Reedición de Hybrid-T1: compatible con Mamba, redefine la velocidad de inferencia

Recientemente, el campo de la modelización lingüística a gran escala ha recibido una atención cada vez mayor por parte de la industria en busca de nuevos paradigmas de aprendizaje por refuerzo en las últimas fases del entrenamiento. Tras la introducción de modelos de la serie O como el GPT-4o de OpenAI y el DeepSeek-R1 del comunicado, el excelente rendimiento del modelo demuestra el papel clave del aprendizaje por refuerzo en el proceso de optimización.
El equipo del Modelo Meta Mixto de Tencent también ha realizado avances significativos recientemente. A mediados de febrero de este año, el equipo lanzó el modelo de inferencia Mixed Yuan T1-Preview basado en una base Mixed Yuan de tamaño medio en la APP Tencent Yuanbao. Ahora, el modelo Deep Thinking de la serie Mixed Meta Model se ha actualizado a la versión oficial Mixed Meta-T1.
Dirección de la experiencia:
https://llm.hunyuan.tencent.com/#/chat/hy-t1
https://huggingface.co/spaces/tencent/Hunyuan-T1
La Hybrid-T1 se basa en la versión de principios de marzo del TurboS Rapid Thinking Base.TurboS es el primer Modelo Mixto de Experiencia (MdE) a hiperescala del mundo, que incorpora la Transformador y Mamba. Con el post-entrenamiento a gran escala, las capacidades de inferencia de Mamba-T1 se amplían significativamente y se alinean mejor con las preferencias humanas.
Hybrid-T1 tiene ventajas únicas en el razonamiento profundo. En primer lugar, la capacidad de captura de textos largos de TurboS ayuda a resolver eficazmente los problemas habituales de pérdida de contexto y dependencia de información remota en la inferencia de textos largos. En segundo lugar, la arquitectura Mamba está optimizada específicamente para secuencias largas y reduce significativamente el consumo de recursos computacionales mediante métodos computacionales eficientes, al tiempo que garantiza la capacidad de capturar información textual larga. En las mismas condiciones de despliegue, la velocidad de descodificación se multiplica por 2.
En la fase posterior de entrenamiento del modelo, 96,7% de los recursos computacionales se invierten en el entrenamiento del aprendizaje por refuerzo, centrándose en mejorar la inferencia pura y optimizar la alineación con las preferencias humanas.
Para lograr este objetivo, el equipo de investigación recopiló problemas científicos y de razonamiento de categoría mundial que abarcaban los campos de las matemáticas, el razonamiento lógico, la ciencia y el código. Estos conjuntos de datos abarcan una amplia gama de tareas, desde el razonamiento matemático básico hasta la resolución de problemas científicos complejos. Esto, combinado con una retroalimentación real (ground-truth), garantiza que el modelo funcione bien ante una amplia gama de tareas de razonamiento.
El entrenamiento se realizó utilizando un enfoque de aprendizaje curricular (CLE), que aumenta progresivamente la dificultad de los datos al tiempo que amplía progresivamente la longitud del contexto del modelo, de modo que éste aprende a utilizar eficazmente la capacidad de razonamiento al tiempo que mejora la ficha Razonamiento.
En cuanto a las estrategias de entrenamiento, se toman prestadas estrategias clásicas de aprendizaje por refuerzo, como la repetición de datos y el restablecimiento periódico de políticas, para mejorar la estabilidad a largo plazo del entrenamiento del modelo en más de 50%. En la fase de alineación con las preferencias humanas, se utiliza un esquema unificado de retroalimentación del sistema de recompensa, que incluye modos de autorrecompensa (evaluación y puntuación exhaustivas de los resultados del modelo basadas en una versión anterior de T1-Preview) y recompensa, para guiar al modelo hacia la autorrecompensa. Los modelos muestran un contenido más rico en detalles e información más eficiente en sus respuestas.
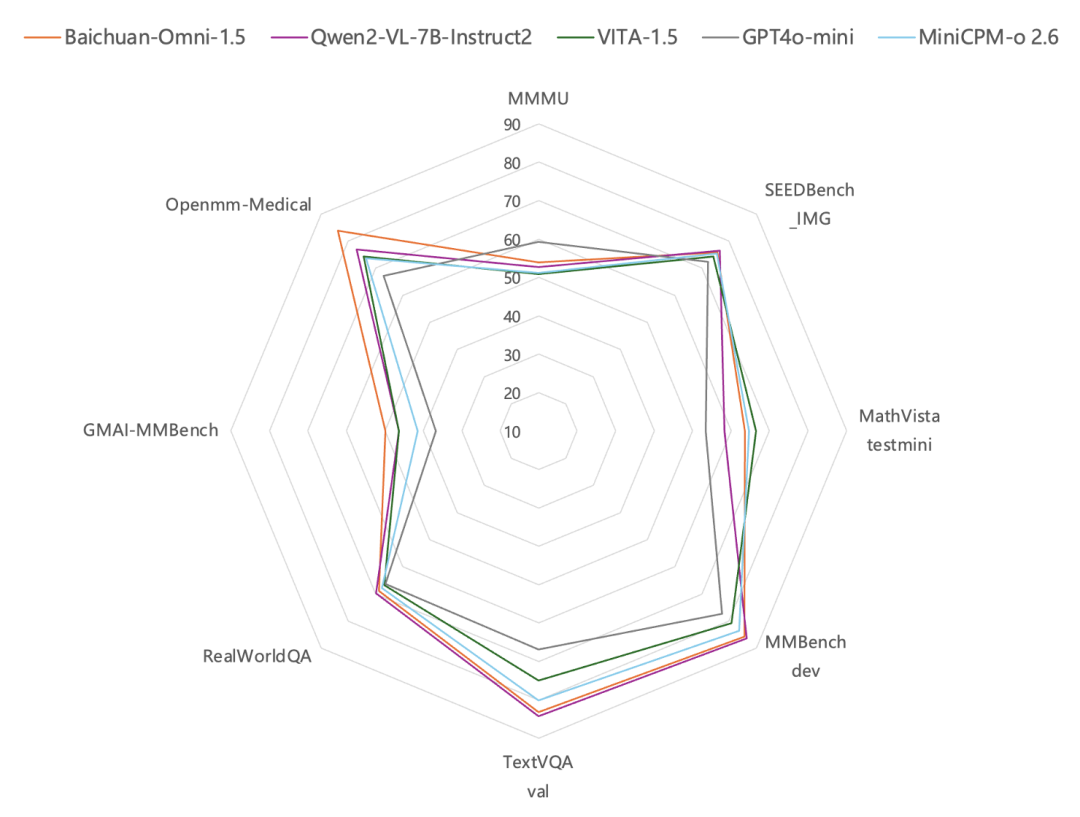
Además de obtener resultados comparables o ligeramente mejores que DeepSeek-R1 en pruebas públicas de referencia de conocimientos de chino e inglés, matemáticas y razonamiento lógico a nivel de competición como MMLU-pro, CEval, AIME, Zebra Logic y otras, Mixed Elements-T1 también obtiene buenos resultados en conjuntos de datos internos de evaluación humana, con ligeras ventajas en el seguimiento de instrucciones culturales y creativas, el resumen de textos y la competencia smart-body. .
En cuanto a las métricas de evaluación global, el rendimiento general del Híbrido-T1 es comparable al de un modelo de inferencia de frontera de primera clase. En la evaluación exhaustiva de la capacidad, el T1 se sitúa en MMLU-PRO Sólo superado por O1 en la lista, ganando 87.2 de altas puntuaciones. El conjunto de pruebas abarca preguntas de 14 áreas de las humanidades, las ciencias sociales, las ciencias y la ingeniería, y se centra en poner a prueba la memoria y la comprensión del modelo de una amplia gama de conocimientos. Además, al centrarse en conocimientos especializados y razonamientos científicos complejos GPQA-diamante(T1 ha logrado los siguientes resultados (principalmente problemas de nivel de doctorado en física, química y biología) 69.3 El resultado.
Los escenarios que requerían grandes capacidades de razonamiento, como la codificación, las matemáticas y el razonamiento lógico, se probaron en ciencias e ingeniería. En el LiveCodeBench En la evaluación del código, T1 alcanzó 64.9 Puntuación. Mientras tanto, T1 destacó en matemáticas. Especialmente en MATH-500 Además de eso, hizo 96.2 Los excelentes resultados, tras DeepSeek-R1, demostraron la capacidad integral de T1 para resolver problemas matemáticos. Además, T1 demostró una gran capacidad de adaptación en tareas de alineación múltiple, tareas de seguimiento de órdenes y tareas de utilización de herramientas. Por ejemplo, T1 obtuvo buenos resultados en la prueba ArenaHard La misión fue galardonada con el 91.9 El resultado.
efecto de modelización


Nota: Los indicadores de evaluación de los demás modelos de la tabla proceden de los resultados oficiales de evaluación. En el caso de las piezas que no figuran en los resultados de la evaluación oficial, los datos proceden de la plataforma de evaluación interna de Hybrid.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Puestos relacionados



Sin comentarios...