
RAG avanzada: arquitectura, tecnología, aplicaciones y perspectivas de desarrollo

La generación aumentada por recuperación (RAG, por sus siglas en inglés) se ha convertido en un marco importante en el campo de la IA, que mejora enormemente la precisión y relevancia de los grandes modelos lingüísticos (LLM, por sus siglas en inglés) a la hora de generar respuestas utilizando fuentes de conocimiento externas. Según Databricks Los datos muestran que 60% de las aplicaciones LLM en la empresa utilizan la Generación Aumentada de Recuperación (RAG), y 30% utilizan un proceso de varios pasos. Mejora de la precisión del 43%Demuestra que el RAG gran potencial para mejorar la calidad y fiabilidad de los contenidos generados por IA.
Sin embargo, los enfoques tradicionales de las GAR siguen enfrentándose a una serie de retos a la hora de responder a consultas complejas, comprender contextos matizados y manejar múltiples tipos de datos. Estas limitaciones han impulsado la creación de GAR avanzadas destinadas a mejorar las capacidades de la IA en la recuperación y generación de información. En particular.número de empresas El GAR se ha integrado en aproximadamente 601 productosTP3T, lo que demuestra su importancia y eficacia en aplicaciones prácticas.
Uno de los mayores avances en este campo ha sido la introducción de los GAR multimodales y los grafos de conocimiento. Los GAR multimodales amplían la capacidad de los GAR para procesar no sólo texto, sino también una amplia gama de datos, como imágenes, audio y vídeo. Esto permite a los sistemas de IA ser más completos y tener una mayor comprensión contextual al interactuar con los usuarios. Los grafos de conocimiento, por su parte, mejoran la coherencia y precisión del proceso de recuperación de información y el contenido generado mediante la representación estructurada del conocimiento.Investigación de Microsoft sugiere que el GraphRAG requerido Ficha El número se reduce de 26% a 97% con respecto a otros métodos, lo que demuestra una mayor eficiencia y un menor coste computacional.
Estos avances en la tecnología RAG se han traducido en importantes mejoras de rendimiento en varias pruebas comparativas y aplicaciones del mundo real. Por ejemplo.mapa del conocimiento alcanzó una precisión de 86,31% en la prueba RobustQA, lo que supera ampliamente a otros métodos RAG. Además, elSequeda y Allemang El estudio de seguimiento de la Comisión descubrió que la combinación de ontologías reducía la tasa de error 20%. Las empresas también se han beneficiado mucho de estos avances, elLinkedIn informó de una reducción de 28,61 TP3T en el tiempo de resolución de la asistencia al cliente mediante un enfoque de RAG más gráfico de conocimiento.
En este artículo nos adentraremos en la evolución de las RAG avanzadas, explorando la complejidad de las RAG multimodales y las RAG de grafos de conocimiento y su eficacia para mejorar la recuperación y generación de información impulsada por la IA. También analizaremos el potencial de estas innovaciones para ser aplicadas en diferentes industrias y los retos a los que se enfrentan la promoción y aplicación de estas tecnologías.
- [¿Qué es la Generación Aumentada por Recuperación (RAG) y por qué es importante para la Modelización de Grandes Lenguajes (LLM)?
- [Tipos de arquitectura RAG]
- [De la GAR básica a la GAR avanzada: cómo superar las limitaciones y mejorar las capacidades].
- [Componentes y procesos avanzados del sistema GAR en la empresa].
- [Tecnología RAG avanzada]
- [Aplicaciones avanzadas del GAR y casos prácticos]
- [¿Cómo construir herramientas de diálogo con GAR avanzadas?]
- [¿Cómo puedo crear una aplicación RAG avanzada?]
- [El auge de los grafos de conocimiento en la RAG avanzada].
- [RAG avanzada: generación mejorada de horizontes ampliados mediante recuperación multimodal].
- [Cómo la plataforma de colaboración GenAI de LeewayHertz, ZBrain, destaca entre los sistemas RAG avanzados].
RAG Avanzado: Arquitectura, Tecnología, Aplicaciones y Perspectivas de Desarrollo PDF Download:
RAG avanzada: arquitectura, tecnología, aplicaciones y perspectivas de desarrollo
¿Qué es la Generación Aumentada por Recuperación (RAG) y por qué es importante para la Modelización de Grandes Lenguajes (LLM)?
Los grandes modelos lingüísticos (LLM, por sus siglas en inglés) se han convertido en un elemento central de las aplicaciones de IA, que confían en su potencia para todo, desde asistentes virtuales hasta sofisticadas herramientas de análisis de datos. Pero a pesar de sus capacidades, estos modelos tienen limitaciones a la hora de proporcionar información actualizada y precisa. Aquí es donde la Generación Aumentada de Recuperación (RAG) proporciona un potente complemento a los LLM.
¿Qué es la Generación Aumentada de Recuperación (RAG)?
La Generación Aumentada de Recuperación (RAG) es una técnica avanzada que mejora las capacidades generativas de los Modelos de Lenguaje de Gran Tamaño (LLM) mediante la integración de fuentes de conocimiento externas. Los LLM se entrenan en grandes conjuntos de datos, con miles de millones de parámetros, y son capaces de realizar una amplia gama de tareas, como responder preguntas, traducción lingüística y completar textos.Los RAG van un paso más allá al hacer referencia a bases de conocimiento autorizadas y específicas del dominio para mejorar la relevancia, precisión y utilidad del contenido generado sin necesidad de volver a entrenar el modelo. Las GAR van un paso más allá al referenciar bases de conocimiento autorizadas y específicas del dominio para mejorar la relevancia, precisión y utilidad de los contenidos generados sin necesidad de volver a entrenar el modelo. Este enfoque rentable y eficaz es ideal para las empresas que desean optimizar sus sistemas de IA.
¿Cómo puede la Generación Aumentada de Recuperación (RAG) ayudar a la Modelización de Grandes Lenguajes (LLM) a resolver el problema central?
Los grandes modelos lingüísticos (LLM) desempeñan un papel clave en el impulso de los chatbots inteligentes y otras aplicaciones de procesamiento del lenguaje natural (PLN). Mediante un entrenamiento exhaustivo, intentan ofrecer respuestas precisas en diversos contextos. Sin embargo, los propios LLM presentan algunas deficiencias y se enfrentan a múltiples retos:
- mensaje de error: Se pueden generar respuestas imprecisas cuando los conocimientos de LLM son insuficientes.
- información obsoletaLos datos de entrenamiento son estáticos, por lo que las respuestas generadas por el modelo pueden estar desfasadas.
- fuente no autorizadaLas respuestas generadas a veces proceden de fuentes poco fiables, lo que afecta a la credibilidad.
- confusión terminológicaEl uso incoherente de la misma terminología por distintas fuentes de datos puede dar lugar fácilmente a malentendidos.
El GAR aborda estos problemas proporcionando al LLM una fuente externa de datos fidedignos para mejorar la precisión y la naturaleza en tiempo real de las respuestas del modelo. Los siguientes puntos explican por qué el GAR es tan importante para el desarrollo del LLM:
- Mejorar la precisión y la pertinenciaRAG extrae la información más actualizada y relevante de fuentes autorizadas para garantizar que las respuestas del modelo sean más precisas y pertinentes en el contexto actual, ya que los datos de entrenamiento son estáticos.
- Superar los límites de los datos estáticosEl GAR permite a LLM acceder a los datos más recientes, lo que mantiene la información actualizada y pertinente.
- Aumentar la confianza de los usuariosEl LLM puede generar las llamadas "ilusiones" -respuestas seguras pero incorrectas- y el GAR aumenta la transparencia y la confianza de los usuarios al permitir que el LLM cite las fuentes y proporcione información verificable.
- ahorro de costesLa RAG ofrece una alternativa más rentable al reentrenamiento del LLM con nuevos datos, lo que supone una alternativa rentable al reentrenamiento de todo el modelo utilizando fuentes de datos externas, haciendo que las técnicas avanzadas de IA estén más ampliamente disponibles.
- Mayor control y flexibilidad para los desarrolladores: RAG ofrece a los desarrolladores más libertad para especificar con flexibilidad las fuentes de conocimiento, adaptarse rápidamente a los cambios en los requisitos y garantizar el tratamiento adecuado de la información sensible para dar soporte a una amplia gama de aplicaciones y mejorar la eficacia de los sistemas de IA.
- Respuestas personalizadasMientras que los LLM tradicionales tienden a dar respuestas demasiado generales, RAG combina los LLM con las bases de datos internas de la organización, la información sobre productos y los manuales de usuario para ofrecer respuestas más específicas y pertinentes, mejorando drásticamente la experiencia de atención e interacción con el cliente.
RAG (Retrieval Augmented Generation) permite a LLM generar respuestas más precisas, contextualizadas y en tiempo real mediante la integración con bases de conocimiento externas. Esto es vital para las organizaciones que dependen de la IA, desde el servicio de atención al cliente hasta el análisis de datos, RAG no solo mejora la eficiencia, sino que también aumenta la confianza de los usuarios en los sistemas de IA.
Tipos de arquitectura RAG
La Generación Aumentada por Recuperación (RAG) representa un gran avance en la tecnología de la IA, ya que combina modelos lingüísticos con sistemas externos de recuperación de conocimientos. Este enfoque híbrido mejora la capacidad de generación de respuestas de IA al obtener información detallada y relevante de grandes fuentes de datos externas. Comprender los distintos tipos de arquitecturas RAG nos ayuda a aprovechar mejor sus ventajas en función de nuestras necesidades específicas. A continuación analizamos en profundidad las tres principales arquitecturas GAR:
1. GAR ingenuo
La RAG ingenua es el método más básico de generación de mejoras de recuperación. Su principio es sencillo: el sistema extrae fragmentos de información relevantes de la base de conocimientos a partir de la consulta del usuario y, a continuación, utiliza estos fragmentos de información como contexto para generar la respuesta mediante el modelado del lenguaje.
Características:
- mecanismo de recuperación: Se utiliza un método sencillo de recuperación para extraer bloques de documentos relevantes de un índice preestablecido, normalmente mediante la concordancia de palabras clave o la similitud semántica básica.
- integración contextualLos documentos recuperados se fusionan con la consulta del usuario y se introducen en el modelo lingüístico para generar una respuesta. Esta fusión proporciona un contexto más rico para que el modelo genere respuestas más pertinentes.
- flujo de procesamientoEl sistema sigue un proceso fijo: recuperar, empalmar, generar. El modelo no modifica la información extraída, sino que la utiliza directamente para generar respuestas.
2. RAG avanzado
La GAR avanzada se basa en la GAR ingenua y utiliza técnicas más avanzadas para mejorar la precisión de la recuperación y la relevancia contextual. Supera algunas de las limitaciones de la GAR ingenua combinando mecanismos avanzados para procesar y utilizar mejor la información contextual.
Características:
- Recuperación mejoradaMejora de la calidad y la pertinencia de la información recuperada mediante estrategias de búsqueda avanzadas, como la ampliación de la consulta (adición de términos pertinentes a la consulta inicial) y la búsqueda iterativa (optimización de documentos en varias etapas).
- Optimización del contextoLa concentración selectiva en las partes más relevantes del contexto mediante técnicas como el mecanismo de atención ayuda al modelo lingüístico a generar respuestas más exactas y contextualmente más precisas.
- estrategia de optimizaciónSe utilizan estrategias de optimización como la puntuación de relevancia y la mejora contextual para garantizar que el modelo capta la información más relevante y de mayor calidad para generar respuestas.
3. GAR Modular
La GAR modular es la arquitectura de GAR más flexible y personalizable. Desglosa el proceso de recuperación y generación en módulos independientes, lo que permite optimizarlo y sustituirlo en función de las necesidades de aplicaciones específicas.
Características:
- Diseño modularDescomponer el proceso RAG en distintos módulos, como la expansión de la consulta, la recuperación, la reordenación y la generación. Cada módulo puede optimizarse de forma independiente y sustituirse bajo demanda.
- Personalización flexiblePermite un alto grado de personalización, ya que los desarrolladores pueden probar distintas configuraciones y técnicas en cada paso para encontrar la mejor solución. La metodología ofrece soluciones personalizadas para una gran variedad de escenarios de aplicación.
- Integración y adaptaciónLa arquitectura es capaz de integrar funcionalidades adicionales, como un módulo de memoria (para registrar interacciones pasadas) o un módulo de búsqueda (para extraer datos de motores de búsqueda o grafos de conocimiento). Esta adaptabilidad permite adecuar con flexibilidad el sistema RAG a necesidades específicas.
Comprender estos tipos y características es fundamental para seleccionar y aplicar la arquitectura GAR más adecuada.
De la GAR básica a la avanzada: superar las limitaciones y mejorar las capacidades
La generación aumentada por recuperación (RAG) se utiliza en la Procesamiento del lenguaje natural (PLN) Se ha convertido en un método muy eficaz para combinar la recuperación de información y la generación de textos con el fin de producir resultados más precisos y contextualizados. Sin embargo, a medida que la tecnología ha ido evolucionando, los primeros sistemas "básicos" de GAR han revelado algunos defectos, lo que ha propiciado la aparición de versiones más avanzadas. La evolución de la GAR básica a la avanzada significa que estamos superando gradualmente estos defectos y mejorando considerablemente las capacidades generales del sistema GAR.
Limitaciones del GAR básico

El marco RAG subyacente es un primer intento de combinar recuperación y generación para la PNL. Aunque este planteamiento es innovador, sigue presentando algunas limitaciones:
- Métodos de búsqueda sencillosLa mayoría de los sistemas básicos de GAR se basan en la simple concordancia de palabras clave, un enfoque que dificulta la comprensión de los matices y el contexto de la consulta y, por tanto, recupera información insuficiente o parcialmente relevante.
- Dificultad para comprender el contextoEl sistema RAG: es difícil que estos sistemas comprendan correctamente el contexto de la consulta de un usuario. Por ejemplo, el sistema RAG subyacente puede recuperar documentos que contengan las palabras clave de una consulta, pero no logra captar la verdadera intención o el contexto del usuario, por lo que no consigue satisfacer con precisión sus necesidades.
- Capacidad limitada para manejar consultas complejasRecomendación: Los sistemas RAG básicos funcionan mal cuando se enfrentan a consultas complejas o de varios pasos. Sus limitaciones en la comprensión del contexto y la recuperación precisa dificultan la gestión eficaz de problemas complejos.
- Base de conocimientos estáticaEl sistema GAR subyacente se basa en una base de conocimientos estática y carece de un mecanismo de actualización dinámica; la información puede quedar obsoleta con el tiempo, lo que afecta a la precisión y pertinencia de la respuesta.
- Falta de optimización iterativaLa GAR subyacente carece de un mecanismo de optimización basado en la retroalimentación, no puede mejorar el rendimiento mediante el aprendizaje iterativo y se estanca con el tiempo.
Transición a RAG avanzado
A medida que la tecnología ha ido evolucionando, han aparecido soluciones más sofisticadas para subsanar las deficiencias de los sistemas básicos de GAR. Los sistemas avanzados de GAR superan estos retos de varias maneras:
- Algoritmos de búsqueda más complejosLos sistemas RAG avanzados utilizan técnicas sofisticadas, como la búsqueda semántica y la comprensión contextual, que pueden ir más allá de la concordancia de palabras clave para comprender el significado real de una consulta y mejorar así la pertinencia de los resultados recuperados.
- Integración contextual mejoradaEstos sistemas incorporan ponderaciones de contexto y relevancia para integrar los resultados de la recuperación y garantizar que no sólo la información sea precisa, sino también adecuada al contexto y responda mejor a la consulta y la intención del usuario.
- Optimización iterativa y mecanismos de retroalimentación::
El sistema Advanced RAG emplea un proceso de optimización iterativo que mejora continuamente la precisión y la pertinencia a lo largo del tiempo incorporando los comentarios de los usuarios. - Actualización dinámica de los conocimientos::
El avanzado sistema RAG es capaz de actualizar dinámicamente la base de conocimientos, introduciendo continuamente la información más reciente y garantizando que el sistema refleje siempre las últimas tendencias y novedades. - Comprensión contextual compleja::
Aprovechando técnicas de PNL más avanzadas, los sistemas RAG avanzados tienen un conocimiento más profundo de la consulta y el contexto, y son capaces de analizar los matices semánticos, las pistas contextuales y la intención del usuario para generar respuestas más coherentes y pertinentes.
Mejoras avanzadas del sistema RAG en los componentes
La evolución de la GAR básica a la avanzada significa que el sistema consigue mejoras significativas en cada uno de los cuatro componentes clave: almacenamiento, recuperación, mejora y generación.
- almacenar: Los sistemas RAG avanzados hacen más eficaz la recuperación de información al almacenar los datos mediante indexación semántica, organizados por el significado de los datos y no por simples palabras clave.
- recuperar (datos)Gracias a la mejora de la búsqueda semántica y la recuperación contextual, el sistema no sólo encuentra datos relevantes, sino que también comprende la intención y el contexto del usuario.
- refuerceEl módulo de mejora del sistema GAR avanzado genera respuestas más personalizadas y precisas mediante un mecanismo dinámico de aprendizaje y adaptación que se optimiza continuamente en función de las interacciones del usuario.
- generandoMódulo de generación: el módulo de generación utiliza una sofisticada comprensión del contexto y una optimización iterativa para permitir la generación de respuestas más coherentes y contextuales.
La evolución de la GAR básica a la avanzada supone un importante salto adelante. Al utilizar técnicas de recuperación sofisticadas, una mayor integración contextual y mecanismos de aprendizaje dinámico, los sistemas de GAR avanzados proporcionan un enfoque más preciso y consciente del contexto para la recuperación y generación de información. Este avance mejora la calidad de las interacciones de la IA y sienta las bases de una comunicación más refinada y eficaz.
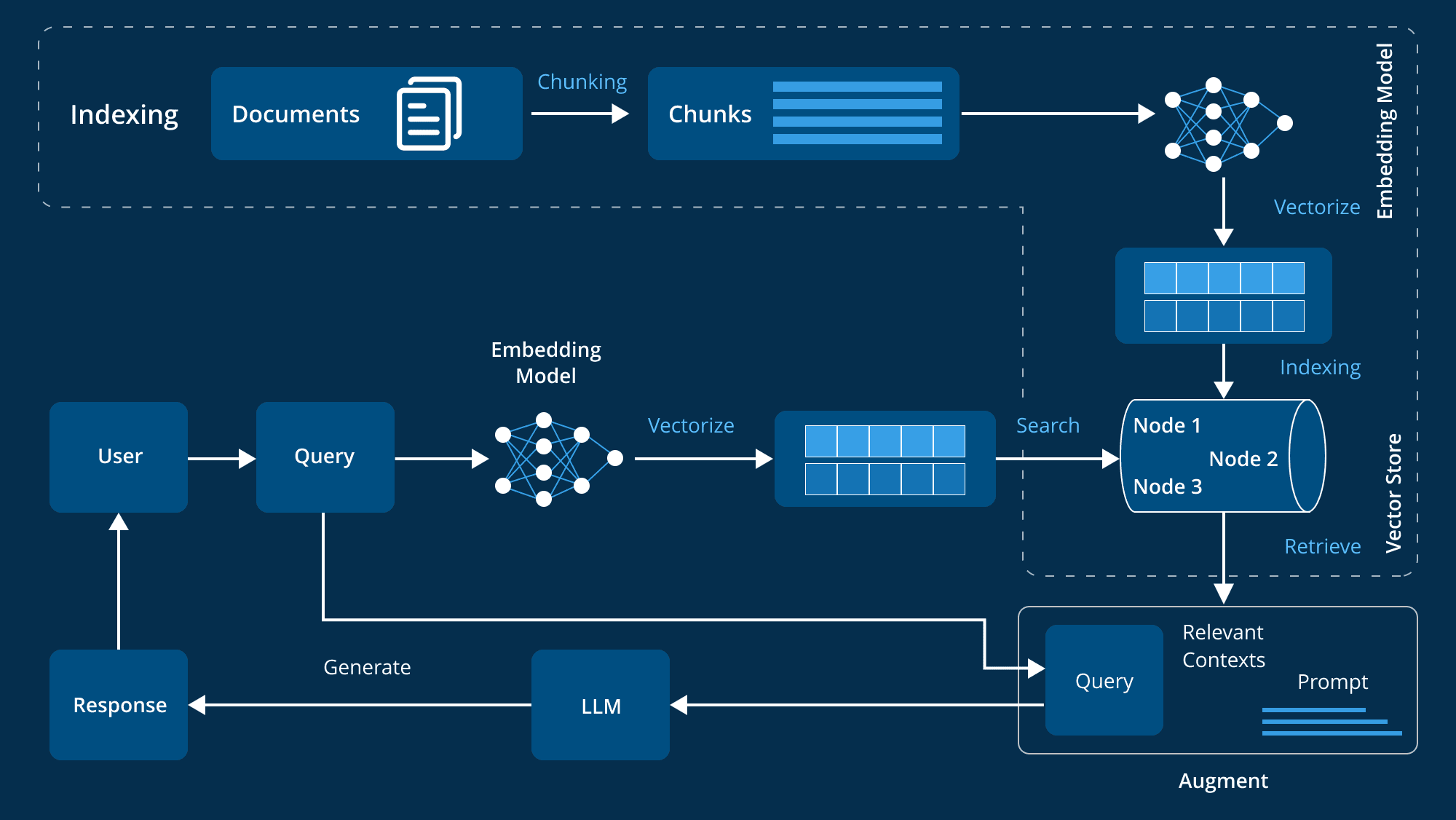
Componentes y flujos de trabajo de un sistema GAR avanzado a nivel de empresa
En el campo de las aplicaciones empresariales, existe una creciente necesidad de sistemas que puedan recuperar y generar información relevante de forma inteligente. Los sistemas de Generación Aumentada de Recuperación (RAG) han surgido como potentes soluciones que combinan la precisión de la recuperación de información con el poder generativo de los Grandes Modelos Lingüísticos (LLM). Sin embargo, para construir un sistema RAG avanzado que se adapte a las complejas necesidades de una organización, su arquitectura debe diseñarse cuidadosamente.
Componentes básicos de la arquitectura
Un sistema avanzado de Generación de Aumento de la Recuperación (RAG) requiere múltiples componentes básicos que trabajen juntos para garantizar la eficiencia y eficacia del sistema. Estos componentes abarcan la gestión de datos, el procesamiento de las entradas de los usuarios, la recuperación y generación de información y la mejora continua del rendimiento del sistema. A continuación se presenta un desglose detallado de estos componentes clave:
- Preparación y gestión de datos
La base de un sistema GAR avanzado es la preparación y gestión de los datos, que implica una serie de componentes clave:
- Agrupación de datos y vectorización: Los datos se descomponen en trozos más manejables y se convierten en representaciones vectoriales, lo que es fundamental para mejorar la eficacia y precisión de la recuperación.
- Generación de metadatos y resúmenes: La generación de metadatos y resúmenes permite una consulta rápida y reduce el tiempo de recuperación.
- Depuración de datos: Asegurarse de que los datos están limpios, organizados y libres de ruido es clave para garantizar que la información recuperada es exacta.
- Maneja formatos de datos complejos: La capacidad del sistema para manejar formatos de datos complejos garantiza una utilización eficaz de los distintos tipos de datos de la organización.
- Gestión de la configuración de usuarios: La personalización es importante en un entorno empresarial, y mediante la gestión de las configuraciones de usuario, las respuestas pueden adaptarse a las necesidades individuales, optimizando la experiencia del usuario.
- Procesamiento de entradas de usuario
El módulo de procesamiento de entradas de usuario desempeña un papel fundamental para garantizar que el sistema pueda gestionar las consultas de forma eficaz:
- Autenticación de usuarios: La seguridad de los sistemas empresariales es muy importante y los mecanismos de autenticación garantizan que sólo los usuarios autorizados puedan utilizar el sistema RAG.
- Optimizador de consultas: La estructura de la consulta del usuario puede no ser adecuada para la recuperación y el optimizador optimiza la consulta para mejorar la pertinencia y precisión de la recuperación.
- Mecanismos de protección de entrada: Los mecanismos de protección protegen el sistema de entradas extrañas o malintencionadas, garantizando la fiabilidad del proceso de recuperación.
- Utilización del historial de chat: Al referirse a diálogos anteriores, el sistema es más capaz de entender y responder a la consulta actual, generando respuestas más precisas y contextualizadas.
- sistema de recuperación de información
El sistema de recuperación de información es el núcleo de la arquitectura GAR y se encarga de recuperar la información más relevante a partir de un índice de datos preprocesados:
- Indexación de datos: La eficaz tecnología de indexación garantiza una recuperación rápida y precisa de la información, y los métodos avanzados de indexación permiten procesar grandes cantidades de datos empresariales.
- Ajuste de hiperparámetros: Los parámetros del modelo de recuperación se ajustan para optimizar su rendimiento y garantizar que se recuperan los resultados más relevantes.
- Reordenación de resultados: Tras la recuperación, el sistema reordena los resultados para garantizar que se muestre primero la información más relevante, lo que mejora la calidad de la respuesta.
- Optimización de la integración: Al ajustar los vectores de incrustación, el sistema es capaz de hacer coincidir mejor la consulta con los datos pertinentes, mejorando así la precisión de la recuperación.
- Problemas hipotéticos con la tecnología HyDE: La generación de pares de preguntas y respuestas hipotéticas mediante la tecnología HyDE (Hypothetical Document Embedding) puede afrontar mejor la recuperación de información cuando la consulta y el documento son asimétricos.
- Generación y tratamiento de la información
Cuando se recupera información relevante, el sistema debe generar una respuesta coherente y contextualmente pertinente:
- Generación de respuestas: Utilizando modelos avanzados de grandes lenguajes (LLM), el módulo sintetiza la información recuperada en una respuesta completa y precisa.
- Protección de la salida y auditoría: Para garantizar que las respuestas generadas cumplen las especificaciones, el sistema utiliza varias reglas para revisarlas.
- Caché de datos: Los datos o respuestas a los que se accede con frecuencia se almacenan en caché, lo que reduce el tiempo de recuperación y mejora la eficiencia del sistema.
- Generación de personalización: El sistema personaliza el contenido generado en función de las necesidades y la configuración del usuario para garantizar la pertinencia y precisión de la respuesta.
- Retroalimentación y optimización del sistema
Los sistemas GAR avanzados deben ser capaces de autoaprendizaje y mejora, y los mecanismos de retroalimentación son esenciales para la optimización continua:
- Comentarios de los usuarios: Al recoger y analizar las opiniones de los usuarios, el sistema puede identificar áreas de mejora y evolucionar para satisfacer mejor sus necesidades.
- Optimización de datos: A partir de los comentarios de los usuarios y los nuevos descubrimientos, los datos del sistema se optimizan continuamente para garantizar la calidad y pertinencia de la información.
- Generar evaluaciones de calidad: El sistema evalúa periódicamente la calidad de los contenidos generados para optimizarlos continuamente.
- Supervisión del sistema: Supervisar continuamente el rendimiento del sistema para garantizar que funciona con eficacia y puede responder a los cambios en la demanda o en los patrones de datos.
Integración con los sistemas de la empresa
Para que un sistema GAR avanzado funcione mejor en un entorno organizativo, es esencial una integración perfecta con los sistemas existentes:
- Integración de sistemas CRM y ERP: La interconexión de los sistemas avanzados de GAR con los sistemas de gestión de relaciones con los clientes (CRM) y de planificación de recursos empresariales (ERP) permite un acceso y una utilización eficaces de los datos empresariales clave, lo que mejora la capacidad de generar respuestas precisas y contextualmente relevantes.
- APIs y arquitectura de microservicios: El uso de API flexibles y una arquitectura de microservicios permite que el sistema RAG se integre fácilmente en el software empresarial existente, permitiendo actualizaciones y ampliaciones modulares.
Seguridad y conformidad
La seguridad y el cumplimiento son especialmente importantes debido a la sensibilidad de los datos empresariales:
- Protocolos de seguridad de los datos: Para proteger la información sensible y garantizar el cumplimiento de las normativas de protección de datos, como el GDPR, se utilizan medidas sólidas de cifrado y tratamiento seguro de datos.
- Control de acceso y autenticación: Implantar mecanismos seguros de autenticación de usuarios y control de acceso basado en funciones para garantizar que sólo el personal autorizado pueda acceder al sistema o modificarlo.
Escalabilidad y optimización del rendimiento
Los sistemas RAG de clase empresarial deben ser escalables y capaces de mantener un buen rendimiento bajo cargas elevadas:
- Arquitectura nativa de la nube: El uso de una arquitectura nativa en la nube proporciona la flexibilidad necesaria para escalar los recursos en función de la demanda, garantizando una alta disponibilidad del sistema y la optimización del rendimiento.
- Equilibrio de carga y gestión de recursos: Las eficientes estrategias de equilibrio de carga y gestión de recursos ayudan al sistema a gestionar grandes volúmenes de peticiones de usuarios y datos manteniendo un rendimiento óptimo.
Análisis e informes
Los sistemas avanzados de GAR también deben disponer de sólidas capacidades de análisis e información:
- Control del rendimiento: La supervisión en tiempo real del rendimiento del sistema, las interacciones de los usuarios y el estado del sistema mediante la integración de herramientas analíticas avanzadas es fundamental para mantener la eficiencia del sistema.
- Integración de Business Intelligence: La integración con herramientas de Business Intelligence puede proporcionar información valiosa para ayudar a la toma de decisiones e impulsar la estrategia empresarial.
Los sistemas GAR avanzados a nivel empresarial representan una combinación de tecnología de IA de vanguardia, mecanismos sólidos de procesamiento de datos, infraestructura segura y escalable, y capacidades de integración sin fisuras. Mediante la combinación de estos elementos, las organizaciones son capaces de construir sistemas GAR que pueden recuperar y generar información de manera eficiente, al tiempo que son una parte fundamental del sistema tecnológico de la empresa. Estos sistemas no sólo aportan un importante valor empresarial, sino que también mejoran los procesos de toma de decisiones y aumentan la eficacia operativa general.
Tecnología RAG avanzada
La Generación Aumentada de Recuperación Avanzada (GAR) engloba una serie de herramientas tecnológicas diseñadas para mejorar la eficacia y la precisión en todas las fases del procesamiento. Estos sistemas RAG avanzados son capaces de gestionar mejor los datos y ofrecer respuestas más precisas y contextualizadas aplicando tecnologías avanzadas en las distintas fases del proceso, desde la indexación y la transformación de consultas hasta la recuperación y la generación. A continuación se presentan algunas de las técnicas avanzadas utilizadas para optimizar cada etapa del proceso GAR:
1. Índice
La indexación es un proceso clave que mejora la precisión y eficacia de los sistemas de grandes modelos lingüísticos (LLM). La indexación es algo más que el simple almacenamiento de datos; implica la organización y optimización sistemáticas de los datos para garantizar que la información sea de fácil acceso y comprensión, al tiempo que se mantiene un contexto importante. Una indexación eficaz ayuda a recuperar los datos con precisión y eficacia, lo que permite a los LLM ofrecer respuestas pertinentes y precisas. Algunas de las técnicas utilizadas en el proceso de indexación son:
Técnica 1: Optimización de bloques de texto mediante la optimización de bloques
El objetivo de la optimización de bloques es ajustar el tamaño y la estructura de los bloques de texto para que no sean ni demasiado grandes ni demasiado pequeños, manteniendo el contexto y mejorando así la recuperación.
Técnica 2: Conversión de texto en vectores mediante modelos de incrustación avanzados
Una vez creados los bloques de texto, el siguiente paso es convertirlos en representaciones vectoriales. Este proceso transforma el texto en vectores numéricos que captan su significado semántico. Modelos como BGE-large o la familia de incrustación E5 son eficaces para representar los matices del texto. Estas representaciones vectoriales son cruciales en la posterior recuperación y correspondencia semántica.
Técnica 3: Mejora de la concordancia semántica mediante la integración del ajuste fino
El objetivo del ajuste fino de la incrustación es mejorar la comprensión semántica de los datos indexados por parte del modelo de incrustación, mejorando así la precisión de la correspondencia entre la información recuperada y la consulta del usuario.
Técnica 4: Mejorar la eficacia de la búsqueda mediante representaciones múltiples
Las técnicas de multirrepresentación convierten los documentos en unidades de recuperación ligeras, como los resúmenes, para acelerar el proceso de recuperación y mejorar la precisión cuando se trabaja con documentos de gran tamaño.
Técnica 5: Utilización de índices jerárquicos para organizar los datos
La indexación jerárquica mejora la recuperación al estructurar los datos en varios niveles, de detallados a generales, mediante modelos como RAPTOR, que proporcionan información contextual amplia y precisa.
Técnica 6: Mejora de la recuperación de datos mediante la incorporación de metadatos
Las técnicas de adición de metadatos añaden información adicional a cada bloque de datos para mejorar las capacidades de análisis y clasificación, haciendo que la recuperación de datos sea más sistemática y contextual.
2. Conversión de consultas
El objetivo de la transformación de consultas es optimizar la entrada de datos del usuario y mejorar la calidad de la recuperación de información. Mediante el uso de LLM, el proceso de transformación puede hacer que las consultas complejas o ambiguas sean más claras y específicas, mejorando así la eficacia y precisión de la búsqueda.
Técnica 1: Uso de HyDE (incrustación hipotética de documentos) para mejorar la claridad de las consultas
HyDE mejora la pertinencia y precisión de la recuperación de información generando datos de hipótesis para aumentar la similitud semántica entre las preguntas y el contenido de referencia.
Técnica 2: Simplificar las consultas complejas con consultas en varios pasos
Las consultas en varios pasos dividen las preguntas complejas en subpreguntas más sencillas, recuperan las respuestas a cada subpregunta por separado y agregan los resultados para ofrecer una respuesta más precisa y completa.
Técnica 3: Mejorar el contexto con pistas de retroceso
La técnica de backtracking hinting genera una consulta general más amplia a partir de la compleja consulta original, de forma que el contexto ayuda a proporcionar una base para la consulta específica, mejorando la respuesta final al combinar los resultados de la consulta original y la más amplia.
Técnica 4: Mejora de la recuperación mediante la reescritura de consultas
La técnica de reescritura de consultas utiliza el LLM para reformular la consulta inicial con el fin de mejorar la recuperación. Tanto LangChain como LlamaIndex utilizan esta técnica, y LlamaIndex proporciona una implementación especialmente potente que mejora drásticamente la recuperación.
3. Enrutamiento de consultas
La función del enrutamiento de consultas es optimizar el proceso de recuperación enviando la consulta a la fuente de datos más adecuada en función de las características de la consulta, garantizando que cada consulta sea tratada por el componente del sistema más apropiado.
Técnica 1: Enrutamiento lógico
El enrutamiento lógico optimiza la recuperación analizando la estructura de la consulta para seleccionar la fuente de datos o el índice más adecuados. Este enfoque garantiza que la consulta sea procesada por la fuente de datos más adecuada para proporcionar una respuesta precisa.
Tecnología 2: Enrutamiento semántico
El enrutamiento semántico dirige la consulta a la fuente de datos o índice correctos analizando el significado semántico de la consulta. Mejora la precisión de la recuperación al comprender el contexto y el significado de la consulta, especialmente en el caso de cuestiones complejas o matizadas.
4. Técnicas de búsqueda previa e indexación de datos
La optimización previa a la recuperación mejora la calidad y la capacidad de recuperación de la información en un índice de datos o una base de conocimientos. Los métodos específicos de optimización varían en función de la naturaleza, la fuente y el tamaño de los datos. Por ejemplo, aumentar la densidad de la información puede generar respuestas más precisas con menos tokens, lo que mejora la experiencia del usuario y reduce costes. Sin embargo, los métodos de optimización que funcionan para un sistema pueden no funcionar para otros. Los grandes modelos lingüísticos (LLM) ofrecen herramientas para probar y ajustar estas optimizaciones, lo que permite adoptar enfoques a medida para mejorar la recuperación en distintos dominios y aplicaciones.
Técnica 1: Utilizar los LLM para aumentar la densidad de información
Un paso fundamental para optimizar un sistema GAR es mejorar la calidad de los datos antes de indexarlos. La utilización de LLM para la limpieza, el etiquetado y el resumen de datos permite aumentar la densidad de la información y obtener resultados más precisos y eficaces en el tratamiento de datos.
Técnica 2: Búsqueda en índices jerárquicos
Las búsquedas de indexación jerárquica simplifican el proceso de búsqueda creando resúmenes de documentos como primera capa de filtros. Este enfoque multicapa garantiza que en la fase de búsqueda sólo se tengan en cuenta los datos más relevantes, lo que mejora la eficacia y la precisión de la búsqueda.
Técnica 3: Mejorar la simetría de la búsqueda mediante parejas hipotéticas de preguntas y respuestas
Para abordar la asimetría entre consultas y documentos, esta técnica utiliza LLM para generar pares hipotéticos de preguntas y respuestas a partir de documentos. Al integrar estos pares de preguntas y respuestas en la recuperación, el sistema puede ajustarse mejor a la consulta del usuario, mejorando así la similitud semántica y reduciendo los errores de recuperación.
Técnica 4: Desduplicación con LLMs
La información duplicada puede ser tanto beneficiosa como perjudicial para un sistema GAR. El uso de LLM para desduplicar bloques de datos optimiza la indexación de datos, reduce el ruido y aumenta la probabilidad de generar respuestas precisas.
Técnica 5: Probar y optimizar las estrategias de fragmentación
Una estrategia de fragmentación eficaz es fundamental para la recuperación. Realizando pruebas A/B con diferentes tamaños de trozos y proporciones de solapamiento, se puede encontrar el equilibrio óptimo para un caso de uso concreto. Esto ayuda a mantener un contexto suficiente sin dispersar o diluir demasiado la información relevante.
Técnica 6: Utilizar una ventana deslizante Índice
La indexación por ventanas deslizantes garantiza que no se pierda información contextual importante entre segmentos al solapar bloques de datos durante el proceso de indexación. Este enfoque mantiene la continuidad de los datos y mejora la relevancia y precisión de la información recuperada.
Técnica 7: Aumentar la granularidad de los datos
La mejora de la granularidad de los datos se consigue principalmente aplicando técnicas de limpieza de datos para eliminar la información irrelevante y conservar en el índice sólo el contenido más preciso y actualizado. Esto mejora la calidad de la recuperación y garantiza que sólo se tenga en cuenta la información pertinente.
Técnica 8: Añadir metadatos
Añadir metadatos, como la fecha, el propósito o la sección, puede aumentar la precisión de la búsqueda, permitiendo al sistema centrarse más eficazmente en los datos más relevantes y mejorar la búsqueda global.
Técnica 9: Optimizar la estructura de los índices
La optimización de la estructura de indexación implica cambiar el tamaño de los fragmentos y emplear múltiples estrategias de indexación, como la recuperación por ventanas de frases, para mejorar la forma en que se almacenan y recuperan los datos. Al incluir frases individuales y mantener al mismo tiempo una ventana contextual, este enfoque permite una recuperación más rica y precisa desde el punto de vista contextual durante la inferencia.
5. Técnicas de recuperación
En la fase de recuperación, el sistema recopila la información necesaria para responder a la consulta del usuario. La tecnología de búsqueda avanzada garantiza que el contenido recuperado sea exhaustivo y contextualmente completo, sentando una base sólida para los pasos de procesamiento posteriores.
Técnica 1: Optimización de las consultas de búsqueda con LLM
Los LLM optimizan la consulta del usuario para que se ajuste mejor a los requisitos del sistema de búsqueda, tanto si se trata de una búsqueda simple como de una consulta de diálogo compleja. Esta optimización garantiza que el proceso de búsqueda sea más específico y eficaz.
Técnica 2: Corregir la asimetría consulta-documento con HyDE
Al generar documentos de respuesta hipotéticos, la técnica HyDE mejora la similitud semántica en la recuperación y resuelve la asimetría entre consultas cortas y documentos largos.
TÉCNICA 3: Implantación del encaminamiento de consultas o modelización de decisiones RAG
En los sistemas que utilizan múltiples fuentes de datos, el enrutamiento de las consultas optimiza la eficacia de la recuperación al dirigir las búsquedas a la base de datos adecuada.El modelo de decisión RAG optimiza aún más este proceso al determinar cuándo es necesaria una recuperación para ahorrar recursos cuando el modelo de lenguaje amplio puede responder de forma independiente.
Técnica 4: Exploración en profundidad con buscadores recursivos
Un buscador recursivo realiza más consultas basándose en el resultado anterior y es adecuado para explorar datos relevantes en profundidad y obtener información detallada o exhaustiva.
Técnica 5: Optimización de la selección de fuentes de datos con recuperadores de rutas
El Routing Retriever utiliza LLM para seleccionar dinámicamente la fuente de datos o la herramienta de consulta más adecuada para mejorar la eficacia del proceso de recuperación en función del contexto de la consulta.
Técnica 6: Generación automática de consultas con recuperadores automáticos
El Auto-Retriever utiliza el LLM para generar automáticamente filtros de metadatos o sentencias de consulta, simplificando así el proceso de consulta de la base de datos y optimizando la recuperación de información.
Técnica 7: Combinación de resultados mediante un buscador de fusión
El Fusion Retriever combina los resultados de varias consultas e índices para ofrecer una visión completa y no duplicada de la información, lo que garantiza una búsqueda exhaustiva.
Técnica 8: Agregación de contextos de datos con buscadores de autofusión
El recuperador Auto Merge combina varios segmentos de datos en un único contexto unificado, lo que mejora la pertinencia y exhaustividad de la información al integrar contextos más pequeños.
Técnica 9: Ajuste del modelo de incrustación
El ajuste del modelo de incrustación para hacerlo más específico del dominio mejora la capacidad de manejar terminología especializada. Este enfoque aumenta la pertinencia y precisión de la información recuperada al alinear mejor el contenido específico del dominio.
Técnica 10: Aplicación de la incrustación dinámica
Las incrustaciones dinámicas van más allá de las representaciones estáticas al adaptar los vectores de palabras al contexto, lo que proporciona una comprensión más matizada de la lengua. Este enfoque, como el modelo embeddings-ada-02 de OpenAI, capta los significados contextuales con mayor precisión y, por tanto, proporciona resultados de recuperación más exactos.
Técnica 11: Utilizar la búsqueda híbrida
La búsqueda híbrida combina la búsqueda vectorial con la concordancia tradicional de palabras clave, lo que permite tanto la similitud semántica como el reconocimiento preciso de términos. Este enfoque es especialmente eficaz en situaciones en las que se requiere un reconocimiento preciso de los términos, lo que garantiza una recuperación completa y precisa.
6. Técnicas posteriores a la recuperación
Una vez adquiridos los contenidos pertinentes, la fase posterior a la recuperación se centra en cómo reunirlos de forma eficaz. Este paso consiste en proporcionar información contextual precisa y concisa al Modelo de Lenguaje Amplio (LLM), garantizando que el sistema disponga de todos los detalles necesarios para generar respuestas coherentes y precisas. La calidad de esta integración determina directamente la pertinencia y claridad del resultado final.
Técnica 1: Optimización de los resultados de búsqueda mediante reordenación
Tras la recuperación, el modelo de reordenación reorganiza los resultados de la búsqueda para situar los documentos más relevantes más cerca de la consulta, mejorando así la calidad de la información proporcionada al LLM y, en consecuencia, la generación de la respuesta final. La reordenación no sólo reduce el número de documentos que hay que proporcionar al LLM, sino que también actúa como filtro para mejorar la precisión del procesamiento lingüístico.
Técnica 2: Optimización de los resultados de búsqueda mediante compresión con sugerencias contextuales
LLM puede filtrar y comprimir la información recuperada antes de generar el mensaje final. La compresión ayuda a LLM a centrarse más en la información crítica reduciendo la información de fondo redundante y eliminando el ruido extraño. Esta optimización mejora la calidad de la respuesta, centrándola en los detalles importantes. Los marcos como LLMLingua mejoran aún más este proceso al eliminar los tokens superfluos, lo que hace que las instrucciones sean más concisas y eficaces.
Técnica 3: Puntuación y filtrado de los documentos recuperados mediante la corrección de las GAR
Antes de introducir el contenido en el LLM, es necesario seleccionar y filtrar los documentos para eliminar los irrelevantes o menos precisos. Esta técnica garantiza que sólo se utilice información relevante y de alta calidad, mejorando así la precisión y fiabilidad de la respuesta. El GAR correctivo utiliza un modelo como T5-Large para evaluar la relevancia de los documentos recuperados y filtra los que están por debajo de un umbral preestablecido, garantizando que sólo la información valiosa participe en la generación de la respuesta final.
7. Tecnologías generativas
Durante la fase de generación, la información recuperada se evalúa y reordena para identificar el contenido más importante. La tecnología avanzada en esta fase consiste en seleccionar aquellos detalles clave que aumentan la relevancia y fiabilidad de la respuesta. Este proceso garantiza que el contenido generado no sólo responda a la consulta, sino que además se apoye en los datos recuperados de forma significativa.
Técnica 1: Reducir el ruido con consejos sobre la cadena de pensamiento
Las indicaciones de cadena de pensamiento ayudan a LLM a tratar la información de fondo ruidosa o irrelevante, aumentando la probabilidad de generar una respuesta precisa incluso si hay interferencias en los datos.
TÉCNICA 2: Auto-reflexión del sistema a través de la auto-RAG
El auto-RAG consiste en entrenar al modelo para que utilice fichas reflexivas durante la generación, de modo que pueda evaluar y mejorar su propio resultado en tiempo real, eligiendo la mejor respuesta en función de la facticidad y la calidad.
Técnica 3: Ignorar los fondos extraños mediante el ajuste fino
El sistema RAG se ajustó específicamente para mejorar la capacidad del LLM de ignorar antecedentes extraños, garantizando que sólo la información relevante influya en la respuesta final.
Técnica 4: Mejora de la robustez del LLM frente a antecedentes irrelevantes con razonamiento en lenguaje natural
La integración de modelos de inferencia en lenguaje natural (NLI) ayuda a filtrar la información contextual irrelevante comparando el contexto recuperado con la respuesta generada, lo que garantiza que sólo la información relevante influya en el resultado final.
Técnica 5: Control de la recuperación de datos con FLARE
FLARE (Flexible Language Modelling Adaptation for Retrieval Enhancement) es un enfoque basado en la ingeniería de pistas que garantiza que LLM recupera datos sólo cuando es necesario. Adapta continuamente la consulta y busca palabras clave de baja probabilidad que activen la recuperación de documentos relevantes para mejorar la precisión de la respuesta.
Técnica 6: Mejora de la calidad de la respuesta con ITER-RETGEN
ITER-RETGEN (Recuperación-Generación Iterativa) mejora la calidad de la respuesta ejecutando iterativamente el proceso de generación. Cada iteración utiliza el resultado anterior como contexto para recuperar más información relevante, mejorando así continuamente la calidad y pertinencia de la respuesta final.
Técnica 7: Aclarar los problemas mediante el árbol de aclaraciones (TdC)
ToC genera recursivamente preguntas específicas para aclarar ambigüedades en la consulta inicial. Este enfoque perfecciona el proceso de pregunta-respuesta evaluando y refinando continuamente la pregunta original, lo que da lugar a una respuesta final más detallada y precisa.
8. Evaluación
En las tecnologías avanzadas de Generación Aumentada de Recuperación (RAG), el proceso de evaluación es fundamental para garantizar que la información recuperada y sintetizada sea precisa y pertinente para la consulta del usuario. El proceso de evaluación consta de dos componentes clave: las puntuaciones de calidad y las capacidades requeridas.
La puntuación de la calidad se centra en medir la precisión y pertinencia de los contenidos:
- Antecedentes Relevancia. Evaluar la aplicabilidad de la información recuperada o generada en el contexto específico de la consulta. Garantizar que la respuesta sea precisa y se ajuste a las necesidades del usuario.
- Respuesta Fidelidad. Compruebe que las respuestas generadas reflejan fielmente los datos recuperados y no introducen errores o información engañosa. Esto es esencial para mantener la fiabilidad de los resultados del sistema.
- Pertinencia de la respuesta. Evaluar si la respuesta generada responde directa y eficazmente a la consulta del usuario, asegurándose de que la respuesta es útil y coherente con la esencia de la pregunta.
Las capacidades requeridas son las que debe tener el sistema para ofrecer resultados de alta calidad:
- Robustez al ruido. Mide la capacidad del sistema de filtrar datos extraños o ruidosos para garantizar que estas perturbaciones no afectan a la calidad de la respuesta final.
- Rechazo negativo. Probar la eficacia del sistema para identificar y excluir la información errónea o irrelevante de la contaminación de la salida generada.
- Integración de la información. Evalúe la capacidad del sistema para integrar múltiples piezas de información relevante en una respuesta coherente y exhaustiva que proporcione al usuario una respuesta completa.
- Solidez contrafáctica. Comprobar el funcionamiento del sistema ante situaciones hipotéticas o contrafácticas para garantizar que las respuestas siguen siendo precisas y fiables incluso cuando se trata de preguntas especulativas.
Juntos, estos componentes de evaluación garantizan que el sistema Advanced RAG proporcione una respuesta precisa y pertinente, sólida, fiable y adaptada a las necesidades específicas del usuario.
Tecnologías adicionales
Motor de chat: mejora del diálogo en el sistema GAR
La integración de un motor de chat en un sistema avanzado de Generación Aumentada de Recuperación (RAG) mejora la capacidad del sistema para gestionar preguntas de seguimiento y mantener el contexto del diálogo, de forma similar a la tecnología tradicional de chatbot. Las distintas implementaciones ofrecen diferentes niveles de complejidad:
- Motor de chat contextual: Este enfoque subyacente guía la respuesta del Modelo de Lenguaje Amplio (LLM) recuperando el contexto relevante para la consulta del usuario, incluidos los chats anteriores. Así se garantiza que el diálogo sea coherente y adecuado al contexto.
- Concentración más modos contextuales: Se trata de un enfoque más avanzado que condensa los registros de chat y los últimos mensajes de cada interacción en una consulta optimizada. Esta consulta refinada toma el contexto relevante y lo combina con el mensaje original del usuario para proporcionarlo al LLM y generar una respuesta más precisa y contextualizada.
Estas implementaciones contribuyen a mejorar la coherencia y pertinencia del diálogo en el sistema GAR y ofrecen distintos niveles de complejidad en función de las necesidades.
Citas de referencia: garantizar la exactitud de las fuentes
Garantizar la exactitud de las referencias es importante, especialmente cuando múltiples fuentes contribuyen a las respuestas generadas. Esto puede lograrse de varias maneras:
- Etiquetado directo en origen: La configuración de una tarea en un prompt de Modelo de Lenguaje (LLM) requiere que la fuente esté directamente etiquetada en la respuesta generada. Este enfoque permite etiquetar claramente la fuente original.
- Técnica de emparejamiento difuso: Las técnicas de concordancia difusa, como las utilizadas por LlamaIndex, se emplean para alinear partes del contenido generado con bloques de texto del índice de origen. La concordancia difusa mejora la precisión del contenido y garantiza que refleje la información de la fuente.
Aplicando estas estrategias se puede mejorar notablemente la precisión y fiabilidad de las citas de referencia, garantizando que las respuestas generadas sean creíbles y estén bien fundamentadas.
Agentes de la Generación Aumentada de Recuperación (RAG)
Los agentes desempeñan un papel importante en la mejora del rendimiento de los sistemas de Generación Aumentada de Recuperación (RAG) al proporcionar herramientas y funcionalidades adicionales al Modelo de Lenguaje Grande (LLM) para ampliar su alcance. Introducidos originalmente a través de la API del LLM, estos agentes permiten a los LLM aprovechar funciones de código externas, API e incluso otros LLM para mejorar su funcionalidad.
Una aplicación importante de los agentes es la recuperación de documentos múltiples. Por ejemplo, los recientes asistentes OpenAI demuestran avances en este concepto. Estos asistentes aumentan los LLM tradicionales integrando funciones como registros de chat, almacenes de conocimientos, interfaces de carga de documentos y API de llamadas a funciones que convierten el lenguaje natural en comandos procesables.
El uso de agentes también se extiende a la gestión de múltiples documentos, donde cada documento es gestionado por un agente específico, como los resúmenes y los cuestionarios. Un agente central de alto nivel supervisa estos agentes específicos de cada documento, enrutando las consultas y consolidando las respuestas. Esta configuración permite realizar comparaciones y análisis complejos entre varios documentos, demostrando técnicas avanzadas de GAR.
Respuesta a Sintetizador: elaboración de la respuesta final
El último paso del proceso GAR consiste en sintetizar en una respuesta el contexto recuperado y la consulta inicial del usuario. Además de combinar directamente el contexto con la consulta y procesarla a través del LLM, existen enfoques más refinados:
- Optimización iterativa: Dividir el contexto recuperado en partes más pequeñas optimiza la respuesta a través de múltiples interacciones con el LLM.
- Resumen contextual: La compresión de una gran cantidad de contexto para que quepa en las preguntas del LLM garantiza que las respuestas se mantengan centradas y sean pertinentes.
- Generación de respuestas múltiples: Genere múltiples respuestas de diferentes segmentos del contexto y luego integre estas respuestas en una respuesta unificada.
Estas técnicas mejoran la calidad y precisión de las respuestas del sistema GAR, lo que demuestra el potencial de los métodos avanzados en la síntesis de respuestas.
La adopción de estas tecnologías avanzadas de GAR puede mejorar significativamente el rendimiento y la fiabilidad del sistema. Al optimizar el proceso en cada etapa, desde el preprocesamiento de datos hasta la generación de respuestas, las empresas pueden crear aplicaciones de IA más precisas, eficientes y potentes.
Aplicaciones y casos RAG avanzados
Los sistemas avanzados de Generación Aumentada de Recuperación (GAR) se utilizan en una amplia gama de campos para mejorar el análisis de datos, la toma de decisiones y la interacción con el usuario gracias a sus potentes capacidades de procesamiento y generación de datos. Desde la investigación de mercados a la atención al cliente o la creación de contenidos, los sistemas RAG avanzados han demostrado importantes ventajas en diversos ámbitos. A continuación se describen aplicaciones específicas de estos sistemas en distintos ámbitos:
1. Estudios de mercado y análisis de la competencia
- integración de datosEl sistema RAG es capaz de integrar y analizar datos procedentes de diversas fuentes, como las redes sociales, artículos de prensa e informes del sector.
- Identificación de tendenciasEl sistema RAG, al procesar grandes cantidades de datos, es capaz de identificar tendencias emergentes en el mercado y cambios en el comportamiento de los consumidores.
- Información sobre la competenciaEl sistema proporciona estrategias detalladas de la competencia y análisis de resultados para ayudar a las empresas en su autoevaluación y evaluación comparativa.
- información prácticaLas empresas pueden utilizar estos informes para la planificación estratégica y la toma de decisiones.
2. Atención al cliente e interacción
- Respuestas adaptadas al contextoEl sistema RAG recupera información pertinente de la base de conocimientos para ofrecer respuestas precisas y contextualizadas a los clientes.
- Reducir la carga de trabajoLa automatización de la gestión de problemas comunes libera a los equipos de asistencia manuales de la presión de tener que ocuparse de problemas más complejos.
- Servicio personalizadoEl sistema personaliza las respuestas y las interacciones para satisfacer las necesidades individuales mediante el análisis del historial y las preferencias de los clientes.
- Mejorar la experiencia interactiva: Los servicios de asistencia de alta calidad aumentan la satisfacción del cliente y refuerzan sus relaciones con él.
3. Cumplimiento de la normativa y gestión de riesgos
- Análisis normativoEl sistema RAG escanea e interpreta los documentos legales y las directrices normativas para garantizar su cumplimiento.
- identificación de riesgosEl sistema identifica rápidamente los posibles riesgos de cumplimiento comparando las políticas internas con las normativas externas.
- Recomendaciones de cumplimiento: Proporcionar asesoramiento práctico para ayudar a las empresas a colmar las lagunas de cumplimiento y reducir los riesgos jurídicos.
- Informes eficacesGenerar informes y resúmenes de cumplimiento que sean fáciles de auditar e inspeccionar.
4. Desarrollo e innovación de productos
- Análisis de los comentarios de los clientesEl sistema RAG analiza los comentarios de los clientes para identificar problemas y puntos débiles comunes.
- Perspectivas del mercado: Rastrea las tendencias emergentes y las necesidades de los clientes para orientar el desarrollo de productos.
- Propuestas innovadoras: Aportar posibles características del producto y recomendaciones de mejora basadas en el análisis de datos.
- posicionamiento competitivo: Ayudar a las empresas a desarrollar productos que respondan a las necesidades del mercado y se distingan de la competencia.
5. Análisis financiero y previsiones
- integración de datosEl sistema RAG integra datos financieros, condiciones de mercado e indicadores económicos para un análisis exhaustivo.
- Análisis de tendenciasEl objetivo es: identificar pautas y tendencias en los mercados financieros para facilitar las previsiones y las decisiones de inversión.
- asesoramiento en inversiones: Proporcionar asesoramiento práctico sobre las oportunidades de inversión y los factores de riesgo.
- planificación estratégicaApoyo a la toma de decisiones financieras estratégicas mediante previsiones precisas y recomendaciones basadas en datos.
6. Búsqueda semántica y recuperación eficiente de la información
- comprensión contextualEl sistema RAG realiza búsquedas semánticas entendiendo el contexto y el significado de las consultas de los usuarios.
- Resultados relevantes:: Mejorar la eficacia de la búsqueda recuperando la información más relevante y precisa a partir de grandes cantidades de datos.
- ahorrar tiempo:: Optimizar el proceso de recuperación de datos y reducir el tiempo dedicado a la búsqueda de información.
- Mejorar la precisiónProporciona resultados de búsqueda más precisos que los métodos tradicionales de búsqueda por palabras clave.
7. Mejorar la creación de contenidos
- Integración de tendenciasEl sistema RAG utiliza los datos más recientes para garantizar que los contenidos generados se ajustan a las tendencias actuales del mercado y a los intereses de la audiencia.
- Generación automática de contenidos:: Genere automáticamente ideas y borradores de contenidos en función de los temas y el público objetivo.
- Aumentar la participaciónGenerar contenidos más atractivos y relevantes para mejorar la interacción con el usuario.
- actualización puntual:: Garantizar que los contenidos reflejen los últimos acontecimientos y la evolución del mercado y se mantengan actualizados.
8. resumen del texto
- DestacadosEl sistema RAG puede resumir eficazmente documentos extensos, destilando los puntos clave y las conclusiones importantes.
- ahorrar tiempo: Ahorre tiempo de lectura con resúmenes de informes concisos para ejecutivos y directivos ocupados.
- centrarse en:: Resalte los mensajes clave para ayudar a los responsables de la toma de decisiones a captar rápidamente los puntos principales.
- Mayor eficacia en la toma de decisiones:: Proporcionar información relevante de forma fácil de entender para mejorar la eficacia de la toma de decisiones.
9. Sistema avanzado de preguntas y respuestas
- Respuestas precisasEl sistema RAG extrae datos de una amplia gama de fuentes de información para generar respuestas precisas a preguntas complejas.
- Mejora del acceso:: Mejorar el acceso a la información en diversos ámbitos, como la sanidad o las finanzas.
- sensible al contexto:: Proporcionar respuestas específicas basadas en las necesidades y preguntas concretas del usuario.
- Cuestiones complejas:: Abordar cuestiones complejas integrando múltiples fuentes de información.
10. Agentes de diálogo y chatbots
- información de contextoEl sistema RAG mejora la interacción entre chatbots y asistentes virtuales proporcionando información contextual relevante.
- Mejorar la precisión:: Garantizar que las respuestas de los agentes de diálogo sean precisas e informativas.
- asistencia al usuario:: Mejorar la experiencia de asistencia al usuario proporcionando una interfaz de diálogo inteligente y con capacidad de respuesta.
- Naturaleza interactiva:: Recupere datos relevantes en tiempo real para que las interacciones sean más naturales y atractivas.
11. recuperación de información
- Búsqueda avanzadaMejorar la precisión de los motores de búsqueda gracias a las capacidades de recuperación y generación de RAG.
- Generación de fragmentos de información: Genere fragmentos de información eficaces para mejorar la experiencia del usuario.
- Resultados de búsqueda mejoradosEnriquecer los resultados de búsqueda con respuestas generadas por el sistema GAR para mejorar la resolución de las consultas.
- motor del conocimiento:: Utilice los datos de la empresa para responder a preguntas internas, como políticas de recursos humanos o cuestiones de cumplimiento, para facilitar el acceso a la información.
12. Recomendaciones personalizadas
- Análisis de los datos de los clientesGenerar recomendaciones personalizadas de productos analizando compras anteriores y opiniones.
- Mejorar la experiencia de compra:: Mejorar la experiencia de compra del usuario recomendándole productos en función de sus preferencias personales.
- aumentar los ingresosRecomendación de productos pertinentes en función del comportamiento de los clientes para aumentar las ventas.
- casación de mercados:: Adaptar los contenidos recomendados a las tendencias actuales del mercado para satisfacer las necesidades cambiantes de los clientes.
13. completar texto
- suplemento contextualRAG: El sistema RAG completa partes del texto de forma contextualmente adecuada.
- aumentar la eficacia:: Proporcionar complementos precisos para simplificar tareas como la redacción de correos electrónicos o la escritura de código.
- Mejorar la productividad:: Reduzca el tiempo necesario para completar las tareas de escritura y codificación y aumente la productividad.
- Mantener la coherenciaComplementos textuales: asegúrese de que los complementos textuales sean coherentes con el contenido y el tono existentes.
14. Análisis de datos
- Integración total de datos:: El sistema RAG integra datos de bases de datos internas, informes de mercado y fuentes externas para ofrecer una visión completa y un análisis en profundidad.
- previsión precisa:: Mejore la precisión de las previsiones analizando los datos más recientes, las tendencias y la información histórica.
- Descubrimiento InsightFunciones:: Analizar conjuntos de datos exhaustivos para identificar y evaluar nuevas oportunidades y proporcionar información valiosa para el crecimiento y la mejora.
- Recomendaciones basadas en datosFunciones:: Proporcionar recomendaciones basadas en datos mediante el análisis de conjuntos de datos exhaustivos para apoyar la toma de decisiones estratégicas y mejorar la calidad general de la toma de decisiones.
15. tarea de traducción
- buscar una traducción:: Recuperar traducciones relevantes de bases de datos para ayudar en las tareas de traducción.
- Generación de contexto:: Generar traducciones coherentes basadas en el contexto y con referencia al corpus recuperado.
- Mejorar la precisión:: Utilización de datos procedentes de múltiples fuentes para mejorar la precisión de las traducciones.
- aumentar la eficacia: Agilice el proceso de traducción mediante la automatización y la generación en función del contexto.
16. Análisis de los comentarios de los clientes
- análisis exhaustivoFunciones:: Analizar los comentarios procedentes de distintas fuentes para conocer a fondo la opinión de los clientes y sus problemas.
- visiónProporcionar información detallada que revele los temas recurrentes y los puntos débiles de los clientes.
- integración de datosAnálisis exhaustivo: integre los comentarios de las bases de datos internas, las redes sociales y las reseñas para realizar un análisis exhaustivo.
- Toma de decisiones informativa:: Tome decisiones más rápidas e inteligentes basadas en las opiniones de los clientes para mejorar productos y servicios.
Estas aplicaciones demuestran el amplio abanico de posibilidades de los sistemas RAG avanzados, demostrando su capacidad para mejorar la eficiencia, la precisión y el conocimiento. Ya se trate de mejorar la atención al cliente, potenciar los estudios de mercado o agilizar el análisis de datos, los sistemas RAG avanzados ofrecen soluciones de incalculable valor que impulsan la toma de decisiones estratégicas y la excelencia operativa.
Creación de herramientas de diálogo con GAR avanzado
Las herramientas de IA de diálogo desempeñan un papel fundamental en las interacciones modernas con los usuarios, ya que proporcionan información vívida y rápida en diversas plataformas. Podemos llevar las capacidades de estas herramientas a un nivel completamente nuevo integrando un sistema avanzado de Generación Aumentada de Recuperación (RAG), que combina una potente recuperación de información con técnicas avanzadas de generación para garantizar que los diálogos sean a la vez informativos y mantengan un flujo natural de comunicación. Cuando se incorpora a una herramienta de IA de diálogo, el sistema RAG proporciona a los usuarios respuestas precisas y ricas en contexto, al tiempo que mantiene una cadencia de diálogo natural. Esta sección explora cómo puede utilizarse la GAR para construir herramientas de diálogo avanzadas, destacando los elementos clave en los que hay que centrarse a la hora de construir estos sistemas y cómo hacerlos eficaces y prácticos en aplicaciones del mundo real.
Diseñar el proceso de diálogo
El núcleo de cualquier herramienta de diálogo es su flujo de diálogo, es decir, los pasos que sigue el sistema para procesar las entradas del usuario y generar respuestas. En el caso de las herramientas avanzadas basadas en GAR, el diseño del flujo de diálogo debe planificarse cuidadosamente para aprovechar al máximo las capacidades de recuperación del sistema GAR y la generación de modelos lingüísticos. Este flujo suele constar de varias fases clave:
Evaluación y replanteamiento del problema::
- El sistema evalúa primero la pregunta formulada por el usuario y determina si es necesario reformatearla para proporcionar el contexto necesario para una respuesta precisa. Si la pregunta es demasiado vaga o carece de detalles clave, el sistema puede reformatearla en una consulta independiente, asegurándose de que se incluye toda la información necesaria.
Comprobación de pertinencia y encaminamiento::
- Una vez que la pregunta está correctamente formateada, el sistema busca los datos pertinentes en el almacén vectorial (una base de datos que contiene información indexada). Si se encuentra información relevante, la pregunta se envía a la aplicación RAG, que recupera la información necesaria para generar una respuesta.
- Si no hay información relevante en el almacén de vectores, el sistema debe decidir si continúa con la respuesta generada únicamente por el modelo lingüístico o si solicita al sistema RAG que declare que no se puede proporcionar una respuesta satisfactoria.
Generar una respuesta::
- En función de las decisiones tomadas en el paso anterior, el sistema utiliza los datos recuperados para generar respuestas detalladas o se basa en el conocimiento del modelo lingüístico y el historial de diálogos para responder al usuario. Este enfoque garantiza que la herramienta sea capaz de hacer frente a problemas del mundo real y, al mismo tiempo, dar cabida a diálogos más informales y abiertos.
Optimizar los procesos de diálogo mediante mecanismos de toma de decisiones
Un aspecto importante a la hora de construir herramientas avanzadas de diálogo GAR es implantar mecanismos de toma de decisiones que controlen el flujo del diálogo. Estos mecanismos ayudan al sistema a decidir de forma inteligente cuándo recuperar información, cuándo confiar en las capacidades generativas y cuándo informar al usuario de que no hay datos relevantes disponibles. Gracias a estas decisiones, la herramienta puede ser más flexible y adaptarse a distintos escenarios de diálogo.
- Punto de decisión 1: ¿Reinventarse o continuar?
En primer lugar, el sistema decide si la pregunta del usuario puede tratarse tal cual o si es necesario reformularla. Este paso garantiza que el sistema comprenda la intención del usuario y disponga de todo el contexto necesario para permitir una recuperación o generación eficaz antes de generar una respuesta. - Punto de decisión 2: ¿Recuperar o generar?
En caso de que sea necesaria una remodelación, el sistema determina si hay información relevante en el almacén de vectores. Si se encuentran datos relevantes, el sistema utilizará el GAR para recuperar y generar la respuesta. En caso contrario, el sistema debe decidir si se basa únicamente en el modelo lingüístico para generar la respuesta. - Punto de decisión 3: ¿Informar o interactuar?
Si ni el almacén de vectores ni el modelo lingüístico pueden ofrecer una respuesta satisfactoria, el sistema informa al usuario de que no dispone de información relevante, manteniendo así la transparencia y la credibilidad del diálogo.
Cómo diseñar indicaciones eficaces para los GAR conversacionales
Las instrucciones desempeñan un papel fundamental a la hora de guiar el comportamiento conversacional de los modelos lingüísticos. Para diseñar instrucciones eficaces, es necesario comprender claramente la información contextual, los objetivos de la interacción y el estilo y el tono deseados. Por ejemplo:
- información general: Proporcionar información contextual pertinente para garantizar que el modelo lingüístico capte el contexto necesario al generar o adaptar las preguntas.
- Consejos orientados a los objetivosAclarar el propósito de cada pregunta, por ejemplo, para adaptar la pregunta, decidir sobre un proceso de recuperación o generar una respuesta.
- Estilo y tonoEspecificar el estilo deseado (por ejemplo, formal, informal) y el tono (por ejemplo, informativo, empático) para garantizar que el resultado del modelo lingüístico cumple las expectativas de la experiencia del usuario.
La creación de herramientas de diálogo con técnicas avanzadas de GAR requiere una estrategia integrada que combine los puntos fuertes de la recuperación y la generación. Diseñando cuidadosamente los flujos de diálogo, aplicando mecanismos inteligentes de toma de decisiones y desarrollando instrucciones eficaces, los desarrolladores pueden crear herramientas de IA que ofrezcan respuestas precisas y ricas en contexto, así como interacciones naturales y significativas con los usuarios.
¿Cómo crear aplicaciones RAG avanzadas?
Está muy bien empezar construyendo una aplicación básica de Generación Aumentada de Recuperación (RAG), pero para aprovechar todo el potencial de RAG en escenarios más complejos, hay que ir más allá de lo básico. En esta sección se describe cómo crear una aplicación RAG avanzada que potencie el proceso de recuperación, mejore la precisión de la respuesta e implemente técnicas avanzadas como la reescritura de consultas y la recuperación multietapa.
Antes de sumergirnos en las técnicas avanzadas, repasemos brevemente la funcionalidad básica de una aplicación RAG, que combina las capacidades de un modelo lingüístico (LLM) con una base de conocimientos externa para responder a las consultas de los usuarios. Este proceso suele constar de dos fases:
- recuperar (datos)La aplicación busca fragmentos de texto en bases de datos vectoriales u otras bases de conocimiento que sean relevantes para la consulta del usuario.
- leerEl texto recuperado se transmite al LLM para que genere una respuesta basada en estos contextos.
Este enfoque de "búsqueda y lectura" proporciona a LLM la información de base necesaria para dar respuestas más precisas a las consultas que requieren conocimientos especializados.
Los pasos para crear una aplicación RAG avanzada son los siguientes:
Paso 1: Utilizar técnicas avanzadas para mejorar la recuperación
La etapa de recuperación es fundamental para la calidad de la respuesta final. En una aplicación GAR básica, el proceso de recuperación es relativamente sencillo, pero en una aplicación GAR avanzada, puede utilizar las siguientes mejoras:
1. Búsqueda por etapas
Las búsquedas multietapa ayudan a seleccionar los contextos más relevantes afinando la búsqueda en varios pasos. Suele incluir:
- Búsqueda inicial ampliaComienza con una búsqueda amplia de documentos potencialmente relevantes.
- Refinar la búsquedaBúsqueda más precisa basada en los resultados preliminares y limitada a los segmentos más relevantes.
Este método mejora la precisión de la información recuperada, lo que a su vez proporciona respuestas más exactas.
2. Reescritura de consultas
La reescritura de consultas convierte la consulta de un usuario en un formato que tiene más probabilidades de arrojar resultados relevantes en una búsqueda. Esto puede lograrse de varias maneras:
- reescritura de muestra ceroReescribir consultas sin ejemplos concretos, basándose en la comprensión lingüística del modelo.
- Muestra menos reescrituraSe proporcionan ejemplos para ayudar a los modelos a reescribir consultas similares para mejorar la precisión.
- Reescritores a medidaEl modelo dedicado a la reescritura de consultas se perfecciona para gestionar mejor las consultas específicas del dominio.
Estas consultas reescritas se ajustan mejor al lenguaje y la estructura de los documentos de la base de conocimientos, lo que mejora la precisión de la recuperación.
3. Descomposición de subconsultas
En el caso de las consultas complejas que incluyen varias preguntas o aspectos, descomponer la consulta en varias subconsultas puede mejorar la recuperación. Cada subconsulta se centra en un aspecto concreto de la pregunta original, de modo que el sistema puede recuperar el contexto pertinente para cada parte e integrar las respuestas.
Paso 2: Mejorar la generación de respuestas
Una vez mejorado el proceso de recuperación, el siguiente paso consiste en optimizar el modo en que Big Language Model genera las respuestas:
1. Consejos para retroceder
Ante preguntas complejas o de varios niveles, puede ser útil generar consultas adicionales más amplias. Estas sugerencias "de emergencia" pueden ayudar a recuperar una gama más amplia de información contextual, lo que permite al Big Language Model generar respuestas más completas.
2. Incrustación hipotética de documentos (HyDE)
HyDE es una técnica de vanguardia que capta la intención de una consulta generando documentos hipotéticos basados en la consulta del usuario y, a continuación, utilizando estos documentos para encontrar documentos reales coincidentes en una base de conocimientos. Este enfoque es especialmente adecuado cuando la consulta no es semánticamente similar al contexto pertinente.
Paso 3: Integrar los circuitos de retroalimentación
Para mejorar continuamente el rendimiento de las aplicaciones GAR, es importante integrar circuitos de retroalimentación en el sistema:
1. Comentarios de los usuarios
Incorporar un mecanismo que permita a los usuarios evaluar la pertinencia y precisión de las respuestas. Esta retroalimentación puede utilizarse para ajustar el proceso de recuperación y generación.
2. Mejora del aprendizaje
Mediante técnicas de aprendizaje por refuerzo, los modelos se entrenan en función de los comentarios de los usuarios y otros parámetros de rendimiento. Esto permite al sistema aprender de sus errores y mejorar su precisión y relevancia con el tiempo.
Paso 4: Ampliación y optimización
A medida que avanzan las aplicaciones RAG, el escalado y la optimización del rendimiento cobran cada vez más importancia:
1. Búsqueda distribuida
Para hacer frente a bases de conocimiento a gran escala, se implementan sistemas de recuperación distribuidos que pueden procesar tareas de recuperación en paralelo a través de múltiples nodos, reduciendo así la latencia y aumentando la velocidad de procesamiento.
2. Estrategia de caché
La aplicación de una estrategia de almacenamiento en caché de los bloques de contexto a los que se accede con frecuencia reduce la necesidad de recuperarlos repetidamente y acelera los tiempos de respuesta.
3. Optimización de modelos
Optimización de grandes modelos lingüísticos y otros modelos utilizados en la aplicación para reducir la carga computacional manteniendo la precisión. Técnicas como la destilación de modelos y la cuantificación son muy útiles en este caso.
La creación de una aplicación GAR avanzada requiere un profundo conocimiento de los mecanismos de recuperación y los modelos de generación, así como la capacidad de implantar y optimizar tecnologías complejas. Siguiendo los pasos descritos anteriormente, podrá crear un sistema avanzado de GAR que supere las expectativas de los usuarios y ofrezca respuestas de alta calidad y contextualmente precisas para una gran variedad de escenarios de aplicación.
El auge de los grafos de conocimiento en las GAR avanzadas
El papel de los grafos de conocimiento en los sistemas avanzados de generación de aumento de la recuperación (RAG) ha cobrado especial importancia a medida que las organizaciones confían cada vez más en la IA para tareas complejas basadas en datos.Según Gartner. El grafo del conocimiento es una de las tecnologías de vanguardia que promete perturbar varios mercados en el futuro.Tecnologías emergentes que afectan al radar ha señalado que los grafos de conocimiento son herramientas de apoyo fundamentales para las aplicaciones avanzadas de IA, y proporcionan la base para la gestión de datos, la capacidad de razonamiento y la fiabilidad de los resultados de la IA. Esto ha llevado al uso generalizado de los grafos de conocimiento en diversos sectores, como la sanidad, las finanzas y el comercio minorista.
¿Qué es el Gráfico del Conocimiento?
Un grafo de conocimiento es una representación estructurada de la información en la que se definen explícitamente las entidades (nodos) y las relaciones entre ellas (aristas). Estas entidades pueden ser objetos concretos (como personas y lugares) o conceptos abstractos. Las relaciones entre entidades ayudan a construir una red de conocimiento que hace que la recuperación de datos, el razonamiento y la inferencia sean más humanamente cognitivos. Más que almacenar datos, el grafo de conocimiento capta las relaciones ricas y matizadas dentro de un dominio, lo que lo convierte en una poderosa herramienta en aplicaciones de IA.
Mejora y planificación de consultas con grafos de conocimiento
La mejora de las consultas es una solución al problema de las preguntas poco claras en el sistema GAR. El objetivo es añadir el contexto necesario a una consulta para garantizar que incluso las preguntas vagas puedan interpretarse con precisión. Por ejemplo, en el ámbito financiero, preguntas como "¿Cuáles son los retos actuales en la aplicación de la normativa financiera?" Preguntas como "¿Cuáles son los retos actuales en la aplicación de la regulación financiera?" pueden mejorarse para incluir entidades específicas como "cumplimiento AML" o "proceso KYC" para centrar el proceso de búsqueda en la información más relevante.
En el ámbito jurídico, preguntas como "¿Cuáles son los riesgos asociados a los contratos?" pueden ampliarse añadiendo tipos de contrato específicos, como "contrato laboral" o "acuerdo de servicios", en función del contexto proporcionado por el grafo de conocimiento.
La planificación de consultas, por su parte, descompone las consultas complejas en partes manejables generando subpreguntas. Esto garantiza que el sistema RAG pueda recuperar e integrar la información más relevante para ofrecer una respuesta completa. Por ejemplo, para responder a la pregunta "¿Cómo afectarán a la empresa las nuevas normas de información financiera?" el sistema podría recuperar primero datos sobre cada una de las normas de información, los plazos de aplicación y las repercusiones históricas en las distintas áreas.
En el ámbito médico, una pregunta como "¿Cuáles son los últimos avances en dispositivos médicos?" puede desglosarse en subpreguntas que exploren los avances en áreas específicas, como "dispositivos implantables", "dispositivos de diagnóstico" o "herramientas quirúrgicas", lo que garantiza que el sistema obtenga información detallada y relevante de cada subcategoría. información detallada y pertinente de cada subcategoría.
Mediante la mejora y planificación de las consultas, el grafo de conocimiento ayuda a optimizar y estructurar las consultas para mejorar la precisión y pertinencia de la recuperación de información, lo que en última instancia proporciona respuestas más precisas y útiles en ámbitos complejos como las finanzas, el derecho y la sanidad.
El papel de los grafos de conocimiento en el GAR
En los sistemas de generación mejorada por recuperación (RAG), los grafos de conocimiento mejoran el proceso de recuperación y generación proporcionando datos estructurados y ricos en contexto. Los sistemas RAG tradicionales se basan en texto no estructurado y bases de datos vectoriales, lo que puede dar lugar a una recuperación de información imprecisa o incompleta. Mediante la integración de grafos de conocimiento, los sistemas RAG son capaces de:
- Mejor comprensión de las consultas: Los gráficos de conocimiento ayudan al sistema a comprender mejor el contexto y las relaciones de una consulta y, por tanto, a recuperar los datos pertinentes con mayor precisión.
- Generación de respuestas mejorada: Los datos estructurados que proporciona el grafo de conocimiento pueden generar respuestas más coherentes y contextualmente relevantes, reduciendo el riesgo de errores de IA.
- Aplicación del razonamiento complejo: Los grafos de conocimiento admiten el razonamiento multisalto, en el que el sistema puede inferir nuevos conocimientos o conectar información dispar atravesando múltiples relaciones.
Componentes clave del grafo de conocimiento
El grafo de conocimiento consta de los siguientes componentes principales:
- Nodos: Representa diversas entidades o conceptos en el campo del conocimiento, como personas, lugares o cosas.
- Lateral: Describe la relación entre nodos, mostrando cómo están interconectadas estas entidades.
- Atributos: Información adicional o metadatos asociados a nodos y aristas que proporcionan más contexto o detalles.
- Tríada: Los elementos básicos de un grafo de conocimiento son un tema, un predicado y un objeto (por ejemplo, "Einstein" [tema] "descubrimiento" [predicado] "relatividad" [objeto ), estas tripletas constituyen el marco básico para describir las relaciones entre entidades.
Metodología Knowledge Graph-RAG
La metodología KG-RAG consta de tres pasos principales:
- KG Construcción: Este paso consiste en transformar los datos textuales no estructurados en un grafo de conocimiento estructurado, garantizando que los datos estén organizados y sean pertinentes.
- Recuperado: Mediante un novedoso algoritmo de recuperación denominado Cadena de Exploración (CoE), el sistema realiza la recuperación de datos a través del grafo de conocimiento.
- Generación de respuestas: Por último, la información recuperada se utiliza para generar respuestas coherentes y contextualizadas, combinando los datos estructurados del grafo de conocimiento con las capacidades de un gran modelo lingüístico.
Esta metodología pone de relieve el importante papel del conocimiento estructurado para mejorar el proceso de recuperación y generación de los sistemas GAR.
Ventajas de los grafos de conocimiento en el GAR
La incorporación del grafo de conocimiento al sistema GAR aporta varias ventajas significativas:
- Representación estructurada del conocimiento: Los gráficos de conocimiento organizan la información de forma que reflejen las complejas relaciones entre entidades, lo que hace más eficiente la recuperación y el uso de los datos.
- Comprensión contextual: Los gráficos de conocimiento proporcionan información contextual más rica al capturar las relaciones entre entidades, lo que permite al sistema GAR generar respuestas más pertinentes y coherentes.
- Capacidad de razonamiento: La cartografía del conocimiento ayuda al sistema a inferir nuevos conocimientos analizando las relaciones entre entidades para generar respuestas más completas y precisas.
- Integración de conocimientos: Los gráficos de conocimiento pueden integrar información de distintas fuentes para ofrecer una visión más completa de los datos y ayudar a tomar mejores decisiones.
- Interpretabilidad y transparencia: La naturaleza estructurada del grafo de conocimiento hace que la ruta de razonamiento sea clara y comprensible, facilita la explicación del proceso de formación de conclusiones y mejora la credibilidad del sistema.
Integración de KG con LLM-RAG
El uso de grafos de conocimiento en combinación con la modelización de grandes lenguajes (LLM) en los sistemas GAR mejora la representación global del conocimiento y las capacidades de razonamiento. Esta combinación permite la fusión dinámica de conocimientos, lo que garantiza que la información se mantiene actualizada y pertinente en el momento de la inferencia, generando así respuestas más precisas y perspicaces.
Uso de gráficos de conocimiento en cuestionarios de cadenas de pensamiento
El mapeo del conocimiento está ganando terreno en el cuestionario de cadena de pensamiento, especialmente cuando se utiliza junto con el modelado de grandes lenguajes (LLM). Este método consiste en dividir las preguntas complejas en subpreguntas, recuperar la información pertinente y sintetizarla para obtener una respuesta final. Los grafos de conocimiento proporcionan información estructurada en este proceso, reforzando la capacidad de razonamiento del LLM.
Por ejemplo, un agente LLM podría utilizar primero el grafo de conocimiento para identificar entidades relevantes en una consulta, obtener después más información de distintas fuentes y, por último, generar una respuesta completa que refleje el conocimiento interconectado en el grafo.
Aplicaciones prácticas de los grafos de conocimiento
En el pasado, los grafos de conocimiento se utilizaban principalmente en dominios de datos intensivos, como el análisis de grandes volúmenes de datos y los sistemas de búsqueda empresarial, donde su función era mantener la coherencia y uniformidad entre diferentes silos de datos. Sin embargo, con el desarrollo de grandes sistemas RAG basados en modelos lingüísticos, los grafos de conocimiento han encontrado nuevos escenarios de aplicación. Ahora sirven de complemento estructurado a los grandes modelos probabilísticos del lenguaje, ayudando a reducir la información falsa, proporcionar más contexto y actuar como mecanismo de memoria y personalización en los sistemas de IA.
Presentación de GraphRAG
GraphRAG es una metodología de recuperación de última generación que combina grafos de conocimiento y bases de datos vectoriales en una arquitectura RAG (Retrieval Augmented Generation). Este modelo híbrido aprovecha los puntos fuertes de ambos sistemas para ofrecer soluciones de IA más precisas, contextualizadas y fáciles de entender.Gartner ha declarado La creciente importancia de los gráficos de conocimiento para mejorar la estrategia de producto y crear nuevos escenarios de aplicación de la IA.
Entre las funciones de GraphRAG se incluyen:
- Mayor precisión: Al combinar datos estructurados y no estructurados, GraphRAG es capaz de ofrecer respuestas más precisas y completas.
- Escalabilidad: Este enfoque simplifica el desarrollo y mantenimiento de las aplicaciones GAR y permite una mejor escalabilidad.
- Interpretabilidad: GraphRAG proporciona rutas de inferencia claras que aumentan la transparencia del sistema, haciendo que los resultados de la IA sean más fáciles de entender y fiables.
Ventajas de GraphRAG
GraphRAG presenta varias ventajas significativas con respecto a los métodos tradicionales de GAR:
- Respuestas de mayor calidad: La integración del grafo de conocimiento ha mejorado la precisión y la pertinencia de las respuestas generadas por la IA, y las pruebas comparativas recientes muestran que la precisión se ha triplicado.
- Rentabilidad: GraphRAG es más rentable, requiere menos recursos informáticos y datos de entrenamiento, y es una opción atractiva para las organizaciones que buscan optimizar sus inversiones en IA.
- Mejor escalabilidad: Este enfoque admite aplicaciones de IA a gran escala, lo que permite a las organizaciones gestionar fácilmente consultas más complejas y conjuntos de datos más grandes.
- Mejora de la interpretabilidad: El enfoque estructurado de GraphRAG proporciona rutas de inferencia más claras, lo que hace que el proceso de toma de decisiones de la IA sea más transparente y fácil de depurar.
- Revelar conexiones ocultas: Los gráficos de conocimiento pueden revelar relaciones que pasan desapercibidas en los grandes conjuntos de datos, proporcionando una visión más profunda y mejorando la calidad del proceso de toma de decisiones.
Arquitecturas GraphRAG comunes
Varias arquitecturas GraphRAG están surgiendo como formas de integrar eficazmente los grafos de conocimiento en los sistemas RAG:
- Grafos de conocimiento con agrupación semántica: Esta arquitectura mejora la relevancia y precisión de la recuperación de datos agrupando la información relevante antes de generar las respuestas.
- Integración de grafos de conocimiento con bases de datos vectoriales: Esta arquitectura combina los dos sistemas para proporcionar un contexto más rico al modelo lingüístico más amplio, lo que da lugar a la generación de respuestas más completas y adecuadas al contexto.
- Sistema de preguntas y respuestas basado en grafos de conocimiento: En esta arquitectura, el grafo de conocimiento añade información factual a las respuestas generadas por el gran modelo lingüístico tras la recuperación de vectores para garantizar la precisión y exhaustividad de las respuestas.
- Recuperación híbrida mejorada con gráficos: Este enfoque combina búsquedas vectoriales, búsquedas por palabras clave y consultas específicas de grafos para proporcionar un sistema de recuperación potente y flexible que mejora la capacidad de los grandes modelos lingüísticos para generar respuestas pertinentes.
Modelos emergentes para GraphRAG
A medida que GraphRAG sigue evolucionando, empiezan a surgir varios patrones emergentes:
- Mejora de la consulta: Optimice y mejore las consultas utilizando gráficos de conocimiento para garantizar la recuperación de la información más relevante.
- Mejora de la respuesta: Mejorar la precisión y exhaustividad de las respuestas generadas por el Big Language Model añadiendo hechos relevantes.
- Control de respuestas: Utilice gráficos de conocimiento para verificar la exactitud del contenido generado por IA y reducir el riesgo de información incorrecta o falsa.
Estos patrones demuestran cómo GraphRAG está cambiando la forma en que los sistemas de IA procesan consultas complejas y generan respuestas.
Aplicaciones de GraphRAG
- Investigación jurídica: La capacidad de GraphRAG para navegar a través de una compleja red de leyes, jurisprudencia y casos prácticos proporciona a los profesionales del Derecho una potente herramienta que les ayuda a descubrir información jurídica relevante y posibles conexiones.
- Sanidad: En el ámbito sanitario, GraphRAG ayuda a comprender las complejas relaciones existentes entre los conocimientos médicos, el historial del paciente y las opciones de tratamiento para mejorar la precisión del diagnóstico y la planificación personalizada del tratamiento.
- Análisis financiero: GraphRAG ayuda a analizar complejas redes y dependencias financieras, proporcionando información sobre las tendencias del mercado, la gestión del riesgo y las estrategias de inversión utilizando datos interconectados del grafo del conocimiento.
- Análisis de redes sociales: GraphRAG permite explorar complejas estructuras e interacciones sociales, ayudando a investigadores y analistas a comprender las pautas de relación e influencia en las redes sociales.
- Gestión del conocimiento: GraphRAG mejora la base de conocimiento corporativo capturando y aprovechando las relaciones y jerarquías dentro de las organizaciones, mejorando los procesos de toma de decisiones y fomentando la innovación dentro de la empresa.
A medida que avanza la IA, resulta cada vez más importante incorporar grafos de conocimiento a los sistemas de generación de aumentos de recuperación. La aparición de GraphRAG demuestra las ventajas de combinar los grafos de conocimiento con los métodos vectoriales tradicionales, lo que proporciona un planteamiento más completo y eficaz de la recuperación de información y la generación de respuestas.
RAG avanzada: ampliar horizontes mediante la generación mejorada con recuperación multimodal
Los avances en inteligencia artificial han ido acompañados de grandes progresos que siguen ampliando los límites de la comprensión y la generación automáticas. Mientras que los sistemas tradicionales de Generación Aumentada de Recuperación (GAR) se han centrado principalmente en datos textuales, la aparición de la GAR multimodal marca un importante salto tecnológico. Esta innovadora tecnología permite a la IA procesar e integrar múltiples formas de datos -como texto, imágenes, audio y vídeo- para generar resultados ricos en contenido y contextualizados. Al aprovechar los datos multimodales, estos sistemas avanzados de IA se vuelven más flexibles, sensibles al contexto y capaces de ofrecer una visión más profunda y respuestas más precisas. Esta sección explora los conceptos básicos, los mecanismos operativos y las aplicaciones potenciales de la GAR multimodal, destacando su importancia en la próxima generación de interacciones de IA.
Comprender el GAR multimodal
La RAG multimodal es una extensión avanzada del marco clásico de la RAG que combina mecanismos de recuperación con IA generativa para múltiples tipos de datos. Mientras que los sistemas RAG tradicionales obtienen información consultando bases de datos textuales, el RAG multimodal amplía esta capacidad integrando texto, imágenes, audio y vídeo en el proceso de recuperación y generación. Esta ampliación permite a los modelos de IA aprovechar una gama más amplia de entradas para generar resultados más completos y matizados.
¿Cómo funciona el GAR multimodal?
El flujo de trabajo de un GAR multimodal consiste en codificar distintos tipos de datos en un formato estructurado, normalmente vectores, para que el modelo de IA pueda procesarlos. Estos vectores se almacenan en un espacio de incrustación compartido que contiene datos de distintas modalidades. Cuando se realiza una consulta, el modelo recupera la información pertinente de estas modalidades, garantizando así una respuesta más rica y precisa. Por ejemplo, para una consulta sobre un acontecimiento histórico, el sistema puede recuperar descripciones textuales, imágenes relevantes, clips de audio de comentarios de expertos y secuencias de vídeo, que juntos forman una respuesta más detallada e informativa.
Métodos de aplicación de los GAR multimodales
Hay varios enfoques que pueden adoptarse para realizar un GAR multimodal, cada uno con sus propias ventajas y retos:
- Un único modelo multimodal:
Este enfoque utiliza un modelo unificado que se entrena para codificar diversos tipos de datos -por ejemplo, texto, imágenes, audio- en un espacio vectorial común. A continuación, el modelo puede recuperar y generar sin problemas todos estos tipos de datos. Aunque este enfoque simplifica el proceso al utilizar un único modelo, requiere un entrenamiento complejo para garantizar una codificación y recuperación precisas de los datos multimodales. - Modalidad base basada en texto:
En este enfoque, los datos no textuales se convierten en descripciones textuales antes de su codificación y almacenamiento. Este enfoque aprovecha los modelos de texto más avanzados. Sin embargo, puede haber pérdida de información durante el proceso de conversión, ya que los matices de la imagen o el audio pueden no estar totalmente representados en el texto. - Codificadores múltiples:
Este planteamiento utiliza diferentes modelos para codificar distintos tipos de datos, cada uno de ellos gestionado por su propio modelo especializado. El proceso de recuperación integrará estos resultados. Aunque este enfoque permite una codificación más especializada y una recuperación de datos más precisa, aumenta la complejidad del sistema y exige una gestión cuidadosa de los múltiples modelos y sus interacciones.
Arquitectura de un GAR multimodal
La arquitectura del GAR multimodal se basa en los fundamentos de los GAR tradicionales, al tiempo que incorpora la complejidad de tratar con múltiples tipos de datos. La arquitectura central incluye los siguientes componentes clave:
- Codificadores modales específicos:
Cada modalidad de datos, como texto, imagen o audio, es procesada por un codificador especializado. Estos codificadores convierten los datos brutos en un espacio de incrustación uniforme, lo que permite comparar y recuperar todas las modalidades de forma normalizada. - Espacio empotrado compartido:
Un componente clave del GAR multimodal es el espacio de incrustación compartido, que almacena vectores codificados de distintas modalidades. Este espacio permite realizar comparaciones y recuperaciones intermodales, lo que permite al modelo reconocer información relevante en distintos tipos de datos. - Retriever:
El componente Recuperador se encarga de consultar el espacio de incrustación compartido para encontrar los puntos de datos más relevantes en todas las modalidades. Puede recuperar información basándose en varios criterios, como la relevancia de la consulta o la similitud con otros puntos de datos del espacio. - Generador:
Una vez recuperada la información pertinente, el componente generador integra estos datos en la respuesta del modelo de IA. El generador suele ser un modelo lingüístico complejo capaz de entrelazar información procedente de múltiples modalidades en un resultado coherente y contextualmente preciso. - Mecanismos de integración:
El mecanismo de fusión se encarga de combinar los datos multimodales recuperados en una representación unificada para uso del generador. Este proceso puede implicar la selección de las modalidades más relevantes o la síntesis de información procedente de distintas fuentes para crear una respuesta global.
Hay varias estrategias clave que deben emplearse para gestionar la información de las distintas modalidades en un sistema GAR:
- Uniformemente incrustado en el espacio:
La codificación de todos los tipos de datos en un espacio de incrustación común permite al sistema realizar con eficacia operaciones de recuperación intermodal. Al mismo tiempo, este espacio de incrustación proporciona una base para integrar y alinear datos de distintas fuentes. - Mecanismos de atención intermodal:
El uso de un mecanismo de atención intermodal garantiza que el modelo sea capaz de centrarse en la información más relevante de los datos recuperados, independientemente de la modalidad de la que procedan. Esto ayuda a equilibrar la importancia de cada tipo de datos en la respuesta final. - Posprocesamiento específico de la modalidad:
Una vez finalizada la recuperación, puede ser necesario un posprocesamiento específico de los datos para cada modalidad, como cambiar el tamaño de las imágenes o normalizar el audio, para garantizar que los datos estén optimizados para su integración y generación.
RAG multimodal en chatbots
Los GAR multimodales mejoran enormemente las capacidades de los chatbots, permitiéndoles ofrecer experiencias interactivas más ricas y contextualizadas. Los chatbots tradicionales se basan principalmente en el texto, lo que limita su capacidad para responder a información que implique la vista o el oído. Las RAG multimodales permiten a los chatbots captar e integrar información de imágenes, vídeos y clips de audio para ofrecer una experiencia de usuario más completa e interesante.
Por ejemplo, utilizando los GAR multimodales Chatbot de atención al cliente En respuesta a la consulta de un usuario, pueden mostrarse vídeos instructivos, imágenes de productos o audioguías, lo que permite una ayuda más interactiva y práctica. Esto es especialmente importante en sectores como el comercio minorista, la sanidad y la educación, donde la comunicación a menudo debe apoyarse en múltiples formas de información.
Ampliación de las aplicaciones RAG multimodales
La introducción de funciones multimodales está abriendo nuevas oportunidades en diversos sectores:
- Sanidad:
Los GAR multimodales pueden combinar historias clínicas textuales, imágenes radiológicas, resultados de laboratorio y descripciones sonoras de pacientes para mejorar la precisión y exhaustividad de los sistemas de diagnóstico. - Finanzas:
En los servicios financieros, el GAR multimodal es capaz de procesar y analizar documentos complejos que contienen tablas, gráficos y texto explicativo para mejorar el proceso de toma de decisiones. - Educación:
Las plataformas educativas pueden utilizar el GAR multimodal para combinar texto, videoconferencias, ilustraciones y simulaciones interactivas en un relato didáctico completo, proporcionando una experiencia de aprendizaje más rica.
La GAR multimodal es un importante avance tecnológico que puede cambiar la forma en que los sistemas de IA interactúan con los usuarios y responden a ellos. Al incorporar múltiples tipos de datos al proceso de recuperación y generación, los sistemas de GAR multimodal pueden proporcionar resultados más ricos, precisos y contextualizados, abriendo nuevas posibilidades en todos los sectores. A medida que la tecnología evolucione, se espera que sus aplicaciones se amplíen para mejorar aún más la capacidad de la IA de procesar información multimodal compleja.
Cómo la plataforma de coordinación GenAI de LeewayHertz, ZBrain, destaca entre los sistemas RAG avanzados.
¿Siente curiosidad por la RAG avanzada, la RAG multimodal y los gráficos de conocimiento? Imagine combinar estas potentes funciones en una única plataforma que le permita crear fácilmente aplicaciones avanzadas de IA. Eso es ZBrain.
ZBrainDesarrollada por LeewayHertz, ZBrain es una plataforma de orquestación integral diseñada para simplificar y acelerar el desarrollo y escalado de soluciones de IA de clase empresarial. A través de su entorno fácil de usar y de bajo código, ZBrain permite a las organizaciones crear, desplegar y escalar rápidamente aplicaciones personalizadas de IA generativa (GenAI) con un esfuerzo de codificación reducido. La plataforma revoluciona el proceso de desarrollo de IA empresarial al permitir a las organizaciones aprovechar sus propios datos para crear aplicaciones de IA altamente personalizadas y precisas. Como centro de control central, ZBrain se integra a la perfección con las pilas tecnológicas existentes para mejorar la eficiencia del desarrollo de aplicaciones GenAI. Las aplicaciones creadas con ZBrain destacan en tareas de procesamiento del lenguaje natural (PLN) como la generación de informes, la traducción, el análisis de datos, la clasificación y el resumen de textos. Al aprovechar los datos privados y contextuales, ZBrain garantiza que las respuestas sean altamente relevantes y personalizadas para satisfacer necesidades empresariales específicas.
Cómo interactuar con sistemas avanzados de Generación de Aumento de la Recuperación (RAG)
- Integración de diversas fuentes de datos: ZBrain integra diversas fuentes de datos, como flujos privados, públicos y en tiempo real, en todos los formatos de datos (estructurados, semiestructurados y no estructurados) para mejorar la precisión y relevancia de las respuestas de la IA.
- Optimización a nivel de bloque: La plataforma garantiza que se generen resultados precisos y adaptados al usuario, desglosando la información en fragmentos manejables y aplicando las estrategias de búsqueda más eficaces.
- Descubrimiento automático de estrategias de recuperación: Los algoritmos avanzados de ZBrain identifican y aplican automáticamente estrategias de búsqueda óptimas, reduciendo las acciones manuales basadas en datos y contexto y mejorando la precisión de la recuperación de datos.
- Medidas de protección y control de las alucinaciones: ZBrain está equipado con salvaguardas y controles fantasma para evitar la generación de información inexacta o engañosa, lo que garantiza una gran precisión y fiabilidad.
capacidad multimodal
- Maneja múltiples formatos de datos. ZBrain destaca en el manejo de múltiples formatos de datos como texto, imágenes, vídeo y audio, proporcionando una respuesta completa y detallada.
- Integración y análisis de distintos tipos de datos. La plataforma es capaz de integrar y analizar varios tipos de datos para ofrecer perspectivas más ricas y respuestas pertinentes.
- Mejora del procesamiento de consultas. ZBrain gestiona y recupera eficazmente información de múltiples modalidades de datos, mejorando la precisión y la comprensión de problemas complejos.
mapa del conocimiento
- Marco de datos estructurados. ZBrain organiza los datos en una red estructurada que mejora la precisión de la recuperación y proporciona una visión más profunda al conectar conceptos relacionados.
- Conocimiento más profundo de los datos. La naturaleza interconectada del grafo de conocimiento permite a ZBrain ofrecer respuestas matizadas y contextualizadas que conducen a perspectivas más ricas y significativas.
- Capacidades de datos ampliadas. ZBrain permite ampliar los datos a nivel de bloque o archivo, actualizar la metainformación y generar ontologías para mejorar la representación, organización y recuperación de datos.
Ventajas de utilizar ZBrain en el desarrollo de soluciones empresariales de IA
ZBrain ofrece muchas ventajas para el desarrollo de soluciones empresariales de IA, entre las que se incluyen:
- escalabilidad
ZBrain facilita la escalabilidad de las soluciones de IA para gestionar volúmenes de datos y escenarios de uso cada vez mayores sin comprometer el rendimiento. - Integración eficaz
La plataforma se integra fácilmente con las pilas tecnológicas existentes, lo que reduce el tiempo y los costes de implantación y acelera la adopción de la IA. - personalización
ZBrain apoya el desarrollo de aplicaciones de IA altamente personalizadas que satisfacen necesidades empresariales específicas y se alinean con los objetivos de la organización. - Eficacia de los recursos
Su naturaleza de bajo código reduce la necesidad de un gran número de desarrolladores y es adecuada para organizaciones con equipos técnicos más pequeños. - Soluciones integrales
Desde el desarrollo hasta la implantación, ZBrain cubre todo el ciclo de vida de una aplicación de IA, lo que la convierte en una solución integral. - Despliegue neutral en la nube
ZBrain es neutral con respecto a la nube, lo que permite que las aplicaciones se desplieguen en una variedad de plataformas en la nube, proporcionando flexibilidad para adaptarse a diferentes necesidades organizativas y preferencias de infraestructura.
El avanzado sistema RAG de ZBrain, su soporte multimodal y su sólida integración de gráficos de conocimiento la convierten en una potente plataforma que ofrece mayor precisión, eficacia y conocimiento en una amplia gama de aplicaciones.
nota
Los avances en Retrieval-Augmented Generation (RAG) han aumentado drásticamente sus capacidades, permitiéndole superar las limitaciones anteriores y abrir nuevas posibilidades en la recuperación y generación de información impulsada por IA. Mediante el uso de sofisticados mecanismos de recuperación, la RAG avanzada puede acceder a grandes cantidades de datos para garantizar que las respuestas generadas sean precisas y contextualmente relevantes. Este avance allana el camino para aplicaciones de IA más dinámicas e interactivas, lo que convierte a la GAR en una herramienta importante en ámbitos como la atención al cliente, la investigación, la gestión del conocimiento y la creación de contenidos. La aplicación de estas tecnologías avanzadas de GAR ofrece a las organizaciones la oportunidad de mejorar la experiencia del usuario, agilizar los procesos y resolver problemas complejos con mayor precisión y eficacia.
La introducción de la GAR Multimodal y la GAR Knowledge Graph mejora aún más las capacidades de este marco, impulsando su adopción generalizada en todos los sectores. La RAG multimodal combina datos textuales, visuales y de otros tipos, lo que permite al modelo de lenguaje amplio (LLM) generar respuestas más completas y contextualizadas que mejoran la experiencia del usuario y proporcionan información más rica y matizada. Y Knowledge Graph RAG utiliza estructuras de datos interconectadas para recuperar y generar contenidos semánticamente ricos, mejorando enormemente la precisión y profundidad de la información. Estos avances en la tecnología RAG anuncian una nueva ola de innovación en IA, que ofrece soluciones más inteligentes y flexibles a los complejos retos de la recuperación de información.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...