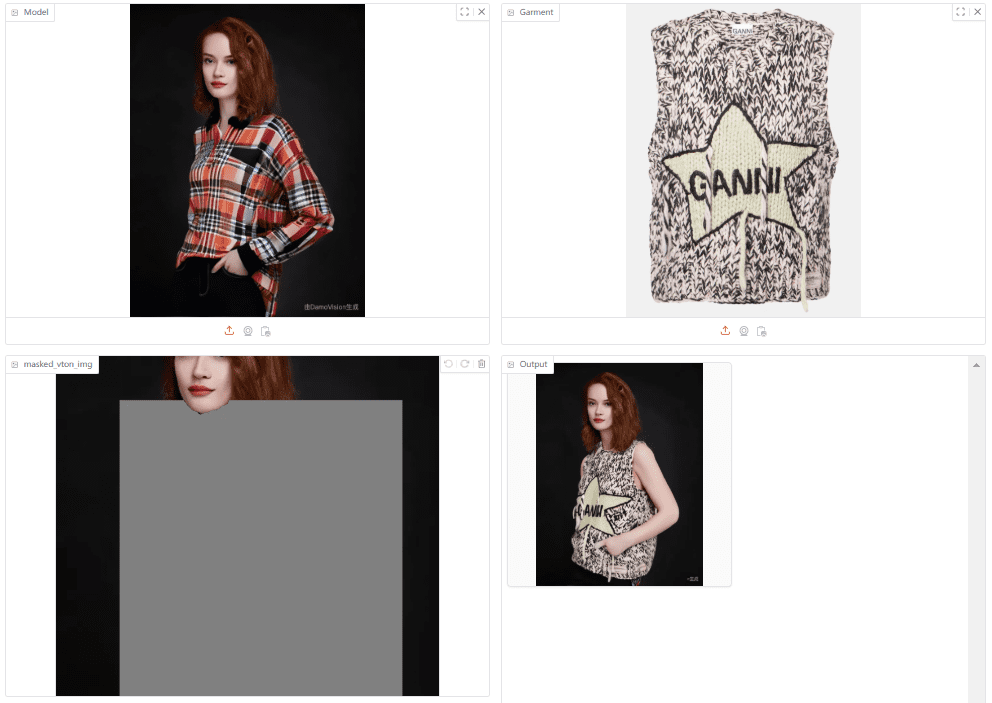
DiffSynth-Engine: motor de código abierto para la implantación de FLUX en entornos de baja densidad, Wan 2.1
Últimos recursos sobre IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 66.5K 00

Introducción general
DiffSynth-Engine es un proyecto de código abierto de ModelScope, alojado en GitHub, que se basa en la tecnología de modelado de difusión y se centra en la generación eficiente de imágenes y vídeos para que los desarrolladores desplieguen modelos de IA en entornos de producción. El proyecto evolucionó a partir de DiffSynth-Studio , después de una transformación integral de ingeniería , eficiencia computacional optimizada y facilidad de despliegue . Es compatible con múltiples modelos (por ejemplo, FLUX, Wan2.1) y proporciona una estructura de código clara y una gestión de memoria flexible. Desde marzo de 2025, el proyecto se actualiza continuamente y ha recibido una gran atención por parte de la comunidad de código abierto, con el objetivo de promover la practicidad de la creación de IA.

Lista de funciones
- Admite la generación eficaz de imágenes y vídeos, cubriendo una amplia gama de necesidades, desde imágenes estáticas a contenidos dinámicos.
- Proporcionar un código claro y legible sin depender de bibliotecas de terceros, facilitando a los desarrolladores su modificación y ampliación.
- Compatible con diversos modelos de base (por ejemplo, FLUX, Wan2.1) y modelos LoRA para adaptarse a distintos escenarios.
- Incorpora una gestión flexible de la memoria, admite FP8, INT8 y otros modos de cuantificación, y puede ejecutarse en dispositivos con poca memoria gráfica.
- Optimice la velocidad de inferencia y soporte la computación paralela tensorial para acelerar las tareas generativas a gran escala.
- Ofrece soporte multiplataforma y es compatible con Windows, macOS (incluido Apple Silicon) y Linux.
- Admite la conversión de texto en imagen, texto en vídeo y estilo de vídeo, entre otras muchas funciones.
Utilizar la ayuda
Proceso de instalación
La instalación de DiffSynth-Engine es sencilla y puede realizarse en unos pocos pasos.
- Instalación de paquetes básicos
Instale a través de pip3 introduciendo el siguiente comando en el terminal:
pip3 install diffsynth-engine
Asegúrese de que la versión de Python es 3.8 o superior. Se recomienda utilizar un entorno virtual para evitar conflictos de dependencias.
- Descargar modelos
El proyecto no incluye archivos de modelo, que deben descargarse manualmente o mediante código. Por ejemplo, para obtener los archivos FLUX Modelos:
from diffsynth_engine import fetch_model
model_path = fetch_model("muse/flux-with-vae", revision="20240902173035", path="flux1-dev-with-vae.safetensors")
Una vez descargados, los archivos del modelo suelen colocarse localmente en un directorio específico para que las secuencias de comandos puedan llamarlos.
- Verificar la instalación
Una vez finalizada la instalación, ejecute un sencillo script de prueba para confirmar que el entorno funciona:from diffsynth_engine import __version__ print(__version__)La salida del número de versión significa que la instalación se ha realizado correctamente.
Funciones principales
1. Generación de imágenes (FLUX como ejemplo)
- procedimiento
Utilice el siguiente código para generar una imagen:from diffsynth_engine.pipelines import FluxImagePipeline, FluxModelConfig from diffsynth_engine import fetch_model model_path = fetch_model("muse/flux-with-vae", revision="20240902173035", path="flux1-dev-with-vae.safetensors") config = FluxModelConfig(dit_path=model_path) pipe = FluxImagePipeline.from_pretrained(config, offload_mode="cpu_offload").eval() image = pipe( prompt="月球上的宇航员骑马,黑白摄影风格,颗粒感强,对比度高", width=1024, height=1024, num_inference_steps=30, seed=42, ) image.save("flux_txt2img.png") - Descripción destacada
Por defecto, se necesitan 23 GB de memoria de vídeo. Si no tienes suficiente memoria, puedes ajustar eloffload_mode="sequential_cpu_offload"El proceso de cuantificación puede ejecutarse con tan solo 4 GB de RAM, pero el tiempo de generación se alarga (por ejemplo, 91 segundos). Admite múltiples precisiones de cuantificación (por ejemplo, q8_0, q6_k) y los requisitos de memoria pueden reducirse a 7-12 GB.
2. Generación de vídeo (Wan 2.1 como ejemplo)
- procedimiento
Utilice el siguiente código para generar un vídeo:from diffsynth_engine.pipelines import WanVideoPipeline, WanModelConfig from diffsynth_engine.utils.download import fetch_model from diffsynth_engine.utils.video import save_video config = WanModelConfig( model_path=fetch_model("muse/wan2.1-14b-bf16", path="dit.safetensors"), t5_path=fetch_model("muse/wan2.1-umt5", path="umt5.safetensors"), vae_path=fetch_model("muse/wan2.1-vae", path="vae.safetensors"), ) pipe = WanVideoPipeline.from_pretrained(config) video = pipe( prompt="小狗在草地上奔跑,阳光照耀,背景有野花和蓝天", num_frames=41, width=848, height=480, seed=42, ) save_video(video, "wan_t2v.mp4", fps=15) - Descripción destacada
Se tardan 358 segundos en generar 2 segundos de vídeo en una sola tarjeta. Si utilizas 4 GPUs A100 y activas el paralelismo tensorial (parallelism=4, use_cfg_parallel=True),时间缩短至 114 秒,加速比达 3.14 倍。
3. Optimización de la memoria baja
- procedimiento
En el ejemplo FLUX, eloffload_modecambiar asequential_cpu_offload::pipe = FluxImagePipeline.from_pretrained(config, offload_mode="sequential_cpu_offload").eval() - Descripción destacada
Los requisitos de memoria gráfica se han reducido de 23 GB a 3,52 GB para los dispositivos medios. Los modos de cuantificación (como q4_k_s) equilibran aún más la velocidad y la calidad, generando resultados ligeramente reducidos pero útiles.
4. Razonamiento paralelo multitarjeta
- procedimiento
En el ejemplo Wan2.1, añade el parámetro paralelo:pipe = WanVideoPipeline.from_pretrained(config, parallelism=4, use_cfg_parallel=True) - Descripción destacada
Admite cálculo paralelo multi-GPU. 2 GPU aceleran 1,97x, 4 GPU aceleran 3,14x para implantaciones de nivel industrial.
advertencia
- requisitos de hardware: Se recomiendan 8 GB de memoria de vídeo para la generación de imágenes, 24 GB para la generación de vídeo o configuraciones multitarjeta.
- trayectoria del modeloPara garantizar que
fetch_modelLa ruta descargada es correcta, de lo contrario deberá especificarla manualmente. - referencia documentalConsulte la página oficial de GitHub para obtener más información.
<https://github.com/modelscope/DiffSynth-Engine>.
escenario de aplicación
- creación personal
Los usuarios pueden generar imágenes artísticas con FLUX o crear vídeos cortos con Wan2.1, adecuados para compartir en las redes sociales. - Implantación industrial
Las empresas pueden utilizar el razonamiento paralelo multitarjeta para generar rápidamente contenidos de vídeo de alta calidad para publicidad o producción de películas. - Estudios técnicos
Los desarrolladores pueden modificar el código, probar diferentes modelos y estrategias cuantitativas e impulsar la optimización de la tecnología de IA. - Educación y formación
Los estudiantes pueden aprender la aplicación práctica de la modelización de la difusión y explorar los principios de la generación de IA mediante una instalación sencilla.
CONTROL DE CALIDAD
- ¿Y si falla la instalación?
Compruebe la versión de Python y la conexión de red. Asegúrese de que pip está actualizado (pip install --upgrade pip), o descargue las dependencias manualmente. - ¿Qué modelos son compatibles?
Admite modelos de base como FLUX, Wan2.1 y modelos de ajuste fino compatibles con LoRA que cubren la generación de imágenes y vídeo. - ¿Funcionará un ordenador de perfil bajo?
Can. Ajustesoffload_modeTras los parámetros de cuantificación, FLUX puede funcionar con 4 GB de RAM. - ¿Cómo se configura el paralelismo multitarjeta?
Añadido durante la inicialización de la tuberíaparallelismasegúrate de que el número de GPUs coincide.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...