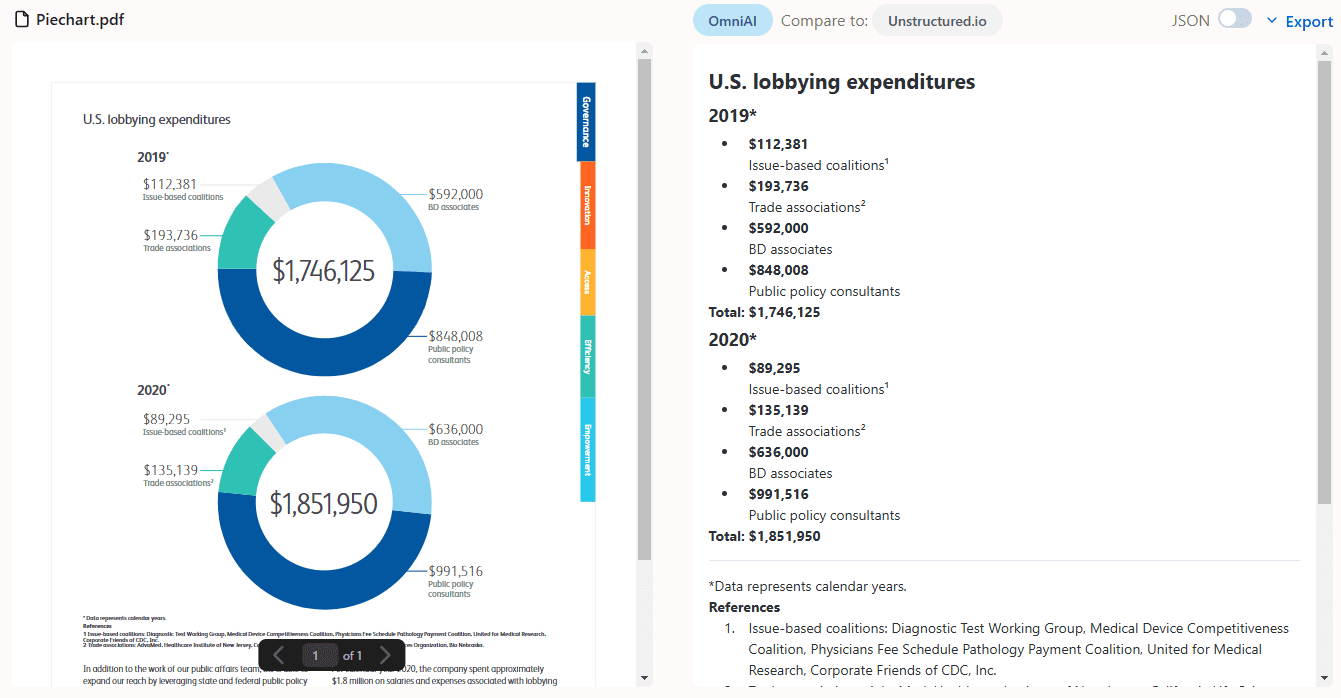
Kiln: herramienta sencilla de ajuste de modelos LLM y síntesis de datos, ¡código base 0 para ajustar sus propios minimodelos!
Últimos recursos sobre IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 69.2K 00

Introducción general
Kiln es una herramienta de código abierto centrada en el ajuste fino de grandes modelos lingüísticos (LLM), la generación de datos sintéticos y la colaboración en conjuntos de datos. Proporciona una aplicación de escritorio intuitiva con soporte para sistemas Windows, MacOS y Linux que permite a los usuarios ajustar modelos como Llama, GPT4o y Mixtral con cero código y automatizar despliegues sin servidor.Kiln también soporta la generación de datos de entrenamiento a través de una herramienta de visualización interactiva y proporciona control de versiones basado en Git para facilitar el trabajo en equipo. Kiln también admite la generación de datos de entrenamiento a través de herramientas de visualización interactivas y proporciona un control de versiones basado en Git para la colaboración en equipo sobre datos estructurados. Su biblioteca Python abierta y su API REST OpenAPI facilitan a los desarrolladores la integración de los conjuntos de datos de Kiln en sus flujos de trabajo.


Lista de funciones
- Aplicaciones de escritorio intuitivas: Compatible con sistemas Windows, MacOS y Linux, se instala con un solo clic y tiene un diseño intuitivo.
- Ajuste del código cero: Admite el ajuste fino de modelos como Llama, GPT4o y Mixtral con despliegue automático sin servidor.
- Generación de datos sintéticos: Genere datos de formación mediante herramientas de visualización interactivas.
- Trabajo en equipoControl de versiones basado en Git para que los miembros del equipo colaboren en los conjuntos de datos.
- Generación de consejosGeneración automática de avisos a partir de los datos, incluidos avisos de encadenamiento, submuestreo y multimuestreo.
- Amplio apoyo a modelos y proveedoresSoporte para Ollama, OpenAI, OpenRouter, Fireworks, Groq, AWS y más.
- Bibliotecas y API de código abierto: Proporciona la biblioteca Python de código abierto del MIT y la API REST OpenAPI.
- la privacidad ante todoLos datos del usuario son completamente privados, con soporte para operación local y claves API autocontenidas.
- Soporte de datos estructuradosCreación de tareas de IA basadas en JSON.
- Uso gratuito: Las aplicaciones de escritorio son gratuitas y las bibliotecas de código abierto son abiertas.
Utilizar la ayuda
Proceso de instalación
- Descargar la solicitudVisita la página de Kiln en GitHub y selecciona la descarga del instalador adecuado para tu sistema operativo.
- Instalación de aplicaciones::
- Windows (ordenador)Ejecute el archivo .exe descargado y siga el asistente de instalación para completar la instalación.
- MacOSDescarga el archivo .dmg, ábrelo y arrastra Kiln a la carpeta Aplicaciones.
- LinuxDescargue el archivo .tar.gz, descomprímalo y ejecute el script de instalación.
Normas de uso
- Iniciar la aplicaciónUna vez finalizada la instalación, abra la aplicación de escritorio Kiln.
- Ajuste del modelo::
- Seleccione el módulo de funciones "Ajuste fino".
- Seleccione el modelo que desea ajustar (por ejemplo, Llama, GPT4o, Mixtral).
- Cargue datos de entrenamiento o cree un conjunto de datos utilizando la herramienta de generación de datos sintéticos de Kiln.
- Configure los parámetros de ajuste fino y haga clic en "Iniciar ajuste fino".
- Una vez completados los ajustes, el modelo se despliega automáticamente sin necesidad de ninguna acción adicional.
- Generar datos sintéticos::
- Seleccione el módulo de funciones "Generación de datos sintéticos".
- Cree y edite datos de formación utilizando herramientas de visualización interactivas.
- Guarde el conjunto de datos generado para su posterior ajuste.
- Trabajo en equipo::
- Seleccione el módulo funcional Colaboración de conjuntos de datos.
- Utilice el control de versiones Git para gestionar conjuntos de datos y facilitar la colaboración entre los miembros del equipo.
- Proporcione ejemplos, consejos, comentarios y otra información sobre el conjunto de datos para facilitar el trabajo conjunto de los miembros del equipo.
- Generación de consejos::
- Seleccione el módulo de funciones Generación de avisos.
- Cargue el conjunto de datos y seleccione el tipo de consulta (por ejemplo, pensamiento en cadena, menos muestras, múltiples muestras).
- Generación automática de pistas para el entrenamiento y la inferencia de modelos.
- Integración en el flujo de trabajo::
- Integre los conjuntos de datos y la funcionalidad de Kiln en sus propios flujos de trabajo utilizando la biblioteca Python de Kiln y la API REST OpenAPI.
- Consulte la documentación y el código de ejemplo de Kiln para empezar a desarrollar rápidamente.
Procedimiento de funcionamiento detallado
- Ajuste del modeloDetalles sobre cómo seleccionar un modelo, cargar datos, configurar parámetros e iniciar el ajuste fino.
- Generación de datos sintéticosDetalles sobre cómo crear y editar datos utilizando herramientas de visualización.
- Trabajo en equipoDescripción detallada de cómo utilizar el control de versiones Git para gestionar conjuntos de datos y cómo proporcionar y procesar comentarios.
- Generación de consejosDetalles sobre cómo seleccionar un tipo de consulta, cargar datos y generar una consulta.
- Integración en el flujo de trabajoDetalla cómo utilizar las bibliotecas y API de Python para la integración, proporcionando ejemplos de código y escenarios de uso.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...