Coqui TTS (xTTS): un conjunto de herramientas de aprendizaje profundo para la generación de texto a voz con soporte multilingüe y capacidades de clonación de voz.
Últimos recursos sobre IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 107.5K 00

Introducción general
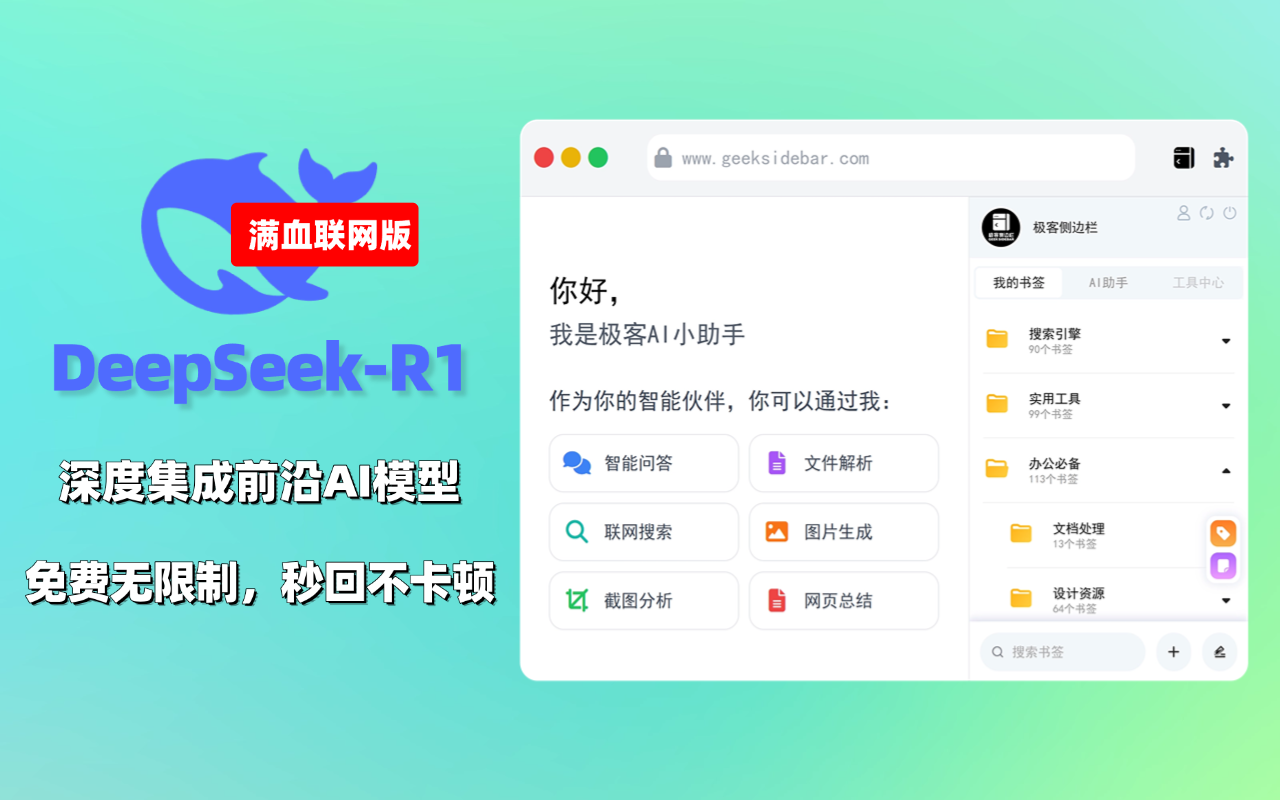
Coqui TTS es un conjunto de herramientas avanzadas de generación de texto a voz (TTS) de código abierto basado en técnicas de aprendizaje profundo. Coqui TTS no solo admite modelos preentrenados, sino que también proporciona herramientas para entrenar nuevos modelos y ajustar los existentes para una amplia gama de idiomas y escenarios de aplicación.
El autor ya no actualiza el proyecto, la rama del proyecto está en mantenimiento continuo: https://github.com/idiap/coqui-ai-TTS
:文本到语音生成的深度学习工具包,支持多种语言和声音克隆功能-1")
Demostración: https://huggingface.co/spaces/coqui/xtts
Lista de funciones
- Soporte multilingüe: Admite la conversión de texto a voz en más de 1100 idiomas.
- Modelo de preentrenamientoEl programa ofrece una amplia gama de modelos preentrenados que el usuario puede utilizar directamente.
- formación de modelos: Ayuda a la formación de nuevos modelos y al ajuste de los existentes.
- clonación de sonido: Admite la función de clonación de voz, que permite generar una voz para un sonido específico.
- Formación eficaz: Proporcionar herramientas de formación de modelos rápidas y eficaces.
- Registro detallado: Proporcionar registros de formación detallados sobre el terminal y el Tensorboard.
- Herramientas prácticas: Proporcionar herramientas para el análisis y cotejo de conjuntos de datos.
Utilizar la ayuda
Proceso de instalación
- almacén de clonesEn primer lugar, clona el repositorio GitHub de Coqui TTS.
git clone https://github.com/coqui-ai/TTS.git cd TTS
2. **安装依赖** :使用 pip 安装所需的依赖。
```bash
pip install -r requirements.txt
- Instalación de TTS Ejecute el siguiente comando para instalar TTS.
python setup.py install
Utilización
- Carga de modelos preentrenados La conversión de texto a voz puede realizarse utilizando modelos preformados.
from TTS.api import TTS
tts = TTS(model_name="tts_models/en/ljspeech/tacotron2-DDC", progress_bar=True)
tts.tts_to_file(text="Hello, world!", file_path="output.wav")
- Formación de un nuevo modelo Puede entrenar nuevos modelos a partir de su propio conjunto de datos.
python TTS/bin/train_tts.py --config_path config.json --dataset_path /path/to/dataset
- Perfeccionamiento de los modelos existentes El objetivo: adaptar los modelos existentes a escenarios de aplicación específicos.
python TTS/bin/train_tts.py --config_path config.json --dataset_path /path/to/dataset --restore_path /path/to/pretrained/model
Procedimiento de funcionamiento detallado
- Preparación de datos Prepare el conjunto de datos de entrenamiento y asegúrese de que el formato de los datos cumple los requisitos.
- archivo de configuración : Editar archivo de configuración
config.json, establezca los parámetros de entrenamiento. - Iniciar la formación Ejecute el script de entrenamiento para iniciar el entrenamiento del modelo.
- Supervisar la formación Monitoriza el proceso de entrenamiento, visualiza los registros de entrenamiento y el rendimiento del modelo a través del terminal y del Tensorboard.
- evaluación de modelos Una vez finalizado el entrenamiento, se evalúa el rendimiento del modelo y se realizan los ajustes y optimizaciones necesarios.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...