
Jina AI presenta Reader-LM, un revolucionario modelo de lenguaje reducido para extraer eficazmente el contenido principal de las páginas web HTML

Jina AI ha lanzado Reader-LM-0.5B y Reader-LM-1.5B, dos pequeños modelos lingüísticos diseñados para convertir HTML sin procesar y ruidoso de la web abierta en formato Markdown limpio, que admiten longitudes de contexto de hasta 256K tokens y muestran un rendimiento comparable o mejor que los grandes modelos lingüísticos en las tareas de conversión. rendimiento en la tarea de conversión.
prólogo
En abril de 2024, Jina AI lanzó Jina Reader, una sencilla API que convierte cualquier URL en markdown compatible con LLM. La API utiliza el navegador Chrome para obtener el código fuente de una página web, extrae el contenido principal utilizando el paquete Readability de Mozilla y convierte el HTML limpio en markdown utilizando regex y las bibliotecas para convertir el HTML depurado en markdown.
Tras el lanzamiento, los comentarios de los usuarios apuntaban a problemas con la calidad de los contenidos, que Jina AI solucionó parcheando la canalización existente.
Desde entonces, hemos estado dándole vueltas a la siguiente pregunta: en lugar de juguetear con más heurísticas y expresiones regulares (que cada vez son más difíciles de mantener y no favorecen el multilingüismo), ¿podemos resolver este problema de principio a fin con un modelo lingüístico?

Ilustración de reader-lm, que sustituye la heurística readability+turndown+regex por un pequeño modelo lingüístico.
Acerca de Reader-LM
11 de septiembre de 2024 -- Jina AI, que sigue impulsando la innovación en inteligencia artificial para el procesamiento de contenidos y la conversión de textos, ha anunciado hoy el lanzamiento de sus últimos logros tecnológicos: Reader-LM-0.5B y Reader-LM-1.5B, dos pequeños modelos lingüísticos. Estos modelos marcan una nueva era en el procesamiento de contenidos HTML sin procesar en la web abierta, convirtiendo eficientemente HTML complejo en formato Markdown estructurado, proporcionando un potente soporte para la gestión de contenidos y aplicaciones de aprendizaje automático en la era del Big Data.
Rendimiento y eficiencia revolucionarios
Los modelos Reader-LM-0.5B y Reader-LM-1.5B consiguen un rendimiento comparable o incluso superior al de los modelos lingüísticos de mayor tamaño, al tiempo que mantienen un tamaño de parámetros compacto. Estos modelos, que admiten longitudes de contexto de hasta 256.000 tokens, gestionan los elementos ruidosos del HTML moderno, como CSS en línea, scripts, etc., y producen archivos Markdown limpios y bien estructurados. Esto supone una gran comodidad para los usuarios que necesitan extraer y convertir texto a partir de contenido web sin procesar.

Experiencia práctica fácil de usar
Jina AI ofrece una solución a este problema en el Google Colab (0.5Bresponder cantando1.5BEl modelo Reader-LM se ha diseñado para ofrecer a los usuarios la posibilidad de experimentar fácilmente la potencia del modelo Reader-LM mediante el uso de las notas Reader-LM. Ya se trate de cargar diferentes versiones del modelo, cambiar la URL de un sitio procesado o explorar el resultado, los usuarios pueden hacerlo en un entorno gratuito basado en la nube. Además, Reader-LM pronto estará disponible en los mercados de Azure y AWS, lo que proporcionará más opciones de integración y despliegue para los usuarios empresariales.
Rendimiento superior a los modelos tradicionales
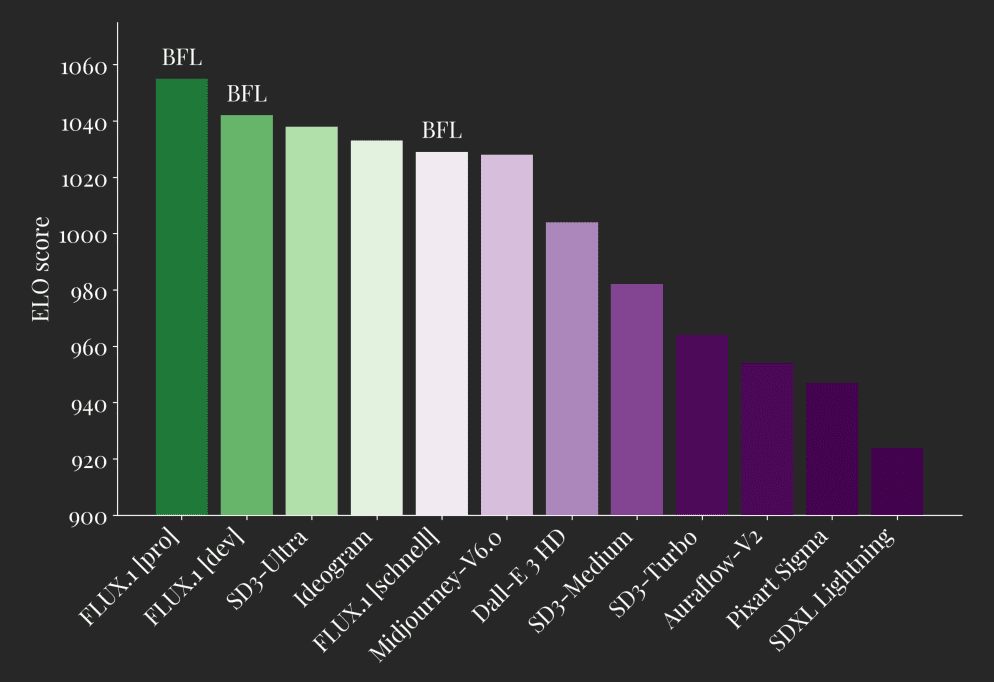
Mediante pruebas comparativas con grandes modelos lingüísticos como GPT-4o, Gemini-1.5-Flash, Gemini-1.5-Pro, LLaMA-3.1-70B y Qwen2-7B-Instruct, se demuestra que Reader-LM obtiene buenos resultados en ROUGE-L, Word Error Rate (WER) y Ficha (TER), entre otras métricas clave. Estas evaluaciones demuestran el liderazgo de Reader-LM en precisión, recuperación y capacidad para generar Markdown limpio.

La investigación cualitativa confirma sus beneficios
Además de la evaluación cuantitativa, Jina AI ha confirmado el rendimiento superior de Reader-LM en la extracción de titulares, la extracción de contenido principal, la retención de estructuras y el uso de sintaxis Markdown mediante estudios cualitativos de Markdown de salida inspeccionado visualmente. Estos resultados ponen de manifiesto la eficacia y fiabilidad de Reader-LM en aplicaciones reales.
Un enfoque innovador de la formación en dos etapas
Jina AI desveló los detalles de su proceso de formación de Reader-LM, incluida la preparación de los datos, la formación en dos fases y cómo superaron los problemas de degradación y ciclado del modelo. Hicieron hincapié en la importancia de la calidad de los datos de entrenamiento y garantizaron la estabilidad del modelo y la calidad de la generación a través de medios técnicos como la búsqueda comparativa y los criterios de parada repetida.
lo último en
Reader-LM de Jina AI no sólo supone un gran avance en el campo de la modelización de pequeños lenguajes, sino también una mejora significativa de las capacidades de procesamiento de contenidos web abiertos. El lanzamiento de estos dos modelos no solo proporciona a los desarrolladores y científicos de datos una herramienta eficiente y fácil de usar, sino que también abre nuevas posibilidades para las aplicaciones de IA en la extracción, limpieza y transformación de contenidos.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Puestos relacionados


Sin comentarios...