
¿Cuánto tiempo de vídeo puede entender un modelo grande? Smart Spectrum GLM-4V-Plus: 2 horas


Basándonos en las dos generaciones anteriores de modelos de vídeo (CogVLM2-Video y GLM-4V-PLUS), hemos optimizado aún más las técnicas de comprensión de vídeo con el lanzamiento de la versión beta GLM-4V-Plus-0111. Esta versión introduce técnicas como la resolución variable nativa, que mejora la capacidad del modelo para adaptarse a distintas longitudes y resoluciones de vídeo.
- Comprensión más detallada de vídeos cortos: para contenidos con una duración de vídeo corta, el modelo admite vídeo nativo de alta resolución para garantizar una captura precisa de la información detallada.
- Mayor comprensión de los vídeos largos: ante vídeos de hasta 2 horas de duración, el modelo puede ajustarse automáticamente a una resolución menor, equilibrando eficazmente la captura de información temporal y espacial para lograr una comprensión en profundidad de los vídeos largos.
Con esta actualización, la versión beta GLM-4V-Plus-0111 no sólo mantiene las ventajas de las dos generaciones anteriores de modelos en términos de Q&A temporal, sino que también consigue mejoras significativas en la longitud de vídeo y la adaptabilidad de la resolución.
I. Comparación de resultados
En el recientemente publicado Smart Spectrum Realtime, 4V, Air new model release, sincronizado con el nuevo artículo sobre la API, detallamos los resultados de la revisión del modelo GLM-4V-Plus-0111 (beta) en el ámbito de la comprensión de imágenes. El modelo alcanzó el nivel sota en varias listas públicas de revisión.
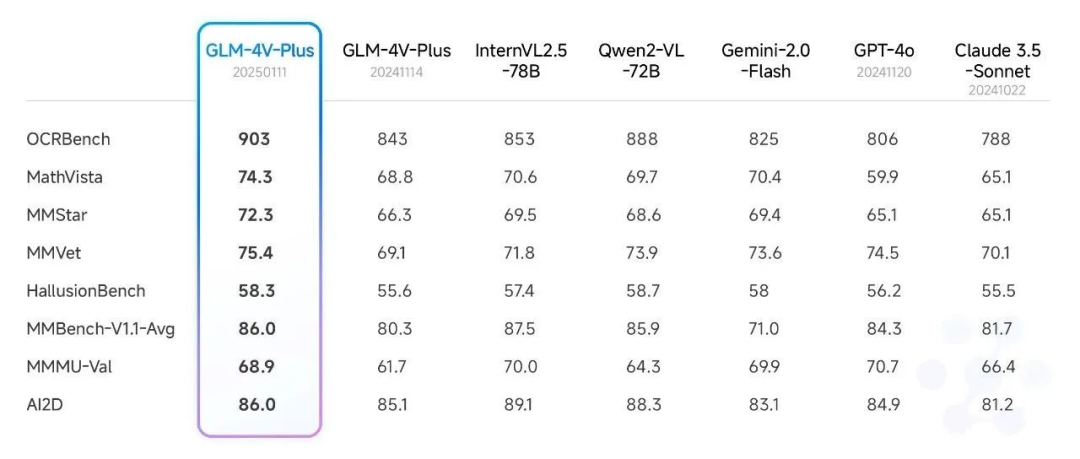
Además, también realizamos una prueba exhaustiva frente a un conjunto autorizado de revisión de comprensión de vídeo, y también logramos un nivel relativamente destacado. En concreto, el modelo beta GLM-4V-Plus-0111 supera con creces a otros modelos de comprensión de vídeo comparables en lo que respecta a la comprensión detallada de acciones en vídeo y a la comprensión de vídeos largos.
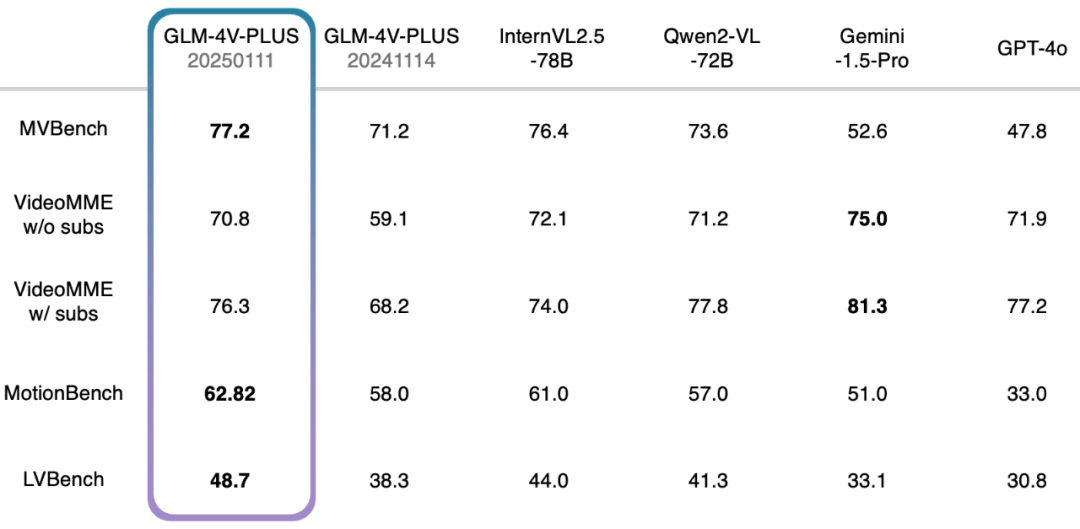
- MVBench: Este conjunto de revisión consta de 20 tareas de vídeo complejas diseñadas para evaluar exhaustivamente las capacidades combinadas de los macromodelos multimodales en la comprensión de vídeo.
- VideoMME sin subtítulos: Como referencia de evaluación multimodal, VideoMME se utiliza para evaluar las capacidades de análisis de vídeo de grandes modelos lingüísticos. En este caso, la versión w/o subs denota una entrada multimodal sin subtítulos, centrándose en el análisis del propio vídeo.
- VideoMME con subtítulos: similar a la versión sin subtítulos, pero con la adición de subtítulos como entradas multimodales para proporcionar una evaluación más completa del rendimiento general del modelo cuando se trata de datos multimodales.
- MotionBench: centrado en la comprensión detallada del movimiento, MotionBench es un completo conjunto de datos de referencia que contiene diversos datos de vídeo y anotaciones humanas de alta calidad para evaluar las capacidades de los modelos de comprensión de vídeo para el análisis del movimiento.
- LVBench: Con el objetivo de evaluar la capacidad del modelo para comprender vídeos largos, LVBench pone a prueba el rendimiento de los modelos multimodales cuando se enfrentan a tareas de vídeo de larga duración, y verifica la estabilidad y precisión de los modelos en el análisis de series temporales largas.
II. Aplicación del escenario
En el último año, las áreas de aplicación de los modelos de comprensión de vídeo se han ido ampliando, proporcionando diversas capacidades como la generación de descripciones de vídeo, la segmentación de eventos, la clasificación, el etiquetado y el análisis de eventos para nuevos medios de comunicación, publicidad, revisión de seguridad, fabricación industrial y otras industrias. Nuestro nuevo modelo de comprensión de vídeo GLM-4V-Plus-0111 beta hereda y refuerza estas funciones básicas, y mejora aún más las capacidades de procesamiento y análisis de datos de vídeo.
Capacidad de descripción de vídeo más precisa: Al basarse en entradas de resolución nativa y en la optimización continua de datos fantasma, el nuevo modelo reduce significativamente la tasa fantasma en la generación de descripciones de vídeo y logra una descripción más completa del contenido de vídeo, proporcionando a los usuarios una información de vídeo más precisa y rica.


Procesamiento eficaz de datos de vídeo: el nuevo modelo no sólo es capaz de proporcionar descripciones detalladas de los vídeos, sino que también puede realizar con eficacia tareas de clasificación, generación de títulos y etiquetado de vídeos. Los usuarios pueden mejorar aún más la eficiencia del procesamiento personalizando las indicaciones o creando procesos automatizados de datos de vídeo para una gestión inteligente.

Conocimiento preciso del tiempo: En respuesta a la naturaleza temporal de los datos de vídeo, nuestro modelo se ha dedicado desde su primera generación a mejorar las capacidades de interrogación temporal. Ahora, el nuevo modelo puede localizar con mayor precisión los puntos temporales de eventos específicos, permitir la segmentación semántica y la edición automatizada de vídeos, y ofrecer un potente soporte para la edición y el análisis de vídeos.
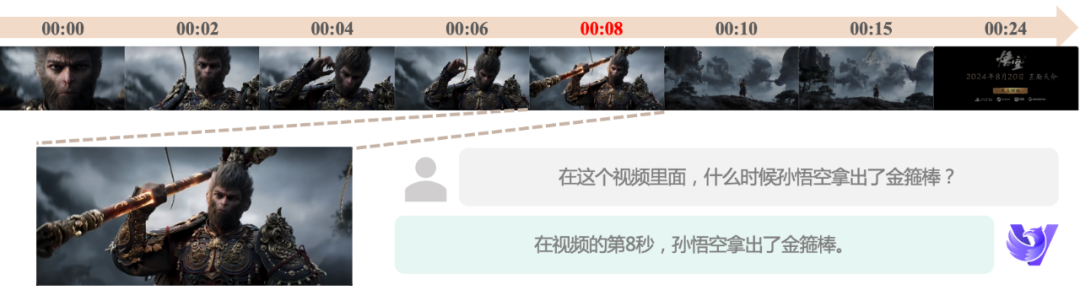
Capacidad de comprensión fina del movimiento: El nuevo modelo admite entradas de mayor frecuencia de imagen, lo que permite capturar pequeños cambios de movimiento y lograr una comprensión más fina del movimiento incluso cuando la frecuencia de imagen del vídeo es baja, lo que supone una gran garantía para los escenarios de aplicación que requieren un análisis preciso del movimiento.


Comprensión de vídeo ultralarga: Gracias a la innovadora tecnología de resolución variable, el nuevo modelo supera las limitaciones del tiempo de procesamiento de vídeo y admite hasta 2 horas de comprensión de vídeo, lo que amplía significativamente los escenarios de aplicación empresarial del modelo de comprensión de vídeo, y a continuación se muestra un caso de demostración de comprensión de vídeo de una hora de duración:

Capacidad de videollamada en tiempo real: Basándonos en un potente modelo de comprensión de vídeo, hemos desarrollado un modelo de videollamada en tiempo real, GLM-Realtime, con capacidad de comprensión de vídeo y preguntas y respuestas en tiempo real, y memoria de llamada de hasta 2 minutos. El modelo ya está en línea.Plataforma abierta Smart Spectrum AIGLM-Realtime no sólo ayuda a los clientes a crear inteligencias de videollamada, sino que también se combina con el hardware conectable en red existente para crear fácilmente productos innovadores como hogares inteligentes, juguetes con IA, gafas con IA y mucho más.
Actualmente, los usuarios normales también pueden disfrutar de la experiencia de realizar videollamadas con IA en la aplicación Smart Spectrum Clear Speech.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...