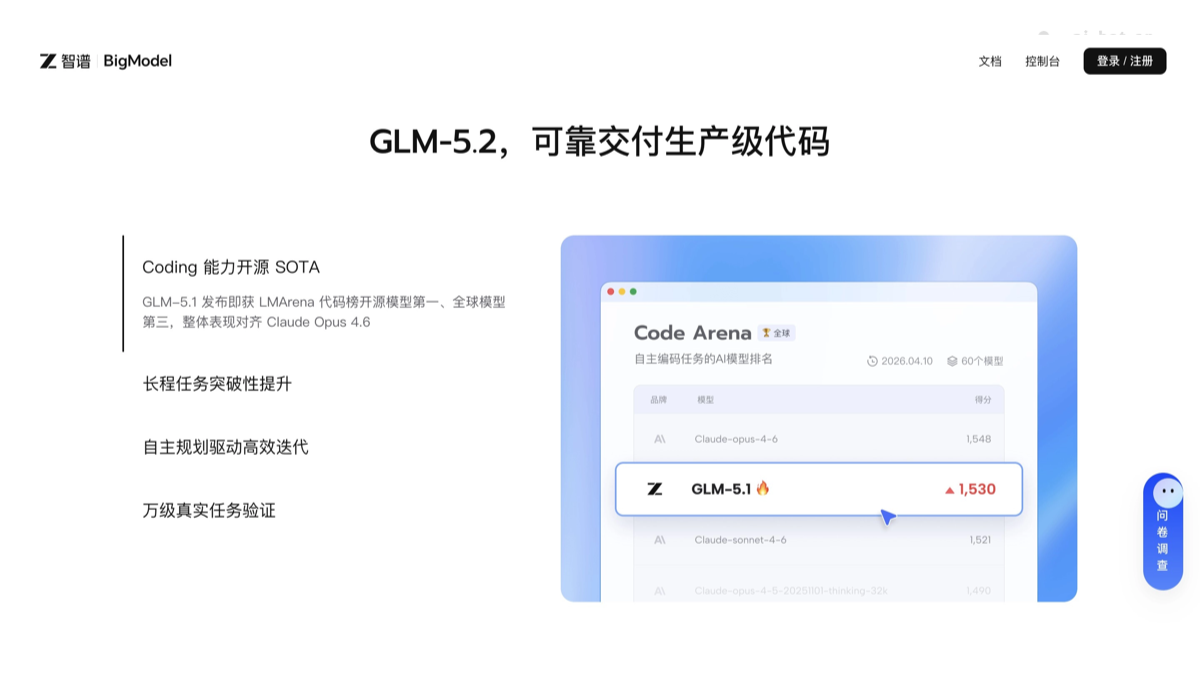
GLM-5.2 - 智谱最新推出的旗舰级开源大模型
GLM-5.2 是智谱最新推出的旗舰级开源大模型,超长上下文理解和智能编程为核心卖点。模型具备百万级 token 的上下文处理能力,能一次性分析整个代码仓库或长篇技术文档。
蛙蛙写作2.0升级深度解析:三栏架构如何重塑AI长篇创作体验
2025年7月,蛙蛙写作正式发布2.0版本,这是该产品自2024年上线以来幅度最大的一次产品重构。此次升级不仅在底层技术能力上实现了对主流大模型的深度整合,更在产品交互架构上做出了突破性的创新——引入...

TypeNo - 开源 AI 语音输入工具,专为 macOS 设计
TypeNo 是 marswaveai 团队开源的中文语音输入工具,专为 macOS 打造。用户只需轻点 Control 键即可录音,松手后语音会在本地实时转为文字并自动填入当前应用。
肉包 - 开源AI手机自动化助手,能看懂屏幕自动执行
肉包(Roubao)是开源的AI手机助手,让用户用现有Android手机能体验类似"豆包手机"的智能自动化功能。肉包基于视觉语言模型,能看懂屏幕内容并自动执行复杂任务,从点外卖、发微信到跨App操作...
HiClaw - 阿里云开源的多智能体团队协作系统
HiClaw 是阿里云开源的多 Agent 协作框架,让单个用户能像指挥团队一样调度多个 AI 员工。系统设置一位 Manager 管家负责拆解任务、分配工作,各 Worker 专精不同领域且相互隔离...

MiniMax Music 2.5+ - MiniMax推出的AI音乐生成模型
MiniMax Music 2.5+是MiniMax推出的AI音乐生成模型,专注器乐创作。模型精通古典管弦、电子氛围、自然声景等多元风格,擅长将东方传统乐器与西方现代编曲融合,实现跨风格创新。
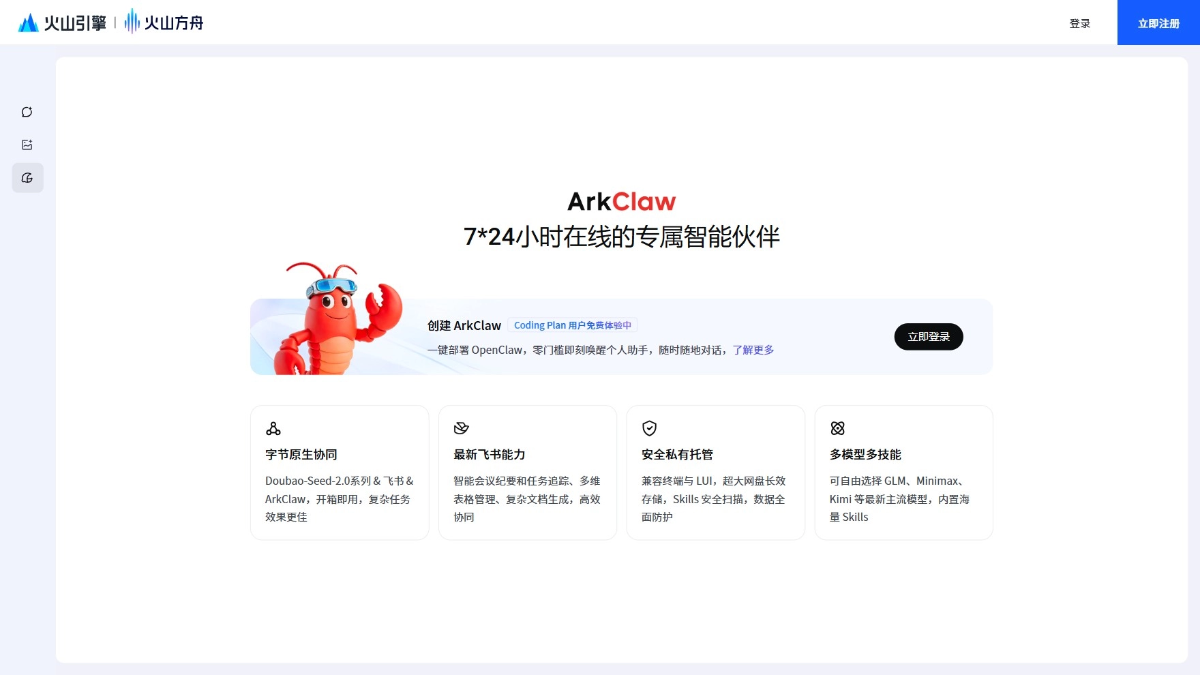
ArkClaw - 火山引擎推出的云端AI助手,零门槛部署OpenClaw
ArkClaw是火山引擎推出的云端智能助手平台,基于OpenClaw架构构建,让用户无需繁琐配置可快速部署专属AI Agent。
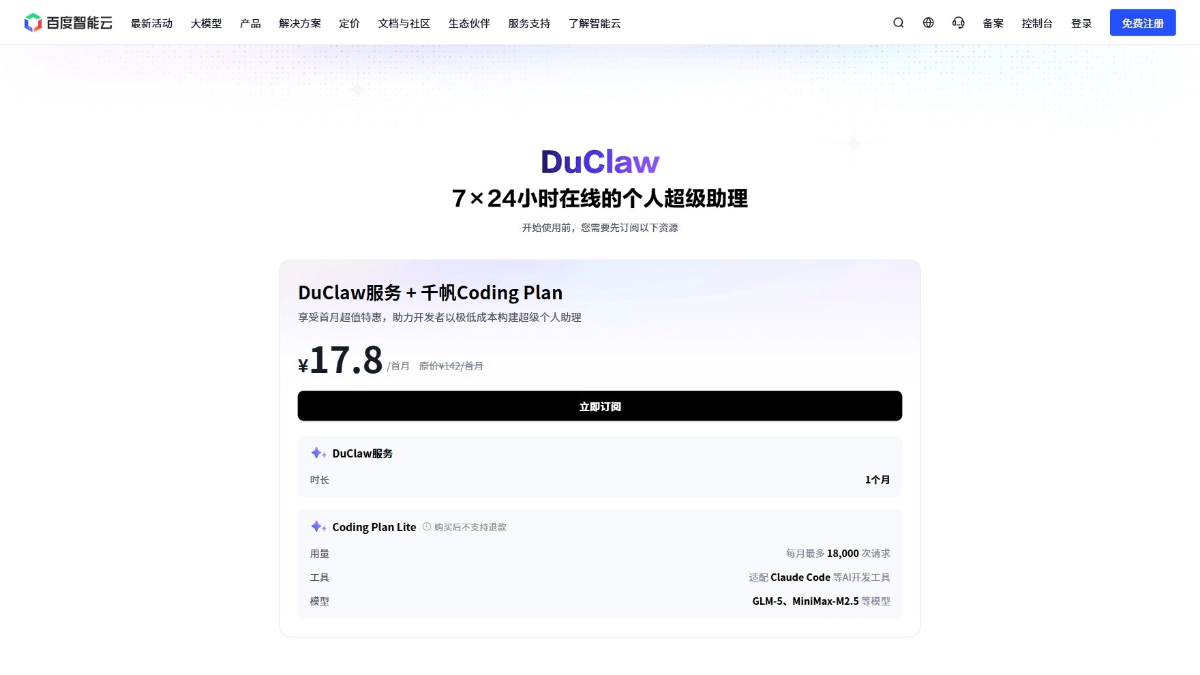
DuClaw - 百度智能云推出的OpenClaw云部署服务
DuClaw是百度智能云推出的托管式OpenClaw服务,专为无技术背景用户设计。DuClaw免除了服务器配置、镜像选择和API密钥管理的繁琐步骤,用户订阅后可在网页端直接调用完整的智能体功能。
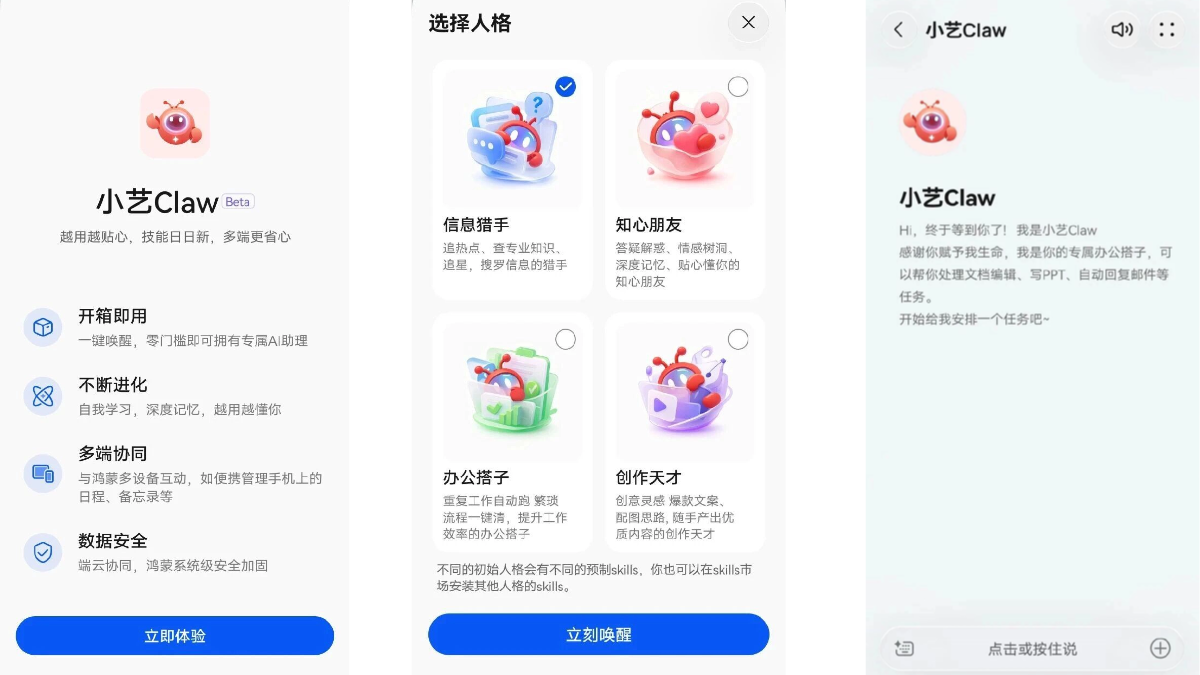
小艺Claw - 华为推出的个人手机AI助理,一键接入OpenClaw
小艺Claw是华为基于OpenClaw开源框架推出的AI智能体,集成于小艺App中。小艺Claw打破传统语音助手"被动应答"的交互逻辑,具备自主规划与任务执行能力,可独立完成办公文档处理、信息检索、服...

GPT‑5.4 - OpenAI推出的全能旗舰AI模型
GPT-5.4是OpenAI推出的旗舰AI模型,专为复杂专业场景设计。模型突破性融合推理、编程、原生计算机操控与深度搜索四大能力,在OSWorld测试中首次超越人类操作水平,知识工作任务表现达专家级标...