Requiere sólo 14 GB de RAM para ejecutar DeepSeek-Coder V3/R1 (Q4_K_M quantised) localmente.

resúmenes
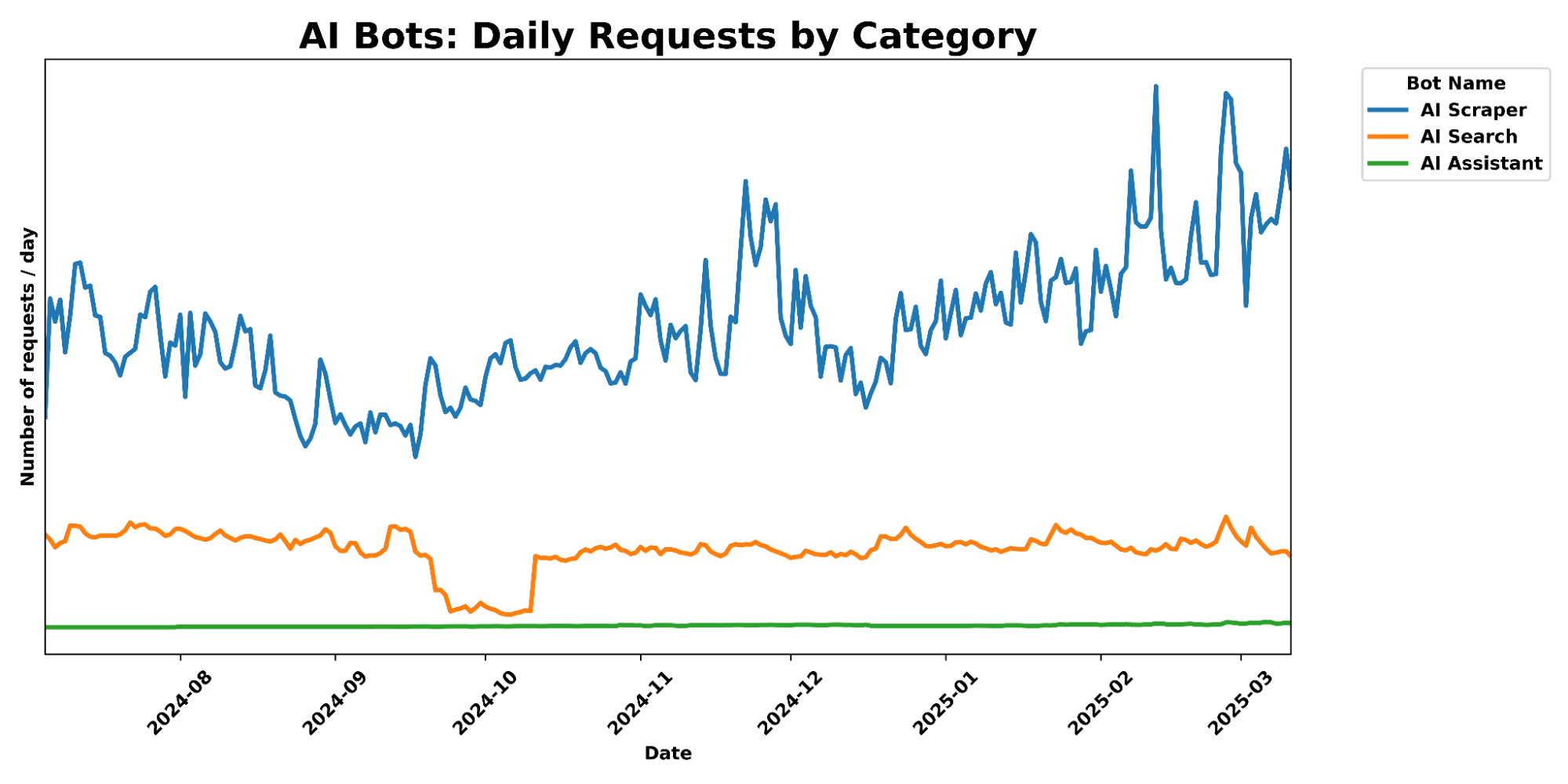
10 de febrero de 2025Compatibilidad con DeepseekR1 y V3 en una GPU (24 GB de RAM) / varias GPU y 382 GB de RAM, con aumentos de velocidad de hasta 3-28 veces.
Saludos a todos, de parte del equipo KTransformers (antes conocido como el equipo del Proyecto de Código Abierto de Inferencia Híbrida CPU/GPU, conocido por DeepSeek-V2).
KTransformers El equipo ha recibido peticiones de compatibilidad con DeepSeek-R1/V3 y se complace en anunciar que por fin está disponible.
Siento la espera, pero el equipo de KTransformers ha estado preparando algo realmente increíble.
Hoy, el equipo de KTransformers se enorgullece de anunciar no sólo la compatibilidad con DeepSeek-R1/V3, como se muestra en el siguiente vídeo:
https://github.com/user-attachments/assets/ebd70bfa-b2c1-4abb-ae3b-296ed38aa285
- [Actualizado!!!!] Local 671B DeepSeek-Coder-V3/R1. Ejecuta su versión Q4_K_M sólo con 14 GB de memoria de vídeo y 382 GB de RAM.
- Velocidad de prellenado (fichas/s).
- KTransfermor: 54,21 (32 núcleos) → 74,362 (doble ruta, 2×32 núcleos) → 255,26 (núcleo MoE optimizado basado en AMX, solo V0.3) → 286,55 (uso selectivo de 6 expertos, solo V0.3)
- junto con llama.cpp alcanzó hasta 10,31 tokens/s en 2×32 núcleos en comparación con el 27,79 veces la aceleración.
- Velocidad de descodificación (fichas/s).
- KTransfermor: 8,73 (32 núcleos) → 11,26 (dual, 2×32 núcleos) → 13,69 (uso selectivo de 6 expertos, solo V0.3)
- En comparación con los 4,51 tokens/s de llama.cpp en 2×32 núcleos, se consigue hasta Aceleración de 3,03x.
- Velocidad de prellenado (fichas/s).
El equipo de KTransformers también presentó un avance de las próximas optimizaciones, incluido un núcleo acelerado por Intel AMX y métodos selectivos de activación de expertos, que mejorarán significativamente el rendimiento. Con la versión V0.3preview, el rellenado previo alcanza los 286 tokens/s, ¡más rápido que llama.cpp para la inferencia nativa! 28 veces.
La distribución binaria ya está disponible y el código fuente se publicará lo antes posible.Ver paquetes de ruedas aquí.
Condiciones de preparación
El equipo de KTransformers realizó las mejores pruebas de rendimiento (V0.2) con las siguientes configuraciones:
CPU: Intel (R) Xeon (R) Gold 6454S 1T RAM (2 nodos NUMA)
GPU: 4090D 24G Memoria de vídeo
Memoria: Memoria de servidor estándar DDR5-4800 (1 TB)
Resultados de la evaluación comparativa
V0.2
establecer
- Modelo: DeepseekV3-q4km (int4)
- CPU: cpu_model_name: Intel (R) Xeon (R) Gold 6454S, 32 núcleos por ruta, 2 rutas, 2 nodos numa
- GPU: 4090D 24G Memoria de vídeo
- Pruebas del equipo KTransformers tras el calentamiento completo
Consumo de memoria.
- Individual: 382 G de RAM, al menos 14 GB de VRAM
- Dual: 1T RAM, al menos 14GB VRAM
Resultados de la evaluación comparativa
El escenario "6 expertos" forma parte del avance de la V0.3.
| Prompt
| (500 fichas) | Doble Ktrans (6 expertos) | Doble Ktrans (8 expertos) | Ktrans simple (6 expertos) | Ktrans individual (8 expertos) | llama.cpp (8 expertos) |
|---|---|---|---|---|---|
| Ficha/s de precarga | 97.32 | 82.94 | 65.14 | 54.21 | 10.31 |
| Descodificar ficha/s | 13.69 | 12.208 | 10.303 | 8.73 | 4.51 |
Aumenta la velocidad de descodificación hasta 3,03 vecesAumento máximo de la velocidad de prellenado 9,44 veces. Parece que KTransformers no es tan bueno como el prepopulado en términos de aceleración de la descodificación, y aún queda mucho margen para la optimización de la descodificación.
V0.3-Previsualización
establecer
- Modelo: DeepseekV3-BF16 (cuantificado en línea como int8 para CPU, int4 para GPU)
- CPU: cpu_model_name: Intel (R) Xeon (R) Gold 6454S, 32 núcleos por ruta, 2 rutas, 2 nodos numa
- GPU: (1~4)x 4090D 24GVRAM (las indicaciones más largas requieren más memoria)
Consumo de memoria.
- 644 GB de RAM, al menos 14 GB de memoria gráfica
Resultados de la evaluación comparativa
| Longitud de la pregunta | 1K | 2K | 4K | 8K |
|---|---|---|---|---|
| KTrans (8 expertos) Ficha/s de prellenado | 185.96 | 255.26 | 252.58 | 195.62 |
| KTrans (6 expertos) Ficha/s de precarga | 203.70 | 286.55 | 271.08 | 207.20 |
KTrans V0.3 es más rápido que KTrans V0.2 en el prellenado. 3,45 vecesEs más rápido que llama.cpp. 27,79 veces. Este aumento de la velocidad de precarga es realmente impresionante y parece que KTransformers ha puesto mucho esfuerzo en la optimización de la precarga.
La velocidad de descodificación es la misma que la de KTrans V0.2 (versión para 6 expertos), por lo que se omite. Parece que la versión V0.3 se centra principalmente en mejoras de la velocidad de prellenado.
La principal aceleración procede de
- Conjunto de instrucciones Intel AMX y diseño de memoria compatible con caché diseñado por el equipo de KTransformers.
- Estrategia de selección de expertos para seleccionar menos expertos basándose en los resultados de perfiles fuera de línea a partir de datos fuera del dominio
Según el equipo de KTransformers para DeepSeekV2, DeepSeekV3 y DeepSeekR1, el
Al reducir ligeramente el número de expertos activados en la inferencia, el
La calidad de salida no cambia. Pero la velocidad de descodificación y prellenado
se acelerará, lo cual es alentador. Así que la demo del equipo de KTransformers aprovecha este hallazgo Parece que la "estrategia de selección de expertos" es la clave para acelerar, pero cómo garantizar que la calidad del resultado no se deteriore requiere más pruebas y comprobaciones.
Cómo funciona
Demo V0.2
Versión de ruta única (32 núcleos)
El equipo de KTransformers local_chat El comando de prueba es:
git clone https://github.com/kvcache-ai/ktransformers.git
cd ktransformers
numactl -N 1 -m 1 python ./ktransformers/local_chat.py --model_path <your model path> --gguf_path <your gguf path> --prompt_file <your prompt txt file> --cpu_infer 33 --cache_lens 1536
<当看到 chat 时,按 Enter 键加载文本 prompt_file>
puede ser una ruta local o un conjunto de rutas de una cara de abrazo en línea, por ejemplo, deepseek-ai/DeepSeek-V3. Si encuentra problemas de conexión en línea, intente utilizar un espejo (hf-mirror.com).
también puede ser una ruta en línea, pero como es grande, el equipo de KTransformers recomienda que la descargue y cuantifique el modelo en el formato que desee.
comando numactl -N 1 -m 1 Diseñado para evitar transferencias de datos entre nodos NUMA
Versión Dual-Path (64 núcleos)
Antes de instalar (utilizando install.sh o make dev_install), a través de export USE_NUMA=1 Configuración de variables de entorno USE_NUMA=1 (Si ya está instalado, vuelva a instalarlo con esta variable de entorno establecida)
El equipo de KTransformers local_chat El comando de prueba es:
git clone https://github.com/kvcache-ai/ktransformers.git
cd ktransformers
export USE_NUMA=1
make dev_install # or sh ./install.sh
python ./ktransformers/local_chat.py --model_path <your model path> --gguf_path <your gguf path> --prompt_file <your prompt txt file> --cpu_infer 65 --cache_lens 1536
<当看到 chat 时,按 Enter 键加载文本 prompt_file>
tiene el mismo significado. Sin embargo, dado que el equipo KTransformers utiliza un bidireccional, será cpu_infer Fijado en 65
Demo V0.3
Versión Dual-Path (64 núcleos)
El equipo de KTransformers local_chat El comando de prueba es:
wget https://github.com/kvcache-ai/ktransformers/releases/download/v0.1.4/ktransformers-0.3.0rc0+cu126torch26fancy-cp311-cp311-linux_x86_64.whl
pip install ./ktransformers-0.3.0rc0+cu126torch26fancy-cp311-cp311-linux_x86_64.whl
python -m ktransformers.local_chat --model_path <your model path> --gguf_path <your gguf path> --prompt_file <your prompt txt file> --cpu_infer 65 --cache_lens 1536
<当看到 chat 时,按 Enter 键加载文本 prompt_file>
El significado de los parámetros es el mismo que en la V0.2. Sin embargo, dado que el equipo de KTransformers utiliza una doble vía, los parámetros cpu_infer Fijado en 65
Algunas explicaciones
- El equipo de KTransformers también quería aprovechar mejor los dos nodos NUMA de la CPU Xeon Gold.
Para evitar el coste de la transferencia de datos entre nodos, el equipo de KTransformers está
La matriz de claves se "copia" en ambos nodos, lo que consume más memoria pero acelera el proceso de prepoblación y descodificación.
Sin embargo, este método utiliza mucha memoria y tarda en cargar los pesos, así que ¡ten paciencia mientras se carga!
El equipo de KTransformers optimizará esta enorme sobrecarga de memoria. Permanece atento~ Esta "copia" de la matriz puede acelerar el proceso, pero la huella de memoria es un verdadero problema, así que estamos deseando ver qué se le ocurre al equipo de KTransformers en el futuro. - parámetro de comando
--cpu_infer 65Especifique el número de núcleos a utilizar (más que el número de núcleos físicos está bien, el
Pero más no es mejor. Ajústalo ligeramente por debajo del número real de núcleos.) - ¿Por qué la inferencia híbrida CPU/GPU?
DeepSeek El algoritmo MLA es intensivo desde el punto de vista computacional. Aunque es posible ejecutarlo íntegramente en la CPU, descargar el cálculo pesado en la GPU puede mejorar drásticamente el rendimiento. Con la CPU encargándose del cálculo experto y la GPU del MLA/KVCache, esta estrategia de inferencia híbrida parece inteligente, ya que aprovecha al máximo tanto la CPU como la GPU. - ¿De dónde procede el aumento de velocidad?
- Descarga de expertos: A diferencia de las descargas tradicionales basadas en capas o KVCache (como se ve en llama.cpp), el equipo de KTransformers descarga el cálculo de expertos a la CPU y MLA/KVCache a la GPU, lo que encaja perfectamente con la arquitectura de DeepSeek para lograr una eficiencia óptima.
- Optimización Intel AMX - El kernel acelerado AMX del equipo KTransformers ha sido cuidadosamente ajustado para ejecutarse varias veces más rápido que la implementación existente llama.cpp. el equipo KTransformers planea abrir el código de este kernel después de la limpieza, y está considerando contribuir con código al upstream llama.cpp. el AMX La incorporación del conjunto de instrucciones AMX parece ser uno de los factores clave en la aceleración de KTransformers.
- ¿Por qué CPU Intel?
Intel es actualmente el único proveedor de CPU que admite la instrucción AMX, que ofrece un rendimiento significativamente mejor que la alternativa basada únicamente en AVX. Parece que las CPU de Intel son el camino a seguir cuando se trata de experimentar el mejor rendimiento de KTransformers.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...