Enrollados Modelos vectoriales de texto largo Estrategias de fragmentación Concurso
Base de conocimientos de IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 42.2K 00

El modelo de vector de texto largo es capaz de codificar diez páginas de texto en un solo vector, lo cual suena potente, pero ¿es realmente práctico?
Mucha gente piensa... No necesariamente.
¿Se puede utilizar directamente? ¿Debe dividirse en trozos? ¿Cuál es la forma más eficaz de fragmentación? En este artículo exploraremos distintas estrategias de fragmentación para modelos vectoriales de texto largo, analizaremos sus pros y sus contras y le ayudaremos a evitar errores.
El problema de la vectorización de textos largos
En primer lugar, veamos qué problemas plantea comprimir un artículo entero en un único vector.
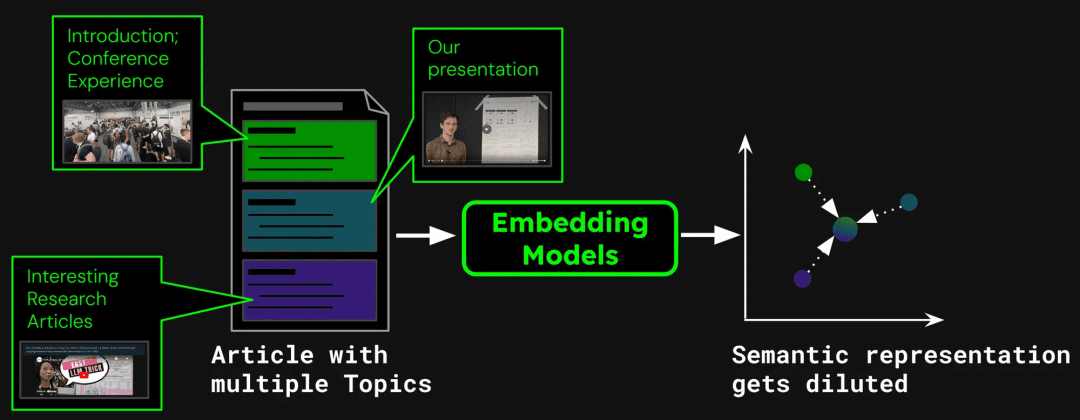
Como ejemplo de creación de un sistema de búsqueda de documentos, un solo artículo puede contener varios temas. Por ejemplo, este blog sobre el informe de asistentes al ICML 2024 contiene una introducción a la conferencia, una presentación del trabajo de Jina AI (jina-clip-v1) y resúmenes de otros artículos de investigación. Si todo el artículo se vectoriza en un único vector, ese vector mezclará información de tres temas diferentes:
Esto puede provocar los siguientes problemas:
1. Dilución de la representación
indica que la dilución debilita la precisión de los vectores de texto. Aunque la entrada del blog contiene varios temas, laSin embargo, las consultas de búsqueda de los usuarios tienden a centrarse sólo en una de ellas. Representar todo el artículo con un único vector equivale a comprimir toda la información temática en un único punto del espacio vectorial. A medida que se añade más texto a la entrada del modelo, este vector representa progresivamente el tema general del artículo, diluyendo los detalles de pasajes o temas concretos. Esto es como mezclar varios pigmentos en un solo color, lo que dificulta al usuario identificar un color concreto de la mezcla cuando intenta encontrarlo.
2. Capacidad limitada
Las dimensiones vectoriales generadas por el modelo son fijas, y los textos largos contienen mucha información, lo que inevitablemente provocará una pérdida de información durante el proceso de transformación. Es como comprimir un mapa de alta definición en un sello de correos, y muchos detalles no son visibles.
3. Pérdida de información
Muchos modelos de texto largo sólo pueden manejar hasta 8192 tokens. Un texto mejor tendrá que truncarse, normalmente al final, y si la información clave está al final del documento, la recuperación puede fallar.
4. Requisitos de segmentación
Algunas aplicaciones sólo necesitan vectorizar segmentos específicos de texto, como los sistemas de preguntas y respuestas, en los que sólo es necesario extraer los párrafos que contienen las respuestas para vectorizarlos. En este caso, sigue siendo necesario fragmentar el texto.
3 Estrategias de tratamiento de textos largos
Antes de empezar el experimento, para evitar confusiones conceptuales, definimos primero tres estrategias de troceado:
1. No Chunking:Codifica todo el texto directamente en un único vector.
2. Chunking ingenuo:El texto se divide primero en varios trozos y se vectoriza por separado. Entre los métodos más utilizados se encuentra el chunking de tamaño fijo, que divide el texto en trozos de tamaño fijo. ficha número de trozos; chunking basado en frases: chunking en frases; chunking basado en la semántica: chunking basado en información semántica. En este experimento se utilizan trozos de tamaño fijo.
3. Chunking tardío:Se trata de un nuevo método de lectura de todo el texto antes de fragmentarlo y consta de dos pasos principales:
- Texto íntegro del códigoCodifica primero todo el documento para obtener una representación vectorial de cada token, conservando toda la información contextual.
- agrupación de trozosGeneración de vectores para cada bloque de texto mediante la agrupación media de los vectores de tokens del mismo bloque de texto según el límite del trozo. Como el vector de cada token se genera en el contexto del texto completo, la partición tardía puede preservar la información contextual entre bloques.
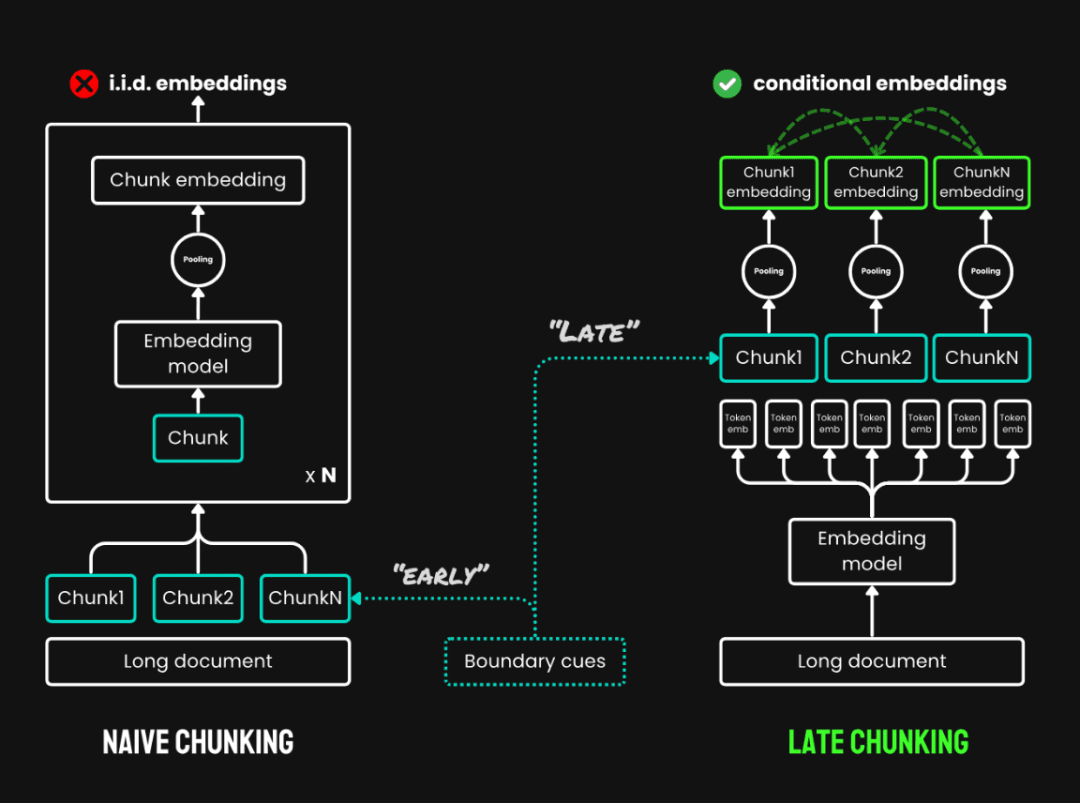
División tardía frente a fragmentación simple
Para los modelos que superan la longitud máxima de entrada (por ejemplo, 8192 fichas), utilizamos el Chunking tardíoEn el caso de la segmentación tardía, se añade una etapa de presegmentación dividiendo primero el documento en varios macrobloques superpuestos, cada uno de los cuales tiene una longitud comprendida dentro del intervalo procesable del modelo. A continuación, se aplica una estrategia estándar de segmentación tardía (codificación y agrupación) dentro de cada macrobloque. El solapamiento entre macrobloques se utiliza para garantizar la continuidad de la información contextual.
Puntuación tardía Código de aplicación específico: https://github.com/jina-ai/late-chunking在 Experiencia con el cuaderno: https://colab.research.google.com/drive/1iz3ACFs5aLV2O_ uZEjiR1aHGlXqj0HY7?usp=compartir
Entonces, ¿cuál es el mejor método?
A efectos comparativos, hemos utilizado el conjunto de datos sobre 5 jina-embeddings-v3 Se realizaron experimentos en los que todos los textos largos se truncaron hasta la longitud máxima de entrada del modelo (8192 tokens) y se segmentaron en bloques de texto cada 64 tokens.

Los 5 conjuntos de datos de prueba corresponden también a 5 tareas de recuperación diferentes
La siguiente figura muestra la diferencia de rendimiento entre los 3 métodos en diferentes tareas, ningún método es el mejor en todos los casos y la elección depende de la tarea específica.
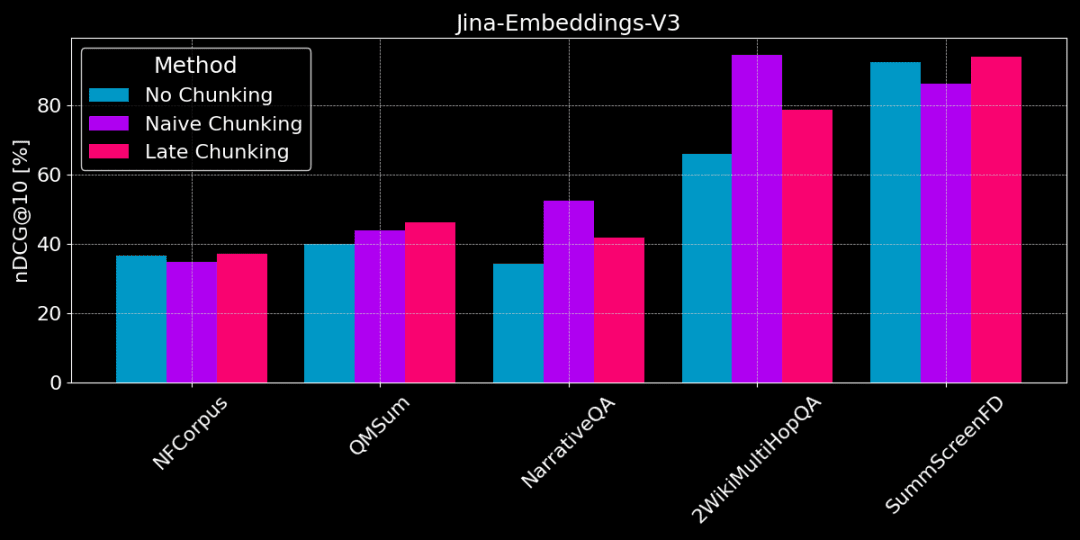
No chunking vs plain chunking vs late chunking
👩🏫 Busca hechos concretos, la fragmentación simple es buena.
Si es necesario extraer del texto información factual específica y localizada (por ejemplo, "¿Quién robó algo?) ), en conjuntos de datos como QMSum, NarrativeQA y 2WikiMultiHopQA, la fragmentación simple funciona mejor que la vectorización de todo el documento. Dado que las respuestas suelen encontrarse en una parte específica del texto, el troceado simple puede localizar con mayor precisión el fragmento de texto que contiene la respuesta sin distraerse con otra información extraña.
Pero el troceado simple también corta el contexto y puede perder información global para analizar correctamente las relaciones referenciales y las referencias en el texto.
👩🏫 El artículo es coherente desde el punto de vista temático, y las puntuaciones tardías son mejores.
La división tardía es más eficaz cuando el tema está claro y la estructura del texto es coherente. Como la división tardía tiene en cuenta el contexto, permite comprender mejor el significado y la relevancia de cada parte, incluidas las relaciones referenciales dentro de textos largos.
Sin embargo, si hay mucho contenido irrelevante en el artículo, la puntuación tardía tendrá en cuenta el "ruido" y provocará una regresión del rendimiento y una degradación de la precisión. Por ejemplo, NarrativeQA y 2WikiMultiHopQA no funcionan tan bien como el chunking simple porque en estos artículos hay demasiada información irrelevante.
¿Tiene algún efecto el tamaño de los trozos?
La siguiente figura muestra el rendimiento de los métodos plain chunking y late chunking en diferentes conjuntos de datos con distintos tamaños de trozo:
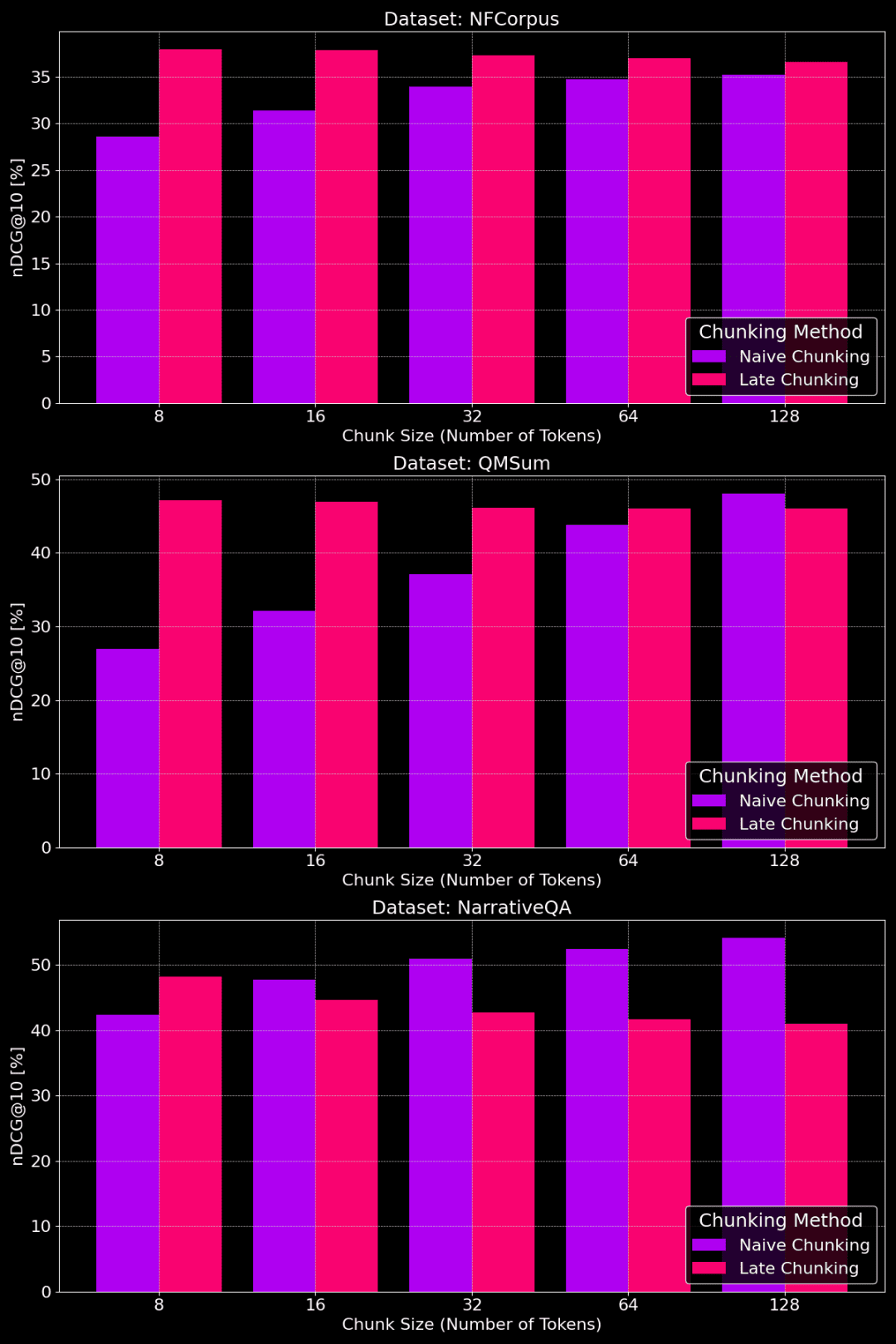
Comparación del rendimiento del chunking simple y el chunking tardío para distintos tamaños de trozo
Como podemos ver en la figura, el tamaño óptimo de los trozos depende en realidad de cómo sea el conjunto de datos específico.
Para el método de división tardía, los trozos más pequeños captan mejor la información contextual y, por tanto, funcionan mejor. En particular, si hay mucho contenido en el conjunto de datos que no está relacionado con el tema (como en el caso del conjunto de datos NarrativeQA), demasiado contexto puede introducir ruido y perjudicar el rendimiento.
En el caso del chunking simple, los trozos más grandes a veces funcionan mejor porque la información contenida es más completa y tiene menos pérdidas. Sin embargo, a veces los trozos son demasiado grandes y la información está demasiado desordenada, lo que a su vez reduce la precisión de la recuperación. Así pues, el tamaño óptimo de los trozos debe ajustarse al conjunto de datos y a la tarea específicos, y no existe una respuesta única.
Una vez conocidas las ventajas e inconvenientes de las distintas estrategias de fragmentación, ¿cómo elegir la más adecuada?
1. ¿En qué casos es adecuada la vectorización de texto completo (sin chunking)?
- El tema es singular, con la información clave centrada al principio:Por ejemplo, en las noticias estructuradas, la información clave suele estar en los titulares y los párrafos iniciales. En este caso, el uso directo de la vectorización de texto completo suele dar buenos resultados porque el modelo capta la información clave.
- En general, introducir en el modelo la mayor cantidad posible de contenido textual no afectará a los resultados de recuperación. Sin embargo, los modelos de texto largo tienden a prestar más atención a la parte inicial (título, introducción, etc.), y la información de las partes intermedia y final puede ser ignorada. Por lo tanto, si la información clave se encuentra en el medio o al final del artículo, este método será mucho menos eficaz.
- Los resultados experimentales detallados figuran en:https://jina.ai/news/still-need-chunking-when-long-context-models-can-do-it-all
2. ¿Dónde es apropiado el Naive Chunking?
- Variedad de temas, necesidad de recuperar información específicaSi el texto contiene más de un tema, o si la consulta del usuario se centra en un hecho concreto del texto, la fragmentación simple es una buena opción. Puede evitar eficazmente la dilución de la información y mejorar la precisión de la recuperación de información específica.
- Necesidad de mostrar fragmentos de texto localizadosLa necesidad de mostrar en los resultados fragmentos de texto relacionados con la consulta requiere una estrategia de fragmentación (chunking) similar a la de un motor de búsqueda.
- Además, la fragmentación afecta al espacio de almacenamiento y al tiempo de procesamiento al tener que vectorizar más bloques de texto.
3. ¿Qué papel desempeña la fragmentación tardía?
- Coherencia temática, necesidad de información contextualPara textos largos con temas coherentes, como ensayos, informes largos, etc., el método de partición tardía puede retener eficazmente la información contextual y, por tanto, comprender mejor la semántica global del texto. Es especialmente adecuado para tareas que requieren comprender la relación entre distintas partes de un texto, como la comprensión lectora y la correspondencia semántica de textos largos.
- Necesidad de equilibrar los detalles locales con la semántica globalEl método de partición tardía puede equilibrar eficazmente los detalles locales y la semántica global en trozos de menor tamaño, y en muchos casos puede lograr mejores resultados que los otros dos métodos. Sin embargo, debe tenerse en cuenta que si hay muchos contenidos irrelevantes en el artículo, la partición tardía afectará al efecto debido a la consideración de dicha información irrelevante.
llegar a un veredicto
La selección de una estrategia de vectorización de textos largos es una cuestión compleja, sin una solución única que sirva para todo, y requiere tener en cuenta las características de los datos y los objetivos de recuperación, incluida la longitud del texto antes mencionada, el número de temas y la ubicación de la información clave.
En este artículo, esperamos proporcionar un marco de análisis comparativo sobre diferentes estrategias de chunking y proporcionar algunas referencias a través de resultados experimentales. En la aplicación práctica, puede comparar más experimentos y elegir la estrategia más adecuada para su escenario.
Si está interesado en la vectorización de textos largosjina-embeddings-v3Merece la pena probarlo, ya que ofrece funciones avanzadas de procesamiento de textos largos, compatibilidad con varios idiomas y puntuación tardía.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...