
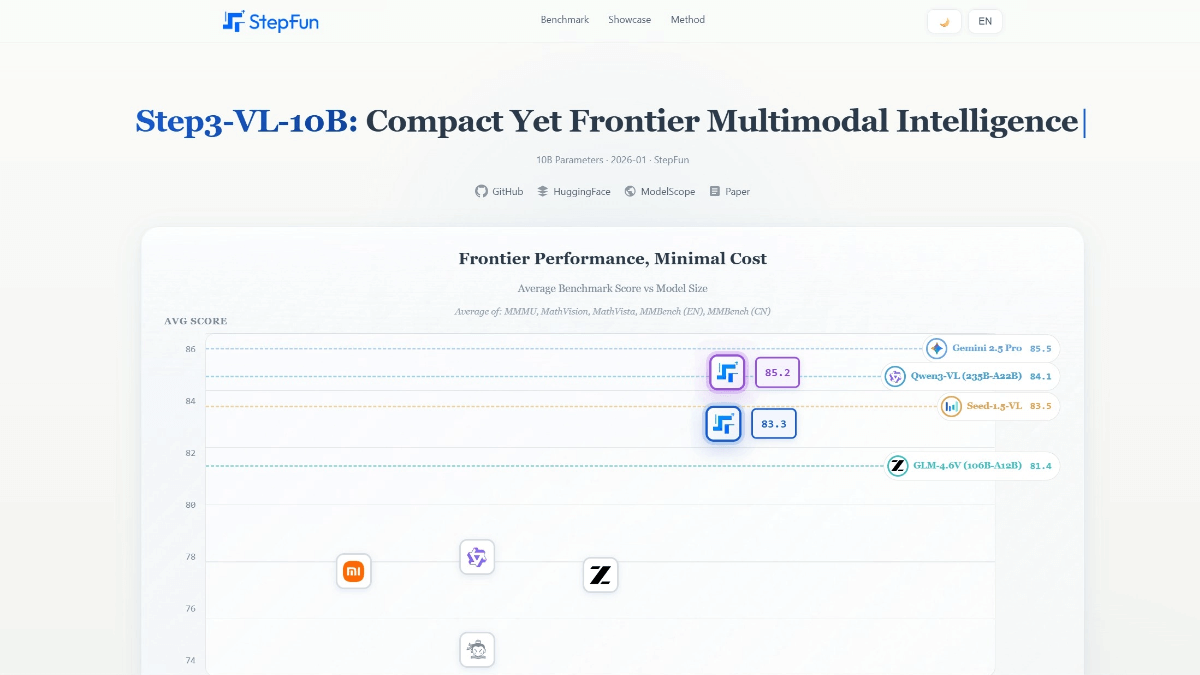
DeepSeek-R1-FP4: versión optimizada para FP4 de la inferencia DeepSeek-R1 25 veces más rápida
Últimos recursos sobre IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 56.3K 00

Introducción general
DeepSeek-R1-FP4 es un modelo de lenguaje cuantificado de código abierto y optimizado por NVIDIA basado en la tecnología DeepSeek IA DeepSeek-R1 Desarrollo. Cuantifica los pesos y los valores de activación en tipos de datos FP4 utilizando el optimizador de modelos TensorRT, lo que permite al modelo reducir significativamente los requisitos de recursos manteniendo un alto rendimiento. Con aproximadamente 1,6 veces menos espacio en disco y memoria de GPU en comparación con el modelo original, es ideal para la inferencia eficiente en entornos de producción. Optimizado específicamente para la arquitectura Blackwell de NVIDIA, el modelo proporciona hasta 25 veces más velocidad de inferencia por GPU. ficha Es 20 veces más barato y demuestra un gran potencial de rendimiento. Admite longitudes de contexto de hasta 128K, es adecuado para procesar tareas de texto complejas y está abierto a uso comercial y no comercial, lo que ofrece a los desarrolladores una solución de IA rentable.

Lista de funciones
- Razonamiento eficienteMejora drástica de la velocidad de inferencia y optimización del uso de recursos mediante la cuantización FP4.
- Ayuda a largo plazo:: Admite una longitud de contexto máxima de 128K, lo que resulta adecuado para procesar tareas de generación de textos largos.
- Despliegue de TensorRT-LLMPuede implementarse rápidamente para ejecutarse en GPUs NVIDIA utilizando el framework TensorRT-LLM.
- uso del código abierto:: Soporte para escenarios comerciales y no comerciales, permitiendo la libre modificación y el desarrollo derivado.
- optimización del rendimiento: Diseñado para la arquitectura Blackwell, proporciona una eficacia de inferencia y una rentabilidad ultraelevadas.
Utilizar la ayuda
Proceso de instalación y despliegue
La implementación de DeepSeek-R1-FP4 requiere cierto soporte de hardware y software, especialmente la GPU NVIDIA y el framework TensorRT-LLM. A continuación se incluye una guía detallada de instalación y uso para ayudar a los usuarios a empezar rápidamente.
1. Preparación medioambiental
- requisitos de hardwareGPU de arquitectura NVIDIA Blackwell : se recomiendan las GPU de arquitectura NVIDIA Blackwell (por ejemplo, B200), que requieren al menos 8 GPU (cada una con ~336 GB de VRAM sin cuantificar, ~1342 GB después de la cuantificación para cumplir los requisitos del modelo). Para pruebas más pequeñas, se recomienda al menos 1 GPU de alto rendimiento (por ejemplo, A100/H100).
- dependencia del software:
- Sistema operativo: Linux (por ejemplo, Ubuntu 20.04 o posterior).
- Controlador NVIDIA: última versión (compatible con CUDA 12.4 o superior).
- TensorRT-LLM: La última versión de la rama maestra debe compilarse a partir de las fuentes de GitHub.
- Python: 3.11 o posterior.
- Otras bibliotecas:
tensorrt_llmytorchetc.
2. Descargar modelo
- entrevistas Cara de abrazo PáginaHaga clic en la pestaña "Archivos y versiones".
- Descargue el archivo del modelo (por ejemplo
model-00001-of-00080.safetensors(etc., un total de 80 slices, con un tamaño total de más de 400 GB). - Guarde el archivo en un directorio local, por ejemplo
/path/to/model/.
3. Instalación de TensorRT-LLM
- Clona el último repositorio de TensorRT-LLM desde GitHub:
git clone https://github.com/NVIDIA/TensorRT-LLM.git cd TensorRT-LLM
- Compilar e instalar:
make build pip install -r requirements.txt - Verifica la instalación:
python -c "import tensorrt_llm; print(tensorrt_llm.__version__)"
4. Modelo de despliegue
- Cargue y ejecute el modelo utilizando el código de ejemplo proporcionado:
from tensorrt_llm import SamplingParams, LLM # 初始化模型 llm = LLM( model="/path/to/model/nvidia/DeepSeek-R1-FP4", tensor_parallel_size=8, # 根据 GPU 数量调整 enable_attention_dp=True ) # 设置采样参数 sampling_params = SamplingParams(max_tokens=32) # 输入提示 prompts = [ "你好,我的名字是", "美国总统是", "法国的首都是", "AI的未来是" ] # 生成输出 outputs = llm.generate(prompts, sampling_params) for output in outputs: print(output) - Antes de ejecutar el código anterior, asegúrate de que los recursos de la GPU se han asignado correctamente. Si los recursos son insuficientes, ajuste la
tensor_parallel_sizeParámetros.
5. Guía de funcionamiento
Razonamiento eficiente
- El punto fuerte de DeepSeek-R1-FP4 es su tecnología de cuantificación FP4. En lugar de ajustar manualmente los parámetros del modelo, los usuarios pueden simplemente asegurarse de que su hardware es compatible con la arquitectura Blackwell y experimentar un aumento de la velocidad de inferencia. En tiempo de ejecución, se recomienda configurar
max_tokenscontrola la longitud de la salida para evitar el desperdicio de recursos. - Ejemplo de cómo hacerlo: Ejecute un script de Python en un terminal, introduzca diferentes indicaciones y observe la velocidad y la calidad de la salida.
procesamiento de contexto largo
- El modelo admite longitudes de contexto de hasta 128K, lo que resulta adecuado para generar artículos largos o procesar diálogos complejos.
- Funcionamiento: En el
promptsIntroduzca un contexto largo, como el comienzo de un artículo de 5.000 palabras y, a continuación, establezca la opciónmax_tokens=1000El texto se genera de la misma manera que el texto que sigue. Compruebe la coherencia del texto generado después de ejecutarlo. - Advertencia: Los contextos largos pueden incrementar el uso de memoria, se recomienda monitorizar el uso de memoria de la GPU.
optimización del rendimiento
- Si se utilizan GPU Blackwell, puede beneficiarse directamente de una aceleración de 25x en la inferencia. Si se utilizan otras arquitecturas (por ejemplo, A100), el aumento de rendimiento puede ser ligeramente inferior, pero sigue siendo significativamente mejor que el modelo sin cuantificar.
- Sugerencia de funcionamiento: En un entorno multi-GPU, ajuste el
tensor_parallel_sizepara aprovechar al máximo los recursos de hardware. Por ejemplo, 8 GPUs se establece en 8 y 4 GPUs se establece en 4.
6. Preguntas frecuentes y soluciones
- memoria de vídeo insuficiente: Si se produce un desbordamiento de memoria, reduzca
tensor_parallel_sizeo utilizar una versión menos cuantificada (por ejemplo, el formato GGUF proporcionado por la comunidad). - Razonamiento lentoAsegúrese de que TensorRT-LLM se ha compilado correctamente y la aceleración de GPU está activada, compruebe que la versión del controlador coincide.
- anomalía de salida: Compruebe el formato de la consulta de entrada para asegurarse de que ningún carácter especial interfiere con el modelo.
Recomendaciones de uso
- uso inicial: Empieza con pistas sencillas y aumenta gradualmente la longitud del contexto para familiarizarte con el funcionamiento del modelo.
- entorno de producciónPruebe varios conjuntos de avisos antes de la implantación para asegurarse de que el resultado cumple las expectativas. Se recomienda optimizar el acceso multiusuario con herramientas de equilibrio de carga.
- Personalización para desarrolladores:: Los modelos pueden modificarse basándose en licencias de código abierto para adaptarse a tareas específicas, como la generación de código o los sistemas de preguntas y respuestas.
Con estos pasos, los usuarios pueden desplegar y utilizar rápidamente DeepSeek-R1-FP4 para disfrutar de la comodidad de una inferencia eficiente.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...