InternVL3.5 - Modelos grandes multimodales de código abierto de Shanghai AI Lab
Últimos recursos sobre IAPublicado hace 7 meses Círculo de intercambio de inteligencia artificial 48.2K 00

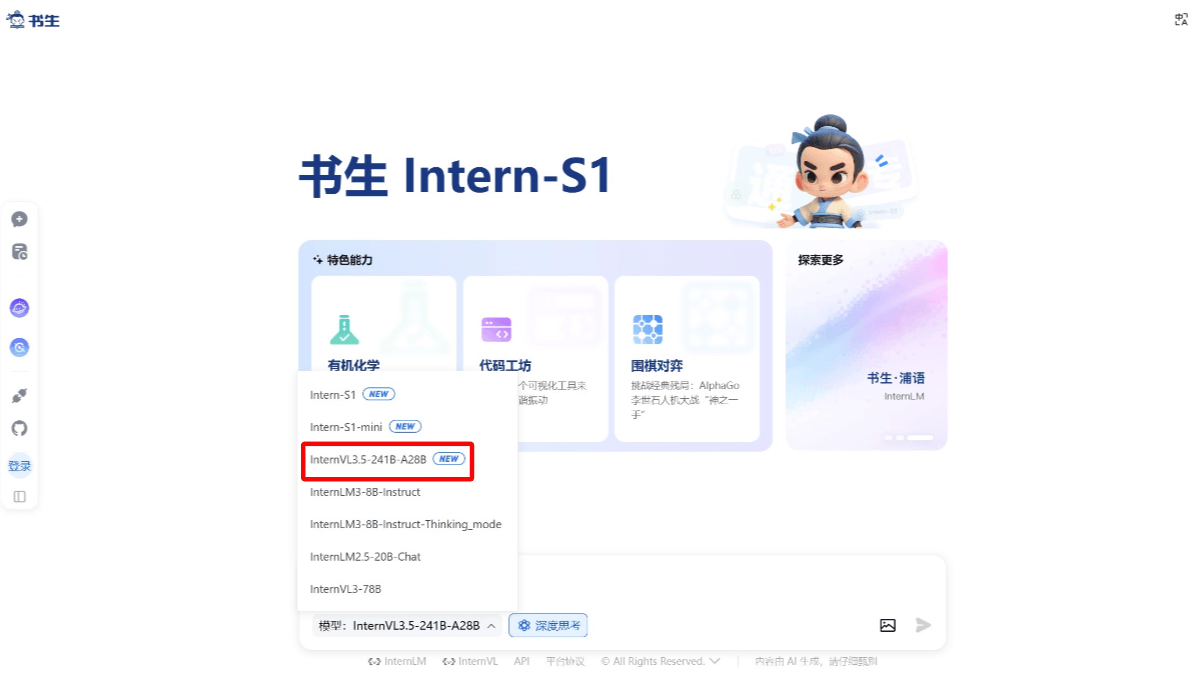
¿Qué es InternVL 3.5?
InternVL3.5 es un gran modelo multimodal de código abierto del Laboratorio de Inteligencia Artificial de Shanghái (SAL), que ha sido ampliamente mejorado en términos de capacidad general, capacidad de inferencia y eficiencia de despliegue, proporcionando nueve tamaños de 1.000 millones a 241.000 millones de parámetros, cubriendo diferentes escenarios de demanda de recursos, incluyendo el modelo denso y el modelo mixto de expertos (MoE), y es el primer gran modelo multimodal de código abierto que soporta el lenguaje GPT-OSS y la base de modelos. InternVL3.5 adopta el marco Cascade Reinforcement Learning (Cascade RL), que mejora significativamente la capacidad de inferencia mediante el proceso en dos fases de "calentamiento offline - ajuste online". Se han reforzado las capacidades básicas de interfaz gráfica de usuario, razonamiento espacial incorporado y procesamiento de gráficos vectoriales. Por ejemplo, en la tarea de posicionamiento de la interfaz gráfica ScreenSpot, el modelo supera a los principales modelos de código abierto con una puntuación de 92,9.
Características de InternVL 3.5
- Potentes funciones de detección multimodalEl sistema de gestión de contenidos de la Comisión Europea: puede comprender y procesar una amplia gama de información visual, como imágenes y vídeos, y generar descripciones de texto relevantes, adecuadas para la creación de contenidos, el servicio inteligente de atención al cliente y otros campos.
- Excelente rendimiento de la inferencia multimodalExcelente rendimiento en pruebas de referencia de razonamiento multidisciplinar, capaz de manejar tareas complejas de razonamiento multimodal, como la resolución de problemas matemático-físicos, el razonamiento lógico, etc., apto para la educación, la investigación y otros escenarios.
- Funciones eficaces de tratamiento de textos: Destaca en tareas de procesamiento del lenguaje natural como la inferencia de textos y las preguntas y respuestas, y proporciona generación y análisis de textos de alta calidad para aplicaciones como la escritura inteligente y el análisis de textos.
- Interfaz gráfica de usuario avanzada Funciones corporales inteligentesLos elementos de la interfaz pueden automatizarse en todas las plataformas, lo que permite realizar tareas como la recuperación de documentos, la exportación a PDF y el envío de correos electrónicos para mejorar la ofimática.
- Excelente razonamiento espacial corporalLa tecnología de navegación y comprensión de las relaciones espaciales físicas puede aplicarse a escenarios de inteligencia incorporada, como la navegación robótica y el control de hogares inteligentes, para mejorar la autonomía y la inteligencia de los dispositivos.
- Procesamiento de gráficos vectoriales de alta eficaciaPuede generar o editar gráficos vectoriales basados en comandos de lenguaje natural, lo que resulta adecuado para escenarios profesionales como el diseño web y el análisis de dibujos de ingeniería, y mejora la eficacia del diseño y el análisis.
- Opciones flexibles de implantación de modelosModelos densos: existe una amplia gama de tamaños de modelos, desde 1.000 millones hasta 241.000 millones de parámetros, para satisfacer diferentes necesidades de recursos y escenarios de aplicación, con soporte para modelos densos y modelos mixtos de experiencia (MoE).
Principales ventajas de InternVL 3.5
- Marco de aprendizaje por refuerzo en cascadaEl proceso en dos etapas de "calentamiento fuera de línea - ajuste fino en línea", combinado con los algoritmos de optimización de preferencias híbridas (MPO) y GSPO, mejora significativamente la capacidad de inferencia del modelo y la estabilidad del entrenamiento.
- Enrutamiento dinámico de la resolución visualLa elección dinámica de la tasa de compresión para cada corte de imagen reduce los tokens visuales al tiempo que preserva la información clave, lo que mejora significativamente la velocidad de inferencia sin apenas pérdida de rendimiento.
- Arquitectura de implantación disociadaEl nuevo diseño se basa en una combinación de transferencia de funciones de precisión BF16 y pipelining asíncrono, lo que incrementa enormemente el rendimiento y resuelve el problema de bloqueo de recursos de las implantaciones en serie tradicionales al colocar el codificador visual y el modelo de lenguaje en GPU diferentes.
- Optimización del modelo a escala realOfrece una amplia gama de tamaños de modelos, desde 1.000 millones hasta 241.000 millones de parámetros, que abarcan distintos escenarios de demanda de recursos, y admite modelos densos y modelos mixtos de experiencia (MoE) para satisfacer requisitos de aplicación diversificados.
- Excelente razonamiento multimodalObtención de la puntuación más alta para un modelo de código abierto en la prueba comparativa de razonamiento multidisciplinar MMMU, superando significativamente a los modelos de código abierto existentes con grandes capacidades de razonamiento matemático y lógico.
- Despliegue eficiente EficienciaLa capacidad de respuesta del modelo mejora espectacularmente con entradas de alta resolución, y el rendimiento del modelo 38B se multiplica por 4,05, lo que reduce significativamente el coste real de implantación.
¿Cuál es la página web oficial de InternVL3.5?
- Repositorio Github:: https://github.com/OpenGVLab/InternVL
- Dirección del modelo HuggingFace:: https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B
- Informe técnico:: https://huggingface.co/papers/2508.18265
- Dirección de la experiencia en línea:: https://chat.intern-ai.org.cn/
Personas a las que va dirigido InternVL 3.5
- Investigadores en inteligencia artificialEl modelo proporciona a los investigadores una potente herramienta de investigación multimodal que puede utilizarse para explorar nuevos algoritmos, arquitecturas de modelos y escenarios de aplicación, haciendo avanzar la investigación académica en IA multimodal.
- desarrollador de softwareLos desarrolladores pueden utilizar código fuente abierto y opciones de implantación flexibles para integrar el modelo en diversas aplicaciones informáticas y desarrollar productos y servicios con interacción inteligente.
- Educadores y estudiantesEn educación, las capacidades de razonamiento multimodal y procesamiento de textos del modelo pueden utilizarse para desarrollar herramientas de tutoría inteligente que ayuden a los estudiantes a comprender y resolver mejor problemas complejos de las asignaturas.
- creador de contenidosLos creadores de contenidos pueden utilizar la percepción multimodal y las funciones de generación de texto para generar rápidamente contenidos creativos, como descripciones de imágenes, pies de vídeos, artículos, etc., con el fin de mejorar la eficacia creativa.
- Usuarios de ofimáticaLa función GUI permite a los usuarios automatizar operaciones de oficina multiplataforma, mejorar la eficacia del trabajo y reducir las tareas repetitivas.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...