
PDF gratuito de Fundamentos de grandes modelos de la Universidad de Zhejiang - con enlace de descarga
Últimos recursos sobre IAPublicado hace 7 meses Círculo de intercambio de inteligencia artificial 43.6K 00

Fundamentos de los grandes modelos ofrece un análisis en profundidad de las tecnologías básicas y las vías prácticas de los grandes modelos lingüísticos (LLM). Partiendo de la teoría básica del modelado lingüístico, explica sistemáticamente los principios del diseño de modelos basados en arquitecturas estadísticas, de redes neuronales recurrentes (RNN) y de transformadores, centrándose en las tres arquitecturas principales de los grandes modelos lingüísticos (sólo codificador, codificador-decodificador, sólo decodificador) y en modelos representativos (por ejemplo, BERT, T5, serie GPT). El libro explica tecnologías clave como la ingeniería de prompts, el ajuste eficiente de parámetros, la edición de modelos y la generación de mejoras de recuperación. Combinado con ricos estudios de casos, el libro demuestra prácticas de aplicación en diferentes escenarios, proporcionando a los lectores un aprendizaje exhaustivo y en profundidad y una guía práctica, ayudando a los lectores a dominar la aplicación y optimización de las tecnologías de grandes modelos lingüísticos.

Conceptos básicos de modelado lingüístico
- Modelización lingüística basada en métodos estadísticosUn análisis en profundidad de los modelos de n-gramas y las estadísticas que los sustentan, incluidos los supuestos de Markov y la estimación de gran verosimilitud.
- Modelización lingüística basada en RNNExplicación detallada de las características estructurales de las redes neuronales recurrentes (RNN), problemas comunes de desaparición y explosión del gradiente en el entrenamiento, y aplicaciones prácticas en la modelización del lenguaje.
- Modelización lingüística basada en transformadoresAnálisis exhaustivo de los componentes básicos de la arquitectura Transformer, como el mecanismo de autoatención, las redes neuronales feed-forward (FFN), la normalización de capas y la conectividad residual, y su aplicación eficaz en el modelado del lenguaje.
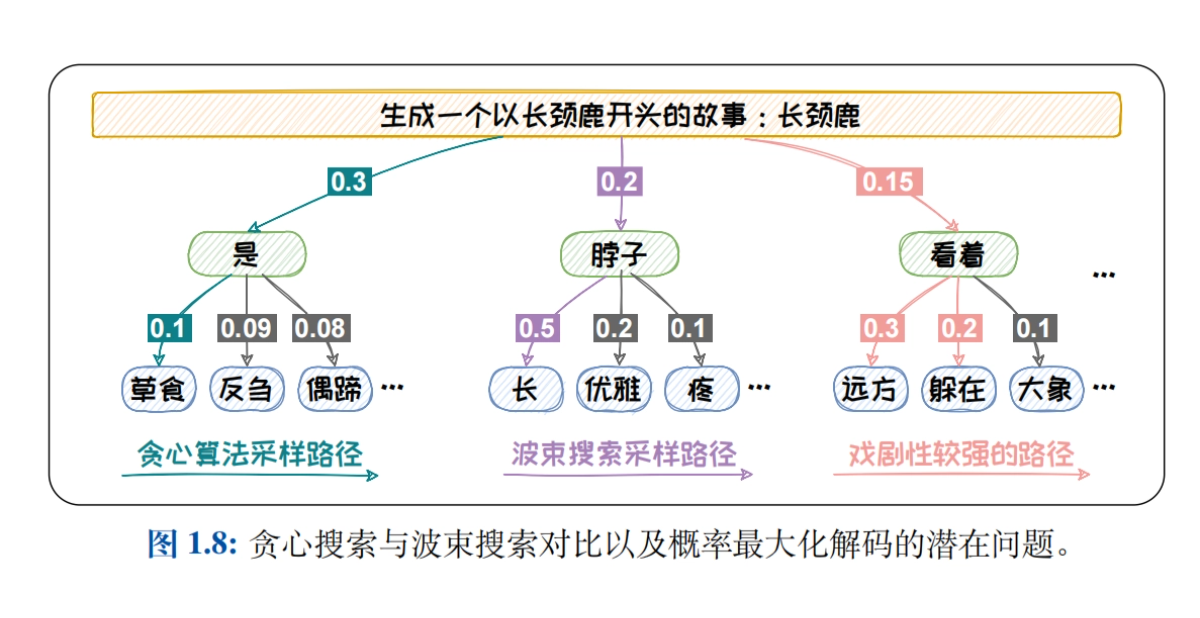
- Métodos de muestreo para la modelización lingüística: Se introducen sistemáticamente estrategias de descodificación como Greedy Search, Beam Search, Top-K Sampling, Top-P Sampling y el mecanismo de temperatura para explorar el impacto de las distintas estrategias en la calidad del texto generado.
- Revisión de los modelos lingüísticosSe presentan descripciones detalladas de las rúbricas intrínsecas (p. ej., perplejidad) y extrínsecas (p. ej., BLEU, ROUGE, BERTScore, G-EVAL) para analizar los puntos fuertes y las limitaciones de cada rúbrica en la evaluación del rendimiento de los modelos lingüísticos.
Arquitectura del modelo Big Language
- Big Data + Big Models → Nueva inteligenciaA continuación se ofrece un análisis en profundidad del impacto del tamaño del modelo y del tamaño de los datos en la capacidad del modelo, una explicación detallada de las Leyes de Escalado (como la Ley de Kaplan-McCandlish y la Ley de Chinchilla) y un análisis de cómo mejorar el rendimiento del modelo optimizando el tamaño del modelo y de los datos.
- Visión general de la arquitectura del modelo Big Language: Compara y analiza los mecanismos de atención y las tareas aplicables de tres arquitecturas principales, Encoder-only, Encoder-Decoder y Decoder-only, para ayudar a los lectores a comprender las características y ventajas de las distintas arquitecturas.
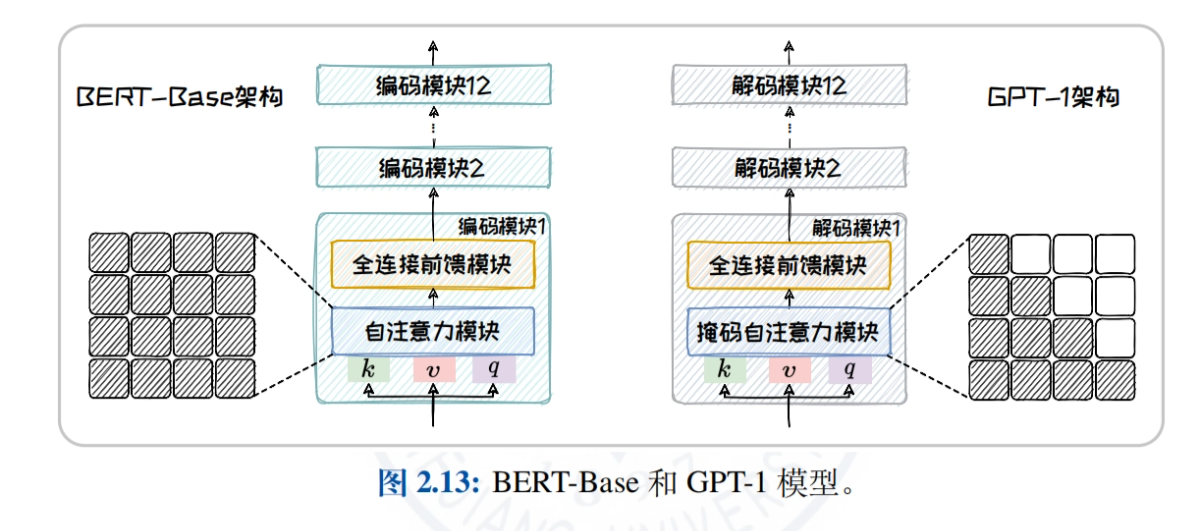
- Arquitectura de sólo codificadorEn este artículo, tomando BERT como ejemplo, explicamos en profundidad la estructura de su modelo, las tareas de preentrenamiento (p. ej., MLM, NSP) y los modelos derivados (p. ej., RoBERTa, ALBERT, ELECTRA) para explorar la aplicación del modelo en tareas de comprensión del lenguaje natural.
- Arquitectura codificador-decodificadorT5 y BART se utilizan como ejemplos para presentar el marco unificado de generación de textos y diversas tareas de preentrenamiento, así como para analizar el rendimiento de los modelos en tareas como la traducción automática y el resumen de textos.
- Arquitectura de sólo descodificadorLa historia del desarrollo y las características de la familia GPT (de GPT-1 a GPT-4) y la familia LLaMA (LLaMA1/2/3) se describen en detalle, explorando las ventajas de los modelos para tareas de generación de texto de dominio abierto.
- arquitectura sin transformadorIntroducción de modelos de espacio de estados (SSM) como RWKV, Mamba y el paradigma Training While Testing (TTT), explorando el potencial de arquitecturas no convencionales para su aplicación en escenarios específicos.
Ingeniería Prompt
- Introducción al proyecto PromptDefine Prompt y Prompt Engineering, explica en detalle el proceso de desambiguación y vectorización (Tokenization, Embedding), y explora cómo generar texto de alta calidad mediante un modelo bootstrap Prompt bien diseñado.
- Aprendizaje en contexto (ICL)Introducción a los conceptos de aprendizaje de muestra cero, muestra única y pocas muestras, exploración de estrategias de selección de ejemplos (por ejemplo, similitud y diversidad) y análisis de cómo puede utilizarse el aprendizaje contextual para mejorar la adaptabilidad de los modelos a las tareas.
- Cadena de pensamiento (CoT)Explicar los tres modos de CoT: paso a paso (por ejemplo, CoT, Zero-Shot CoT, Auto-CoT), think-through (por ejemplo, ToT, GoT), y brainstorming (por ejemplo, Self-Consistency), y explorar cómo mejorar el razonamiento de los modelos a través de la cadena de pensamiento.
- ConsejosPresenta técnicas como la estandarización de la redacción de las preguntas clave, el resumen racional de las preguntas, el uso de los TdC en el momento adecuado y el buen uso de las pistas psicológicas (por ejemplo, juegos de rol, sustitución situacional) para ayudar a los lectores a mejorar el diseño de sus preguntas clave.
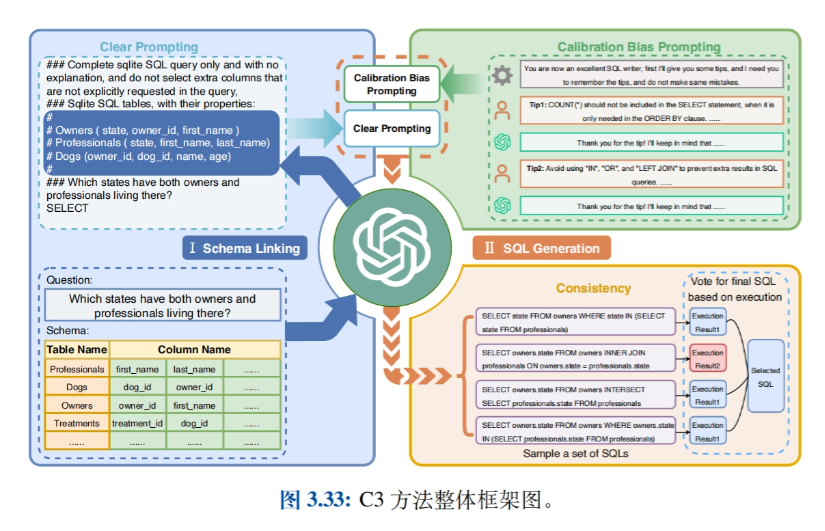
- Aplicaciones relacionadasPresentación de aplicaciones como Big Model-based Intelligentsia (Agentes), Data Synthesis, Text-to-SQL, GPTS, etc., y exploración de casos prácticos de uso de Prompt Engineering en diferentes dominios.
Ajuste eficaz de los parámetros
- Introducción al ajuste eficaz de los parámetrosEl objetivo de este artículo es presentar los dos enfoques dominantes en la adaptación de tareas en sentido descendente -el aprendizaje del contexto y el ajuste fino de las instrucciones- para llegar a la técnica de Ajuste Fino Eficaz de Parámetros (PEFT, por sus siglas en inglés), detallando las importantes ventajas en términos de reducción de costes y eficacia.
- Métodos de fijación de parámetrosDescripción detallada de los métodos para un ajuste fino eficaz mediante la incorporación a la estructura del modelo de módulos de entrenamiento nuevos y más pequeños, incluida la aplicación y las ventajas de las entradas complementarias (por ejemplo, Prompt-tuning), los modelos complementarios (por ejemplo, Prefix-tuning y Adapter-tuning) y las salidas complementarias (por ejemplo, Proxy-tuning).
- Método de selección de parámetrosIntroducción de métodos para ajustar con precisión sólo una parte de los parámetros del modelo, divididos en métodos basados en reglas (por ejemplo, BitFit) y métodos basados en el aprendizaje (por ejemplo, Child-tuning), explorando cómo reducir la carga computacional y mejorar el rendimiento del modelo mediante la actualización selectiva de los parámetros.
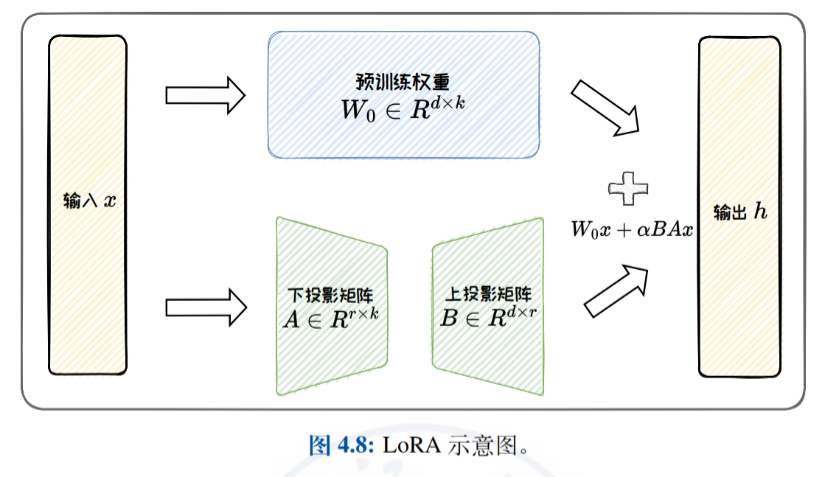
- Métodos de adaptación de bajo rangoUna introducción detallada al ajuste fino eficiente mediante la aproximación de la matriz de actualización de pesos original por una matriz de bajo rango, con un enfoque en LoRA y sus variantes (por ejemplo, ReLoRA, AdaLoRA y DoRA), y una discusión de la eficiencia paramétrica de LoRA y las capacidades de generalización de tareas.
- Práctica y aplicaciónPresenta el uso del marco HF-PEFT y las técnicas relacionadas, demuestra casos de uso de las técnicas PEFT en la consulta de datos tabulares y el análisis de datos tabulares, y demuestra la eficacia de PEFT en la mejora del rendimiento de grandes tareas específicas de modelos.
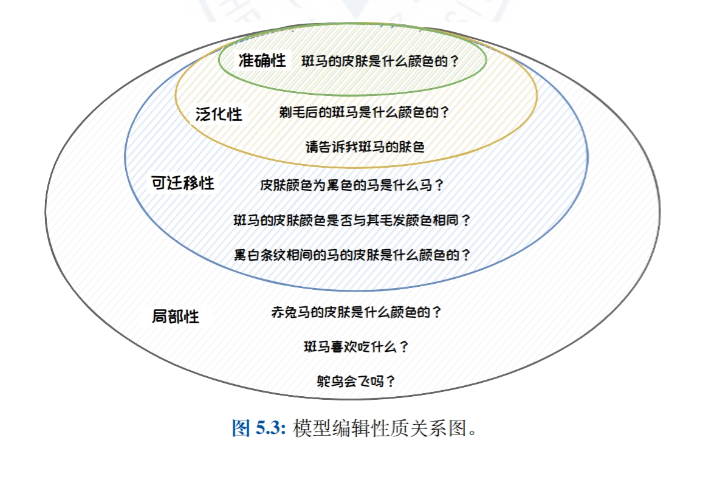
Edición de modelos
- Introducción a la edición de modelosIntroducción a la idea, definición y naturaleza de la edición de modelos, detallando su importancia para corregir errores de sesgo, toxicidad y conocimiento en grandes modelos lingüísticos.
- Enfoque clásico de la edición de modelos: Clasificar los métodos de edición de modelos en métodos de ampliación externa (por ejemplo, métodos de almacenamiento en caché de conocimientos y de parámetros adicionales) y métodos de modificación interna (por ejemplo, métodos de metaaprendizaje y de edición posicional), presentando trabajos representativos de cada tipo de método.
- Método de parámetro adicional: T-PatcherEn este artículo se describe en detalle el método T-Patcher, que consigue un control preciso de la salida del modelo mediante la adición de parámetros específicos al modelo, y es adecuado para escenarios que requieren una corrección rápida y precisa de puntos de conocimiento específicos en el modelo.
- Método de edición de la localización: ROMAIntroducción detallada al método ROME, que consigue un control preciso de los resultados del modelo localizando y modificando capas o neuronas específicas dentro del modelo, y es adecuado para escenarios que requieren una modificación profunda de la estructura de conocimiento interna del modelo.
- Aplicaciones de edición de modelosPresentación de las aplicaciones prácticas de la edición de modelos en la actualización precisa de modelos, la protección del derecho al olvido y la mejora de la seguridad de los modelos, y demostración del potencial de aplicación de la tecnología de edición de modelos en diferentes escenarios.
Búsqueda Generación mejorada
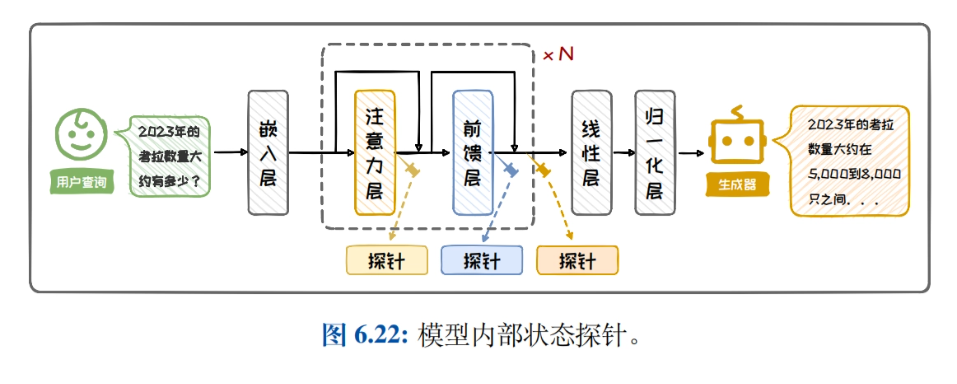
- Perfil de generación de mejora de la recuperaciónPresenta los antecedentes y la composición de la generación mejorada por recuperación, detallando la importancia y los escenarios de aplicación de la mejora del rendimiento del modelo mediante la combinación de recuperación y generación en tareas de procesamiento del lenguaje natural.
- Recuperación de la arquitectura de generación mejorada: Presenta la clasificación de arquitecturas RAG, la arquitectura de mejora de caja negra y la arquitectura de mejora de caja blanca, compara y analiza las características y los escenarios aplicables de las distintas arquitecturas, y ayuda a los lectores a elegir la arquitectura adecuada.
- recuperación de conocimientosIntroducción detallada a la construcción de bases de conocimientos, la mejora de las consultas, los buscadores y la mejora de la eficacia de la recuperación, explorando cómo mejorar la eficacia de la recuperación y optimizar el proceso de recuperación de conocimientos mediante la reordenación de los resultados de la recuperación.
- Mejora de la generación: Presenta cuándo realzar, dónde realzar, múltiples realces y métodos de reducción de costes, analiza estrategias para aplicar el realce generativo a distintas tareas y mejora la calidad y la eficacia del texto generado.
- Práctica y aplicación: Presenta los pasos para construir un sistema RAG sencillo, muestra ejemplos de RAG en aplicaciones típicas y ayuda a los lectores a comprender y aplicar técnicas de generación mejorada de recuperación para mejorar el rendimiento de sus modelos en tareas del mundo real.
Dirección de descarga de material
El informe Fundamentals of Large Modelling puede descargarse en: https://url23.ctfile.com/f/65258023-8434020435-605e6e?p=8894 (Código de acceso: 8894)
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...