
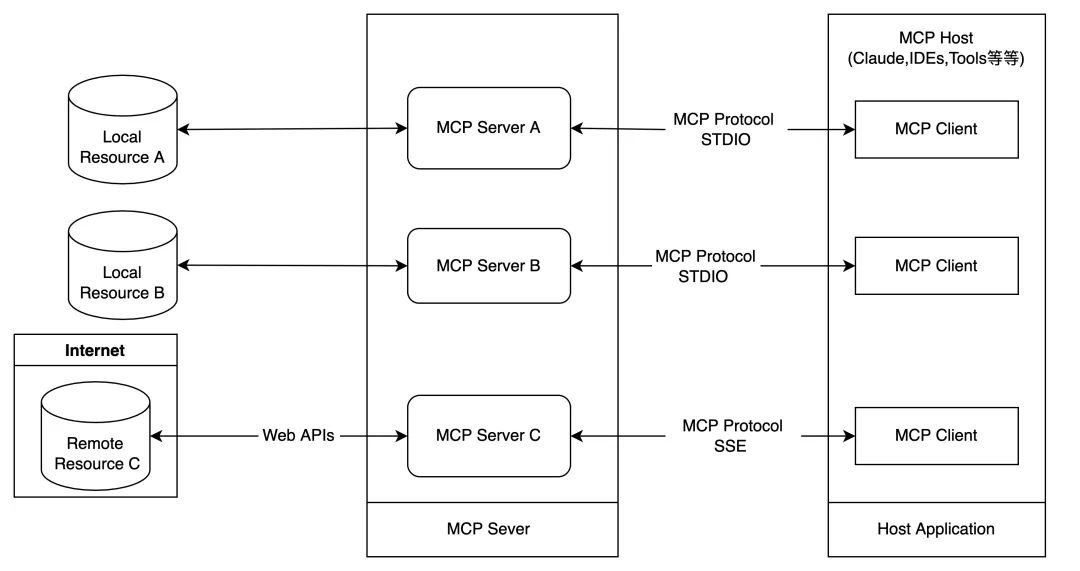
Dify v0.6.9 utiliza flujos de trabajo personalizados como herramientas
Tutoriales prácticos sobre IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 61.7K 00

Esto puede hacerse en el Dify Los flujos de trabajo de IA se lanzaron en la v0.6.9 como herramientas reutilizables (para su uso en Agentes o Flujos de Trabajo). Esto permite su integración con nuevos agentes y otros flujos de trabajo, eliminando así la duplicación de esfuerzos. Se han añadido dos nuevos nodos de flujo de trabajo y un nodo mejorado:
Iteración:Asegúrese de que la entrada es un array. El nodo de iteración procesará cada elemento del array sucesivamente hasta que todos los elementos hayan sido procesados. Por ejemplo, si necesita un artículo largo, simplemente introduzca algunos títulos. Esto generará un artículo que contiene un párrafo para cada título, eliminando la necesidad de una compleja programación de avisos.
Extractor de parámetros:La extracción de parámetros estructurados a partir del lenguaje natural mediante Large Language Models (LLM) simplifica el proceso de uso de herramientas en flujos de trabajo y la realización de peticiones HTTP.
Agregador de variables:El asignador de variables mejorado permite una selección de variables más flexible. Al mismo tiempo, la experiencia del usuario mejora gracias a la mejora de las conexiones de los nodos.
Los flujos de trabajo en Dify se dividen en Chatflow y Flujo de trabajo De dos tipos:ChatflowAplicaciones conversacionales para escenarios basados en el diálogo, incluido el servicio de atención al cliente, la búsqueda semántica y la lógica multipaso en la construcción de respuestas.Flujo de trabajoOrientada a la automatización y a los escenarios por lotes, es adecuada para aplicaciones como la traducción de alta calidad, el análisis de datos, la generación de contenidos, la automatización del correo electrónico, etc.

Portal Chatflow

Portal de flujo de trabajo
I. Flujo de trabajo de traducción en tres pasos
1. Nodo de inicio

La definición de variables de entrada dentro del nodo Inicio admite cuatro tipos: texto, párrafo, opciones desplegables y números. Esto se muestra a continuación:

En Chatflow, el nodo de inicio proporcionará variables integradas en el sistema: sys.query y sys.files. sys.query se utiliza para la introducción de preguntas del usuario en aplicaciones basadas en diálogos, y sys.files se utiliza para cargar un archivo en un diálogo, por ejemplo, cargar una imagen para comprender el significado, que debe utilizarse con el modelo de comprensión de imágenes o herramientas para la introducción de imágenes.
2. Nodo LLM (Reconocimiento de nombres propios)

El SISTEMA proporciona orientaciones de alto nivel para el diálogo, como se indica a continuación:
<任务> 识别用户输入的技术术语。请用{XXX} -> {XXX}的格式展示翻译前后的技术术语对应关系。
<输入文本>
{{#1711067409646.input_text#}}
<示例>
Transformer -> Transformer
Token -> Token
零样本 -> Zero Shot
少样本 -> Few Shot
<专有名词>
En el nodo LLM se pueden personalizar los mensajes de entrada del modelo. Si selecciona el modelo Chat, puede personalizar los mensajes SYSTEM/USER/ASSISTANT. Esto se muestra a continuación:

| número de serie | cuenta | nota | |
|---|---|---|---|
| 1 | SISTEMA (palabra clave) | Orientaciones de alto nivel para el diálogo | pista |
| 2 | USUARIO | Proporcionar comandos, consultas o cualquier entrada de texto al modelo | Problemas de los usuarios |
| 3 | ASISTENTE | Respuestas modelo basadas en los mensajes de los usuarios | Respuestas de los ayudantes |
3. Nodo LLM2 (traducción directa)

El SISTEMA proporciona orientaciones de alto nivel para el diálogo, como se indica a continuación:
<任务> 您是一名精通英文的专业译者,特别是在将专业的学术论文转换为通俗易懂的科普文章方面有着非凡的能力。请协助我把下面的中文段落翻译成英文,使其风格与英文的科普文章相似。
<限制>
请根据中文内容直接翻译,维持原有的格式,不省略任何信息。
<翻译前>
{{#1711067409646.input_text#}}
<直接翻译>
4. LLM3 (señala los problemas de la traducción directa)

El SISTEMA proporciona orientaciones de alto nivel para el diálogo, como se indica a continuación:
<任务>
根据直接翻译的结果,指出其具体存在的问题。需要提供精确描述,避免含糊其辞,并且无需增添原文中未包含的内容或格式。具体包括但不限于:
不符合英文的表达习惯,请明确指出哪里不合适句子结构笨拙,请指出具体位置,无需提供修改建议,我们将在后续的自由翻译中进行调整表达含糊不清,难以理解,如果可能,可以试图进行解释
<直接翻译>
{{#1711067578643.text#}}
<原文>
{{#1711067409646.input_text#}}
<直接翻译的问题>
5. LLM4 (traducción italiana - segunda traducción)

El SISTEMA proporciona orientaciones de alto nivel para el diálogo, como se indica a continuación:
<任务>基于初次直接翻译的成果及随后识别的各项问题,我们将进行一次重新翻译,旨在更准确地传达原文的意义。在这一过程中,我们将致力于确保内容既忠于原意,又更加贴近英文的表达方式,更容易被理解。在此过程中,我们将保持原有格式不变。
<直接翻译>
{{#1711067578643.text#}}
<第一次翻译的问题>
{{#1711067817657.text#}}
<意译>
6. Nodo final

Definición de los nombres de las variables de salidasecond_translation.
7. Publicar el flujo de trabajo como herramienta
Publique el flujo de trabajo como una herramienta para poder utilizarlo en el Agente, como se muestra a continuación:

Haga clic para acceder a la página Herramientas, como se muestra a continuación:

8.Plantilla Jinja
Mientras escribía Prompt, encontré soporte para plantillas Jinja. Ver [3][4] para más detalles.
II. Uso del flujo de trabajo en Workflow

III. Uso del flujo de trabajo en los agentes
Esencialmente, tratar Workflow como una herramienta y así ampliar las capacidades del Agente es similar a otras herramientas, como la búsqueda en Internet, la computación científica, etc.


IV. Pruebas individuales del flujo de trabajo de traducción en tres fases

La entrada se muestra a continuación:
Transformer是大语言模型的基础。
El resultado se muestra a continuación:
The Transformer serves as the cornerstone for large-scale language models.
A continuación se muestra la página de detalles:

A continuación se muestra la página de seguimiento:

1. Inicio
(1) Entrada
{
"input_text": "Transformer是大语言模型的基础。",
"sys.files": [],
"sys.user_id": "7d8864c3-c456-4588-9b0a-9368c94ca377"
}
(2) Salida
{
"input_text": "Transformer是大语言模型的基础。",
"sys.files": [],
"sys.user_id": "7d8864c3-c456-4588-9b0a-9368c94ca377"
}
2. LLM
(1) Tratamiento de datos
{
"model_mode": "chat",
"prompts": [
{
"role": "system",
"text": "<任务> 识别用户输入的技术术语。请用{XXX} -> {XXX}的格式展示翻译前后的技术术语对应关系。\n<输入文本>\nTransformer是大语言模型的基础。\n<示例>\nTransformer -> Transformer\nToken -> Token\n零样本 -> Zero Shot \n少样本 -> Few Shot\n<专有名词>",
"files": []
}
]
}
(2) Salida
{
"text": "Transformer -> Transformer",
"usage": {
"prompt_tokens": 107,
"prompt_unit_price": "0.01",
"prompt_price_unit": "0.001",
"prompt_price": "0.0010700",
"completion_tokens": 3,
"completion_unit_price": "0.03",
"completion_price_unit": "0.001",
"completion_price": "0.0000900",
"total_tokens": 110,
"total_price": "0.0011600",
"currency": "USD",
"latency": 1.0182260260044131
}
}
3. LLM 2
(1) Tratamiento de datos
{
"model_mode": "chat",
"prompts": [
{
"role": "system",
"text": "<任务> 您是一名精通英文的专业译者,特别是在将专业的学术论文转换为通俗易懂的科普文章方面有着非凡的能力。请协助我把下面的中文段落翻译成英文,使其风格与英文的科普文章相似。\n<限制> \n请根据中文内容直接翻译,维持原有的格式,不省略任何信息。\n<翻译前> \nTransformer是大语言模型的基础。\n<直接翻译> ",
"files": []
}
]
}
(2) Salida
{
"text": "The Transformer is the foundation of large language models.",
"usage": {
"prompt_tokens": 176,
"prompt_unit_price": "0.001",
"prompt_price_unit": "0.001",
"prompt_price": "0.0001760",
"completion_tokens": 10,
"completion_unit_price": "0.002",
"completion_price_unit": "0.001",
"completion_price": "0.0000200",
"total_tokens": 186,
"total_price": "0.0001960",
"currency": "USD",
"latency": 0.516718350991141
}
}
4. LLM 3
(1) Tratamiento de datos
{
"model_mode": "chat",
"prompts": [
{
"role": "system",
"text": "<任务>\n根据直接翻译的结果,指出其具体存在的问题。需要提供精确描述,避免含糊其辞,并且无需增添原文中未包含的内容或格式。具体包括但不限于:\n不符合英文的表达习惯,请明确指出哪里不合适句子结构笨拙,请指出具体位置,无需提供修改建议,我们将在后续的自由翻译中进行调整表达含糊不清,难以理解,如果可能,可以试图进行解释\n<直接翻译>\nThe Transformer is the foundation of large language models.\n<原文>\nTransformer是大语言模型的基础。\n<直接翻译的问题>",
"files": []
}
]
}
(2) Salida
{
"text": "句子结构笨拙,不符合英文表达习惯。",
"usage": {
"prompt_tokens": 217,
"prompt_unit_price": "0.001",
"prompt_price_unit": "0.001",
"prompt_price": "0.0002170",
"completion_tokens": 22,
"completion_unit_price": "0.002",
"completion_price_unit": "0.001",
"completion_price": "0.0000440",
"total_tokens": 239,
"total_price": "0.0002610",
"currency": "USD",
"latency": 0.8566757979860995
}
}
5. LLM 4
(1) Tratamiento de datos
{
"model_mode": "chat",
"prompts": [
{
"role": "system",
"text": "<任务>基于初次直接翻译的成果及随后识别的各项问题,我们将进行一次重新翻译,旨在更准确地传达原文的意义。在这一过程中,我们将致力于确保内容既忠于原意,又更加贴近英文的表达方式,更容易被理解。在此过程中,我们将保持原有格式不变。\n<直接翻译> \nThe Transformer is the foundation of large language models.\n<第一次翻译的问题>\n句子结构笨拙,不符合英文表达习惯。\n<意译> ",
"files": []
}
]
}
(2) Salida
{
"text": "The Transformer serves as the cornerstone for large-scale language models.",
"usage": {
"prompt_tokens": 187,
"prompt_unit_price": "0.01",
"prompt_price_unit": "0.001",
"prompt_price": "0.0018700",
"completion_tokens": 12,
"completion_unit_price": "0.03",
"completion_price_unit": "0.001",
"completion_price": "0.0003600",
"total_tokens": 199,
"total_price": "0.0022300",
"currency": "USD",
"latency": 1.3619857440062333
}
}
6. Conclusión
(1) Entrada
{
"second_translation": "The Transformer serves as the cornerstone for large-scale language models."
}
(2) Salida
{
"second_translation": "The Transformer serves as the cornerstone for large-scale language models."
}
V. Prueba del flujo de trabajo de traducción en tres pasos en el Agente
Al iniciar la herramienta:

Al cerrar la herramienta:

VI. Cuestiones conexas
1. ¿Cuándo se activa el Workflow en el Agente?
Al igual que con las herramientas, se activa mediante la descripción de la herramienta. La implementación exacta sólo está clara mirando el código fuente.
bibliografía
[1] Flujo de trabajo: https://docs.dify.ai/v/zh-hans/guides/workflow[2] Enseñanza práctica de Dify al ecosistema WeChat: https://docs.dify.ai/v/zh-hans/learn-more/use-cases/dify-on-wechat[3] Documentación oficial de Jinja: https://jinja.palletsprojects.com/en/3.0.x/[4] Plantilla Jinja: https://jinja.palletsprojects.com/en/3.1.x/templates/© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...