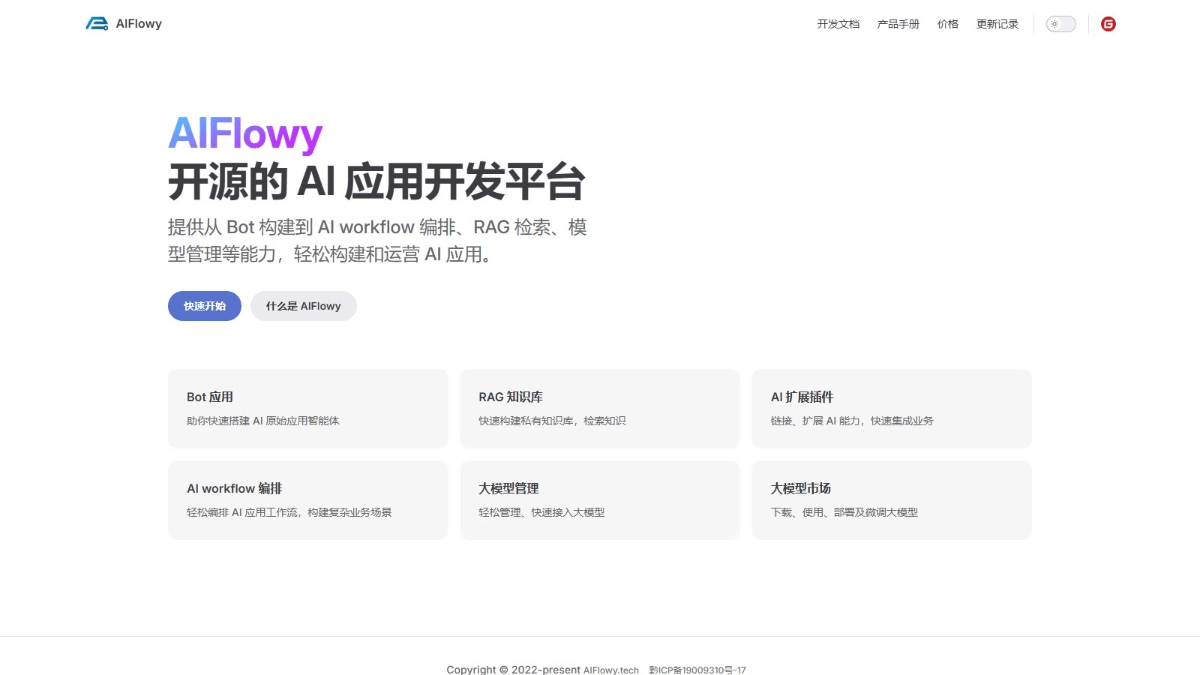
Gemini 3.1 Flash-Lite - Google推出的最轻量、最具性价比的模型
Últimos recursos sobre IAPublicado hace 3 semanas Círculo de intercambio de inteligencia artificial 17K 00

Gemini 3.1 Flash-Lite是什么
Géminis 3.1 Flash-Lite 是 Google 发布的 Gemini 3 系列中最轻量、最具性价比的模型,主打极致速度与低成本。模型从 Gemini 3 Pro 蒸馏而来,输入价格仅 $0.25/百万 token,输出速度达 363 tokens/秒,比前代快 45%,首 ficha 响应速度提升 2.5 倍。支持 100 万 token 超长上下文,可处理文本、图像、音频、视频多模态输入,提供 Minimal 到 High 四档可调推理强度。专为高频翻译、内容审核、实时 UI 生成、AI Agent 路由等大规模调用场景设计,是开发者构建高吞吐量 AI 应用的理想选择。

Gemini 3.1 Flash-Lite的功能特色
- 极致性价比:输入价格仅 $0.25/百万 token,输出 $1.50/百万 token,是 Gemini 系列中最便宜的模型。
- 超快响应速度:输出速度达 363 tokens/秒,首 token 响应比 2.5 Flash 快 2.5 倍。
- Ventana contextual extralarga:支持 100 万 token 上下文,单次可处理 3,000 张图片或 45 分钟视频。
- 四档可调推理:支持 Minimal、Low、Medium、High 四个思考深度档位,按需灵活调节。
- Entradas multimodales:支持文本、图像、音频、视频多种输入格式。
- 函数调用能力:支持结构化输出和 Google 搜索接入,便于构建 Agent 应用。
- caché contextual (informática):支持缓存机制,降低高频重复调用成本。
- 高输出上限:单次最多可输出 64,000 tokens,满足长文本生成需求。
Gemini 3.1 Flash-Lite的核心优势
- 成本最低:输入价格仅 $0.25/百万 token,为 Gemini 系列中定价最低的模型,适合大规模高频调用场景。
- 速度最快:输出速度 363 tokens/秒,比 2.5 Flash 快 45%,首 token 响应快 2.5 倍,延迟极低。
- Ligero y eficaz:从 Gemini 3 Pro 蒸馏而来,继承大模型能力的同时通过模型压缩实现极致轻量化。
- 灵活可控:四档思考级别(Minimal/Low/Medium/High)可动态调节,平衡质量与成本。
- 多模态兼容:支持文本、图像、音频、视频统一处理,单次可分析 3,000 张图或 45 分钟视频。
- 超长上下文:100 万 token 上下文窗口 + 64,000 token 输出上限,胜任长文档和视频分析。
- Integración empresarial:支持函数调用、Google 搜索、上下文缓存,无缝对接 Vertex AI 和 AI Studio。
Gemini 3.1 Flash-Lite官网是什么
- Página web del proyecto:https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-lite/
Gemini 3.1 Flash-Lite的适用人群
- 高频调用开发者:需要大规模 API 调用且对成本敏感的开发者,如翻译、审核类应用。
- 实时应用构建者:追求低延迟响应的实时仪表盘、聊天机器人、UI 生成工具开发者。
- AI Agent 开发者:需要快速路由分发任务、构建多 Agent 系统的工程师。
- 电商运营团队:需批量生成商品描述、产品页面内容的运营人员。
- SaaS 产品经理:希望为产品集成 AI 自动化工作流,降低多步骤业务处理成本的产品团队。
- 内容平台运营者:需要高频内容审核、标签生成、摘要提取的内容平台。
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...