Ilya Sutskever estalla en NeurIPS y declara: se acabará el preentrenamiento, se acabó exprimir los datos

El razonamiento es impredecible, así que tenemos que empezar con sistemas de IA increíbles e impredecibles.
Ilya por fin ha aparecido y, de entrada, tiene algo sorprendente que decir. El viernes, Ilya Sutskever, antiguo científico jefe de OpenAI, dijo en la Global AI Summit que "hemos llegado al final de los datos que podemos obtener, y no va a haber más." 
Ilya Sutskever, cofundador y antiguo científico jefe de OpenAI, saltó a los titulares cuando dejó la empresa en mayo de este año para fundar su propio laboratorio de IA, Safe Superintelligence. Se ha mantenido alejado de los medios desde que dejó OpenAI, pero hizo una rara aparición pública este viernes en NeurIPS 2024, una conferencia sobre sistemas de procesamiento de información neuronal en Vancouver.
"El preentrenamiento tal y como lo conocemos llegará sin duda a su fin", dijo Sutskever desde el escenario.
En el campo de la inteligencia artificial, los modelos de preentrenamiento a gran escala, como BERT y GPT, han alcanzado un gran éxito en los últimos años y se han convertido en un hito en el camino del progreso tecnológico.
Debido a la complejidad de los objetivos del preentrenamiento y a los enormes parámetros del modelo, el preentrenamiento a gran escala puede captar eficazmente los conocimientos de una gran cantidad de datos etiquetados y no etiquetados. Al almacenar el conocimiento en parámetros enormes y ajustarlo para una tarea específica, el rico conocimiento implícitamente codificado en los enormes parámetros puede beneficiar a una gran variedad de tareas posteriores. El consenso en la comunidad de la IA es ahora adoptar el preentrenamiento como columna vertebral de las tareas posteriores, en lugar de aprender modelos desde cero. 
Sin embargo, en su charla de NeurIPS, Ilya Sutskever afirmó que, aunque los datos existentes pueden seguir impulsando la IA, el sector está a punto de quedarse sin datos nuevos que puedan considerarse utilizables. Señaló que esta tendencia acabará obligando a la industria a cambiar la forma en que se entrenan actualmente los modelos.
Sutskever compara la situación con el agotamiento de los combustibles fósiles: al igual que el petróleo es un recurso finito, también lo son los contenidos generados por el hombre en Internet.
"Hemos alcanzado el pico de datos, y no hay más datos por venir", dijo Sutskever. "Tenemos que utilizar los datos disponibles porque Internet sólo hay uno".
Sutskever predice que la próxima generación de modelos "exhibirá autonomía de forma real". Por otro lado, Agente se ha convertido en una palabra de moda en la IA.
Además de ser "autónomos", también mencionó que los futuros sistemas tendrán la capacidad de razonar. A diferencia de la IA actual, que se basa en gran medida en la coincidencia de patrones (basados en lo que el modelo ha visto antes), los futuros sistemas de IA serán capaces de resolver problemas paso a paso de forma similar a "pensar".
Sutskever afirma que cuanto más puede razonar un sistema, más "impredecible" es su comportamiento. Compara la imprevisibilidad de los "sistemas con verdadero poder de razonamiento" con el rendimiento de la IA avanzada en ajedrez: "ni siquiera los mejores jugadores humanos pueden predecir sus jugadas".
Estos sistemas podrán dar sentido a las cosas a partir de datos limitados y no confundirse", afirmó.
En su charla, comparó el Scaling en los sistemas de IA con la biología evolutiva, citando en el estudio la relación entre las proporciones de cerebro y peso corporal entre distintas especies. Señaló que la mayoría de los mamíferos siguen un patrón específico de Scaling, mientras que la familia humana (antepasados humanos) muestra una tendencia muy diferente de crecimiento de las proporciones cerebro-cuerpo en una escala logarítmica.
Sutskever propone que, al igual que la evolución ha encontrado un nuevo paradigma de escalado para el cerebro científico humano, la IA puede ir más allá de los métodos de preentrenamiento existentes y descubrir vías de escalado totalmente nuevas. A continuación figura el texto completo de la charla de Ilya Sutskever: 
Me gustaría dar las gracias a los organizadores de la conferencia por elegir un artículo para este premio (el artículo Seq2Seq de Ilya Sutskever et al. fue seleccionado para el premio NeurIPS 2024 Time Check). Es estupendo. También me gustaría dar las gracias a mis increíbles coautores Oriol Vinyals y Quoc V. Le, que están justo delante de ustedes. 

Tienes una imagen aquí, una captura de pantalla. hubo una charla similar en NIPS 2014 en Montreal hace 10 años. Eran tiempos mucho más inocentes. Aquí aparecemos en la foto. Por cierto, eso fue la última vez, la de abajo es esta vez.
Ahora tenemos más experiencia y esperamos ser un poco más sabios. Pero aquí me gustaría hablar un poco del ejercicio en sí, y quizá hacer un repaso de 10 años, porque muchas de las cosas que salieron bien en el ejercicio fueron acertadas, y otras no tanto. Podemos echar la vista atrás y ver qué pasó y cómo nos ha llevado a donde estamos hoy. Así que vamos a empezar a hablar de lo que hicimos. Lo primero que vamos a hacer es mostrar diapositivas de la misma presentación de hace 10 años. Se resume en tres puntos principales. Un modelo autorregresivo entrenado en texto, es una gran red neuronal, es un gran conjunto de datos, y eso es todo.
Así que vamos a empezar a hablar de lo que hicimos. Lo primero que vamos a hacer es mostrar diapositivas de la misma presentación de hace 10 años. Se resume en tres puntos principales. Un modelo autorregresivo entrenado en texto, es una gran red neuronal, es un gran conjunto de datos, y eso es todo.
Ahora vamos a entrar en más detalles. 
Aquí hay una diapositiva de hace 10 años que se ve bien, 'La Hipótesis del Aprendizaje Profundo'. Lo que estamos diciendo aquí es que si usted tiene una gran red neuronal con 10 capas, pero puede hacer cualquier cosa que un ser humano puede hacer en una fracción de segundo. ¿Por qué hacemos hincapié en "lo que los humanos pueden hacer en una fracción de segundo"? ¿Por qué esta cosa?
¿Por qué hacemos hincapié en "lo que los humanos pueden hacer en una fracción de segundo"? ¿Por qué esta cosa?
Bueno, si crees en el dogma del aprendizaje profundo de que las neuronas artificiales son similares a las neuronas biológicas, o al menos no demasiado diferentes, y crees que tres neuronas reales son lentas, entonces los humanos pueden procesar cualquier cosa rápidamente. Incluso me refiero a si hubiera una sola persona en el mundo. Si una persona en el mundo puede hacer algo en una fracción de segundo, entonces una red neuronal de 10 capas puede hacerlo, ¿no?
A continuación, basta con incrustar sus conexiones en una red neuronal artificial.
Todo es cuestión de motivación. Cualquier cosa que un humano pueda hacer en una fracción de segundo, también puede hacerla una red neuronal de 10 capas.
Nos centramos en las redes neuronales de 10 capas porque era la forma en que sabíamos entrenar entonces, y si de alguna manera podías superar ese número de capas, entonces podías hacer más. Pero entonces sólo podíamos hacer 10 capas, por eso nos centramos en todo lo que un ser humano podría hacer en una fracción de segundo.
La otra diapositiva de ese año ilustra nuestra idea principal de que usted podría ser capaz de identificar dos cosas, o al menos una cosa, usted podría ser capaz de identificar que la autoregresión está sucediendo aquí. 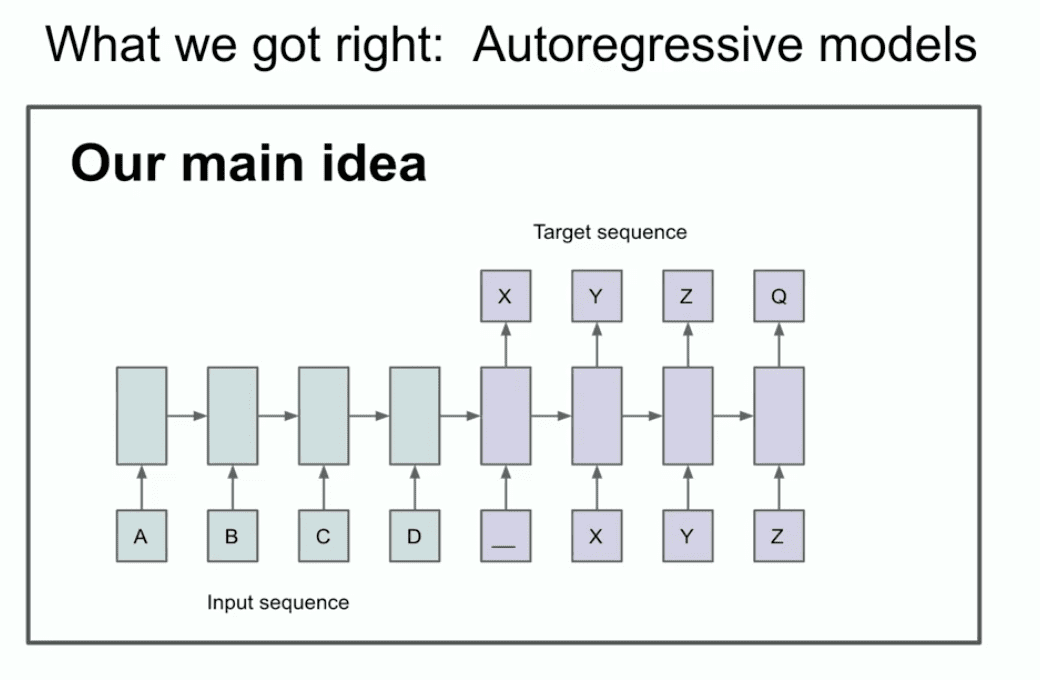
¿Qué demonios dice? ¿Qué dice realmente esta diapositiva? Esta diapositiva dice que si usted tiene un modelo autorregresivo y predice la próxima ficha lo suficientemente bueno, entonces realmente agarrará, capturará y mantendrá la distribución correcta de cualquier secuencia que aparezca a continuación.
Es algo relativamente nuevo, no es la primera red autorregresiva, pero creo que es la primera red neuronal autorregresiva. Realmente creíamos que si la entrenas bien, conseguirás lo que quieras. En nuestro caso, se trataba de una tarea de traducción automática que ahora parece conservadora y entonces parecía muy atrevida. Ahora voy a mostrarles un poco de historia antigua que muchos de ustedes probablemente nunca han visto antes, y se llama la LSTM.
Para los que no estén familiarizados, el LSTM es el investigador pobre en aprendizaje profundo de la Transformador Lo que se hacía antes.
Es básicamente una ResNet, pero girada 90 grados, así que es una LSTM. Así que es un LSTM. un LSTM es como un ResNet ligeramente más complejo. se puede ver el integrador, que ahora se llama el flujo residual. pero usted tiene alguna multiplicación pasando. Es un poco complicado, pero eso es lo que estamos haciendo. Esta es una ResNet girada 90 grados. 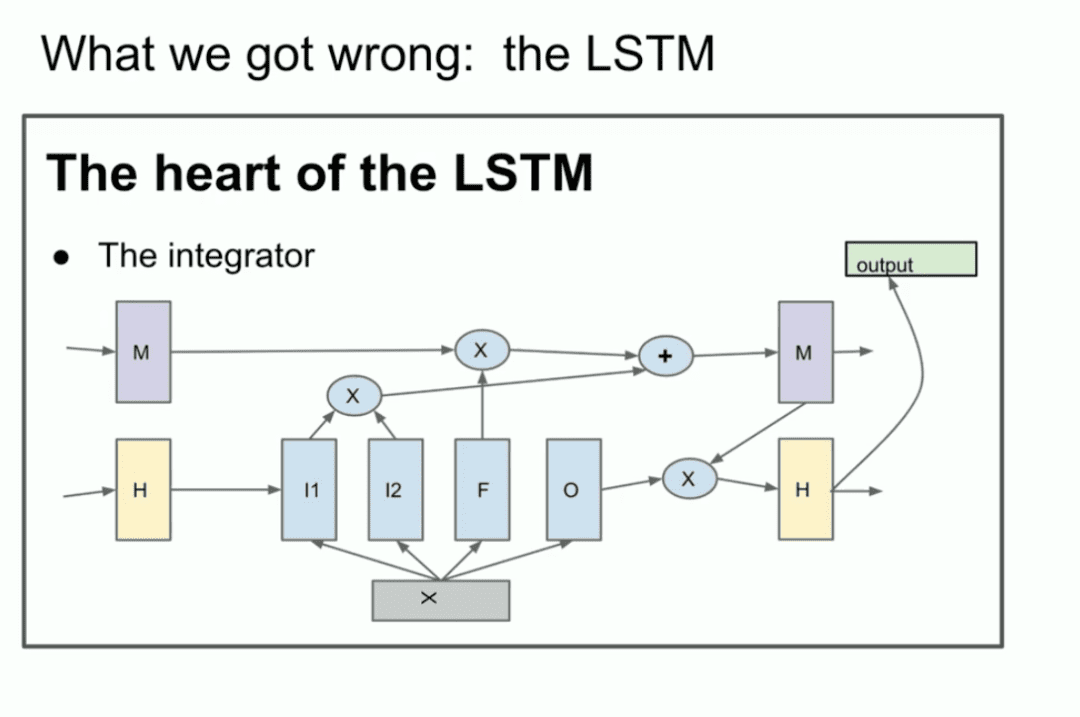
Otro punto clave que quería destacar en aquella antigua charla era que utilizábamos la paralelización, pero no sólo la paralelización.
Utilizamos pipelining, asignando una GPU por capa de la red neuronal, lo que, como sabemos ahora, no es una estrategia inteligente, pero no éramos muy listos en aquel momento. Así que la utilizamos y conseguimos ser 3,5 veces más rápidos con 8 GPU. 
La conclusión final, es la diapositiva más importante. Ilumina lo que podría ser el principio de las Leyes de Escalado. Si tienes un conjunto de datos muy grande y entrenas una red neuronal muy grande, el éxito está garantizado. Uno podría argumentar que si uno es generoso, eso es realmente lo que está sucediendo. 
Ahora quiero mencionar otra idea que creo que ha resistido el paso del tiempo. Es la idea central del aprendizaje profundo. Es la idea del conexionismo. La idea es que si usted cree que las neuronas artificiales son algo así como las neuronas biológicas. Si crees que una es un poco como la otra, entonces te da la confianza para creer en las redes neuronales a hiperescala. No necesitan ser realmente de la escala de un cerebro humano, podrían ser un poco más pequeñas, pero se pueden configurar para hacer prácticamente todo lo que hacemos.
Pero sigue habiendo una diferencia entre eso y los humanos, porque el cerebro humano averigua cómo reconfigurarse, y estamos utilizando los mejores algoritmos de aprendizaje que tenemos, lo que requiere tantos puntos de datos como parámetros. Los humanos lo hacen mucho mejor. Todo esto está orientado a lo que yo llamaría la era previa a la formación.
Todo esto está orientado a lo que yo llamaría la era previa a la formación.
Y luego tenemos lo que llamamos el modelo GPT-2, el modelo GPT-3, las Leyes de Escalado, y me gustaría hacer una mención especial a mi antiguo colaborador Alec Radford, así como a Jared Kaplan y Dario Amodei, cuyos esfuerzos hicieron posible todo este trabajo. 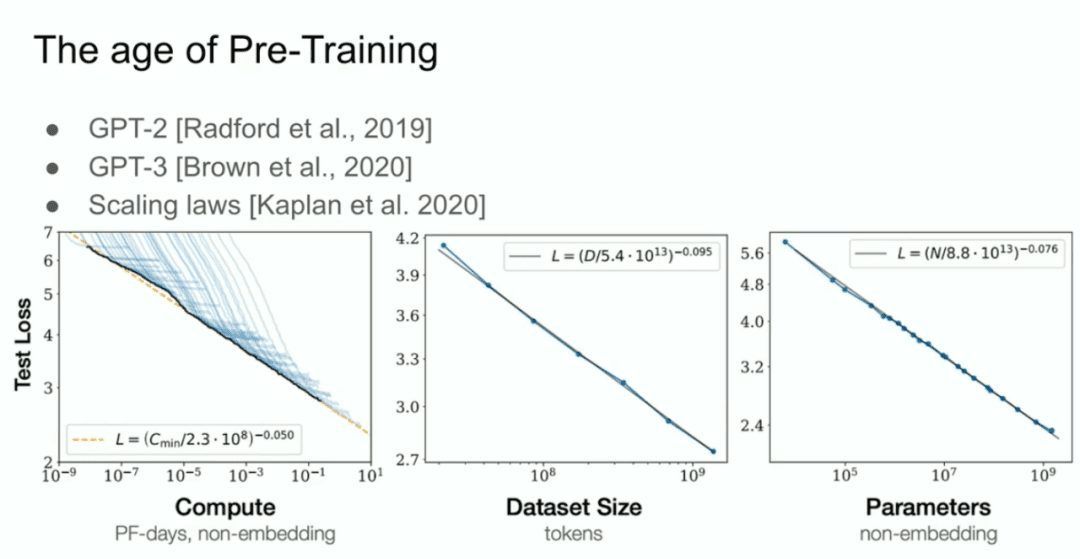 Esa es la era del preentrenamiento, y eso es lo que está impulsando todos los avances, todos los avances que estamos viendo hoy en día, mega-redes neuronales, mega-redes neuronales entrenadas en enormes conjuntos de datos.
Esa es la era del preentrenamiento, y eso es lo que está impulsando todos los avances, todos los avances que estamos viendo hoy en día, mega-redes neuronales, mega-redes neuronales entrenadas en enormes conjuntos de datos.
Pero el itinerario de formación previa, tal y como lo conocemos, llegará sin duda a su fin. ¿Por qué acabará? Porque los ordenadores siguen creciendo gracias a un mejor hardware, mejores algoritmos y grupos de lógica, y todas estas cosas siguen aumentando su potencia de cálculo, y los datos no crecen porque lo único que tenemos es Internet. 
Incluso se podría decir que los datos son el combustible fósil de la IA. Es como si hubieran sido creados de una determinada manera y ahora que los estamos utilizando, hemos maximizado el uso de los datos y no puede ser mejor. Averiguamos qué tenemos que hacer con los datos que tenemos ahora. Todavía voy a trabajar en eso, y eso todavía nos lleva bastante lejos, pero el problema es que sólo hay un Internet.
Así que aquí me aventuraré a especular sobre lo que ocurrirá a continuación. De hecho, ni siquiera necesito especular porque muchos otros están especulando también, y mencionaré sus especulaciones.
- Es posible que haya oído la frase "Agente del Cuerpo Inteligente", es bastante común y estoy seguro de que con el tiempo ocurrirá algo en lo que la gente sienta que los cuerpos inteligentes son el futuro.
- Más concretamente, aunque también de forma un tanto vaga, los datos sintéticos. Pero, ¿qué significa "datos sintéticos"? Averiguarlo es un gran reto, y estoy seguro de que diferentes personas están haciendo todo tipo de progresos interesantes en este sentido.
- También está el cómputo del tiempo de inferencia, o quizás más recientemente (OpenAI's) o1, el modelo o1 que más vívidamente demuestra a la gente tratando de averiguar qué hacer después del pre-entrenamiento.
Todas estas son cosas muy buenas. 
Quiero mencionar otro ejemplo de la biología que me parece realmente genial. Hace muchos años en esta conferencia también vi una presentación en la que alguien mostraba este gráfico que mostraba la relación entre el tamaño del cuerpo y el tamaño del cerebro en los mamíferos. En este caso, era enorme. En esa charla, lo recuerdo claramente, dijeron que en biología todo es confuso, pero aquí tienes un raro ejemplo de una relación muy fuerte entre el tamaño del cuerpo de un animal y su cerebro.
Por casualidad, sentí curiosidad por esta foto.  Así que fui a Google y busqué por imagen.
Así que fui a Google y busqué por imagen.
En este cuadro, se enumeran diversos mamíferos, así como no primates, pero en gran medida iguales, y primitivos. Por lo que sé, los primitivos eran parientes cercanos de los humanos en su evolución, como los neandertales. Por ejemplo, el "Hombre Energizado". Curiosamente, tienen diferentes pendientes del índice de relación cerebro-cuerpo. Muy interesante.
Esto significa que hay un caso, hay un caso en el que la biología figura algún tipo de escala diferente. Obviamente, algo es diferente. Por cierto, quiero hacer hincapié en que este eje x es una escala logarítmica. Esto es 100, 1.000, 10.000, 100.000, de nuevo en gramos, 1 gramo, 10 gramos, 100 gramos, un kilogramo. Así que es posible que las cosas sean diferentes.
Lo que estamos haciendo, lo que hemos estado haciendo hasta ahora en términos de escala, en realidad estamos descubriendo que la forma en que escalamos se convierte en la prioridad número uno. No hay duda en este espacio que todo el mundo que trabaja aquí va a averiguar qué hacer. Pero quiero hablar de ello aquí. Quiero tomarme unos minutos para hacer una proyección a largo plazo, algo a lo que todos nos enfrentamos, ¿verdad?  Todo el progreso que estamos haciendo es un progreso asombroso. Quiero decir, la gente que trabajaba en este campo hace 10 años, recordáis lo impotente que era todo. Si te has incorporado al campo del aprendizaje profundo en los últimos dos años, probablemente ni siquiera puedas relacionarlo.
Todo el progreso que estamos haciendo es un progreso asombroso. Quiero decir, la gente que trabajaba en este campo hace 10 años, recordáis lo impotente que era todo. Si te has incorporado al campo del aprendizaje profundo en los últimos dos años, probablemente ni siquiera puedas relacionarlo.
Quiero hablar un poco de la "superinteligencia" porque es claramente hacia donde se dirige el campo y lo que intenta construir.
Aunque los modelos lingüísticos tienen ahora mismo unas capacidades increíbles, también son un poco poco poco fiables. No está claro cómo conciliar esto, pero al final, tarde o temprano, el objetivo se hará realidad: estos sistemas se convertirán en inteligencias de forma real. Ahora mismo, estos sistemas no son inteligencias perceptivas potentes y significativas; de hecho, apenas están empezando a razonar. Por cierto, cuanto más razona un sistema, más imprevisible se vuelve.
Estamos acostumbrados a que todo el aprendizaje profundo sea muy predecible. Porque si has estado trabajando en replicar la intuición humana, volviendo a un tiempo de reacción de 0,1 segundos, ¿qué tipo de procesamiento hace nuestro cerebro? Eso es intuición, y hemos dado a AIS algo de esa intuición.
Pero el razonamiento, se ven algunas señales tempranas de que el razonamiento es impredecible. El ajedrez, por ejemplo, es impredecible para los mejores jugadores humanos. Así que vamos a tener que lidiar con sistemas de IA muy impredecibles. Entenderán cosas a partir de datos limitados y no se confundirán.
Todo esto es muy limitante. Por cierto, no he dicho cómo ni cuándo sucederían todas estas cosas con la "autoconciencia", porque ¿por qué no iba a ser útil la "autoconciencia"? Nosotros mismos formamos parte del modelo de nuestro propio mundo.
Cuando todas estas cosas confluyan, tendremos sistemas con cualidades y atributos completamente distintos de los que existen hoy en día. Por supuesto, tendrán capacidades increíbles y asombrosas. Pero el problema de un sistema así es que sospecho que será muy diferente.
Yo diría que predecir el futuro también es ciertamente imposible. En realidad, todo tipo de cosas son posibles. Gracias a todos.
Tras una ronda de aplausos en la conferencia Neurlps, Ilya respondió a unas breves preguntas de varios asistentes.
P: En 2024, ¿existen otras estructuras biológicas relevantes para la cognición humana que crea que merece la pena explorar de forma similar, o hay algún otro campo que le interese?
Ilya:Yo respondería a la pregunta de la siguiente manera: si usted o alguien tiene una idea sobre un problema concreto, como "oye, es evidente que ignoramos que el cerebro está haciendo algo, y no lo estamos haciendo", y es factible, entonces debería profundizar en esa dirección. Personalmente, no tengo esa percepción. Por supuesto, también depende del nivel de abstracción de la investigación en la que te centres. Mucha gente aspira a desarrollar una IA de inspiración biológica. En cierto modo, se podría argumentar que la IA biológicamente inspirada ha sido un gran éxito -después de todo, toda la base del aprendizaje profundo es la IA biológicamente inspirada. pero, por otro lado, esa inspiración biológica es en realidad muy, muy limitada. Básicamente se trata de "usemos neuronas", eso es todo lo que es la bioinspiración. Niveles más detallados y profundos de bioinspiración son más difíciles de conseguir, pero yo no lo descartaría. Creo que sería muy valioso que alguien con una visión especial descubriera algún ángulo nuevo. P: Me gustaría hacer una pregunta sobre la autocorrección.
Usted ha mencionado que la inferencia puede ser una de las principales direcciones de desarrollo de los modelos en el futuro y puede ser una característica diferenciadora. En algunas de las sesiones de presentación de carteles hemos visto que existe una "ilusión" de los modelos actuales. Nuestro método actual para analizar si los modelos alucinan (por favor, corríjame si lo he entendido mal, usted es el experto en este tema) se basa principalmente en análisis estadísticos, por ejemplo, determinar si hay una desviación de la media por alguna desviación de la desviación estándar. En el futuro, ¿cree que si el modelo tiene la capacidad de razonar, podrá autocorregirse como la autocorrección y convertirse así en una característica esencial de los futuros modelos? De ese modo, el modelo no tendría tantas alucinaciones porque sería capaz de reconocer las situaciones en las que genera su propio contenido alucinatorio. Quizá sea una pregunta más compleja, pero ¿cree que los futuros modelos serán capaces de comprender y detectar la aparición de alucinaciones mediante el razonamiento?
Ilya:Respuesta: Sí.
Creo que la situación que describes es muy probable. Aunque no estoy seguro, le sugiero que lo compruebe, y es posible que este escenario ya se haya dado en algunos modelos primitivos de razonamiento. Pero a la larga, ¿por qué no iba a ser posible?
P: Es como la función de autocorrección de Microsoft Word, es una función básica.
Ilya:Sí, es que creo que llamarlo "autocorrección" es quedarse un poco corto. Cuando se menciona "autocorrección", se evocan imágenes de funciones relativamente sencillas, pero el concepto va mucho más allá de la autocorrección. En general, la respuesta es sí.
PREGUNTA: Gracias. El siguiente es el segundo interrogador.
P: Hola, Ilya. Me ha gustado mucho el final con el misterioso apagón blanco. ¿Nos sustituirán las IA, o son superiores a nosotros? ¿Necesitan derechos? Es una especie completamente nueva. El Homo sapiens dio a luz a esta inteligencia, y creo que la gente de Reinforcement Learning podría pensar que necesitamos derechos para estos seres.
Tengo una pregunta no relacionada: ¿cómo podemos crear los incentivos adecuados para que los seres humanos los creen de forma que puedan disfrutar de las mismas libertades de las que disfrutamos los Homo sapiens?
Ilya:Creo que en cierto sentido son cuestiones sobre las que la gente debería pensar y reflexionar más. Pero a tu pregunta sobre qué tipo de incentivos deberíamos crear, no creo que pueda responder con seguridad a una pregunta así. Parece que estemos hablando de crear algún tipo de estructura descendente o modelo de gobernanza, pero no estoy muy seguro de ello.
El siguiente es el último interrogador.
P: Hola Ilya, gracias por esta magnífica presentación. Soy de la Universidad de Toronto. Gracias por todo el trabajo que has realizado. Me gustaría preguntarle si cree que los LLM son capaces de generalizar la inferencia multisalto fuera de la distribución.
Ilya:De acuerdo, esta pregunta supone que la respuesta es "sí" o "no", pero en realidad no debería responderse así. Porque primero tenemos que averiguar: ¿qué significa realmente generalización intradistributiva? ¿Qué es intradistributivo? ¿Qué es fuera de distribución? Porque aquí se habla de "prueba del tiempo". Yo diría que hace mucho, mucho tiempo, antes del aprendizaje profundo, la gente utilizaba la concordancia de cadenas y los n-gramas para hacer traducción automática. Por aquel entonces, la gente se basaba en tablas estadísticas de frases. ¿Te lo imaginas? Estos métodos tenían una complejidad de decenas de miles de líneas de código, una complejidad realmente inimaginable. Y en aquella época, la generalización se definía como si el resultado de la traducción no era literalmente idéntico a la representación de la frase en el conjunto de datos. Ahora podríamos decir: "Mi modelo obtuvo una puntuación alta en un concurso de matemáticas, pero quizá algunas de las ideas para estas preguntas de matemáticas se discutieron en algún foro de Internet en algún momento, por lo que el modelo podría simplemente haberlas recordado". Bueno, se podría argumentar que esto podría estar dentro de la distribución, o podría ser el resultado de la memorización. Pero creo que es cierto que nuestros estándares de generalización han aumentado drásticamente, incluso se podría decir que de forma significativa e inconcebible.
Así que mi respuesta es: hasta cierto punto, los modelos probablemente no sean tan buenos generalizando como los humanos. Creo que los humanos son mucho mejores generalizando. Pero al mismo tiempo, también es cierto que los modelos de IA son capaces de generalizar fuera de la distribución hasta cierto punto. Espero que esta respuesta te resulte útil, aunque suene un poco redundante.
P: Gracias.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...