DeepSeek Hands-on: Construcción de grafos de conocimiento en tres pasos - Extracción simple, fusión multiparte, generación de temas
Tutoriales prácticos sobre IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 94.3K 00

Pregunta: Los grafos de conocimiento son importantes, el modelo de lenguaje DeepSeek está de moda, ¿puede usarse para construir grafos de conocimiento rápidamente? Quiero probarlo. DeepSeek de la realidad para ver qué tal se le da extraer información, integrar conocimientos y crear gráficos de la nada.
Métodos: Realicé tres experimentos para probar las capacidades de construcción de grafos de conocimiento de DeepSeek:
- Mapeo de construcción de artículo único: Déle a DeepSeek un artículo y vea si puede obtener la información con precisión y construir un gráfico.
- Cartografía de fusión de múltiples artículos: Dé a DeepSeek varios artículos para ver si puede añadir nuevos conocimientos a un gráfico existente.
- Mapa de generación de temas: Sólo tienes que decirle a DeepSeek el tema del atlas, no el artículo, y ver si puede llegar a un atlas por su cuenta.
Resultados: Los experimentos demuestran que DeepSeek construye y fusiona bien los grafos de conocimiento, pero aún hay margen de mejora.
He aquí el proceso exacto y los resultados del experimento, que aclararé en términos más sencillos.
I. Extraer conocimientos de un solo artículo para construir un mapa
Propósito: Prueba de la capacidad de DeepSeek para extraer conocimiento de un artículo y construir un grafo de conocimiento.
Proceso: Encontré un artículo sobre bases de datos de grafos NebulaGraph e hice que DeepSeek leyera el artículo, extrajera la información clave y, a continuación, generara código de base de datos NebulaGraph (nGQL) para crear un grafo de conocimiento.
Instrucciones: "¿Puedes ayudarme a generar un grafo de conocimiento? Yo te doy el artículo, tú extraes la información clave y construyes el gráfico de conocimiento con código nGQL".
Operación: Copie y pegue el contenido del artículo directamente en DeepSeek.
Código nGQL generado por DeepSeek:
# Schema 定义(TAG 类型)
CREATE TAG IF NOT EXISTS product (
name STRING,
description STRING
);
CREATE TAG IF NOT EXISTS company (
name STRING
);
CREATE TAG IF NOT EXISTS feature (
name STRING
);
CREATE TAG IF NOT EXISTS tool (
name STRING
);
CREATE TAG IF NOT EXISTS scenario (
name STRING
);
CREATE TAG IF NOT EXISTS language (
name STRING
);
CREATE TAG IF NOT EXISTS auth_service (
name STRING
);
CREATE TAG IF NOT EXISTS ecosystem (
name STRING
);
# Schema 定义(EDGE 类型)
CREATE EDGE IF NOT EXISTS has_feature ();
CREATE EDGE IF NOT EXISTS used_by ();
CREATE EDGE IF NOT EXISTS provides_tool ();
CREATE EDGE IF NOT EXISTS supports_language ();
CREATE EDGE IF NOT EXISTS applicable_scenario ();
CREATE EDGE IF NOT EXISTS compatible_with ();
CREATE EDGE IF NOT EXISTS supports_auth ();
CREATE EDGE IF NOT EXISTS integrates_with ();
# 数据插入 - 核心产品
INSERT VERTEX product(name, description) VALUES
"NebulaGraph": ("NebulaGraph", "开源的分布式图数据库,支持千亿点万亿边数据集");
# 数据插入 - 产品特性
INSERT VERTEX feature(name) VALUES
"high_performance": ("高性能"),
"open_source": ("开源"),
"scalability": ("易扩展"),
"flexible_modeling": ("灵活数据建模"),
"read_write_balance": ("读写平衡"),
"compatibility": ("查询语言兼容性");
/* ... 此处省略 n多数据 ... */
Resultados: El código DeepSeek está bien, la sintaxis es correcta, y es eficiente, ya que combina múltiples piezas de datos en una sola declaración. El código se pone en NebulaGraph para ejecutar, la trama se ve así:
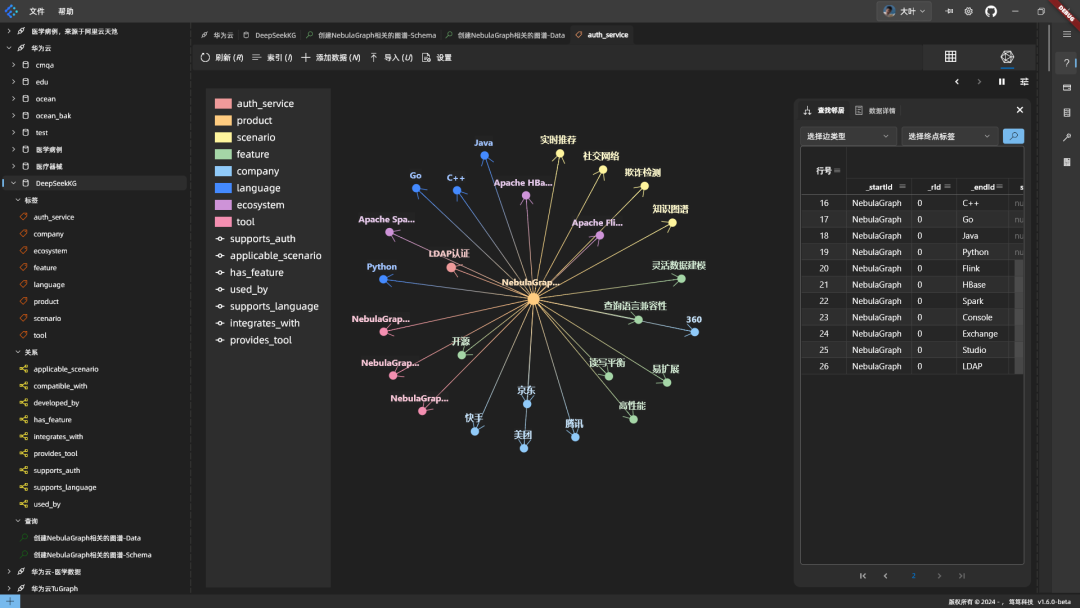
El gráfico se centra en el NebulaGraph y muestra información relevante.
II. Integración de conocimientos en varios artículos
Propósito: Pruebas de la capacidad de DeepSeek para fusionar conocimientos de varios artículos y ampliar un grafo existente.
Proceso: Primero se construye el grafo con un artículo, luego se le dan a DeepSeek más artículos sobre NebulaGraph (de la enciclopedia de Baidu) para fusionar el nuevo conocimiento en el grafo existente.
Instrucciones: "A continuación, otro artículo para usted. Intenta mezclar el mapeo con la estructura actual de la tabla. Para cambiar la estructura de la tabla usa el comando ALTER".
Operación: Los resúmenes de las entradas de NebulaGraph y 360 Encyclopedia se entregaron a DeepSeek, respectivamente.
El código nGQL generado por DeepSeek (léxico NebulaGraph):
# 结构变更 1:为 product 标签增加版本和时间属性
ALTER TAG product ADD (
license STRING,
current_version STRING,
release_date STRING,
last_updated STRING
);
# 结构变更 2:新增开发关系类型
CREATE EDGE IF NOT EXISTS developed_by();
# 数据更新 - 补充产品属性
INSERT VERTEX product(name, description, license, current_version, release_date, last_updated)
VALUES
"NebulaGraph": ("NebulaGraph", "分布式图数据库", "Apache 2.0", "v3.3.0", "2019-05-15", "2022-11-14");
# 新增开发公司(复用 company 标签)
INSERT VERTEX company(name)
VALUES
"Yueshu": ("杭州悦数科技有限公司");
# 新增特性(复用 feature 标签)
INSERT VERTEX feature(name)
VALUES
"acl_mechanism": ("ACL 机制"),
"linear_scaling": ("线性扩容"),
"data_recovery": ("数据恢复"),
"htap": ("HTAP 混合负载"),
"nGQL_language": ("nGQL 查询语言");
# 关系建立(复用已有关系类型)
INSERT EDGE has_feature()
VALUES
"NebulaGraph"->"acl_mechanism":(),
"NebulaGraph"->"linear_scaling":(),
"NebulaGraph"->"data_recovery":(),
"NebulaGraph"->"htap":(),
"NebulaGraph"->"nGQL_language":();
# 新增开发关系
INSERT EDGE developed_by()
VALUES
"NebulaGraph"->"Yueshu":();
Código nGQL generado por DeepSeek (360 palabras):
# 结构变更 1:为 company 标签增加创始人、成立时间和收入属性
ALTER TAG company ADD (founder STRING, founded_date STRING, revenue DOUBLE);
# 结构变更 2:新增事件类型 TAG
CREATE TAG IF NOT EXISTS event (
type STRING,
date STRING,
amount DOUBLE,
details STRING
);
# 数据更新:补充 360 公司信息
INSERT VERTEX company(name, founder, founded_date, revenue)
VALUES
"360": ("奇虎360", "周鸿祎", "2005-09", 116.15);
# 数据插入:产品生态(复用 product 标签)
INSERT VERTEX product(name)
VALUES
"360_Security_Guard": ("360安全卫士"),
"360_Browser": ("360安全浏览器"),
"360_Cloud": ("360安全云");
# 数据插入:重大事件(使用新增 event 标签)
INSERT VERTEX event(type, date, amount, details)
VALUES
"acquisition_360.com": ("域名收购", "2015-02-04", 1700.0, "1.1亿人民币收购 360.com"),
"privatization": ("私有化", "2015-12", 9300.0, "93 亿美元私有化交易");
# 关系建立:复用 developed_by 边连接产品
Resultados: DeepSeek puede modificar la estructura de la tabla basándose en el nuevo artículo (por ejemplo, dando a producto responder cantando empresa tabla más campos) y también ha añadido un nuevo tipo de relación. Para ello, utiliza el método ALTERAR para cambiar la estructura de la tabla. El pequeño problema es que el comentario utiliza el --No se reconoce nGQL, cámbielo manualmente. # En juego.
El código se introduce en la base de datos para su ejecución, y la asignación fusionada funciona:
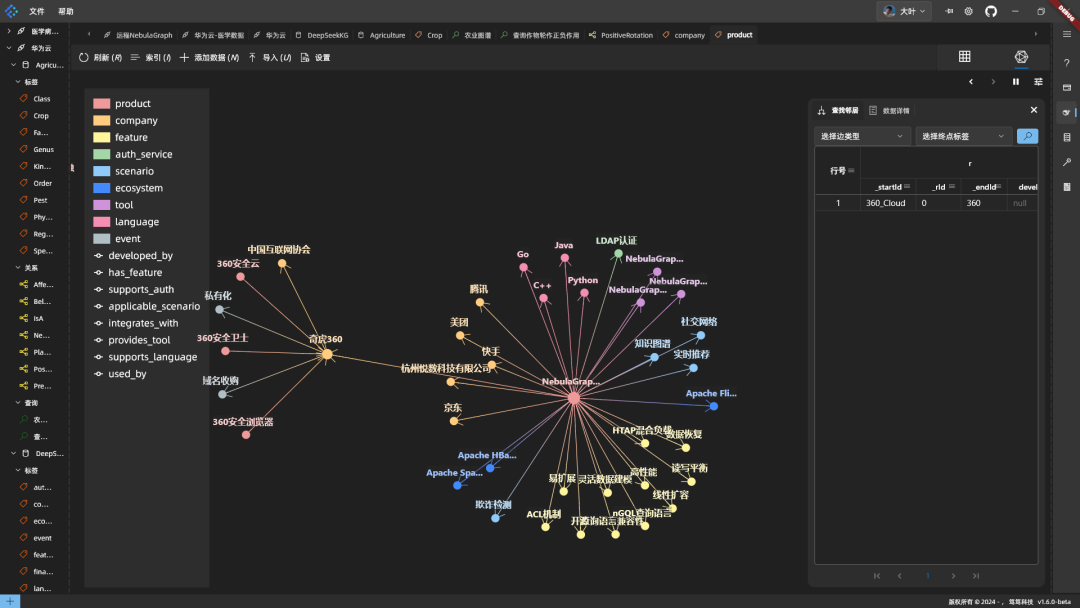
Resumen: DeepSeek es bueno para construir gráficos y fusionar conocimientos. Sin embargo, el servidor a veces es lento y NebulaGraph cambia el esquema de forma asíncrona y tarda un poco en surtir efecto.
III. Generación de temas: cartografía agrícola a partir de la nada
Propósito: Prueba de la capacidad de DeepSeek para generar gráficos de conocimiento basados en temas sin artículos.
Proceso: Cree un nuevo diálogo y deje que DeepSeek genere el código de mapeo directamente sobre el tema "Agricultura". No se da ningún artículo, es un "free-for-all".
Instrucciones: "Quiero construir un grafo de conocimiento agrícola. Utiliza la base de datos NebulaGraph y genera un script nGQL. Los nombres de tabla son joroba grande, los nombres de atributo son joroba pequeña. los nombres de esquema se envuelven con `` para evitar conflictos. Generar al menos 3000 nodos".
Código nGQL generado por DeepSeek (parcial):
# ======================================= #
# 创建图空间
# ======================================= #
CREATE SPACE `Agriculture` (vid_type = FIXED_STRING(32));
USE `Agriculture`;
# ======================================= #
# 定义标签 Schema(大驼峰命名)
# ======================================= #
CREATE TAG IF NOT EXISTS `Crop` (
`cropId` int,
`cropName` string,
`growthPeriod` int,
`suitableTemp` string,
`yieldPerMu` float
);
# ======================================= #
# 此处省略好多脚本
# ======================================= #
Problemas y mejoras:
- Límite de número de nodos: Empecé con 3000 nodos, DeepSeek se negó y dio Python para importar el código CSV. No quería usar Python, así que reduje el número de nodos.
- Vuelve a surgir la cuestión de la anotación: Los comentarios del código son de nuevo --Se volvió a plantear la cuestión.
Instrucciones de mejora: "Usa # para los comentarios, nada de código Python, 3000 nodos son demasiados. Sólo dame el script ngql para 50 nodos".
Diálogo e instrucciones de seguimiento: Para perfeccionar el mapa, seguí hablando con DeepSeek, pidiéndole que añadiera datos, reforzara las asociaciones, organizara el mapa por clasificación (filo, orden, familia, género y especie) y también le pedí que generara datos de rotación de cultivos.
Por ejemplo, mis instrucciones:
- "Datos complementarios para reforzar la vinculación de datos".
- "Haz un atlas de estas clasificaciones [de filos, órdenes, familias, géneros y especies]".
- "Identificar contraindicaciones y ganar cultivos en la rotación de cultivos existentes".
- "Combinación de datos de tejidos de cultivos mapeados para dar scripts nGQL en el formato anterior"
Interludio experimental: DeepSeek, una vez. INSERTAR utiliza la sintaxis Cypher, que no es compatible con nGQL, y se señaló y cambió.
Instrucciones: "Esta sentencia insert no es sintaxis nGQL. Cámbiela para que DDL vaya primero y DML después".
Volumen final de datos: Tras unas cuantas rondas de diálogo, se muestra la cantidad de datos:

Efectos cartográficos: Expande algunos nodos al azar para ver:
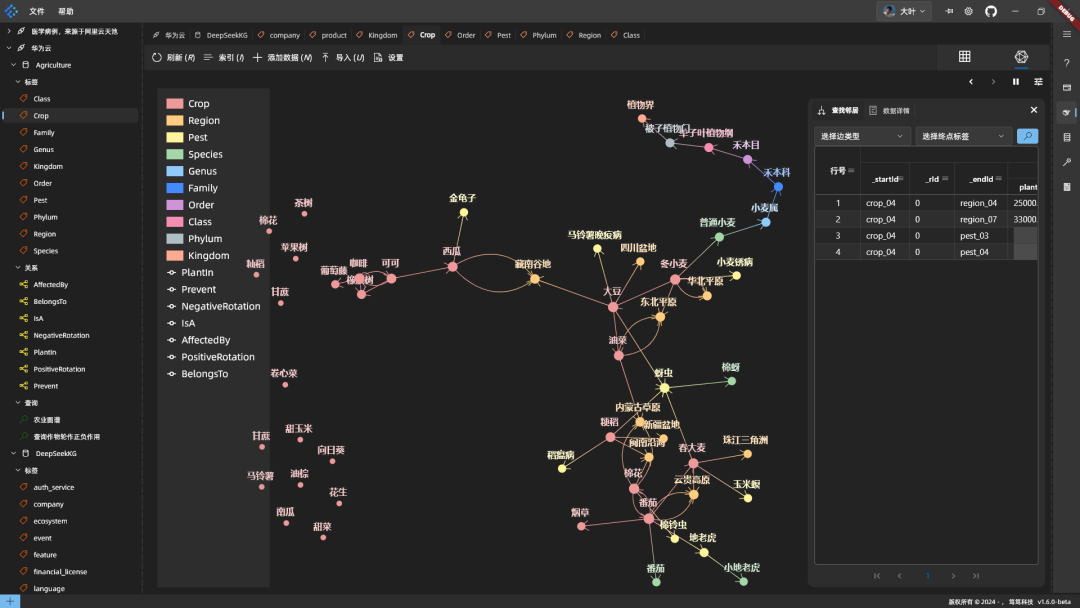
Ejemplos de combinaciones de especies rotativas que aumentan el rendimiento: Efectos combinatorios de la plantación adventicia que mejoran el rendimiento:
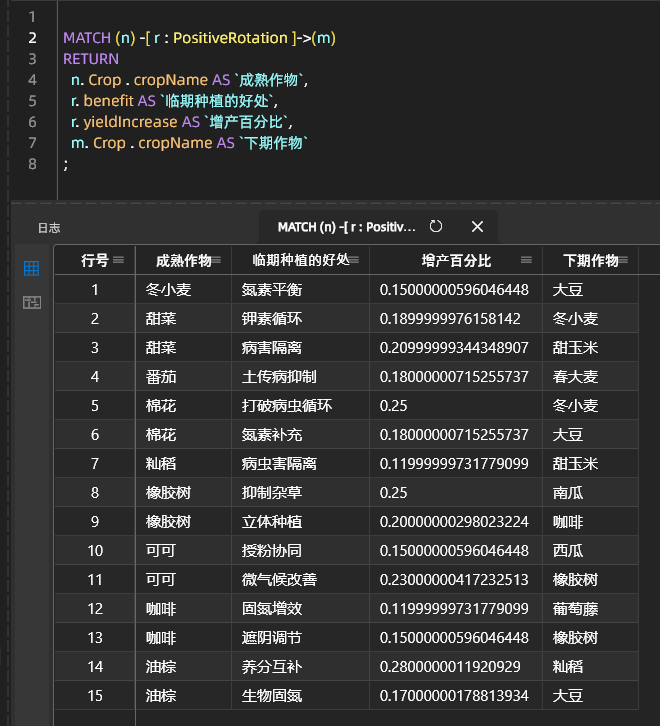
IV. Resumen
Conclusión: DeepSeek destaca en la construcción y fusión de grafos de conocimiento, y los experimentos demuestran sus capacidades:
- La extracción de información es rápida y precisa: DeepSeek extrae rápidamente la información clave del texto, genera scripts nGQL compatibles y posee una gran comprensión del lenguaje para reconocer entidades, relaciones y eventos.
- Gran capacidad para integrar conocimientos: DeepSeek fusiona bien los conocimientos de varios artículos, amplía y actualiza el gráfico en función de los nuevos artículos y garantiza la integridad y precisión del gráfico.
- Se puede construir un mapa de la nada: Ningún artículo puede generar gráficos por temas. Hay algunos contratiempos de sintaxis en el proceso de generación, pero los ajustes producen scripts pasables.
- Hay que optimizar los detalles: Los scripts generados por DeepSeek presentan ocasionalmente problemas de sintaxis, como comentarios incorrectos. Cuando se genera un gran número de nodos, el servidor puede tardar en responder. Debes prestar atención a estos problemas cuando lo utilices realmente.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...