Lanzamiento de Doubao-1.5-pro: un nuevo modelo de base multimodal para el equilibrio definitivo

Doubao-1.5-pro
🌟 Perfil del modelo
Doubao-1.5-pro es un sistema muy disperso Arquitectura del MEEn los cuatro cuadrantes de Prefill/Decode y Attention/FFN, las características de cálculo y acceso son significativamente diferentes. Para los cuatro cuadrantes diferentes, adoptamos hardware heterogéneo combinado con diferentes estrategias de optimización de baja precisión para aumentar significativamente el rendimiento al tiempo que se garantiza una baja latencia, y reducir el coste total teniendo en cuenta los objetivos de optimización de TTFT y TPOT, logrando el equilibrio definitivo entre rendimiento y eficiencia de inferencia.
- parámetro de activación menor: supera el rendimiento del modelo denso muy grande.
- Adaptación multiescena: Supera los resultados de múltiples evaluaciones comparativas.
📊 Evaluación del rendimiento
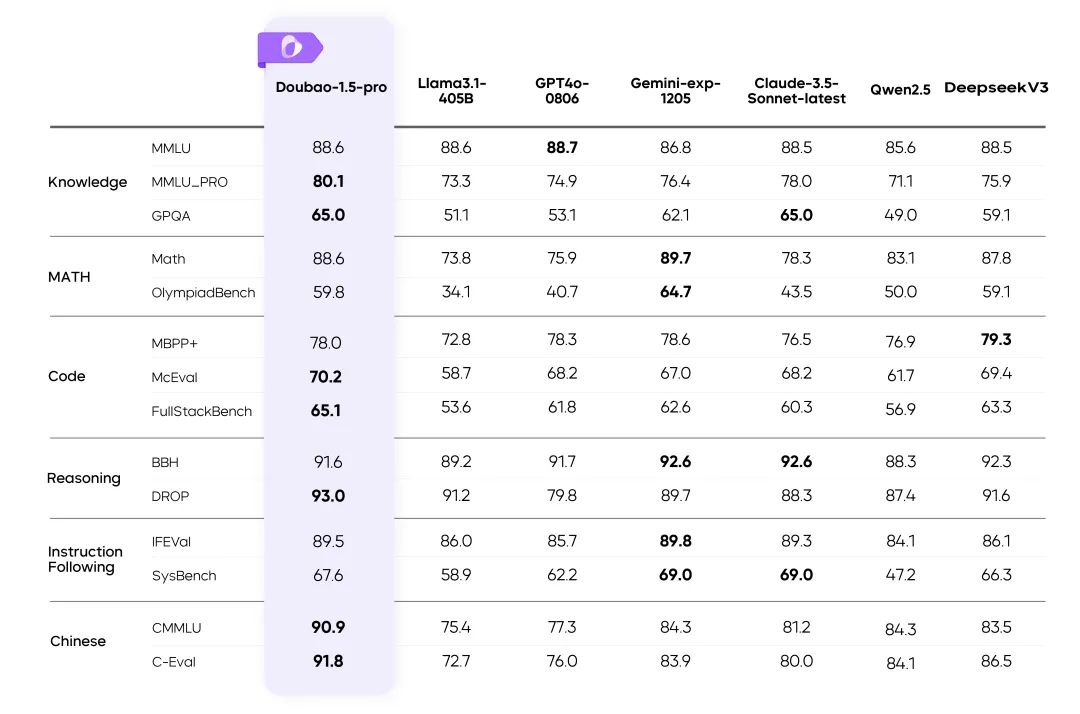
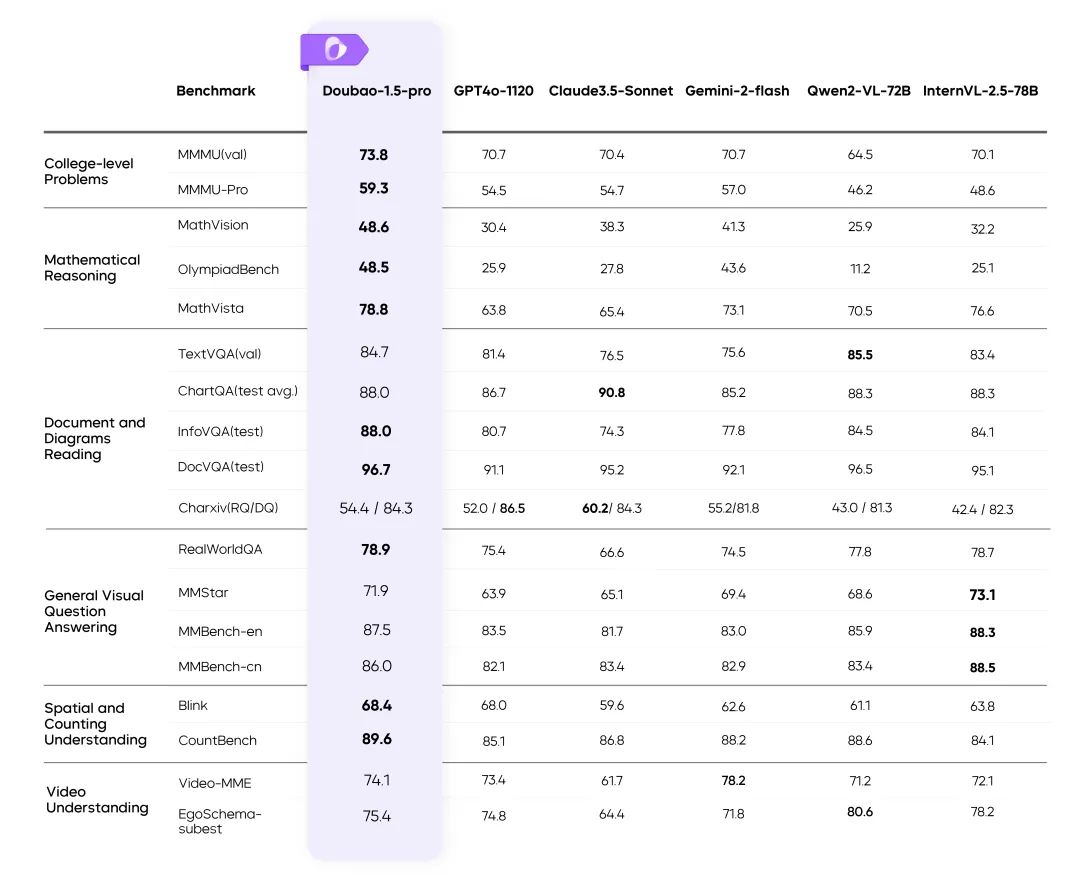
Resultados de Doubao-1.5-pro en múltiples pruebas de referencia
instrucciones::
- Las métricas del resto de modelos de la tabla se han extraído de los resultados oficiales, y las partes no publicadas han sido realizadas por plataformas de evaluación internas.
- GPT4o-0806 Excelente rendimiento en revisiones públicas de modelos lingüísticos, véase: simple-evals.
⚙️ Equilibrio entre rendimiento y razonamiento
Arquitectura eficiente de ME
- utilizar Arquitectura de ME dispersa Lograr la doble optimización de la formación y la eficacia del razonamiento.
- Lo más destacado de la investigación: Determinar la relación óptima de equilibrio entre rendimiento y eficiencia mediante la ley de escalado de la dispersión.
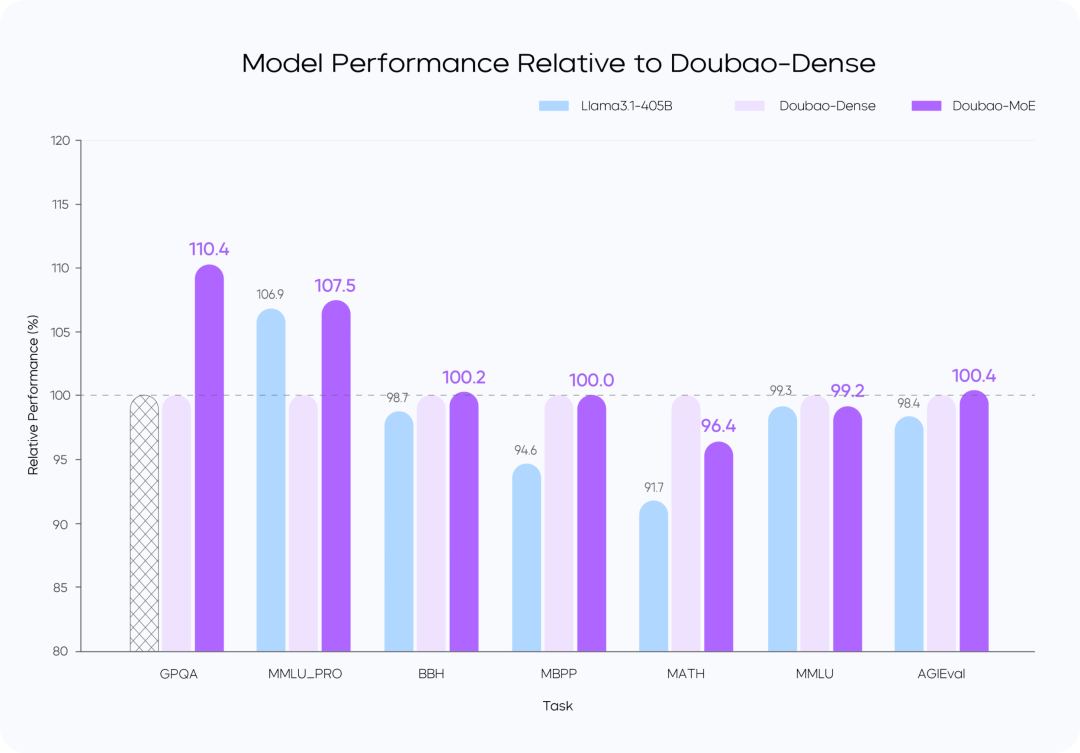
Entrenamiento Pérdida vs.

Comparación del rendimiento de los modelos
instrucciones::
- El modelo Doubao-MoE supera a un modelo denso con siete veces más parámetros activados (Doubao-Dense).
- Doubao El entrenamiento de modelos densos es más eficiente que Llama 3.1-405BLa calidad de los datos y la optimización de las hiperreferencias son fundamentales.
🚀 Razonamiento de alto rendimiento
Optimización computacional y de las características de acceso
Doubao-1.5-pro obtiene buenos resultados en cuatro cuadrantes computacionales: Prellenado, Descodificación, Atención y FFN.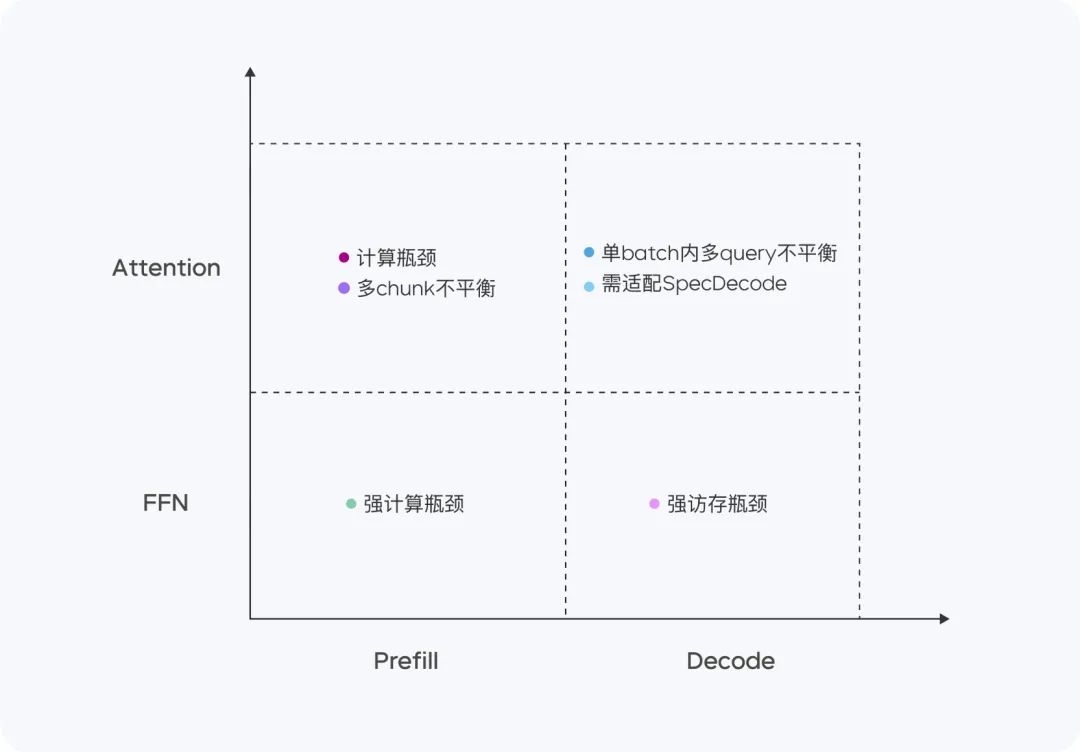
En la fase de Prefill, el cuello de botella de comunicación y acceso no es obvio, pero el cuello de botella de computación se alcanza fácilmente. Teniendo en cuenta las características de la atención unidireccional LLM, realizamos Chunk-PP Prefill Serving en múltiples dispositivos con altos ratios de acceso computacional, de modo que la tasa de utilización de Tensor Core en el sistema en línea se acerca a 60%.
- Prefill Attention: Amplía la implementación de código abierto FlashAttention de 8 bits con instrucciones como MMA/WGMMA, combinadas con Per N fichas La estrategia de cuantificación por secuencia garantiza que esta fase pueda ejecutarse sin pérdidas en GPUs de diferentes arquitecturas. Además, al modelar el consumo de atención de los slices de distintas longitudes y combinarlo con la estrategia dinámica de procesamiento por lotes de consultas cruzadas, se consigue un equilibrio entre tarjetas durante el servicio de Chunk-PP, lo que elimina eficazmente la ejecución en vacío causada por el desequilibrio de carga;
- Prefill FFN: La cuantificación W4A8 reduce eficazmente la sobrecarga de acceso de los expertos MoE dispersos y proporciona más entradas a la etapa FFN a través de la estrategia Batching de consultas cruzadas, lo que mejora el MFU a 0,8.
En la fase de descodificación, el cuello de botella computacional no es obvio, pero los requisitos de comunicación y memoria son relativamente altos. Utilizamos Serving, un dispositivo con menor capacidad de cálculo y memoria, para obtener un mayor ROI y, al mismo tiempo, empleamos un muestreo de muy bajo coste y una estrategia de Descodificación Especulativa para reducir la métrica TPOT.
- Decodificar Atención: TP se despliega para optimizar el escenario común de grandes diferencias en las longitudes de KV de diferentes consultas dentro de un mismo lote mediante búsqueda heurística y estrategia agresiva de división de frases largas; en términos de precisión, se sigue adoptando la cuantificación Por N tokens Por Secuencia; además, el cálculo de Atención durante el muestreo aleatorio se optimiza para garantizar que sólo se accede una vez a la Caché de KV. Además, optimizamos el cálculo de la Atención durante el proceso de muestreo aleatorio para garantizar que sólo se accede una vez a la Caché KV.
- Decodificar FFN: Mantener W4A8 cuantificado y desplegado usando EP.
En general, hemos aplicado las siguientes optimizaciones al sistema de servidores separados por DP:
- Backend RPC personalizado para transferencia de Tensores, y eficiencia de transferencia de Tensores optimizada sobre red TCP/RDMA mediante zero-copy, paralelismo multi-stream, etc., que a su vez mejora la eficiencia de transferencia de KV Cache bajo separación PD.
- Admite la asignación flexible y la expansión y contracción dinámicas de los clústeres de Prefill y Decode, y realiza la expansión elástica HPA para cada función de forma independiente para garantizar que tanto Prefill como Decode no tienen aritmética redundante, y la asignación aritmética de los dos lados está en línea con el patrón de tráfico en línea real.
- En el marco de la computación de la GPU y la CPU pre y post-procesamiento asíncrono, de modo que la GPU razonamiento paso N cuando la CPU temprano lanzamiento de la N + 1 paso Kernel, para mantener la GPU está siempre lleno, todo el marco de la acción de procesamiento de la GPU razonamiento cero sobrecarga. Además, con nuestra solución de clúster de servidor de desarrollo propio y soporte flexible para chips de bajo costo, el costo de hardware es significativamente menor que la solución de la industria. También hemos optimizado considerablemente la eficiencia de la comunicación de paquetes mediante NIC personalizadas y protocolos de red de desarrollo propio. A nivel aritmético, conseguimos un solapamiento eficiente (Overlap) entre computación y comunicación, garantizando así la estabilidad y eficiencia del razonamiento distribuido multiordenador.
🎯 Etiquetado de datos: sin atajos
- Construir un sistema eficaz de producción de datos que combine Equipo de etiquetado responder cantando Modelización de las técnicas de autoelevaciónLa calidad de los datos ha mejorado considerablemente.
🖼️ Capacidades multimodales
Multimodalidad visual: escenas complejas más fáciles
Entrenamiento en resolución dinámica: mejora del rendimiento 60%
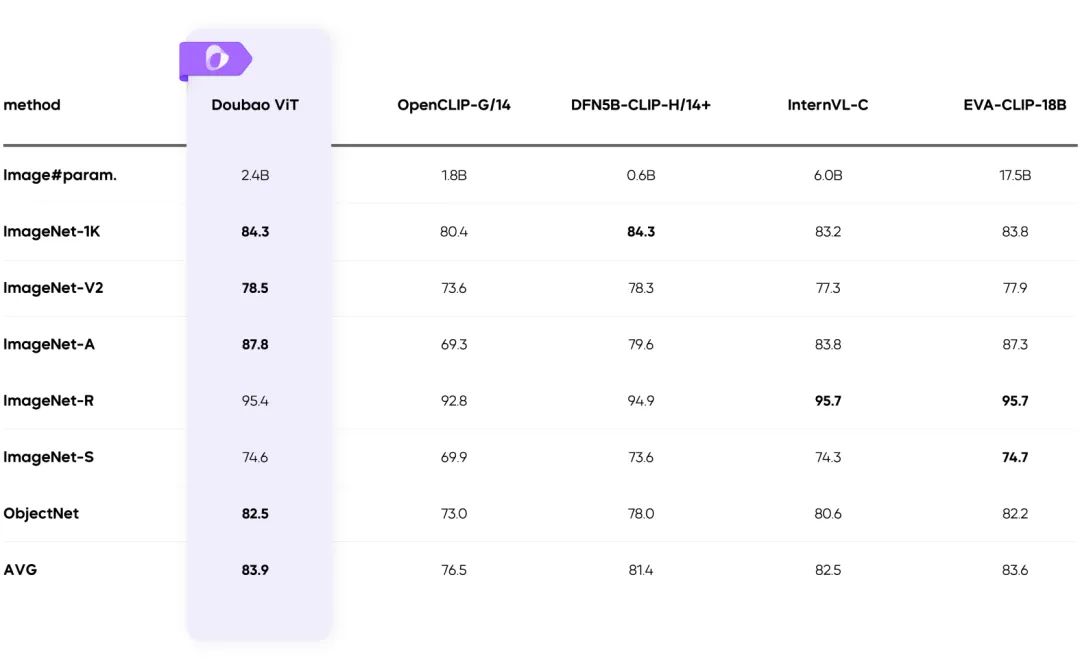
- Resuelve el problema de la carga desigual del codificador visual y mejora significativamente la eficiencia.
✅ Resumen
Doubao-1.5-pro encuentra el equilibrio óptimo entre alto rendimiento y bajo coste de inferencia, y logra avances en escenarios multimodales:
- Diseño innovador de arquitectura dispersa.
- Datos de formación y sistemas de optimización de alta calidad.
- Impulsar una nueva referencia en tecnología multimodal.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...