
¿Cómo se hacen "más inteligentes" los grandes modelos? La Universidad de Stanford revela la clave de la superación personal: cuatro comportamientos cognitivos

El campo de la Inteligencia Artificial ha registrado avances impresionantes en los últimos años, especialmente en el ámbito de los modelos de grandes lenguajes (LLM). Muchos modelos, como Qwen, han demostrado una asombrosa capacidad para autocomprobar respuestas y corregir errores. Sin embargo, no todos los modelos tienen la misma capacidad de automejora. Si se les proporcionan los mismos recursos informáticos y el mismo tiempo para "pensar", algunos modelos son capaces de aprovechar al máximo estos recursos y mejorar su rendimiento de forma espectacular, mientras que otros tienen poco éxito. Este fenómeno plantea la siguiente pregunta: ¿qué factores son responsables de esta discrepancia?
Del mismo modo que los seres humanos dedican más tiempo a pensar en profundidad cuando se enfrentan a problemas difíciles, algunos modelos avanzados de grandes lenguajes empiezan a mostrar un comportamiento de razonamiento similar cuando se entrenan para la autosuperación mediante el aprendizaje por refuerzo. Sin embargo, existen diferencias significativas en la autosuperación entre modelos entrenados con el mismo aprendizaje por refuerzo. Por ejemplo, Qwen-2.5-3B supera con creces a Llama-3.2-3B en el juego de la cuenta atrás. Aunque ambos modelos son relativamente débiles en la fase inicial, al final del entrenamiento mediante aprendizaje por refuerzo, Qwen alcanza una precisión de unos 60%, mientras que Llama sólo llega a unos 30%. ¿Cuál es el mecanismo oculto tras esta importante diferencia?
Un reciente estudio de Stanford ha ahondado en los mecanismos que subyacen a la capacidad de los grandes modelos para superarse a sí mismos, revelando que los modelos lingüísticos clave en la subyacente comportamiento cognitivo La importancia de la IA. Esta investigación ofrece nuevas perspectivas para comprender y potenciar las capacidades de auto-mejora de los sistemas de IA.
El estudio ha sido ampliamente comentado tras su publicación. El director general de Synth Labs, por ejemplo, cree que el descubrimiento es emocionante porque promete integrarse en cualquier modelo para mejorar su rendimiento.

Cuatro comportamientos cognitivos clave
Para investigar las razones de las diferencias en la superación, los investigadores se centraron en dos modelos base, Qwen-2.5-3B y Llama-3.2-3B. Al entrenarlos con aprendizaje por refuerzo en el juego de la Cuenta Atrás, los investigadores observaron diferencias significativas: la capacidad de resolución de problemas de Qwen mejoró notablemente, mientras que Llama-3 mostró una mejora relativamente limitada durante el mismo proceso de entrenamiento. Entonces, ¿qué propiedades del modelo son responsables de esta diferencia?

Para examinar sistemáticamente esta cuestión, el equipo de investigación elaboró un marco de análisis de los comportamientos cognitivos fundamentales para la resolución de problemas. El marco describe cuatro comportamientos cognitivos clave:
- Verificación:: Comprobación sistemática de errores.
- Retroceso:: Abandonar los enfoques fallidos y probar nuevos caminos.
- Fijación de subobjetivosDesglose los problemas complejos en pasos manejables.
- Pensamiento inversoDerivación inversa del resultado deseado a la entrada inicial.
Estas pautas de comportamiento son muy similares a la forma en que los expertos en resolución de problemas abordan tareas complejas. Por ejemplo, los matemáticos realizan pruebas verificando cuidadosamente cada paso de la derivación, retrocediendo para comprobar pasos anteriores cuando se encuentran contradicciones y descomponiendo teoremas complejos en lemas más sencillos para realizar pruebas paso a paso.

Los análisis preliminares indican que el modelo Qwen muestra de forma natural estos comportamientos de inferencia, sobre todo en las áreas de validación y retroceso, mientras que el modelo Llama-3 carece llamativamente de ellos. A partir de estas observaciones, los investigadores formularon la hipótesis central: Ciertos comportamientos de razonamiento en la estrategia inicial son fundamentales para que el modelo aproveche eficazmente el mayor tiempo de prueba. En otras palabras, si un modelo de IA quiere ser "más inteligente" cuando tiene más tiempo para "pensar", primero debe tener algunas habilidades básicas de pensamiento, como el hábito de comprobar si hay errores y verificar los resultados. Si el modelo carece de estas habilidades básicas de pensamiento desde el principio, no podrá mejorar eficazmente su rendimiento aunque se le dé más tiempo para pensar y más recursos computacionales. Esto es muy similar al proceso de aprendizaje humano: si los estudiantes carecen de habilidades básicas de autocomprobación y corrección de errores, es poco probable que simplemente haciendo exámenes más largos mejoren significativamente su rendimiento.
Validación experimental: la importancia del comportamiento cognitivo
Para probar la hipótesis anterior, los investigadores llevaron a cabo una serie de experimentos de intervención inteligente.
En primer lugar, intentaron realizar un bootstrap del modelo Llama-3 utilizando trayectorias de inferencia sintéticas que contenían comportamientos cognitivos específicos (especialmente retrospección). Los resultados muestran que el modelo Llama-3 así guiado presenta mejoras significativas en el aprendizaje por refuerzo, con ganancias de rendimiento incluso comparables a Qwen-2.5-3B.
En segundo lugar, aunque las trayectorias de razonamiento utilizadas para el bootstrapping contuvieran respuestas incorrectas, el modelo Llama-3 seguía siendo capaz de progresar siempre que estas trayectorias presentaran patrones de razonamiento correctos. Este hallazgo sugiere que el El factor clave que realmente impulsa la autosuperación del modelo es la presencia de comportamientos de razonamiento, no la corrección de la respuesta en sí.
Por último, los investigadores filtraron el conjunto de datos OpenWebMath para enfatizar estos comportamientos de razonamiento y utilizaron estos datos para preentrenar el modelo Llama-3. Los resultados experimentales muestran que esta adaptación específica de los datos de preentrenamiento es eficaz para inducir los comportamientos de inferencia necesarios para que el modelo haga un uso eficiente de los recursos computacionales. La trayectoria de mejora del rendimiento del modelo Llama-3 preentrenado y ajustado es sorprendentemente coherente con la del modelo Qwen-2.5-3B.
Los resultados de estos experimentos revelan claramente la existencia de un fuerte vínculo entre el comportamiento inicial de razonamiento de un modelo y su capacidad para mejorarse a sí mismo. Este vínculo ayuda a explicar por qué algunos modelos lingüísticos son capaces de utilizar eficientemente recursos computacionales adicionales, mientras que otros se estancan. Comprender mejor esta dinámica es esencial para desarrollar sistemas de IA capaces de mejorar significativamente la resolución de problemas.
Juego de cuenta atrás con selección de modelo
El estudio comienza con una observación sorprendente: modelos lingüísticos de tamaño similar, pertenecientes a distintas familias de modelos, muestran mejoras de rendimiento muy diferentes cuando se entrenan con aprendizaje por refuerzo. Para explorar a fondo este fenómeno, los investigadores eligieron el juego Countdown como principal banco de pruebas.
Countdown es un puzzle matemático en el que el jugador tiene que combinar un conjunto dado de números utilizando las cuatro operaciones básicas de suma, resta, multiplicación y división para alcanzar un número objetivo. Por ejemplo, dados los números 25, 30, 3, 4 y el número objetivo 32, el jugador debe obtener el número exacto 32 mediante una serie de operaciones, por ejemplo (30 - 25 + 3) × 4 = 32.
Se eligió el juego Cuenta Atrás para este estudio porque examina las capacidades de razonamiento matemático, planificación y estrategia de búsqueda del modelo, al tiempo que proporciona un espacio de búsqueda relativamente restringido que permite al investigador realizar análisis en profundidad. En comparación con dominios más complejos, el juego Cuenta Atrás reduce la dificultad del análisis sin dejar de examinar eficazmente el razonamiento complejo. Además, el éxito de Cuenta Atrás se basa más en las habilidades de resolución de problemas que en otras tareas matemáticas, más que en los conocimientos matemáticos puros.
Los investigadores eligieron dos modelos base, Qwen-2.5-3B y Llama-3.2-3B, para comparar las diferencias de aprendizaje entre las distintas familias de modelos. Los experimentos de aprendizaje por refuerzo se basan en la biblioteca VERL y se implementan con TinyZero. Utilizaron el algoritmo PPO (Proximal Policy Optimization) para entrenar el modelo durante 250 pasos, muestreando 4 trayectorias por taco. La razón de elegir el algoritmo PPO es que, en comparación con el algoritmo GRPO y otros algoritmos de aprendizaje por refuerzo como REINFORCE, PPO muestra una mejor estabilidad bajo varias configuraciones de hiperparámetros, aunque la diferencia de rendimiento global entre algoritmos no es significativa. (Nota del editor: Se sospecha que el original "GRPO" es un error administrativo y debería decir PPO.)
Los resultados experimentales revelan trayectorias de aprendizaje muy diferentes para los dos modelos. Aunque ambos tienen un rendimiento similar al principio de la tarea, con puntuaciones bajas, Qwen-2.5-3B muestra un "salto cualitativo" en torno al paso 30 del entrenamiento, como demuestran las respuestas significativamente más largas generadas por el modelo y un aumento significativo de la precisión. Al final del entrenamiento, Qwen-2.5-3B alcanza una precisión de unos 601 TP3T, muy superior a los 301 TP3T de Llama-3.2-3B.
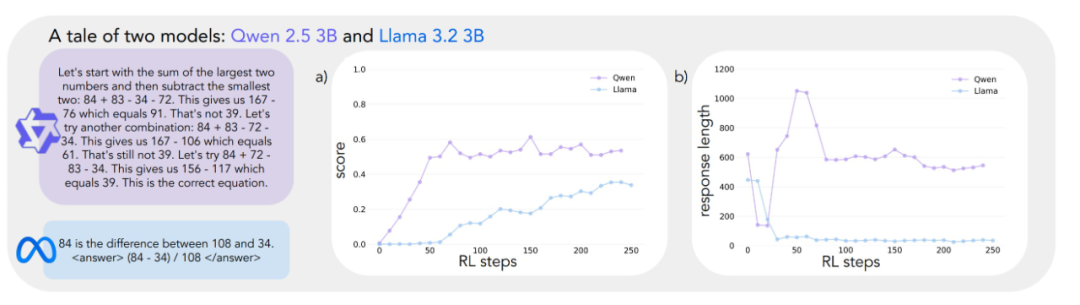
En las últimas fases del entrenamiento, los investigadores observaron un cambio interesante en el comportamiento de Qwen-2.5-3B: el modelo pasó gradualmente de utilizar afirmaciones de validación explícitas (por ejemplo, "8*35 es 280, demasiado alto") a la comprobación implícita de soluciones. El modelo последовательно (en ruso, traducido como "последовательно tierra" o "secuencialmente") probará diferentes soluciones hasta encontrar la correcta, en lugar de evaluar su propio trabajo utilizando palabras. El contraste es sorprendente. Este contraste lleva a una pregunta central: ¿cuáles son las capacidades subyacentes que permiten a un modelo lograr con éxito la autosuperación basada en el razonamiento? Responder a esta pregunta requiere un marco sistemático para analizar el comportamiento cognitivo.
Marco del análisis cognitivo-conductual
Con el fin de comprender mejor las trayectorias de aprendizaje tan diferentes de ambos modelos, los investigadores desarrollaron un marco para identificar y analizar los comportamientos cognitivos clave en los resultados del modelo. El marco se centra en cuatro comportamientos básicos:
- Retroceso: Modifica explícitamente el método cuando se detecta un error (por ejemplo, "Este método no funciona porque ...) .").
- VerificaciónCompruebe sistemáticamente los resultados intermedios (por ejemplo, "validemos este resultado mediante ... para verificar este resultado").
- Fijación de subobjetivosDescomponer problemas complejos en pasos manejables (por ejemplo, "Para resolver este problema, primero tenemos que..."). .
- Pensamiento inversoEn los problemas de razonamiento orientado a objetivos, comience con un resultado deseado y trabaje hacia atrás para encontrar un camino hacia la solución (p. ej., "Para alcanzar el objetivo de 75, necesitamos un número que sea ... divisible por ..."). . para alcanzar el objetivo de 75, necesitamos un número que sea divisible por ...").
Se eligieron estos comportamientos porque representan una estrategia de resolución de problemas muy distinta de los patrones de razonamiento lineal y monótono habituales en los modelos lingüísticos. Estos comportamientos cognitivos permiten trayectorias de razonamiento más dinámicas, similares a las de la búsqueda, en las que las soluciones pueden evolucionar de forma no lineal. Aunque este conjunto de comportamientos no es exhaustivo, los investigadores los eligieron porque son fáciles de identificar y se ajustan de forma natural a las estrategias humanas de resolución de problemas en los juegos de Cuenta Atrás y en tareas de razonamiento matemático más amplias, como la construcción de pruebas matemáticas.
Cada comportamiento cognitivo puede entenderse a través de su papel en el razonamiento de la ficha Por ejemplo, el backtracking se representa negando y reemplazando explícitamente secuencias de tokens de pasos anteriores. Por ejemplo, el backtracking se representa como una secuencia de tokens que niegan y sustituyen explícitamente pasos anteriores; la validación se representa generando tokens que comparan los resultados con los criterios de solución; el backtracking se representa mediante tokens que construyen incrementalmente una ruta de solución al estado inicial desde el objetivo; y el establecimiento de submetas se representa sugiriendo explícitamente pasos intermedios a alcanzar a lo largo del camino hacia el objetivo final. Los investigadores desarrollaron un proceso de clasificación utilizando el modelo GPT-4o-mini que identifica con fiabilidad estos patrones en los resultados del modelo.
El efecto del comportamiento inicial en la superación personal
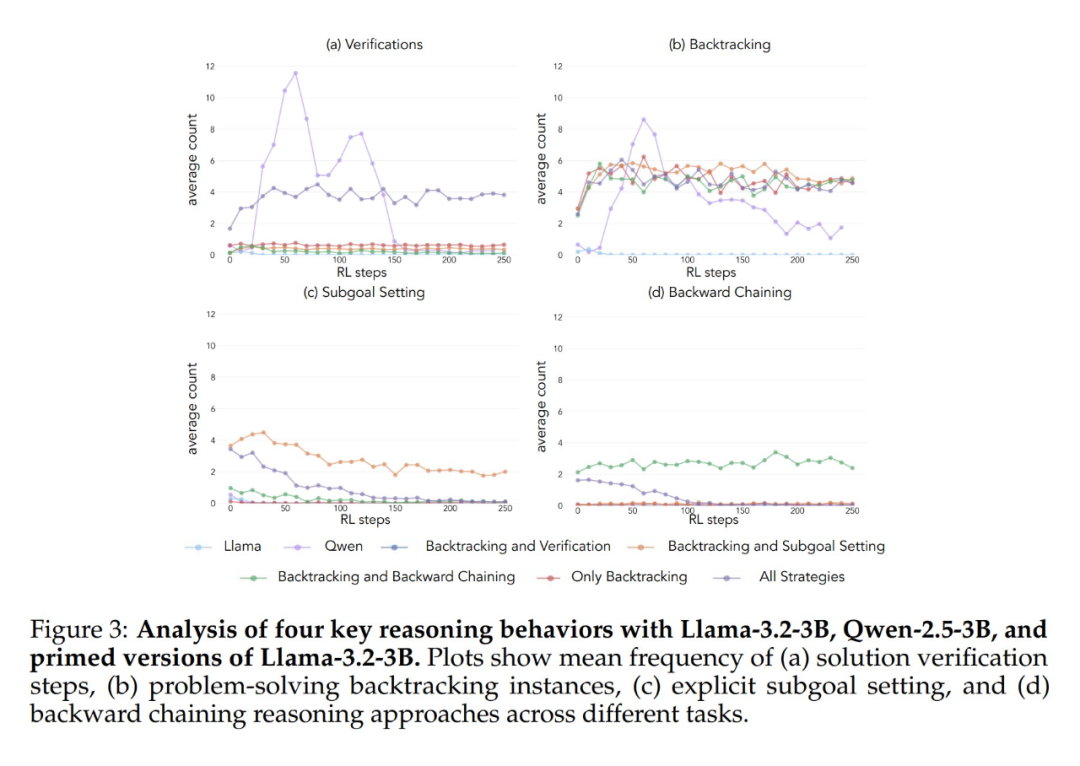
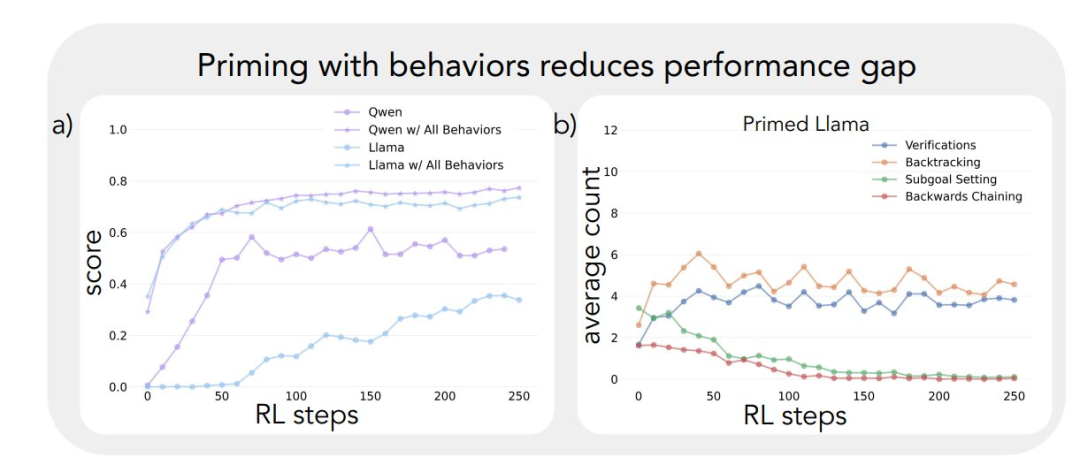
La aplicación del marco analítico anterior a los experimentos iniciales arrojó una idea clave: La mejora significativa del rendimiento del modelo Qwen-2.5-3B se produce paralelamente a la aparición de comportamientos cognitivos, en particular comportamientos de verificación y retroceso. En cambio, el modelo Llama-3.2-3B apenas mostró signos de estos comportamientos a lo largo del entrenamiento.
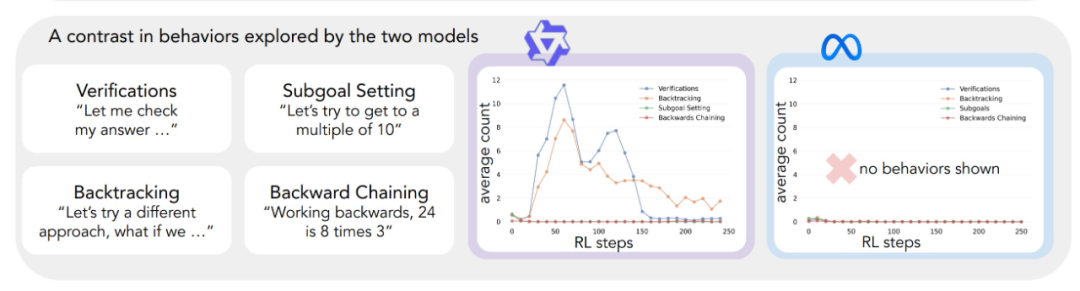
Para comprender mejor esta diferencia, los investigadores analizaron más a fondo los patrones de razonamiento de base de los tres modelos: Qwen-2.5-3B, Llama-3.2-3B y Llama-3.1-70B. Los resultados de los análisis mostraron que el modelo Qwen-2.5-3B producía proporciones más altas de todos los comportamientos cognitivos que las dos variantes del modelo Llama, Llama-3.2-3B y Llama-3.1-70B. El modelo Qwen-2.5-3B produjo una mayor proporción de todos los comportamientos cognitivos. Aunque el modelo Llama-3.1-70B, de mayor tamaño, activó en general estos comportamientos con más frecuencia que el modelo Llama-3.2-3B, este aumento fue desigual, especialmente en el caso de los comportamientos retrospectivos, que siguieron siendo limitados incluso en el modelo de mayor tamaño.

Estas observaciones revelan dos aspectos importantes:
- La presencia de ciertos comportamientos cognitivos en la estrategia inicial puede ser un prerrequisito necesario para que el modelo haga un uso eficaz del mayor tiempo de cálculo de la prueba ampliando la secuencia de inferencia.
- Aumentar el tamaño del modelo puede mejorar hasta cierto punto la frecuencia de activación contextual de estos comportamientos cognitivos.
Este modelo es crucial porque el aprendizaje por refuerzo sólo puede amplificar comportamientos que ya están presentes en trayectorias exitosas. Esto significa que la disponibilidad inicial de estos comportamientos cognitivos es un requisito previo para el aprendizaje efectivo en el modelo.
Intervenir en el comportamiento inicial: guiar el aprendizaje del modelo
Una vez establecida la importancia de los comportamientos cognitivos en el modelo base, la siguiente pregunta es: ¿Pueden inducirse artificialmente estos comportamientos en el modelo mediante intervenciones específicas? La hipótesis de los investigadores es que, creando variantes del modelo base que muestren selectivamente comportamientos cognitivos específicos antes del entrenamiento de aprendizaje por refuerzo, se podría llegar a una comprensión más profunda de qué patrones de comportamiento son esenciales para un aprendizaje eficaz.
Para probar esta hipótesis, primero diseñaron siete conjuntos de datos de inicio diferentes utilizando el juego Countdown. Cinco de estos conjuntos de datos hacían hincapié en diferentes combinaciones de comportamientos: todas las combinaciones de estrategias, sólo retroceso, retroceso y validación, retroceso y establecimiento de submetas, y retroceso y pensamiento retrospectivo. Utilizaron el modelo Claude-3.5-Sonnet para generar estos conjuntos de datos debido a la capacidad de Claude-3.5-Sonnet para generar trayectorias de inferencia con características de comportamiento especificadas con precisión.
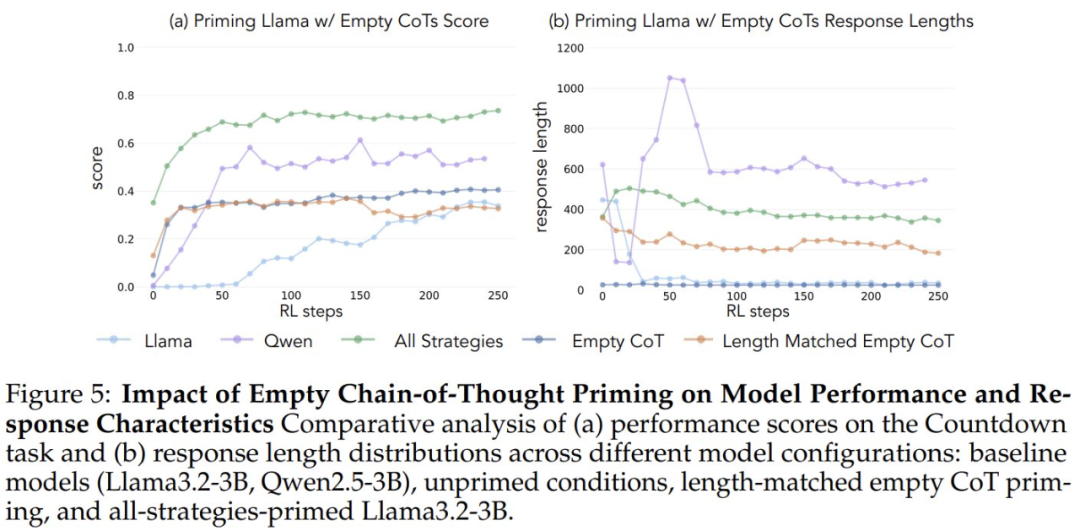
Para verificar que el aumento del rendimiento se debía a comportamientos cognitivos específicos y no simplemente a un aumento del tiempo de cálculo, los investigadores introdujeron también dos condiciones de control: una cadena de pensamiento vacía y una condición de control que poblaba la cadena de fichas de marcador de posición y hacía coincidir la longitud de los puntos de datos con el conjunto de datos "todas las combinaciones de estrategias". ". Estos conjuntos de datos de control ayudaron a los investigadores a verificar que cualquier mejora observada en el rendimiento se debía en realidad a comportamientos cognitivos específicos, y no sólo a un aumento del tiempo de cálculo.
Además, los investigadores crearon una variante del conjunto de datos "Combinación de estrategias completa", que sólo contiene soluciones incorrectas, pero conserva los patrones de razonamiento requeridos. El objetivo de esta variante es distinguir la diferencia entre la importancia del comportamiento cognitivo y la precisión de las soluciones.
Los resultados experimentales muestran que los modelos Llama-3 y Qwen-2.5-3B mejoran significativamente su rendimiento mediante el aprendizaje por refuerzo cuando se inicializan con un conjunto de datos que contiene comportamientos retrospectivos. El análisis del comportamiento muestra además que El aprendizaje por refuerzo amplifica selectivamente los comportamientos cuya utilidad se ha demostrado empíricamente, mientras que inhibe otros comportamientos. Por ejemplo, en la condición de combinación de estrategias completa, el modelo conserva y potencia las conductas retrospectivas y de validación, al tiempo que reduce la frecuencia de las conductas de pensamiento retrospectivo y fijación de submetas. Sin embargo, cuando se combina sólo con conductas retrospectivas, las conductas suprimidas (por ejemplo, el pensamiento retrospectivo y la fijación de submetas) persisten a lo largo del entrenamiento.
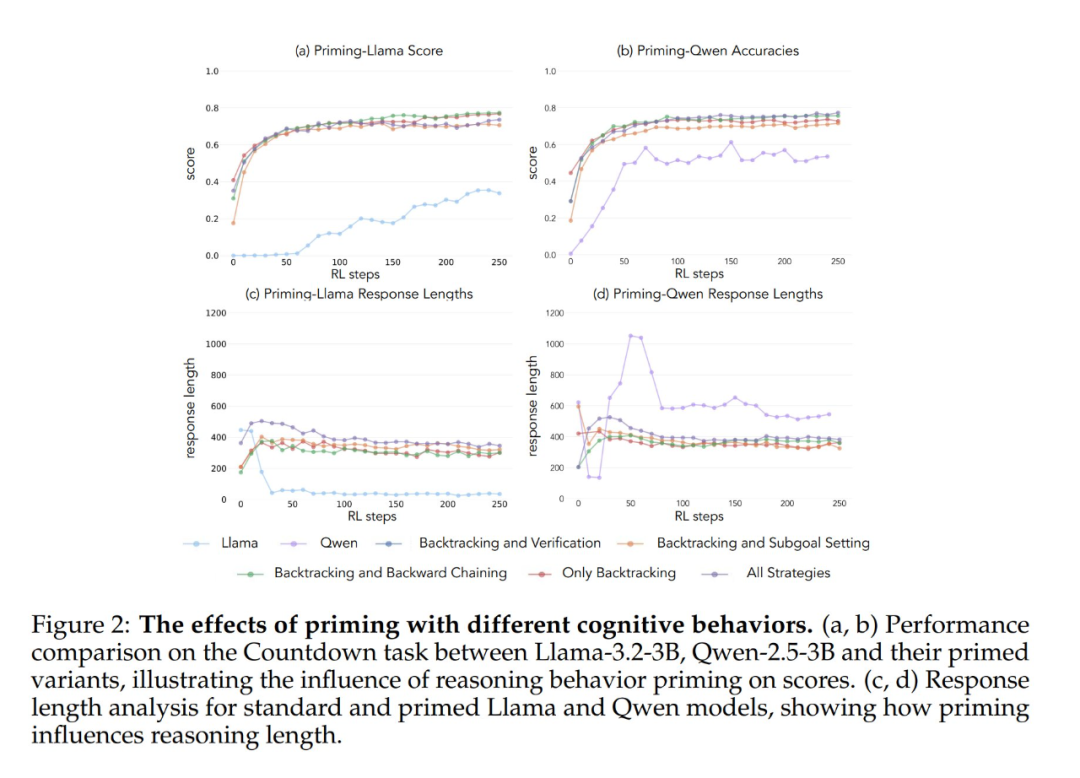
Cuando se iniciaron utilizando una cadena de pensamiento vacía como condición de control, ambos modelos obtuvieron resultados comparables a los del modelo básico Llama-3 (precisiones de aproximadamente 30%-35%). Esto sugiere que la simple asignación de tokens adicionales sin incluir comportamientos cognitivos no es un uso eficiente del cómputo del tiempo de prueba. Aún más sorprendente, el entrenamiento con cadenas de pensamiento vacías tuvo incluso un efecto perjudicial, ya que el modelo Qwen-2.5-3B dejó de explorar nuevos patrones de comportamiento. Una prueba más de que Estos comportamientos cognitivos son cruciales para que el modelo haga un uso eficiente de los recursos computacionales ampliados mediante secuencias de inferencia más largas.
Y lo que es aún más sorprendente, los modelos inicializados con soluciones incorrectas, pero con un comportamiento cognitivo correcto, alcanzaron casi el mismo nivel de rendimiento que los modelos entrenados con conjuntos de datos que contenían soluciones correctas. Este resultado sugiere que La presencia de comportamientos cognitivos (más que la adquisición de respuestas correctas) es un factor clave para el éxito de la superación personal mediante el aprendizaje por refuerzo. Así, los patrones de razonamiento de modelos relativamente débiles pueden guiar eficazmente el proceso de aprendizaje para construir modelos más sólidos. Esto demuestra una vez más que La presencia de un comportamiento cognitivo es más importante que la corrección del resultado.

Selección del comportamiento en los datos de preentrenamiento
Los resultados de estos experimentos sugieren que determinados comportamientos cognitivos son esenciales para la autosuperación de los modelos. Sin embargo, los métodos utilizados para inducir comportamientos específicos en los modelos iniciales en el estudio anterior eran específicos del dominio y se basaban en juegos de cuenta atrás. Esto puede afectar negativamente a la capacidad de generalización de la inferencia final. Entonces, ¿es posible aumentar la frecuencia de comportamientos de inferencia beneficiosos modificando la distribución de los datos de preentrenamiento del modelo para conseguir una capacidad de automejora más general?
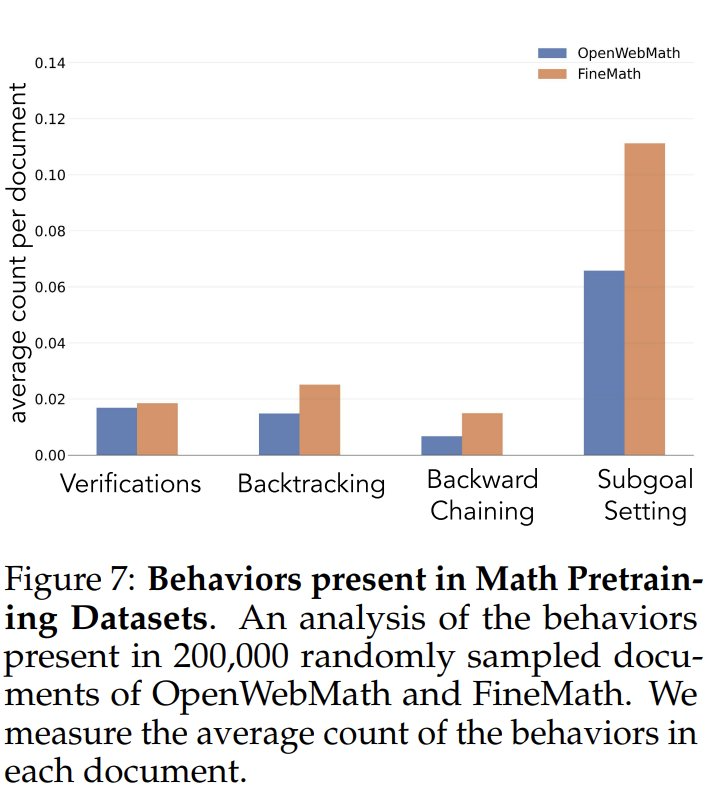
Para investigar la frecuencia de los comportamientos cognitivos en los datos de preentrenamiento, los investigadores analizaron primero las frecuencias naturales de los comportamientos cognitivos en los datos de preentrenamiento. Se centraron en los conjuntos de datos OpenWebMath y FineMath, construidos específicamente para el razonamiento matemático. Utilizando el modelo Qwen-2.5-32B como clasificador, los investigadores analizaron 200.000 documentos seleccionados al azar de estos dos conjuntos de datos para detectar la presencia del comportamiento cognitivo objetivo. Los resultados mostraron que, incluso en estos corpus centrados en las matemáticas, la frecuencia de comportamientos cognitivos como el retroceso y la validación seguía siendo baja. Esto sugiere que los procesos estándar de preentrenamiento han limitado la exposición a estos patrones de comportamiento clave.
Para comprobar si el aumento artificial de la exposición a comportamientos cognitivos aumenta el potencial de mejora del modelo, los investigadores desarrollaron un conjunto de datos de preentrenamiento continuo a partir del conjunto de datos OpenWebMath. Primero utilizaron el modelo Qwen-2.5-32B como clasificador para analizar documentos matemáticos del corpus de preentrenamiento e identificar la presencia del comportamiento de razonamiento objetivo. A partir de ahí, crearon dos conjuntos de datos de comparación: uno rico en comportamientos cognitivos y un conjunto de datos de control con muy poco contenido cognitivo. A continuación, utilizaron el modelo Qwen-2.5-32B para reescribir cada documento de ambos conjuntos de datos en un formato estructurado de pregunta y respuesta, preservando la presencia o ausencia natural de comportamientos cognitivos en los documentos de origen. Los conjuntos de datos de preentrenamiento resultantes contenían cada uno un total de 8,3 millones de tokens. Este planteamiento permitió a los investigadores aislar eficazmente los efectos del comportamiento de razonamiento al tiempo que controlaban el formato y la cantidad de contenido matemático durante el preentrenamiento.
Tras preentrenar el modelo Llama-3.2-3B en estos conjuntos de datos y aplicar el aprendizaje por refuerzo, los investigadores observaron:
- Los modelos preentrenados ricos en comportamiento alcanzan finalmente un nivel de rendimiento comparable al del modelo Qwen-2.5-3B, con una mejora relativamente limitada del rendimiento del modelo de control.
- El análisis conductual de los modelos post-entrenamiento mostró que la variante conductualmente enriquecida del modelo pre-entrenado mantuvo una alta activación del comportamiento de inferencia durante todo el proceso de entrenamiento, mientras que el modelo de control exhibió patrones conductuales similares a los del modelo básico Llama-3.
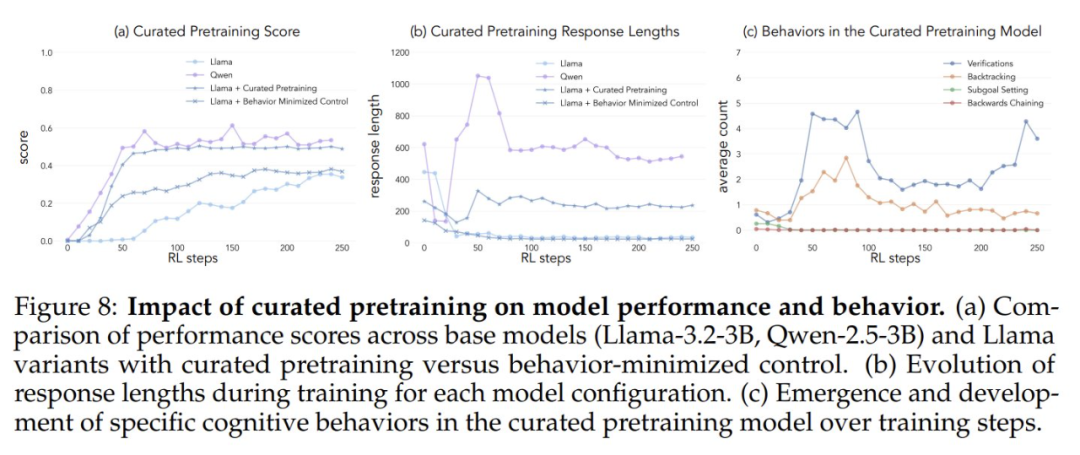
Los resultados de estos experimentos sugieren que La modificación selectiva de los datos de preentrenamiento puede generar con éxito los comportamientos cognitivos clave necesarios para la superación personal efectiva mediante el aprendizaje por refuerzo. Este estudio aporta nuevas ideas y métodos para comprender y mejorar la capacidad de autoperfeccionamiento de grandes modelos lingüísticos. Para más detalles, consulte el artículo original.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Puestos relacionados



Sin comentarios...