DeepSeek-OCR - Modelo de reconocimiento óptico de caracteres de código abierto DeepSeek
Últimos recursos sobre IAActualizado hace 6 meses Círculo de intercambio de inteligencia artificial 40.6K 00

¿Qué es DeepSeek-OCR?
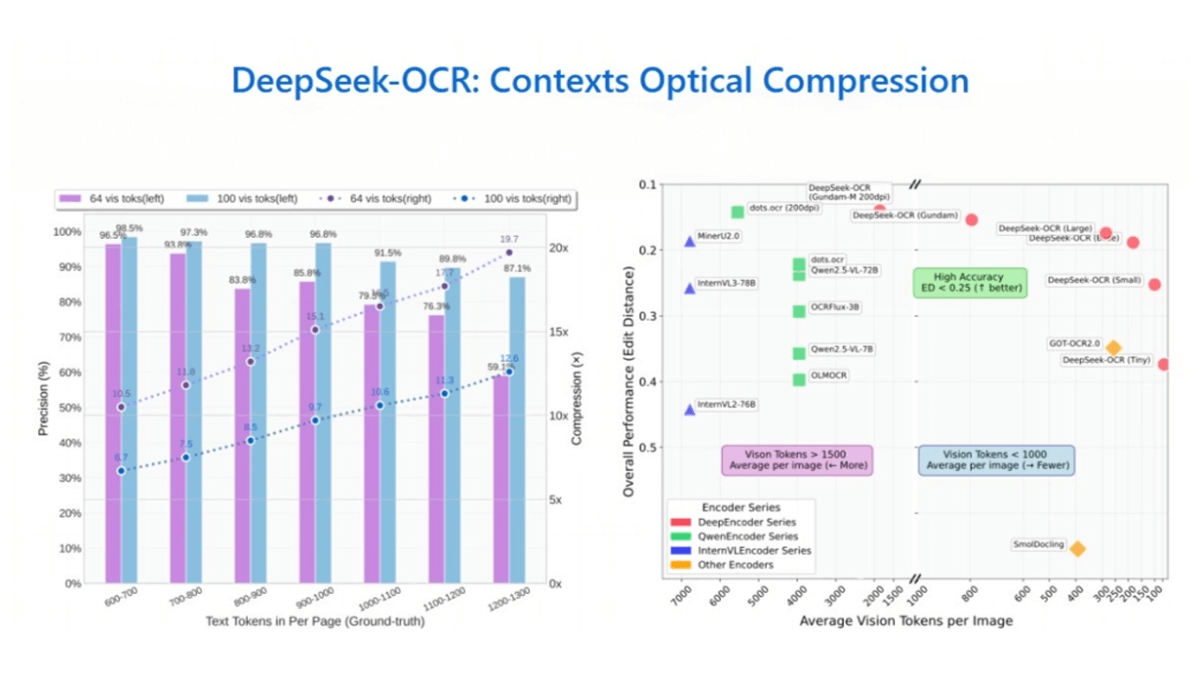
DeepSeek-OCR es DeepSeek El modelo avanzado de reconocimiento óptico de caracteres (OCR) de código abierto del equipo convierte el texto en imágenes mediante la tecnología de "compresión óptica contextual", que utiliza la visión de la imagen. ficha Es capaz de comprimir y descodificar para procesar eficazmente textos largos. Entre sus características técnicas destacan su alto índice de compresión (precisión de hasta 97% con una compresión de 10x), la comprensión conjunta de visión y lenguaje, la compatibilidad con múltiples estructuras y formatos (JPG, PNG, PDF, etc. y el reconocimiento multilingüe), la arquitectura VLM de extremo a extremo, etc. Puede utilizarse en una amplia gama de escenarios de aplicación, como textos largos, documentos complejos y despliegue multilingüe. Amplia gama de escenarios de aplicación, manejo de textos largos, documentos complejos, soporte multilingüe, despliegue localizado. Presenta importantes ventajas de rendimiento, como su alta eficiencia (una sola tarjeta gráfica A100-40G permite generar más de 200.000 páginas de datos de entrenamiento al día), baja latencia (reconocimiento en tiempo real a 15 fotogramas por segundo en dispositivos móviles, con una latencia inferior a 100 milisegundos) y gran adaptabilidad (precisión de reconocimiento de hasta 98,7% en escenarios complejos). El código fuente abierto y los pesos del modelo se han publicado para comodidad de los desarrolladores.
Características de DeepSeek-OCR
- Compresión óptica contextualConvertir texto en imagen, comprimir y descodificar mediante token visual para lograr un procesamiento eficaz de textos largos con una precisión de hasta 97% con una compresión de 10x.
- Comprensión conjunta visual-verbal: Combinación de la información visual de las imágenes con la capacidad de comprender modelos lingüísticos para captar con precisión la semántica y la estructura del texto.
- Soporte multiestructura y multiformatoAdmite una amplia gama de formatos de imagen (JPG, PNG, PDF), así como el reconocimiento multilingüe, y también puede trabajar bien con escritura a mano, texto mixto y documentos con una mezcla de gráficos y texto.
- Alta relación de compresión y gran precisiónEn una compresión de 10x, la precisión del OCR puede alcanzar los 97%; incluso si la tasa de compresión aumenta a 20x, la precisión del modelo puede mantenerse en torno a los 60%.
- Arquitectura VLM de extremo a extremoSe utilizan un codificador DeepEncoder y un descodificador DeepSeek3B-MoE. El codificador se encarga de extraer las características de la imagen, la tokenización y la compresión de la representación visual, y el descodificador genera los resultados requeridos basándose en tokens y claves de la imagen.
- Amplia gama de aplicacionesLas siguientes son algunas de las características de la versión más reciente de TP3T: puede "disparar" un documento de miles de palabras en un solo diagrama, logrando una reducción precisa de 97% a menos de una décima parte del coste, y proporcionando una solución eficaz al problema de los contextos largos en grandes modelos lingüísticos; puede reconocer información en texto, gráficos y diagramas en tablas o estados financieros, e incluso puede leer fórmulas moleculares químicas, fórmulas matemáticas y formas geométricas, incluso leer fórmulas moleculares químicas, fórmulas matemáticas y formas geométricas; es compatible con más de 100 idiomas, incluidos el chino y el inglés; admite la implantación local, lo que evita el envío de documentos sensibles a servicios en la nube de terceros.
- Importantes ventajas de rendimientoLa tarjeta gráfica A100-40G puede generar más de 200.000 páginas al día de datos de entrenamiento de modelos de lenguaje visual/modelos de lenguaje de gran tamaño; en los dispositivos móviles se puede conseguir un reconocimiento en tiempo real a 15 fotogramas por segundo con una latencia inferior a 100 milisegundos; gracias al módulo de fusión de características dinámicas multiescala y al descodificador sensible al contexto, la precisión de reconocimiento del modelo en escenas complejas se dispara hasta el 98,7%, 6,4 puntos porcentuales más que la media del sector. 6,4 puntos porcentuales por encima de la media del sector.
Principales ventajas de DeepSeek-OCR
- Compresión óptica contextual eficienteA modo de ejemplo: al convertir el texto en imágenes y utilizar fichas visuales para la compresión y descodificación, consigue una elevada relación de compresión manteniendo una gran precisión, con una precisión de hasta 97% con una compresión de 10x, y de alrededor de 60% con una compresión de 20x, lo que resuelve eficazmente el problema del tratamiento de textos largos.
- Una profunda fusión de visión y lenguajeEl modelo lingüístico: combinando la información visual de la imagen (por ejemplo, ubicación, disposición, gráficos, límites de la tabla) y la comprensión del modelo lingüístico, no sólo reconoce el contenido textual, sino que también capta con precisión la semántica y la estructura de la disposición para mejorar el tratamiento de documentos complejos.
- Amplia compatibilidad de formatos e idiomasAdmite una amplia gama de formatos de imagen (JPG, PNG, PDF) y más de 100 idiomas, y también maneja escritura a mano, texto mixto y documentos con una mezcla de gráficos y texto, lo que lo hace adecuado para una gran variedad de escenarios.
- Potente rendimientoUna sola tarjeta gráfica A100-40G puede soportar más de 200.000 páginas al día de generación de datos de entrenamiento de grandes modelos lingüísticos; reconocimiento en tiempo real a 15 fotogramas por segundo con una latencia inferior a 100 milisegundos en dispositivos móviles; y una precisión de reconocimiento de hasta 98,71 TP3T en escenas complejas, significativamente mejor que la media del sector.
- Despliegue flexibleAdmite la implantación localizada para evitar el envío de documentos confidenciales a servicios en la nube de terceros, salvaguardar la seguridad de los datos y satisfacer las necesidades de los distintos usuarios para los entornos de implantación.
¿Cuál es la página web oficial de DeepSeek-OCR?
- Repositorio GitHub:: https://github.com/deepseek-ai/DeepSeek-OCR
- Biblioteca de modelos HuggingFace:: https://huggingface.co/deepseek-ai/DeepSeek-OCR
- Documentos técnicos:: https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
¿Para quién es DeepSeek-OCR?
- usuario empresarial: Debe tratar un gran número de documentos, como estados financieros, contratos, documentos técnicos, etc. Puede mejorar la eficacia del trabajo y reducir los costes laborales gracias a la eficacia del tratamiento de textos largos y a la capacidad de reconocimiento de documentos complejos.
- investigador (científico)La compatibilidad multilingüe y la capacidad de reconocimiento preciso de DeepSeek-OCR pueden ayudar en la investigación académica, donde a menudo es necesario manejar contenidos complejos como documentos multilingües, gráficos y fórmulas.
- educadorPara la organización y digitalización de materiales didácticos, como la producción de material didáctico y el análisis de trabajos de examen, etc. Sus funciones de reconocimiento de escritura a mano y de soporte multiformato pueden satisfacer las necesidades de la enseñanza.
- desarrollador: El código fuente abierto y los pesos del modelo facilitan a los desarrolladores la integración en sus propios proyectos, el desarrollo de aplicaciones OCR personalizadas y la ampliación de sus escenarios de aplicación.
- usuario individualDeepSeek-OCR es una solución cómoda y eficaz para extraer el contenido de documentos, organizar notas, traducir materiales en idiomas extranjeros y otros escenarios para mejorar la eficacia personal en la oficina y el estudio.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...