
Análisis en profundidad y comparación de nueve marcos de seguridad de los grandes modelos dominantes
Base de conocimientos de IAPublicado hace 11 meses Círculo de intercambio de inteligencia artificial 67K 00

Con el rápido desarrollo y la amplia aplicación de las tecnologías de modelización lingüística a gran escala, sus riesgos potenciales para la seguridad se están convirtiendo cada vez más en el centro de atención de la industria. Para hacer frente a estos retos, muchas empresas tecnológicas de primera línea, organizaciones de normalización e institutos de investigación de todo el mundo han construido y publicado sus propios marcos de seguridad. En este documento, clasificaremos y analizaremos nueve grandes marcos de seguridad de modelos representativos, con el objetivo de ofrecer una referencia clara a los profesionales de campos afines.

Figura: Visión general del marco de seguridad de Big Model
Secure AI Framework (SAIF) de Google (versión 2025.04)
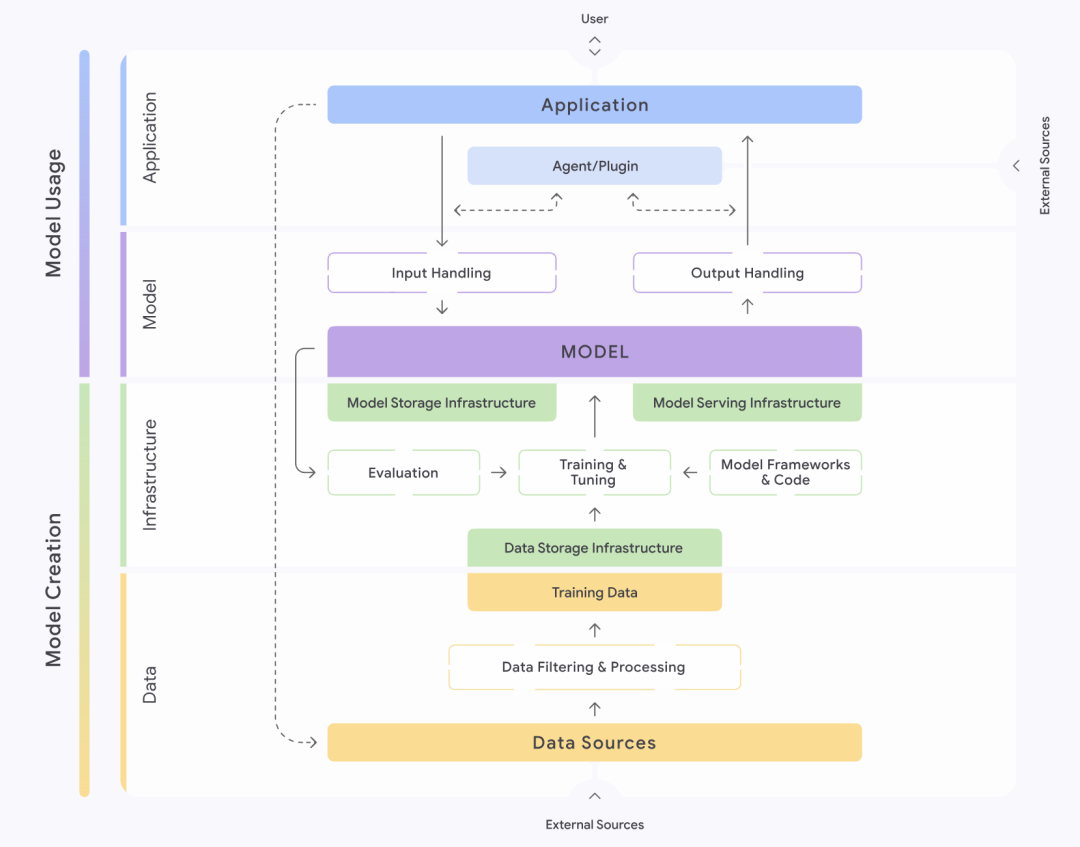
Figura: Estructura del marco SAIF de Google
El Secure AI Framework, o SAIF, introducido por Google (Google) proporciona un enfoque estructurado para comprender y gestionar la seguridad de los sistemas de IA. El marco divide meticulosamente los sistemas de IA en cuatro capas: datos, infraestructura, modelo y aplicación. Cada capa se divide a su vez en diferentes componentes, como la capa de datos, que contiene partes clave como las fuentes de datos, el filtrado y procesamiento de datos, y los datos de entrenamiento, etc. SAIF hace hincapié en que cada una de estas partes alberga riesgos y peligros específicos.
Basándose en el ciclo de vida completo de un sistema de IA, SAIF identificó y clasificó quince riesgos principales, entre ellos el envenenamiento de datos, el acceso no autorizado a los datos de entrenamiento, la manipulación del origen del modelo, el procesamiento excesivo de datos, la fuga de modelos, la manipulación del despliegue de modelos, la denegación de servicio de modelos, la ingeniería inversa de modelos, los componentes inseguros, la inyección de palabras clave, la codificación de modelos, la fuga de datos sensibles, el acceso a datos sensibles mediante extrapolación, la salida de modelos inseguros y el comportamiento malicioso. y comportamiento malicioso. En respuesta a estos quince riesgos, SAIF también propone quince medidas preventivas y de control en consecuencia, que constituyen su orientación básica en materia de seguridad.
Las 10 principales amenazas para la seguridad de las aplicaciones de grandes modelos, según OWASP (publicado en 2025.03)

Figura : Las 10 principales amenazas para la seguridad de las aplicaciones OWASP Big Model
El Open World Application Security Project (OWASP), una de las principales fuerzas en materia de ciberseguridad, también ha publicado su lista de las 10 principales amenazas para la seguridad de las aplicaciones de big models. OWASP divide las aplicaciones de big models en varios "dominios de confianza" clave, como el propio servicio de big models, la funcionalidad de terceros plug-ins, bases de datos privadas y datos de entrenamiento externos. La organización identifica una serie de amenazas a la seguridad, tanto en las interacciones entre estos dominios de confianza como dentro de los mismos.
Las 10 amenazas de seguridad más importantes de OWASP son, por orden de impacto: Inyección de avisos, Revelación de información sensible, Riesgos en la cadena de suministro, Envenenamiento de datos y modelos, Procesamiento inadecuado de la salida, Autorización excesiva, Fuga de avisos del sistema, Vulnerabilidades de vectores e incrustación, Información engañosa y Consumo ilimitado de recursos. Para cada una de estas amenazas, OWASP ofrece recomendaciones de prevención y control, proporcionando una guía práctica para desarrolladores y personal de seguridad.
Marco de seguridad de modelos de OpenAI (en continua actualización)
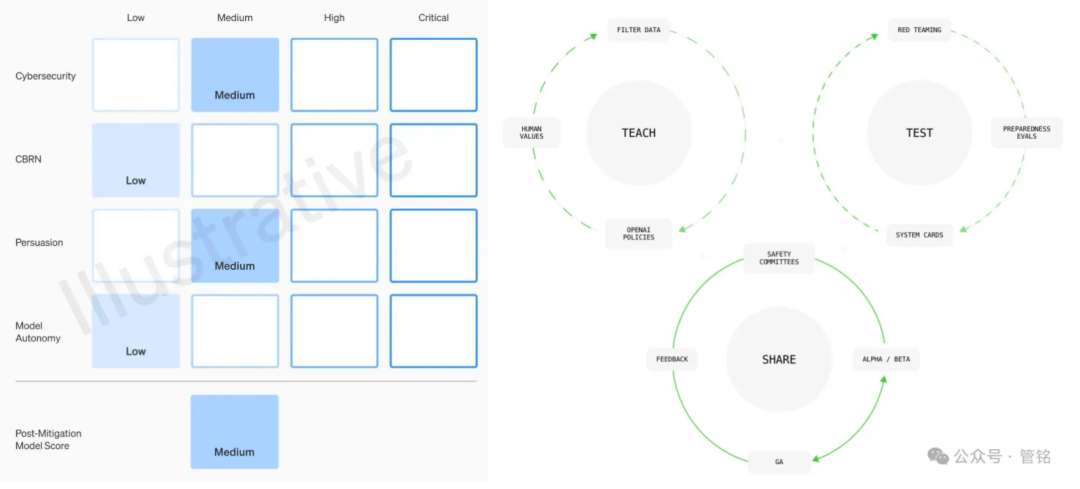
Figura : Dimensiones del marco de seguridad del modelo OpenAI
Como líder en tecnología Big Model, OpenAI concede una gran prioridad a la seguridad de sus modelos. Su marco de seguridad de los modelos se basa en cuatro dimensiones: riesgo de armas de destrucción masiva (QBRN), capacidad de ciberataque, poder de persuasión (capacidad de los modelos para influir en las opiniones y comportamientos humanos) y autonomía de los modelos, que se clasifican como baja, media, alta o grave según el nivel de daño potencial. Antes de cada lanzamiento de un modelo, debe presentarse una evaluación de seguridad detallada, conocida como Tarjeta del Sistema, basada en este marco.
Además, OpenAI propone un marco de gobernanza que incluye la alineación de valores, la evaluación adversarial y la iteración de control. En la fase de alineación de valores, OpenAI se compromete a formular un conjunto de comportamientos del modelo que sean coherentes con los valores humanos universales, y a guiar el trabajo de limpieza de datos en todas las fases del entrenamiento del modelo. En la fase de evaluación adversarial, OpenAI construirá casos de prueba profesionales para probar completamente el modelo antes y después de tomar medidas de protección, y finalmente producirá tarjetas del sistema. En la fase de iteración de control, OpenAI adoptará una estrategia de lanzamiento por lotes para los modelos que ya se hayan desplegado, y seguirá añadiendo y optimizando medidas de protección.
Marco de gobernanza de la seguridad de la IA para el Comité de Normas de Ciberseguridad (publicado en 2024.09)
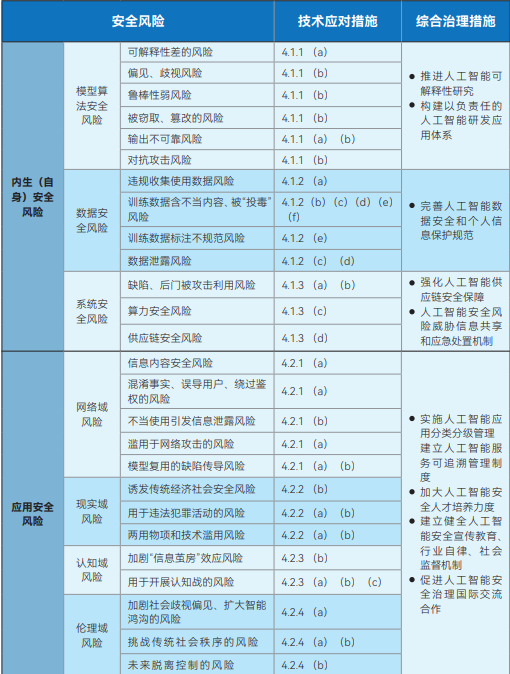
Figura : Marco de gobernanza de la seguridad de la IA del Comité de Normas de Seguridad de la Red
El Marco de Gobernanza de la Seguridad de la Inteligencia Artificial publicado por el Comité Técnico Nacional de Normalización de la Ciberseguridad (NCSSTC) tiene por objeto ofrecer macroorientaciones para el desarrollo seguro de la IA. El marco divide los riesgos de seguridad de la IA en dos categorías principales: riesgos de seguridad endógenos (propios) y riesgos de seguridad de la aplicación. Los riesgos de seguridad endógenos se refieren a los riesgos inherentes al propio modelo, que incluyen principalmente los riesgos de seguridad del algoritmo del modelo, los riesgos de seguridad de los datos y los riesgos de seguridad del sistema. Los riesgos de seguridad de aplicación, por su parte, se refieren a los riesgos a los que puede enfrentarse el modelo en el proceso de aplicación, y se subdividen a su vez en cuatro aspectos: dominio de red, dominio de realidad, dominio cognitivo y dominio ético.
En respuesta a estos riesgos identificados, el marco señala claramente que los desarrolladores de modelos y algoritmos, los proveedores de servicios, los usuarios de sistemas y otras partes pertinentes deben adoptar activamente medidas técnicas para prevenirlos desde diversos aspectos, como los datos de entrenamiento, las instalaciones aritméticas, los modelos y algoritmos, los productos y servicios, así como los escenarios de aplicación. Al mismo tiempo, el marco aboga por el establecimiento y la mejora de un sistema integral de gobernanza de los riesgos de seguridad de la IA que implique a las instituciones de investigación y desarrollo tecnológico, los proveedores de servicios, los usuarios, los departamentos gubernamentales, las asociaciones industriales y las organizaciones sociales.
Sistema de normas de seguridad para la inteligencia artificial del Comité de normas de ciberseguridad V1.0 (publicado en 2025.01)
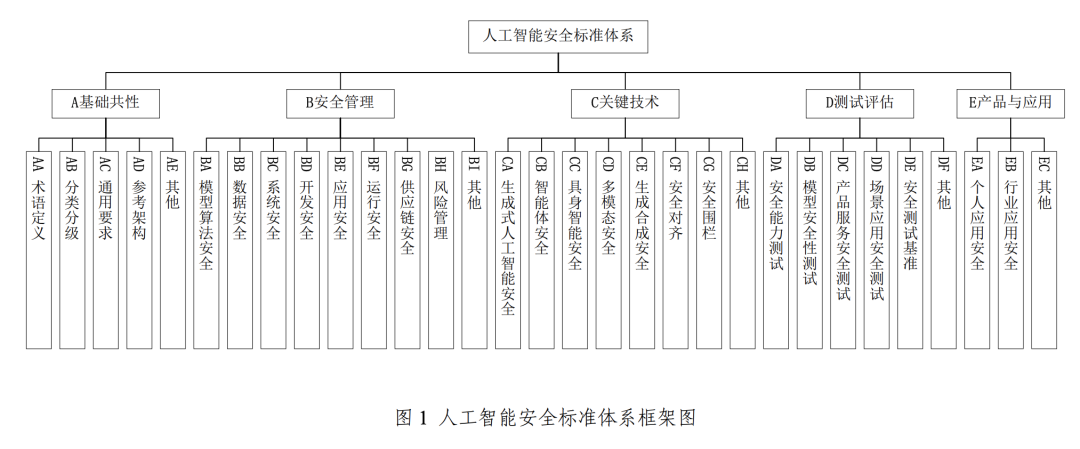
Figura: Sistema de normas de seguridad de la inteligencia artificial del Comité de normas de seguridad de la red V1.0
Para apoyar y aplicar el Marco de Gobernanza de la Seguridad de la Inteligencia Artificial antes mencionado, la CNSC lanzó además el Sistema de Normas de Seguridad de la Inteligencia Artificial V1.0, que clasifica sistemáticamente las normas clave que pueden ayudar a prevenir y resolver los riesgos de seguridad de la IA pertinentes, y se centra en la interfaz efectiva con el sistema nacional de normas existente para la ciberseguridad.
Este sistema de normas se compone principalmente de cinco partes fundamentales: elementos comunes básicos, gestión de la seguridad, tecnología clave, ensayo y evaluación, y productos y aplicaciones. Entre ellas, la parte de gestión de la seguridad clave abarca la seguridad del algoritmo del modelo, la seguridad de los datos, la seguridad del sistema, la seguridad del desarrollo, la seguridad de la aplicación, la seguridad de la operación y la seguridad de la cadena de suministro. El apartado de tecnologías clave, por su parte, se centra en ámbitos punteros como la seguridad de la IA generativa, la seguridad del cuerpo inteligente, la seguridad de la inteligencia incorporada (referida a la IA con entidades físicas, como los robots, cuya seguridad implica interacciones con el mundo físico), la seguridad multimodal, la seguridad de la síntesis generativa, la alineación de la seguridad y el cercado de seguridad.
Big Model Security Practices 2024 por la Universidad de Tsinghua, Zhongguancun Lab y Ant Group (publicado en 2024.11)
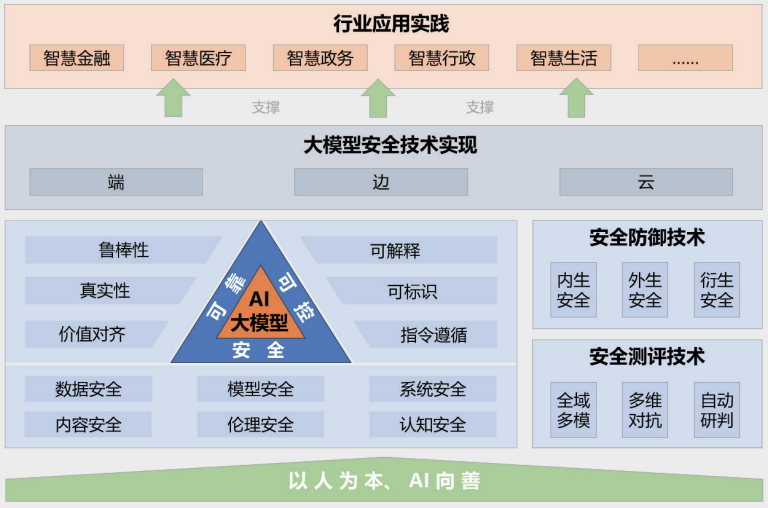
Figura : Marco Big Model Prácticas de seguridad 2024
El informe "Big Model Security Practice 2024", publicado conjuntamente por la Universidad Tsinghua, Zhongguancun Lab y Ant Group, ofrece una visión de la seguridad de los grandes modelos desde la perspectiva de la combinación de la industria, el mundo académico y la investigación. El marco de seguridad de grandes modelos propuesto en el informe contiene cinco partes principales: el principio rector de "orientado a las personas, IA para el bien"; un sistema tecnológico de seguridad de grandes modelos seguro, fiable y controlable; tecnologías de medición y defensa de la seguridad; implementaciones tecnológicas de seguridad colaborativa de extremo a extremo, de borde a borde y en la nube; y casos prácticos de aplicación en múltiples industrias.
El informe señala en detalle los numerosos riesgos y desafíos a los que se enfrentan actualmente los grandes modelos, como la fuga de datos, el robo de datos, el envenenamiento de datos, los ataques de adversarios, los ataques de comandos (que inducen comportamientos no deseados en los modelos a través de comandos bien diseñados), los ataques de robo de modelos, las vulnerabilidades de seguridad del hardware, las vulnerabilidades de seguridad del software, los problemas de seguridad en el propio marco, los riesgos de seguridad introducidos por herramientas externas, la generación de contenidos tóxicos, la difusión de contenidos sesgados, la generación de información falsa, los riesgos ideológicos, el fraude en las telecomunicaciones y el robo de identidad, la infracción de la propiedad intelectual y los derechos de autor, la crisis de integridad en la industria de la educación y los problemas de imparcialidad inducidos por sesgos. información falsa, riesgos ideológicos, fraude en las telecomunicaciones y usurpación de identidad, violación de la propiedad intelectual y los derechos de autor, crisis de integridad en la industria de la educación y problemas de imparcialidad inducidos por los prejuicios. El informe también propone las correspondientes técnicas de defensa para hacer frente a estos complejos riesgos.
Informe de Aliyun e ICTA sobre la seguridad de los grandes modelos (publicado en 2024.09)
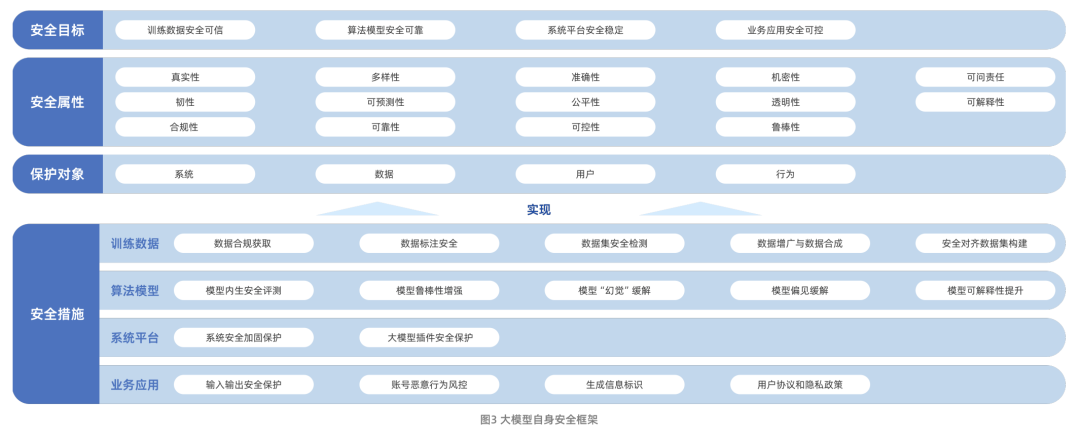
Figura: Marco del informe de investigación sobre seguridad de grandes modelos de Aliyun e ICTA
El informe Big Model Security Research Report, publicado conjuntamente por Aliyun y la Academia China de Tecnología de la Información y las Comunicaciones (CAICT), describe sistemáticamente la trayectoria de evolución de la tecnología de grandes modelos y los retos de seguridad a los que se enfrenta actualmente. Estos retos incluyen principalmente riesgos para la seguridad de los datos, riesgos para la seguridad de los modelos algorítmicos, riesgos para la seguridad de las plataformas de sistemas y riesgos para la seguridad de las aplicaciones empresariales. Cabe destacar que el informe amplía aún más el ámbito de investigación de la seguridad de los grandes modelos, desde la seguridad del propio modelo hasta la forma de utilizar la tecnología de grandes modelos para potenciar y mejorar las capacidades tradicionales de protección de la seguridad de las redes.
En cuanto a la propia seguridad del modelo, el informe construye un marco que contiene cuatro dimensiones: objetivos de seguridad, atributos de seguridad, objetos de protección y medidas de seguridad. Entre ellas, las medidas de seguridad se centran en los cuatro aspectos fundamentales de los datos de formación, los algoritmos del modelo, las plataformas del sistema y las aplicaciones empresariales, lo que refleja una idea de protección integral.
Estudio sobre seguridad y ética del Big Model 2024 del Instituto de Investigación Tencent (publicado en 2024.01)
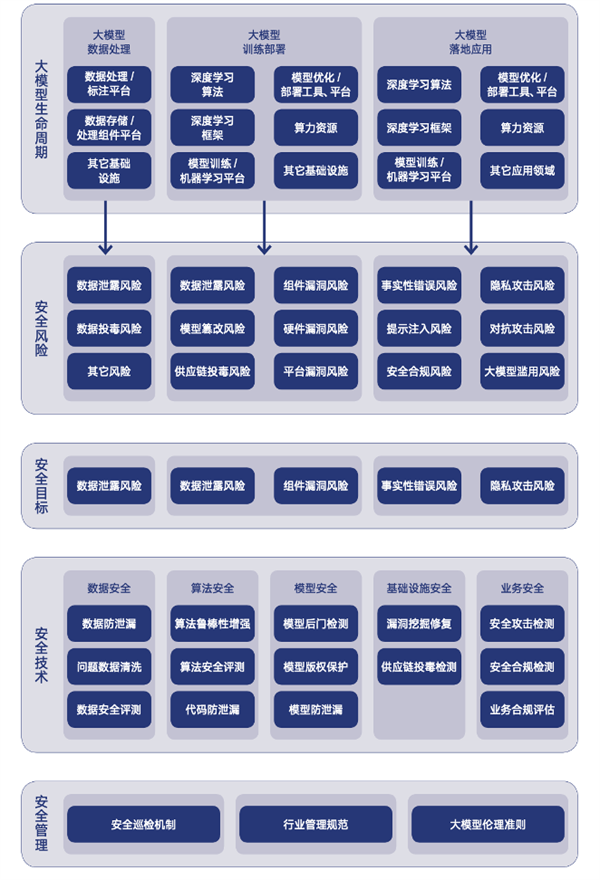
Figura: Preocupación por la seguridad y la ética en la investigación del Big Model del Instituto de Investigación Tencent
El informe "Big Model Security and Ethics Research 2024", publicado por el Instituto de Investigación Tencent, ofrece un análisis en profundidad de las tendencias de la tecnología de grandes modelos y de las oportunidades y retos que estas tendencias presentan para el sector de la seguridad. El informe enumera quince riesgos principales, entre ellos la fuga de datos, el envenenamiento de datos, la manipulación de modelos, el envenenamiento de la cadena de suministro, las vulnerabilidades del hardware, las vulnerabilidades de los componentes y las vulnerabilidades de la plataforma. Por otra parte, el informe comparte cuatro buenas prácticas de seguridad de grandes modelos: evaluación inmediata de la seguridad, ejercicio de ataque y defensa del ejército azul de grandes modelos, práctica de protección de la seguridad del código fuente de grandes modelos y esquema de protección de la seguridad de la vulnerabilidad de la infraestructura de grandes modelos.
El informe también destaca los avances y las tendencias futuras en la alineación de los valores de los grandes modelos. El informe señala que la forma de garantizar que las capacidades y comportamientos de los grandes modelos estén en consonancia con los valores humanos, las verdaderas intenciones y los principios éticos, a fin de salvaguardar la seguridad y la confianza en el proceso de colaboración entre los seres humanos y la IA, se ha convertido en un tema central de la gobernanza de los grandes modelos.
Solución de seguridad Big Model de 360 (continuamente actualizada)
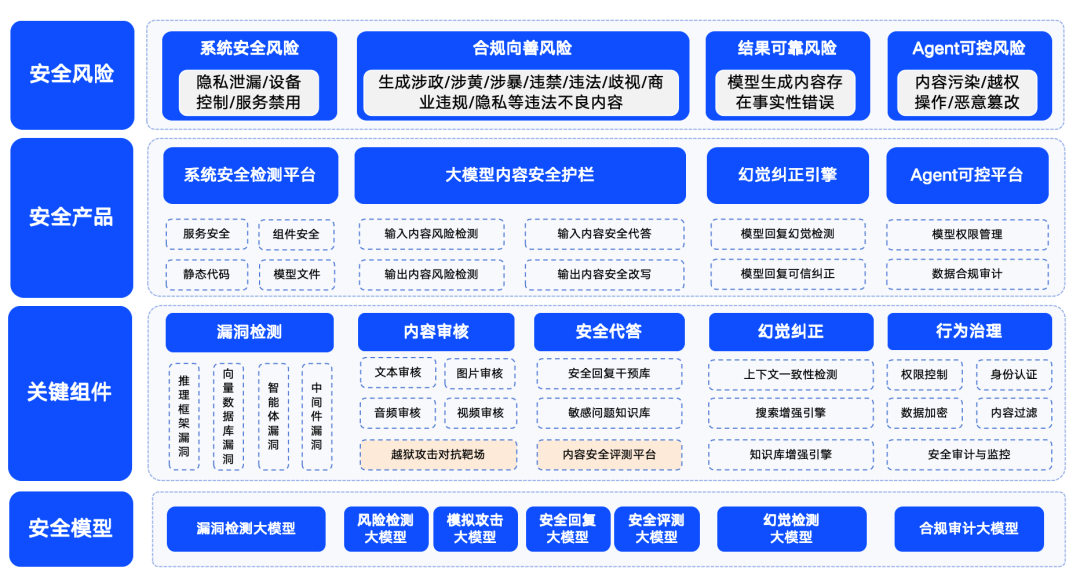
Figura: Esquema de la solución de seguridad 360 Big Model
Qihoo 360 también ha establecido activamente el campo de la seguridad de los grandes modelos, y ha presentado sus soluciones de seguridad.360 resume los riesgos de seguridad de los grandes modelos en cuatro categorías: riesgos de seguridad del sistema, riesgos de seguridad del contenido, riesgos de seguridad de confianza y riesgos de seguridad controlables. Entre ellos, la seguridad del sistema se refiere principalmente a la seguridad de varios tipos de software en el ecosistema de los grandes modelos; la seguridad del contenido se centra en el riesgo de cumplimiento del contenido de entrada y salida; la seguridad de confianza se centra en resolver el problema de la "ilusión" del modelo (es decir, el modelo genera información que parece razonable, pero no es real); y la seguridad controlable aborda el problema más complejo de la seguridad del proceso del agente. La seguridad controlable aborda el problema más complejo de la seguridad de los procesos del Agente.
Con el fin de garantizar que los modelos de gran tamaño puedan ser seguros, buenos, creíbles y controlables para su aplicación en diversas industrias, 360 ha creado una serie de productos de seguridad para modelos de gran tamaño basados en su propia acumulación de capacidades en el campo de los modelos de gran tamaño. Estos productos incluyen el "360 Smart Forensics", destinado principalmente a detectar vulnerabilidades en el ecosistema LLM, el "360 Smart Shield", centrado en la seguridad del contenido de los grandes modelos, y el "360 Smart Search", que garantiza una seguridad creíble. 360SmartSearch". Mediante la combinación de estos productos, 360 ha formado un conjunto de soluciones de seguridad relativamente maduras para grandes modelos en una fase temprana.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...