
Descubrir la ilusión del gran modelo: las clasificaciones de los HHEM permiten comprender el estado de la coherencia factual en el LLM

Aunque las capacidades de los grandes modelos lingüísticos (LLM) evolucionan constantemente, el fenómeno de los errores factuales o "ilusiones" de información no relacionada con el texto original en sus resultados siempre ha sido un reto importante que ha impedido su uso más amplio y una mayor confianza en ellos. Para evaluar cuantitativamente este problema, laClasificación del Modelo de Evaluación de Alucinaciones de Hughes (HHEM)centrado en medir la frecuencia de los fantasmas en los LLM dominantes a la hora de generar resúmenes de documentos.
El término "ilusión" se refiere al hecho de que el modelo introduce "hechos" en el resumen que no están contenidos en el documento original, o incluso son contradictorios. Se trata de un cuello de botella de calidad crítica para los escenarios de procesamiento de información que dependen del LLM, especialmente los basados en la Generación Aumentada de Recuperación (RAG). Al fin y al cabo, si el modelo no es fiel a la información dada, la credibilidad de su resultado se reduce enormemente.
¿Cómo funciona HHEM?
La clasificación utiliza el modelo de evaluación de alucinaciones HHEM-2.1 desarrollado por Vectara. Funciona de la siguiente manera: para un documento fuente y un resumen generado por un LLM concreto, el modelo HHEM emite una puntuación de alucinación entre 0 y 1. Cuanto más se acerque a 1, mayor será la coherencia factual del resumen con el documento fuente. Cuanto más se acerque la puntuación a 1, mayor será la coherencia factual del resumen con el documento fuente; cuanto más se acerque a 0, más grave será la alucinación, o incluso el contenido completamente inventado.Vectara también proporciona una versión de código abierto, HHEM-2.1-Open, para que investigadores y desarrolladores realicen la evaluación localmente, y sus tarjetas de modelo se publican en la plataforma Hugging Face.
Parámetros de evaluación
Para la evaluación se utilizó un conjunto de datos de 1006 documentos, procedentes principalmente de bases de datos públicas como el clásico CNN/Daily Mail Corpus. El equipo del proyecto generó un resumen para cada documento utilizando los LLM individuales implicados en la evaluación y, a continuación, calculó la puntuación HHEM para cada par (documento fuente, resumen generado). Para garantizar la normalización de la evaluación, todas las llamadas al modelo se ajustaron a temperature El parámetro es 0 y tiene por objeto obtener el resultado más determinista del modelo.
Los indicadores de evaluación incluyen, entre otros
- Tasa de alucinaciones. Porcentaje de resúmenes con puntuaciones HHEM inferiores a 0,5. Cuanto más bajo sea el valor, mejor.
- Tasa de coherencia de los hechos. 100% menos la tasa de alucinaciones, que refleja la proporción de resúmenes cuyo contenido es fiel al original.
- Tasa de respuesta. Porcentaje de modelos que generan con éxito resúmenes no vacíos. Algunos modelos pueden negarse a responder o cometer errores debido a políticas de seguridad de contenidos u otros motivos.
- Duración media del resumen. El número medio de palabras en los resúmenes generados proporciona una visión lateral del estilo de salida del modelo.
Explicación de los rankings LLM Illusion
A continuación se muestran las clasificaciones de alucinaciones LLM basadas en la evaluación del modelo HHEM-2.1 (datos a 25 de marzo de 2025, consulte la actualización actual):
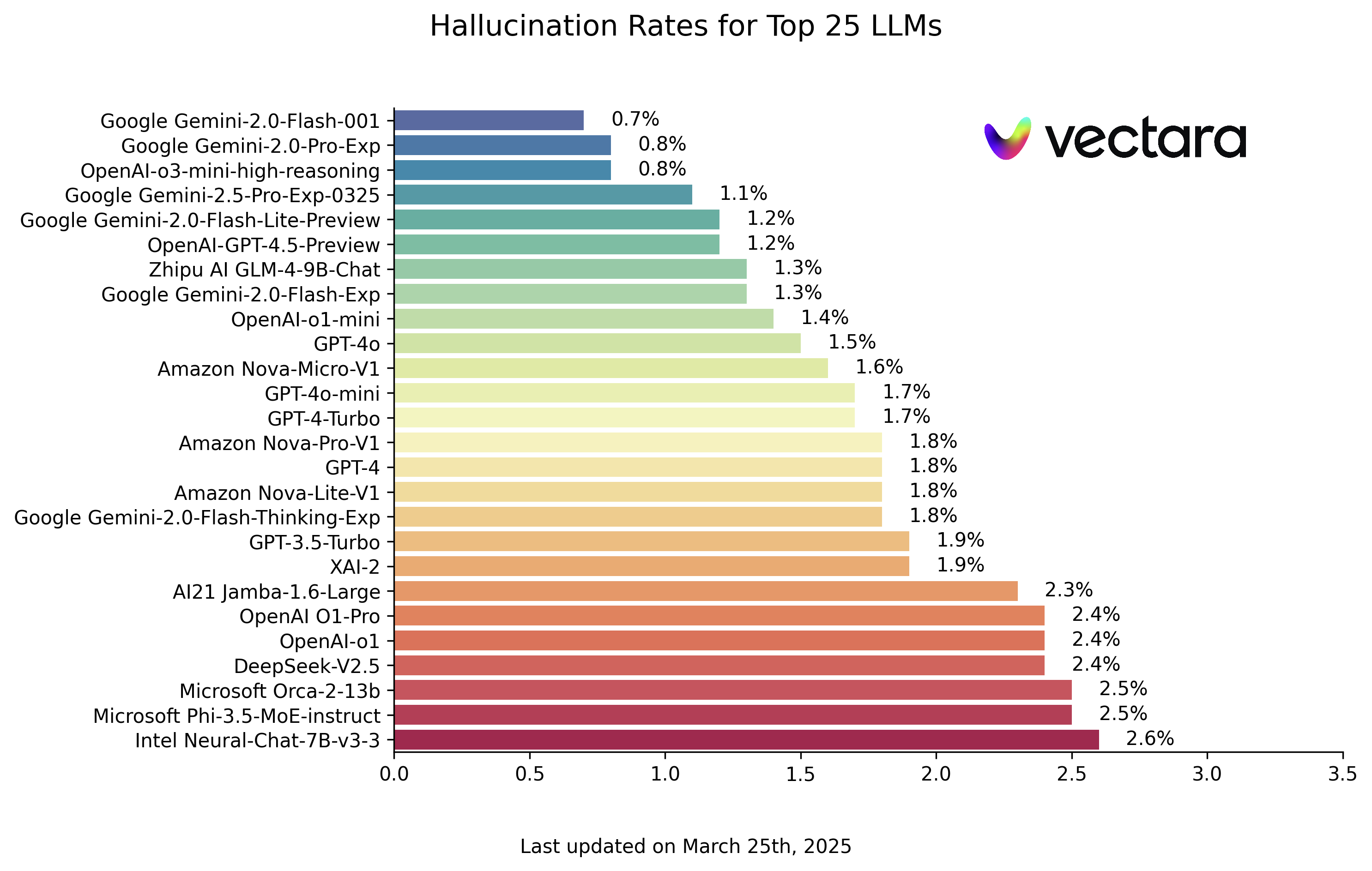
| Modelo | Tasa de alucinaciones | Tasa de coherencia de los hechos | Tasa de respuesta | Extensión media del resumen (palabras) |
|---|---|---|---|---|
| Google Gemini-2.0-Flash-001 | 0.7 % | 99.3 % | 100.0 % | 65.2 |
| Google Gemini-2.0-Pro-Exp | 0.8 % | 99.2 % | 99.7 % | 61.5 |
| OpenAI-o3-mini-razonamiento-alto | 0.8 % | 99.2 % | 100.0 % | 79.5 |
| Google Gemini-2.5-Pro-Exp-0325 | 1.1 % | 98.9 % | 95.1 % | 72.9 |
| Google Gemini-2.0-Flash-Lite-Preview | 1.2 % | 98.8 % | 99.5 % | 60.9 |
| OpenAI-GPT-4.5-Previsualización | 1.2 % | 98.8 % | 100.0 % | 77.0 |
| Zhipu AI GLM-4-9B-Chat | 1.3 % | 98.7 % | 100.0 % | 58.1 |
| Google Gemini-2.0-Flash-Exp | 1.3 % | 98.7 % | 99.9 % | 60.0 |
| OpenAI-o1-mini | 1.4 % | 98.6 % | 100.0 % | 78.3 |
| GPT-4o | 1.5 % | 98.5 % | 100.0 % | 77.8 |
| Amazon Nova-Micro-V1 | 1.6 % | 98.4 % | 100.0 % | 90.0 |
| GPT-4o-mini | 1.7 % | 98.3 % | 100.0 % | 76.3 |
| GPT-4-Turbo | 1.7 % | 98.3 % | 100.0 % | 86.2 |
| Google Gemini-2.0-Flash-Pensamiento-Exp | 1.8 % | 98.2 % | 99.3 % | 73.2 |
| Amazon Nova-Lite-V1 | 1.8 % | 98.2 % | 99.9 % | 80.7 |
| GPT-4 | 1.8 % | 98.2 % | 100.0 % | 81.1 |
| Amazon Nova-Pro-V1 | 1.8 % | 98.2 % | 100.0 % | 85.5 |
| GPT-3.5-Turbo | 1.9 % | 98.1 % | 99.6 % | 84.1 |
| XAI-2 | 1.9 % | 98.1 | 100.0 % | 86.5 |
| AI21 Jamba-1.6-Grande | 2.3 % | 97.7 % | 99.9 % | 85.6 |
| OpenAI O1-Pro | 2.4 % | 97.6 % | 100.0 % | 81.0 |
| OpenAI-o1 | 2.4 % | 97.6 % | 99.9 % | 73.0 |
| DeepSeek-V2.5 | 2.4 % | 97.6 % | 100.0 % | 83.2 |
| Microsoft Orca-2-13b | 2.5 % | 97.5 % | 100.0 % | 66.2 |
| Microsoft Phi-3.5-MoE-instruct | 2.5 % | 97.5 % | 96.3 % | 69.7 |
| Intel Neural-Chat-7B-v3-3 | 2.6 % | 97.4 % | 100.0 % | 60.7 |
| Google Gemma-3-12B-Instruct | 2.8 % | 97.2 % | 100.0 % | 69.6 |
| Qwen2.5-7B-Instrucción | 2.8 % | 97.2 % | 100.0 % | 71.0 |
| AI21 Jamba-1,5-Mini | 2.9 % | 97.1 % | 95.6 % | 74.5 |
| Visión XAI-2 | 2.9 % | 97.1 | 100.0 % | 79.8 |
| Qwen2.5-Max | 2.9 % | 97.1 % | 88.8 % | 90.4 |
| Google Gemma-3-27B-Instruct | 3.0 % | 97.0 % | 100.0 % | 62.5 |
| Snowflake-Arctic-Instruct | 3.0 % | 97.0 % | 100.0 % | 68.7 |
| Qwen2.5-32B-Instrucción | 3.0 % | 97.0 % | 100.0 % | 67.9 |
| Microsoft Phi-3-mini-128k-instruct | 3.1 % | 96.9 % | 100.0 % | 60.1 |
| Mistral Pequeño3 | 3.1 % | 96.9 % | 100.0 % | 74.9 |
| OpenAI-o1-preview | 3.3 % | 96.7 % | 100.0 % | 119.3 |
| Google Gemini-1.5-Flash-002 | 3.4 % | 96.6 % | 99.9 % | 59.4 |
| Microsoft Phi-4-mini-instrucción | 3.4 % | 96.6 % | 100.0 % | 69.7 |
| Google Gemma-3-4B-Instruct | 3.7 % | 96.3 % | 100.0 % | 63.7 |
| 01-AI Yi-1.5-34B-Chat | 3.7 % | 96.3 % | 100.0 % | 83.7 |
| Llama-3.1-405B-Instruct | 3.9 % | 96.1 % | 99.6 % | 85.7 |
| DeepSeek-V3 | 3.9 % | 96.1 % | 100.0 % | 88.2 |
| Microsoft Phi-3-mini-4k-instruct | 4.0 % | 96.0 % | 100.0 % | 86.8 |
| Llama-3.3-70B-Instruct | 4.0 % | 96.0 % | 100.0 % | 85.3 |
| InternLM3-8B-Instruct | 4.0 % | 96.0 % | 100.0 % | 97.5 |
| Microsoft Phi-3.5-mini-instrucción | 4.1 % | 95.9 % | 100.0 % | 75.0 |
| Mistral-Grande2 | 4.1 % | 95.9 % | 100.0 % | 77.4 |
| Llama-3-70B-Chat-hf | 4.1 % | 95.9 % | 99.2 % | 68.5 |
| Qwen2-VL-7B-Instrucción | 4.2 % | 95.8 % | 100.0 % | 73.9 |
| Qwen2.5-14B-Instrucción | 4.2 % | 95.8 % | 100.0 % | 74.8 |
| Qwen2.5-72B-Instrucción | 4.3 % | 95.7 % | 100.0 % | 80.0 |
| Llama-3.2-90B-Visión-Instrucción | 4.3 % | 95.7 % | 100.0 % | 79.8 |
| Claude-3.7-Sonnet | 4.4 % | 95.6 % | 100.0 % | 97.8 |
| Claude-3.7-Sonnet-Piensa | 4.5 % | 95.5 % | 99.8 % | 99.9 |
| Cohere Comando-A | 4.5 % | 95.5 % | 100.0 % | 77.3 |
| AI21 Jamba-1.6-Mini | 4.6 % | 95.4 % | 100.0 % | 82.3 |
| XAI Grok | 4.6 % | 95.4 % | 100.0 % | 91.0 |
| Antrópico Claude-3-5-sonnet | 4.6 % | 95.4 % | 100.0 % | 95.9 |
| Qwen2-72B-Instrucciones | 4.7 % | 95.3 % | 100.0 % | 100.1 |
| Microsoft Phi-4 | 4.7 % | 95.3 % | 100.0 % | 100.3 |
| Mixtral-8x22B-Instruct-v0.1 | 4.7 % | 95.3 % | 99.9 % | 92.0 |
| Claude antrópico-3-5-haiku | 4.9 % | 95.1 % | 100.0 % | 92.9 |
| 01-AI Yi-1.5-9B-Chat | 4.9 % | 95.1 % | 100.0 % | 85.7 |
| Coherencia Comando-R | 4.9 % | 95.1 % | 100.0 % | 68.7 |
| Llama-3.1-70B-Instruct | 5.0 % | 95.0 % | 100.0 % | 79.6 |
| Google Gemma-3-1B-Instruct | 5.3 % | 94.7 % | 99.9 % | 57.9 |
| Llama-3.1-8B-Instrucción | 5.4 % | 94.6 % | 100.0 % | 71.0 |
| Cohere Comando-R-Plus | 5.4 % | 94.6 % | 100.0 % | 68.4 |
| Mistral-Pequeño-3.1-24B-Instrucciones | 5.6 % | 94.4 % | 100.0 % | 73.1 |
| Llama-3.2-11B-Visión-Instrucción | 5.5 % | 94.5 % | 100.0 % | 67.3 |
| Llama-2-70B-Chat-hf | 5.9 % | 94.1 % | 99.9 % | 84.9 |
| IBM Granite-3.0-8B-Instrucción | 6.5 % | 93.5 % | 100.0 % | 74.2 |
| Google Gemini-1.5-Pro-002 | 6.6 % | 93.7 % | 99.9 % | 62.0 |
| Google Gemini-1.5-Flash | 6.6 % | 93.4 % | 99.9 % | 63.3 |
| Mistral-Pixtral | 6.6 % | 93.4 % | 100.0 % | 76.4 |
| Microsoft phi-2 | 6.7 % | 93.3 % | 91.5 % | 80.8 |
| Google Gemma-2-2B-it | 7.0 % | 93.0 % | 100.0 % | 62.2 |
| Qwen2.5-3B-Instrucción | 7.0 % | 93.0 % | 100.0 % | 70.4 |
| Llama-3-8B-Chat-hf | 7.4 % | 92.6 % | 99.8 % | 79.7 |
| Mistral-Ministral-8B | 7.5 % | 92.5 % | 100.0 % | 62.7 |
| Google Gemini-Pro | 7.7 % | 92.3 % | 98.4 % | 89.5 |
| 01-AI Yi-1.5-6B-Chat | 7.9 % | 92.1 % | 100.0 % | 98.9 |
| Llama-3.2-3B-Instrucción | 7.9 % | 92.1 % | 100.0 % | 72.2 |
| DeepSeek-V3-0324 | 8.0 % | 92.0 % | 100.0 % | 78.9 |
| Mistral-Ministral-3B | 8.3 % | 91.7 % | 100.0 % | 73.2 |
| databricks dbrx-instruct | 8.3 % | 91.7 % | 100.0 % | 85.9 |
| Qwen2-VL-2B-Instrucciones | 8.3 % | 91.7 % | 100.0 % | 81.8 |
| Cohere Aya Expansión 32B | 8.5 % | 91.5 % | 99.9 % | 81.9 |
| IBM Granite-3.1-8B-Instruct | 8.6 % | 91.4 % | 100.0 % | 107.4 |
| Mistral-Pequeño2 | 8.6 % | 91.4 % | 100.0 % | 74.2 |
| IBM Granite-3.2-8B-Instrucción | 8.7 % | 91.3 % | 100.0 % | 120.1 |
| IBM Granite-3.0-2B-Instruct | 8.8 % | 91.2 % | 100.0 % | 81.6 |
| Mistral-7B-Instrucción-v0.3 | 9.5 % | 90.5 % | 100.0 % | 98.4 |
| Google Gemini-1.5-Pro | 9.1 % | 90.9 % | 99.8 % | 61.6 |
| Claude-3-opus antrópico | 10.1 % | 89.9 % | 95.5 % | 92.1 |
| Google Gemma-2-9B-it | 10.1 % | 89.9 % | 100.0 % | 70.2 |
| Llama-2-13B-Chat-hf | 10.5 % | 89.5 % | 99.8 % | 82.1 |
| AllenAI-OLMo-2-13B-Instrucción | 10.8 % | 89.2 % | 100.0 % | 82.0 |
| AllenAI-OLMo-2-7B-Instrucción | 11.1 % | 88.9 % | 100.0 % | 112.6 |
| Mistral-Nemo-Instruct | 11.2 % | 88.8 % | 100.0 % | 69.9 |
| Llama-2-7B-Chat-hf | 11.3 % | 88.7 % | 99.6 % | 119.9 |
| Microsoft WizardLM-2-8x22B | 11.7 % | 88.3 % | 99.9 % | 140.8 |
| Cohere Aya Expansión 8B | 12.2 % | 87.8 % | 99.9 % | 83.9 |
| Amazon Titan-Express | 13.5 % | 86.5 % | 99.5 % | 98.4 |
| Google PaLM-2 | 14.1 % | 85.9 % | 99.8 % | 86.6 |
| DeepSeek-R1 | 14.3 % | 85.7 % | 100.0% | 77.1 |
| Google Gemma-7B-it | 14.8 % | 85.2 % | 100.0 % | 113.0 |
| IBM Granite-3.1-2B-Instrucción | 15.7 % | 84.3 % | 100.0 % | 107.7 |
| Qwen2.5-1.5B-Instrucción | 15.8 % | 84.2 % | 100.0 % | 70.7 |
| Qwen-QwQ-32B-Preview | 16.1 % | 83.9 % | 100.0 % | 201.5 |
| Claude-3-sonnet antrópico | 16.3 % | 83.7 % | 100.0 % | 108.5 |
| IBM Granite-3.2-2B-Instrucción | 16.5 % | 83.5 % | 100.0 % | 117.7 |
| Google Gemma-1.1-7B-it | 17.0 % | 83.0 % | 100.0 % | 64.3 |
| Claude-2 antrópica | 17.4 % | 82.6 % | 99.3 % | 87.5 |
| Google Flan-T5-grande | 18.3 % | 81.7 % | 99.3 % | 20.9 |
| Mixtral-8x7B-Instrucción-v0.1 | 20.1 % | 79.9 % | 99.9 % | 90.7 |
| Llama-3.2-1B-Instrucción | 20.7 % | 79.3 % | 100.0 % | 71.5 |
| Apple OpenELM-3B-Instruct | 24.8 % | 75.2 % | 99.3 % | 47.2 |
| Qwen2,5-0,5B-Instrucción | 25.2 % | 74.8 % | 100.0 % | 72.6 |
| Google Gemma-1.1-2B-it | 27.8 % | 72.2 % | 100.0 % | 66.8 |
| TII falcon-7B-instruct | 29.9 % | 70.1 % | 90.0 % | 75.5 |
Nota: Los modelos se clasifican en orden descendente en función de la tasa fantasma. La lista completa y los detalles de acceso a los modelos pueden consultarse en el repositorio GitHub original de la clasificación HHEM.
Un vistazo a la clasificación muestra que Google Gemini y algunos de los modelos más recientes de OpenAI (por ejemplo, el modelo o3-mini-high-reasoning) obtuvieron unos resultados impresionantes, con un índice de alucinaciones que se mantuvo en un nivel muy bajo. Esto demuestra los progresos realizados por los fabricantes de cabezas para mejorar la factorialidad de sus modelos. Al mismo tiempo, se observan diferencias significativas entre modelos de distintos tamaños y arquitecturas. Algunos modelos más pequeños, como el de Microsoft Phi o la serie Gemma también obtuvieron buenos resultados, lo que implica que el número de parámetros del modelo no es el único factor determinante de la coherencia de los hechos. Sin embargo, algunos modelos tempranos o específicamente optimizados presentan tasas relativamente altas de ilusiones.
Desajuste entre los modelos de inferencia fuerte y las bases de conocimiento: el caso de DeepSeek-R1
las listas (de best-sellers) DeepSeek-R1 La tasa relativamente alta de alucinaciones (14,31 TP3T) plantea una cuestión que merece la pena explorar: ¿por qué algunos modelos que obtienen buenos resultados en tareas de razonamiento son, en cambio, propensos a las alucinaciones en tareas de resumen basadas en hechos?
DeepSeek-R1 Estos modelos suelen estar diseñados para manejar el razonamiento lógico complejo, el seguimiento de órdenes y el pensamiento en varios pasos. Su punto fuerte es la "deducción" y la "deducción", más que la simple "repetición" o "paráfrasis". Sin embargo, las bases de conocimiento (especialmente RAG (base de conocimientos en escenarios), el requisito fundamental es precisamente este último: el modelo debe responder o resumir estrictamente a partir de la información textual proporcionada, minimizando la introducción de conocimientos externos o la sobreextracción.
Cuando un modelo de razonamiento fuerte se limita a resumir sólo con un documento determinado, su instinto "razonador" puede ser un arma de doble filo. Puede:
- Sobreinterpretación. Extrapolar información del texto original de forma innecesariamente profunda y sacar conclusiones que no se indican explícitamente en el texto original.
- Información de costura. Intenta enlazar la información fragmentada del texto original mediante una cadena "lógica" que puede no estar respaldada por el texto original.
- Conocimiento externo por defecto. Incluso cuando se les pide que se basen únicamente en el texto original, los vastos conocimientos del mundo adquiridos en su formación pueden seguir filtrándose inconscientemente, dando lugar a desviaciones de los hechos del texto original.
En pocas palabras, esos modelos pueden "pensar demasiado" y, en escenarios que requieren una reproducción exacta y fiel de la información, son propensos a ser "demasiado listos para su propio bien", creando contenidos que parecen razonables, pero que en realidad son una ilusión. Esto demuestra que la capacidad de razonamiento de los modelos y la coherencia factual (especialmente en el caso de fuentes de información restringidas) son dos dimensiones de capacidad diferentes. Para escenarios como las bases de conocimiento y los GAR, puede ser más importante seleccionar modelos con un bajo índice de alucinación que reflejen fielmente la información de entrada que limitarse a perseguir una puntuación de razonamiento.
Metodología y antecedentes
La clasificación HHEM no surgió de la nada, y se basa en una serie de esfuerzos previos en el campo de la investigación de la coherencia fáctica, como los siguientes SUMMAC, TRUE, TrueTeacher La metodología establecida en los trabajos de et al. La idea central es entrenar un modelo específico para la detección de alucinaciones que alcance un alto nivel de correlación con los evaluadores humanos a la hora de juzgar la coherencia del resumen con el texto original.
La tarea de resumen fue seleccionada por el proceso de evaluación como indicador de la factualidad del LLM. Esto se debe no sólo a que la propia tarea de resumen requiere un alto grado de coherencia factual, sino también a que es muy similar al modelo de trabajo del sistema GAR: en GAR, es el LLM el que desempeña el papel de integrar y resumir la información recuperada. Los resultados de esta clasificación son, por tanto, informativos para evaluar la fiabilidad del modelo en las aplicaciones GAR.
Es importante señalar que el equipo de evaluación excluyó los documentos a los que los modelos se negaron a responder o dieron respuestas muy breves e inválidas, y en última instancia utilizó los 831 documentos (de los 1006 originales) para los que todos los modelos pudieron generar resúmenes con éxito para el cálculo de la clasificación final con el fin de garantizar la imparcialidad. El índice de respuestas y la longitud media de los resúmenes también reflejan las pautas de comportamiento de los modelos a la hora de procesar estas solicitudes.
La plantilla Prompt utilizada para la evaluación es la siguiente:
You are a chat bot answering questions using data. You must stick to the answers provided solely by the text in the passage provided. You are asked the question 'Provide a concise summary of the following passage, covering the core pieces of information described.' <PASSAGE>'
En el momento de la llamada real, el<PASSAGE> se sustituirá por el contenido específico del documento de origen.
mirando hacia delante
El programa de clasificación HHEM ha indicado que tiene previsto ampliar el alcance de la evaluación en el futuro:
- Precisión de las citas. Añadir una evaluación de la exactitud de la citación de fuentes de LLM en los escenarios RAG.
- Otras tareas RAG. Abarcar más tareas relacionadas con el GAR, como el resumen de documentos múltiples.
- Soporte multilingüe. Ampliar la evaluación a idiomas distintos del inglés.
La clasificación HHEM proporciona una valiosa ventana para observar y comparar la capacidad de diferentes LLM para controlar las ilusiones y mantener la coherencia factual. Aunque no es la única medida de la calidad de los modelos ni abarca todos los tipos de ilusiones, no cabe duda de que ha atraído la atención del sector hacia la cuestión de la fiabilidad de los LLM y constituye un importante punto de referencia para que los desarrolladores seleccionen y optimicen los modelos. A medida que se vayan perfeccionando los modelos y los métodos de evaluación, es de esperar que se produzcan aún más avances en el suministro de información precisa y creíble a partir de los LLM.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados
![[转]用 2000 美元 EPYC 服务器本地跑起 Deepseek R1 671b 大模型](https://aisharenet.com/wp-content/uploads/2025/02/78984d5c0694467.png)



Sin comentarios...