la optimización de servicios.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...